

Stable Diffusionで「自分だけのキャラや絵柄を再現したい」と思ったことはありませんか?
そんなときに活躍するのが、自作できる追加学習データ=LoRAです。
ConoHa AI Canvasのスタンダードプランとアドバンスプランを契約すると、ハイスペックなパソコンがなくても簡単に作成可能です。
この記事ではLoRAの作り方をステップごとに解説しながら、初心者でも簡単に始められるコツを紹介します。
LoRAとは?少ないリソースでもできる仕組み
LoRA(Low-Rank Adaptation)は、元のモデル全体を作り直すのではなく、一部の学習パラメータだけを追加・更新することで新しい情報を覚えさせる手法です。
Stable Diffusionの出力に「自分だけのキャラ」や「特定の絵柄」を反映させたいとき、少ない画像と短時間で目的の特徴を効率よく学習できます。
これまではモデル全体のファインチューニングを行ったり、モデル同士をマージして好みに近づける方法も使われていましたが、LoRAに必要なリソースは少ないため、環境を用意しやすいメリットがあります。
VRAM12GB程度でも安定して学習できるため、個人のPC環境でも高品質なLoRAを自作可能です。

LoRAの作り方の概要:学習用画像を準備・収集するコツ

LoRA作成に必要なツールや作業内容は多く見えますが、流れをつかめばそれほど複雑ではありません。
ConoHa AI Canvasを使えば、初めてでも手順どおり進めるだけで完成できます(スタンダードプラン以上)。
このセクションでは、必要な準備から学習・出力までの流れを一つずつ整理しながら、LoRA作成を現実的な作業として落とし込んでいきます。
必要な要素とツール一覧
LoRAを個人PCで作成するためには、主に以下の5つが必要です。
- 学習させる画像データ
- 画像に対応するタグ(キャプション)
- 学習スクリプトまたはGUI
- Python実行環境
- GPU(VRAM24GB以上推奨)
画像データ数は任意ですが、最低20〜30枚が推奨されます。難しい髪型を反映するなど、安定した品質を目指す場合に推奨される枚数は50枚以上です。キャプションは自動生成ツールの利用も可能です。
学習スクリプトにはさまざまな選択肢がありますが、GUIで直感的に操作できる「Kohya’s GUI」などが一般的に使用されます。Kohya’s GUIなどを動かすためのPython実行環境を構築するためには、Anacondaを使用するケースが多いです。
個人PCを使用する場合は、このように環境構築が必要になります。
一方、ConoHa AI Canvasのスタンダート/アドバンスプランであれば学習用環境がすでに用意されています。「学習させる画像データ」と「画像に対応するタグ(キャプション)」を用意するだけでLoRAを作成できます。

データセット収集:学習用画像の選び方・集め方
LoRAの品質を左右するもっとも重要な要素が、学習データセットの質です。単に枚数を集めるだけではなく、統一感のあるデータを選定することがコツです。
- 構図・表情・衣装のバリエーションを抑え、色味もそろえた統一感のある画像群
- SDXLを利用する場合、画像サイズは1024×1024が推奨
- アスペクト比を統一する
キャラクターを学習させたい場合は、構図・表情・衣装のバリエーションを抑えましょう。画像には、統一感をもたせることで、描写の安定感を高められます。
AI生成で画像を用意する際には、学習させたい特徴部分を安定させたり、必要がない要素を排除することで、学習用画像としての品質を高めましょう。色味も揃えると、品質の安定したLoRAを作成できます。

画像サイズについては、利用するモデルごとに推奨されるサイズが異なります。現在よく使われているSDXLを利用する場合は1024×1024pxが推奨され、アスペクト比をそろえると学習エラーを防げます。
今回はキャラクターLoRAの作成に焦点を当てますが、特に枚数が少ない場合、「背景が違う(中央下)」「髪型が難しく見えづらい(左上)」などの画像は破綻の原因になります。正面顔を中心に、キャラクターの特徴が見えやすい向きの、表情や顔の向きを少しだけ変えた画像を用意しましょう。
画像を収集する際には、CC0が適用された画像を利用するとよいでしょう。CC0とは、権利者が法律上可能な範囲で著作権や関連する権利を放棄し、誰でも自由に使える状態に近づけるためにCreative Commonsが提供する仕組みです。
作品にCC0を付する者(以下「確約者」という。)は、追加の対価または補償を一切求めることなく、確約者が本作品の著作権および関連する権利の権利者である限り、すすんで本作品にCC0を適用し、CC0の規程に従って、自らの作品を公に配布する
出典: CC0 1.0 全世界 リーガル・コード
ただし、人物写真、商標、キャラクター性のある素材は、肖像権や商標権にも注意が必要です。
データセット準備:キャプションの整備とコツ
キャプション(タグ)は画像の特徴をモデルに伝えるための重要な情報です。
キャプションの内容も、LoRAの品質に影響します。特徴の強いキャプションは前方に配置することで、精度向上につながります。
一方で、キャプションを入れすぎるとLoRAが学ぶ要素が曖昧になってしまい、精度低下の原因になることがあります。はじめはキャプションに設定する要素を最小限にすることをおすすめします。
LoRAの作り方:ConoHa AI Canvasを使って簡単に作成する
実際に、ConoHa AI Canvasを使ってLoRAを作成する手順を紹介します。
ConoHa AI Canvasなら、Webブラウザから簡単に利用できます。ただしスタンダードプラン以上の契約が必要です。
今回はSDXLに適用するLoRAを作成していきます。

学習用画像のアップロード
まずはLoRAの学習に利用する画像をアップロードします。実際の手順は以下の通りです。
ConoHa AI Canvasへログインしたら、ファイルマネージャーを使って学習用画像をアップロードするフォルダを作成します。
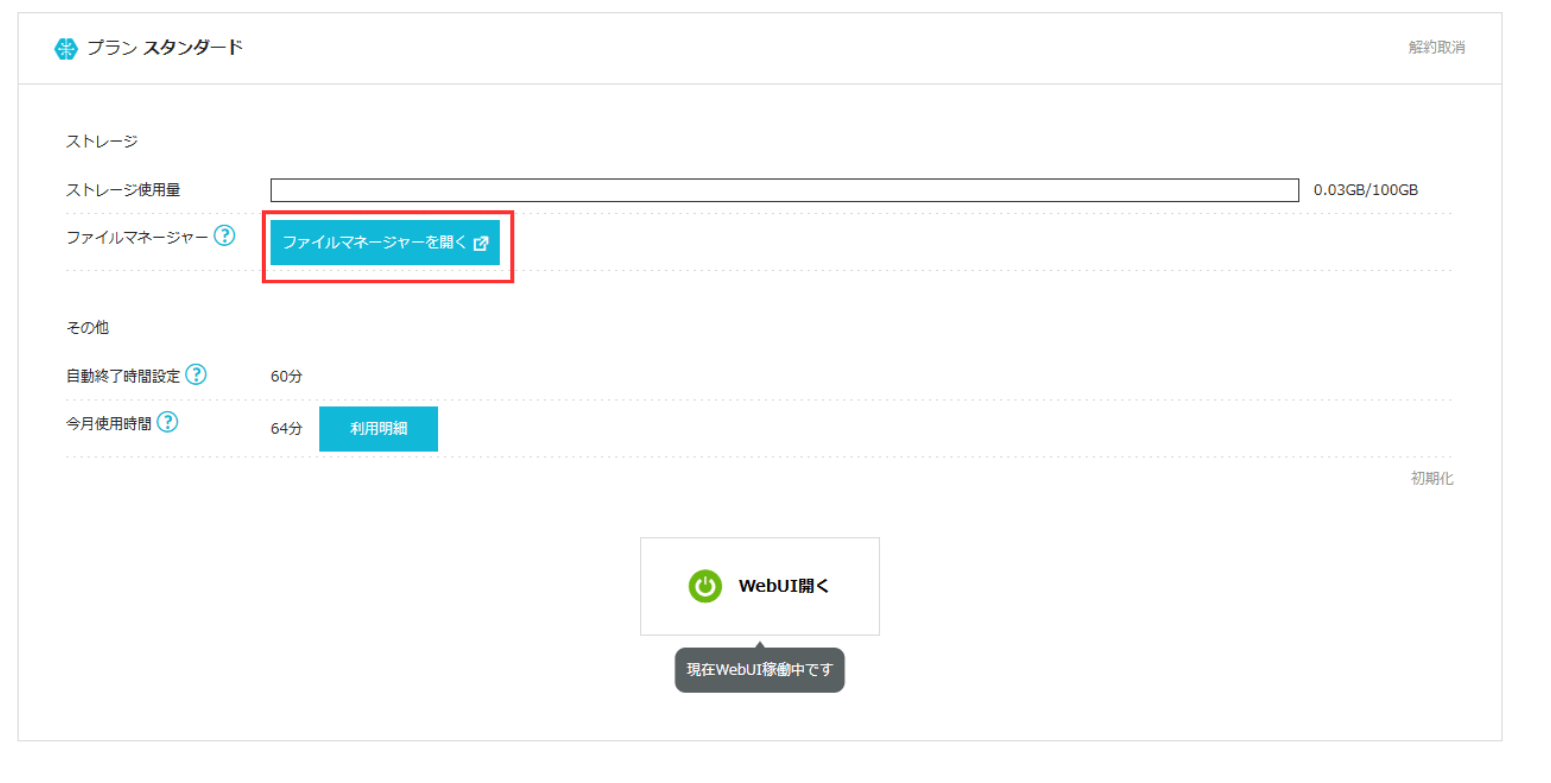
ConoHa AI Canvasコントロールパネルの左メニューから「AI Canvas」をクリックしてください。
以下の画面が表示されるので、「ファイルマネージャーを開く」ボタンをクリックします。
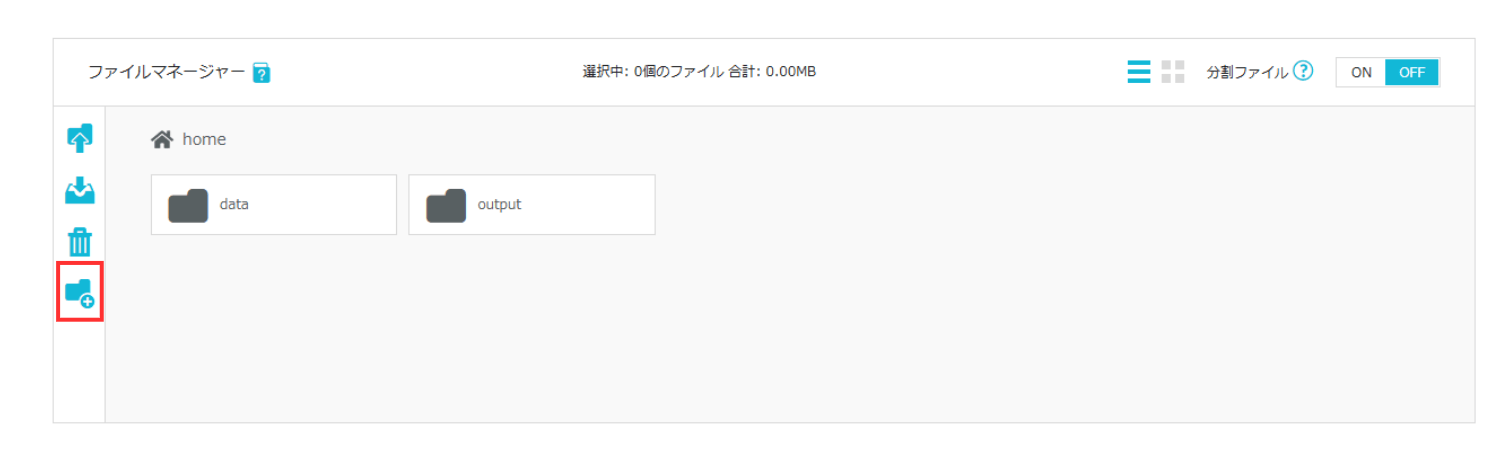
ファイルマネージャーのフォルダ作成アイコンをクリックし、親フォルダを作成します。
フォルダ名を入力したら、「決定」ボタンをクリックしてください。
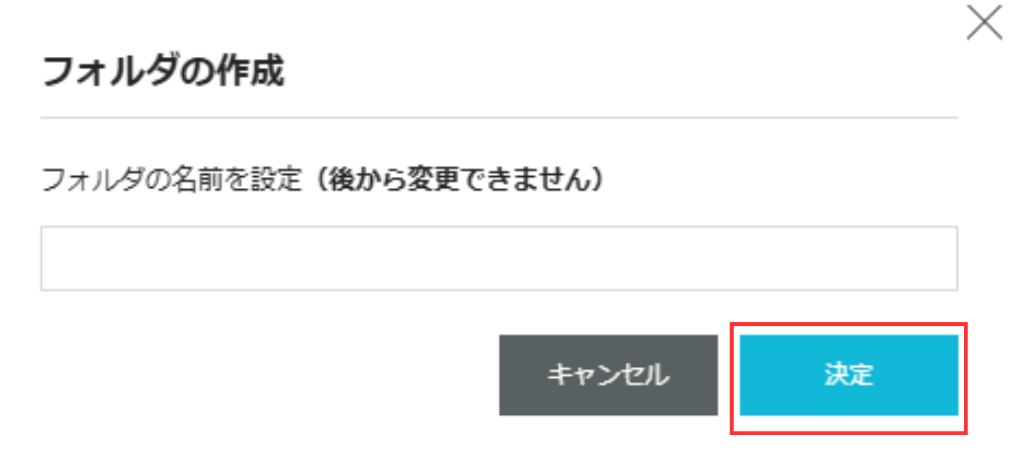
今回、親フォルダの名前はdatasetにしています。
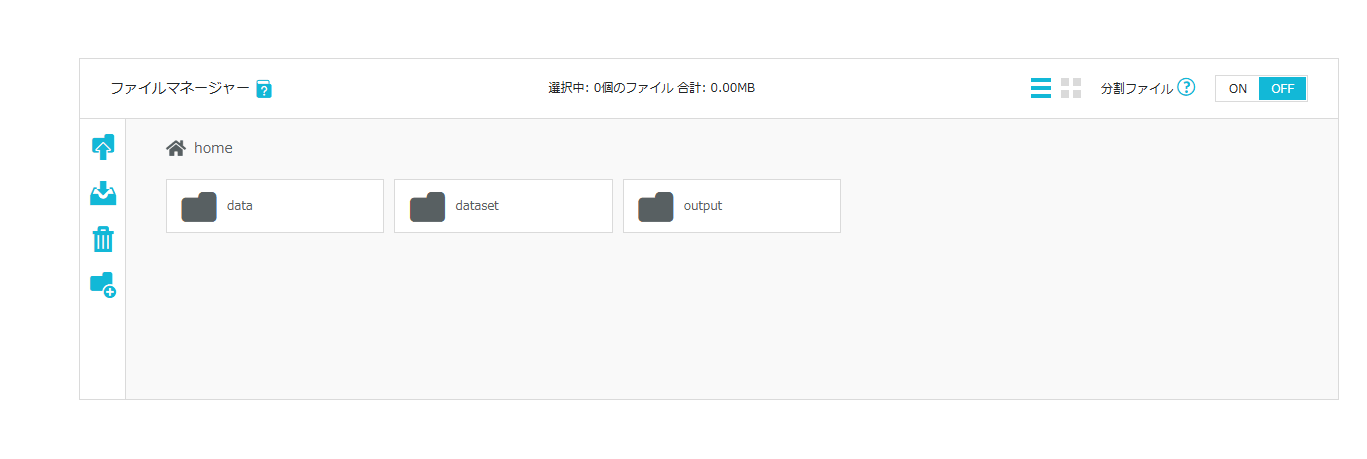
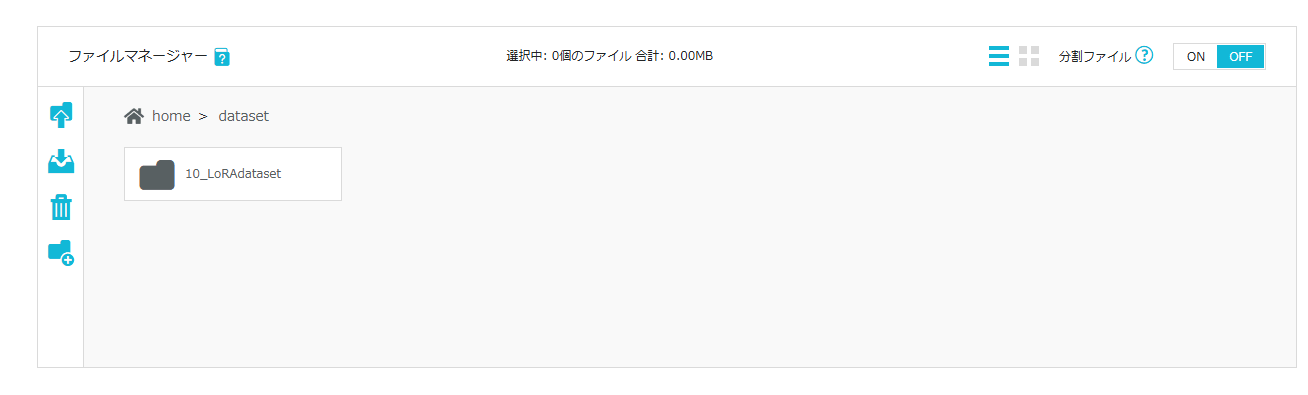
STEP3で作成した親フォルダ内に、同じ手順でアップロード用フォルダを作成します。
アップロード用フォルダの命名規則である「[繰り返し回数]_[任意の名前]」に従って名前を設定してください。今回は10_LoRAdatasetという名前にしています。
ファイルマネージャーの左メニューから「アップロードアイコン」をクリックして学習用画像をアップロードします。今回は25枚の画像をアップロードしました。
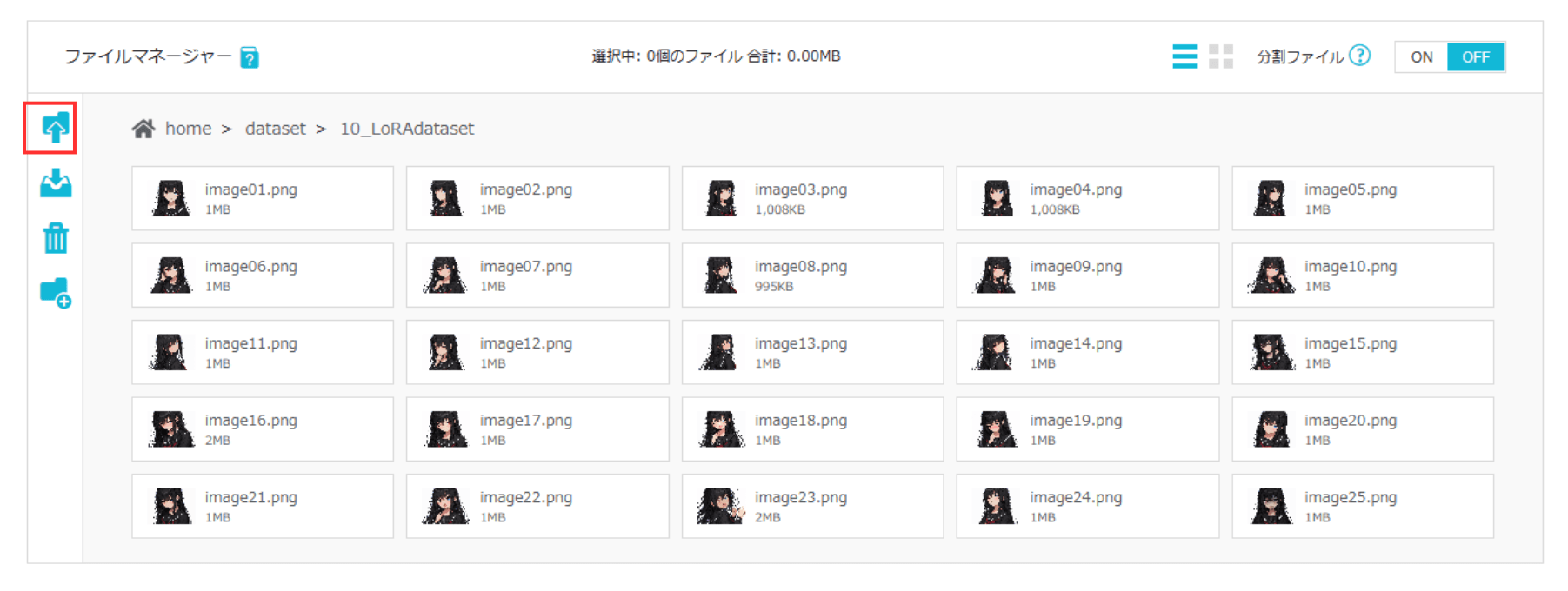
以上のように、GUIの操作で簡単に画像の準備が完了します。
\ MiraLab AIの読者限定で500円割引適用中 /
Utilitiesタブでキャプションを設定
ConoHa AI Canvasを使用する場合、学習用画像を用意し、その画像にキャプションを設定するとすぐにLoRAを作成できます。実際にキャプションを設定する方法は以下の通りです。
今回は画像分類モデルを使って画像内の特徴を推定し、「その画像に含まれていそうな要素」をタグとして書き出すWD14を活用して自動でキャプションを生成しました。
LoRA機能を利用するためのUIとして、Kohya SSを起動します。ConoHa AI Canvasコントロールパネルの「WebUI起動」ボタンをクリックしてください。
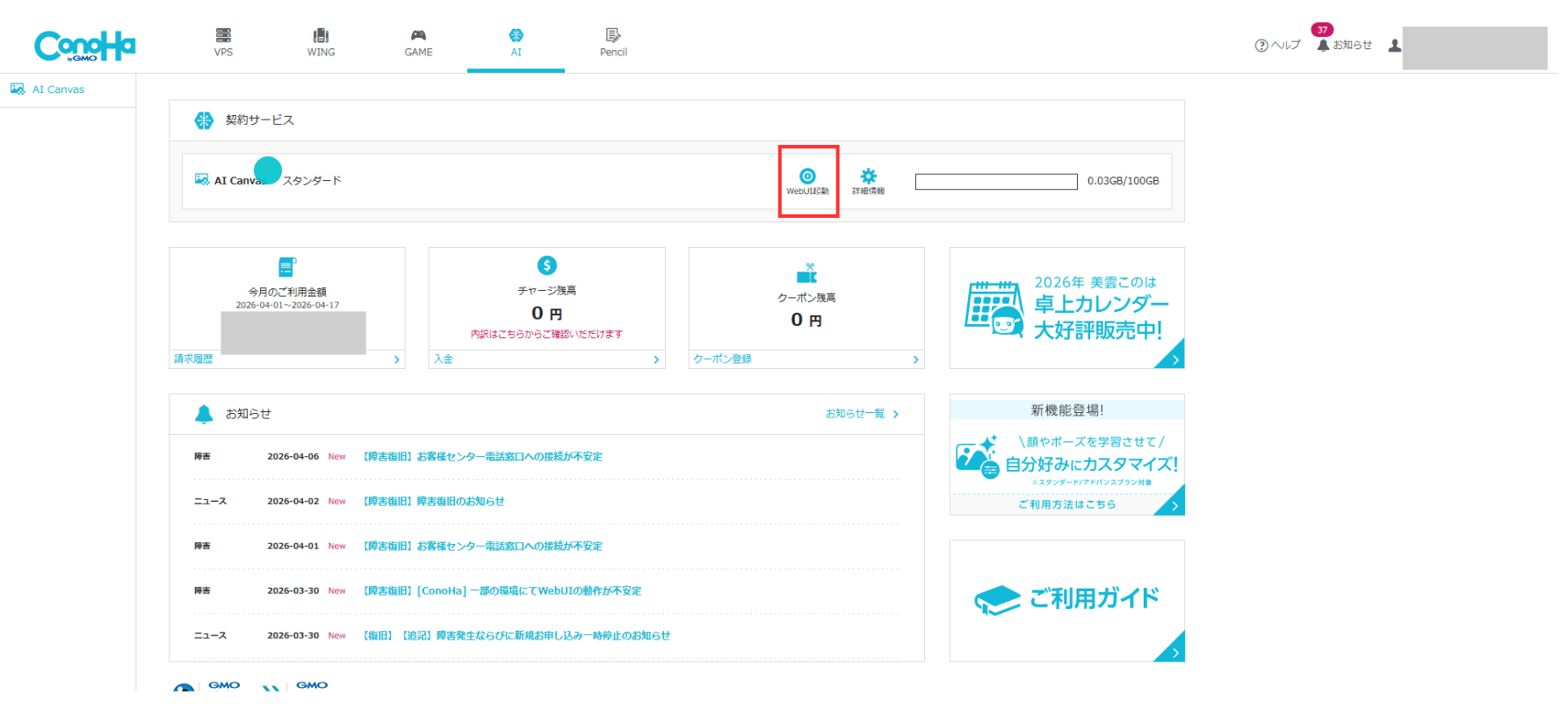
「起動するWebUI」で「Kohya SS (LoRA学習機能)」を選択します。ユーザーネームとパスワードは任意のものを設定してください。設定が完了したら「起動」ボタンをクリックします。
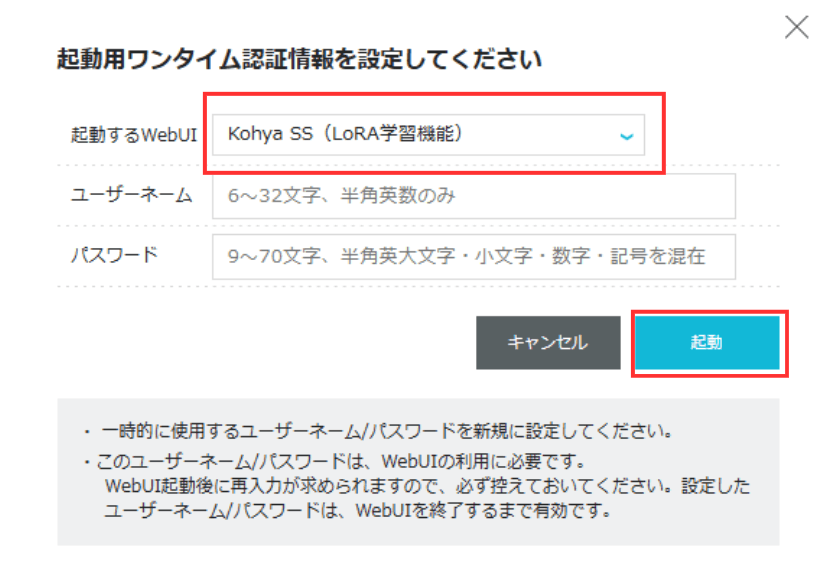
ログイン画面が表示されるので、STEP2で設定したユーザーネームとパスワードを入力し、「Login」ボタンをクリックします。
Kohya SSが起動するので、キャプション作成用の画面を表示します。画面上部で「utilities」タブを開き、次に「WD14キャプション生成」タブを開いてください。
以下を設定したら、画面下部の「画像にキャプションを付ける」ボタンをクリックします。
- キャプションを付ける画像フォルダ:「学習用画像のアップロード」で作成したフォルダ
- Threshold:0.35(推奨値)
- 文字しきい値:0.85(推奨値)


25枚程度であれば数秒でキャプションが作成されます。
ファイルマネージャーの画面で、学習用画像をアップロードしたファイルを確認すると、各画像に対応する.txtファイルが作成されます。
以上のように、ConoHa AI Canvasを使用するとキャプション設定も簡単に行えます。
今回生成されたimage01のキャプション(image01.txt)は以下の内容でした。
1girl, solo, long_hair, looking_at_viewer, blue_eyes, simple_background, shirt, black_hair, white_background, red_eyes, closed_mouth, school_uniform, collarbone, upper_body, serafuku, sailor_collar, black_shirt, neckerchief, heterochromia, transparent_background, red_neckerchief, black_sailor_collar, black_serafuku学習の設定・実行(LoRA作成)
学習用画像とキャプションが用意できたので、Kohya SSのUIでLoRAを作成します。
Kohya SSのUIで「LoRA」タブを開き、以下の設定を行います。
- 事前学習済みモデル名またはパス:画像生成時に利用するモデル
- トレーニング済みモデルの出力名:任意の名前
- 画像フォルダ:画像をアップロードしたフォルダの親フォルダ
「画像フォルダ」には画像が入っているフォルダそのものではなく、その親フォルダを指定する点に注意してください。
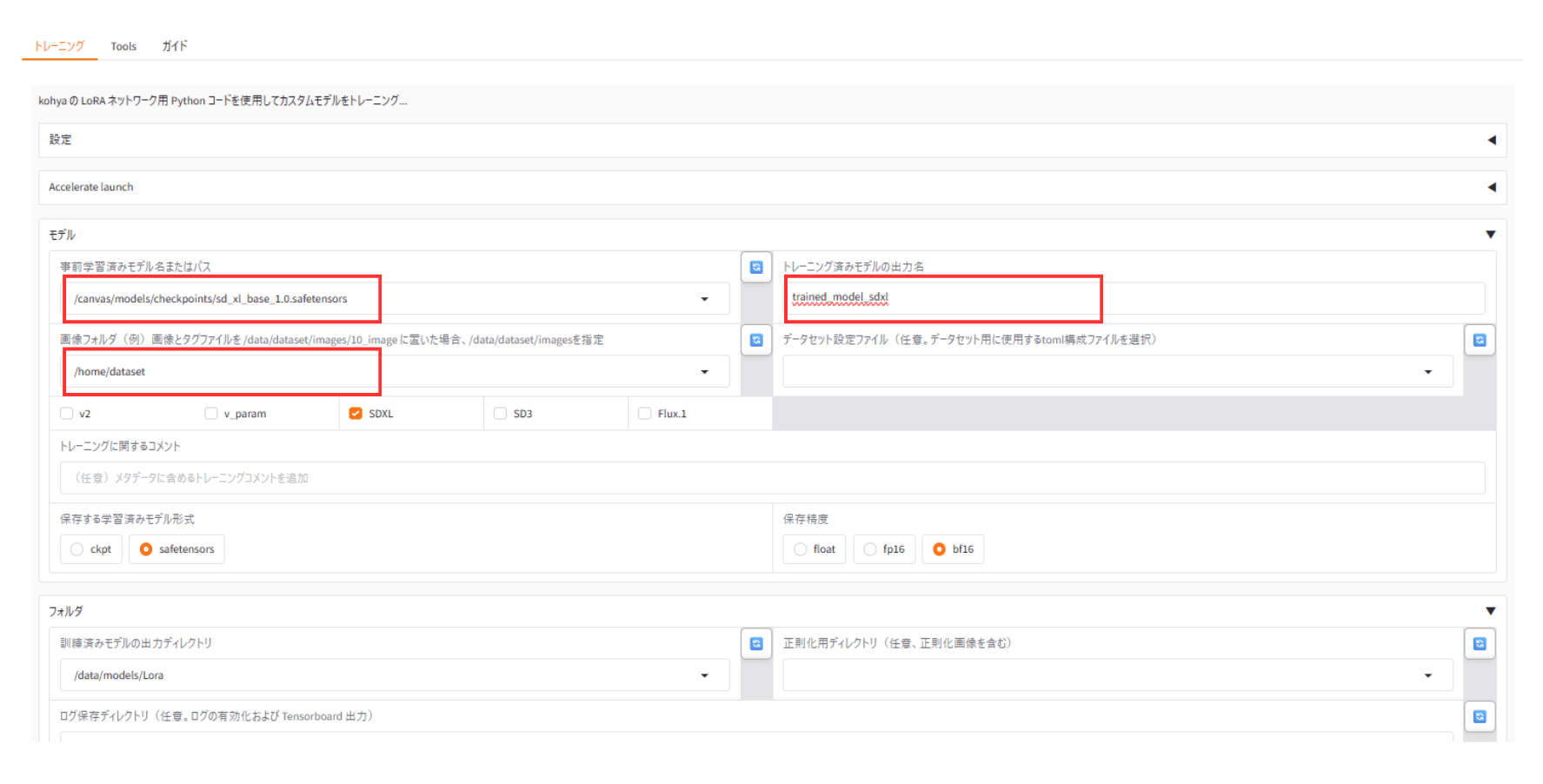
今回は以下の通り設定しています。
- 事前学習済みモデル名またはパス:
/canvas/models/checkpoints/sd_xl_base_1.0.safetensors - トレーニング済みモデルの出力名:
trained_model_sdxl - 画像フォルダ:
/home/dataset
画面下部の「学習を開始」ボタンをクリックして学習を開始します。
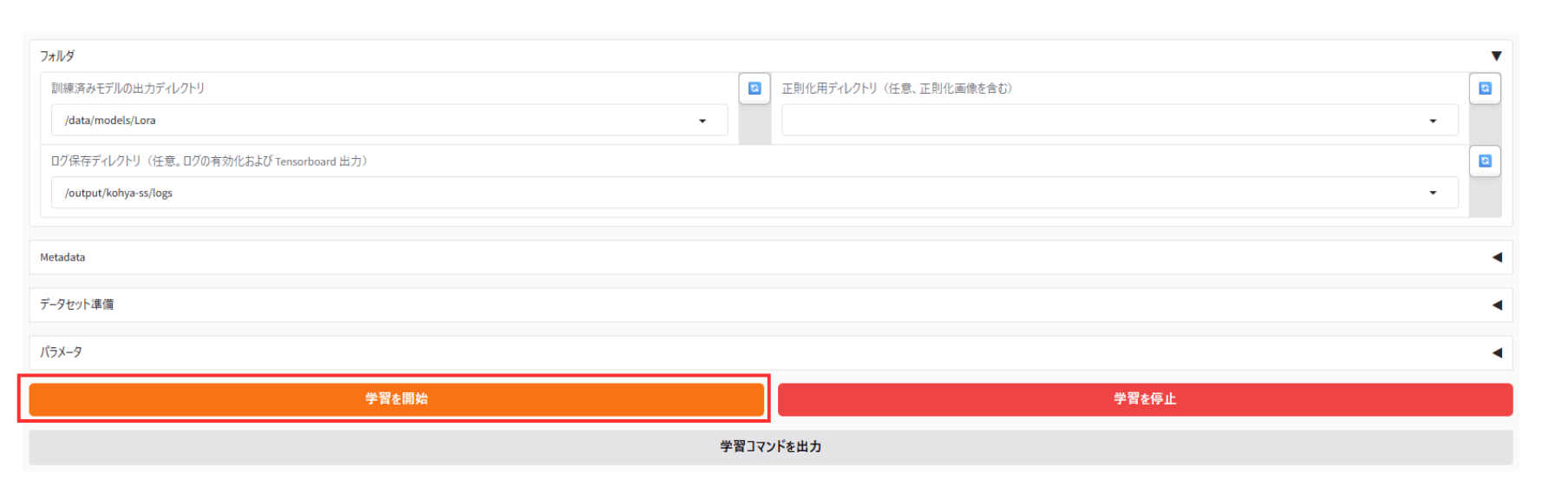
LoRAが作成されると、/home/data/models/Loraにモデルファイルが追加されます。ファイルマネージャーでファイルが追加されたことを確認してください。
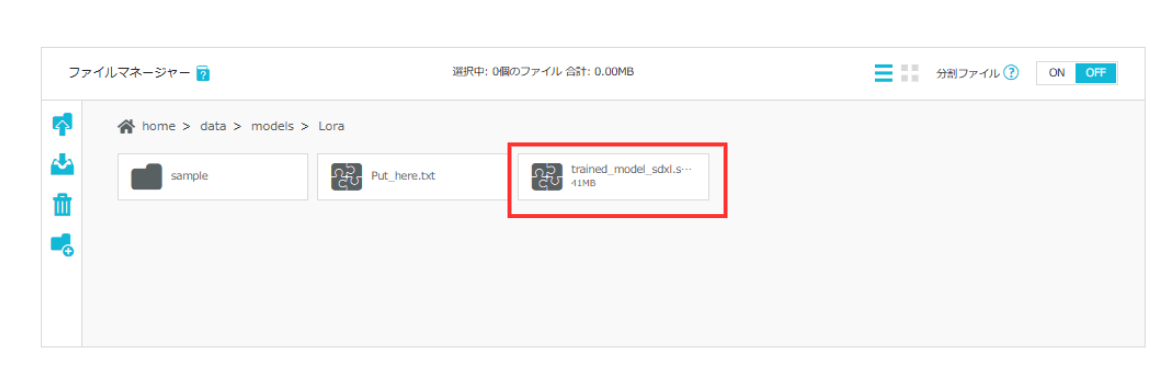
以上のように、ConoHa AI Canvasを使って簡単な手順でLoRAを作成できました。
画像生成の際にこのLoRAを使うことで、画像生成のカスタマイズ性を向上できます。
\ MiraLab AIの読者限定で500円割引適用中 /
LoRAを高品質に仕上げる3つのコツ

LoRAを作成すること自体は簡単ですが、再現性・汎用性・品質を高めるには工夫が必要です。
ここでは特に重要な3つのポイントを紹介します。
タグ整理とキャプション精度の上げ方
正確なキャプション(タグ)付けにより、学習のブレが減り安定した出力になります。
LoRAに学習させる際、「学習させたいキャプションだけを残す」「学習させたいキャプションを残さない」の2パターンがあります。
キャラクターLoRAの場合、使える画像の枚数が多い場合は、学習させたいキャプションを入れなくてもLoRA自体が学習するため、あえて差分のみをプロンプトに書く方法がよく取られます。
今回のように30枚程度の少ない枚数で学習を試みる場合は、学習させたいキャプションだけを残して、LoRAを使用する際もプロンプトに書くと安定します。
また、キャプションに一貫性を持たせることも重要です。
たとえばキャラクターLoRAを作りたい場合に、長髪と短髪の差分を一度に作ろうとすると、出力が不安定になってしまいます。この場合はlong hairとshort hair のそれぞれで画像を用意し、2つのLoRAに分けることで高品質なLoRAとなります。
画像枚数・エポック数の目安と調整法
画像枚数としては、キャラクター特化のLoRAでは30〜50枚、絵柄を再現するLoRAでは100〜200枚程度が目安になります。
学習の際に設定するエポック数は1〜10回程度に設定して、画像の枚数が少ない場合はフォルダ名の先頭に付ける[繰り返し回数]の部分を15程度に増やすことで補完します。
毎エポックごとに保存することで、LoRAが現在どの程度特徴を学んでいるかなどが分かるため、ピークとなる学習段階を見つけやすくなります。
失敗しない学習率とステップ設定
学習率を上げすぎると、特徴を過学習してしまいLoRAの品質が下がります。
学習率は0.00005〜0.0001程度が目安となります。
学習途中のデータを中間保存しておくことで、過学習やエラー時にも復旧が可能です。Kohya SSの「上級」セクションを展開すると、以下のように指定したステップごとにLoRAを保存できます。

完成したLoRAの活用法:Stable Diffusionで使う方法
作成したLoRAは既存のLoRAと同様に、Stable Diffusionのプロンプトで呼び出すだけで使えます。
Automatic1111(Web UI)で作成したLoRAを確認する方法
Automatic1111でのLoRAの呼び出し方を解説します。
画像生成を行うUIとして、Automatic1111を起動します。
ConoHa AI Canvasコントロールパネルの「WebUI起動」ボタンをクリックしてください。
「起動するWebUI」で「Automatic1111(初心者向け)」を選択します。ユーザーネームとパスワードは任意のものを設定してください。設定が完了したら「起動」ボタンをクリックします。
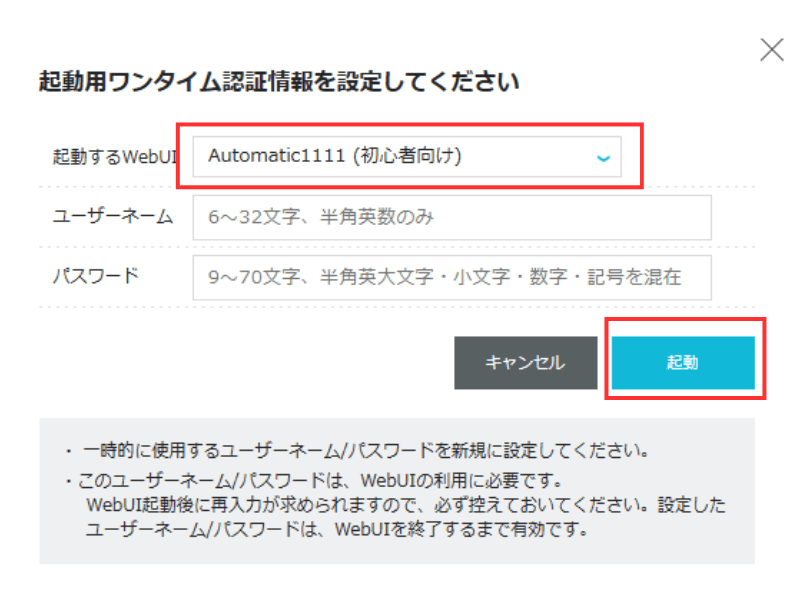
ログイン画面が表示されるので、STEP1で設定したユーザーネームとパスワードを入力し、「Login」ボタンをクリックします。
Automatic1111の画面が表示されたら、左上の「Stable DiffusionのCheckpoint」をLoRA作成時に指定したモデルにします。(今回はsd_xl_base_1.0.safetensors)
画面下部の「LoRA」タブをクリックし、作成したLoRAが表示されていることを確認してください。
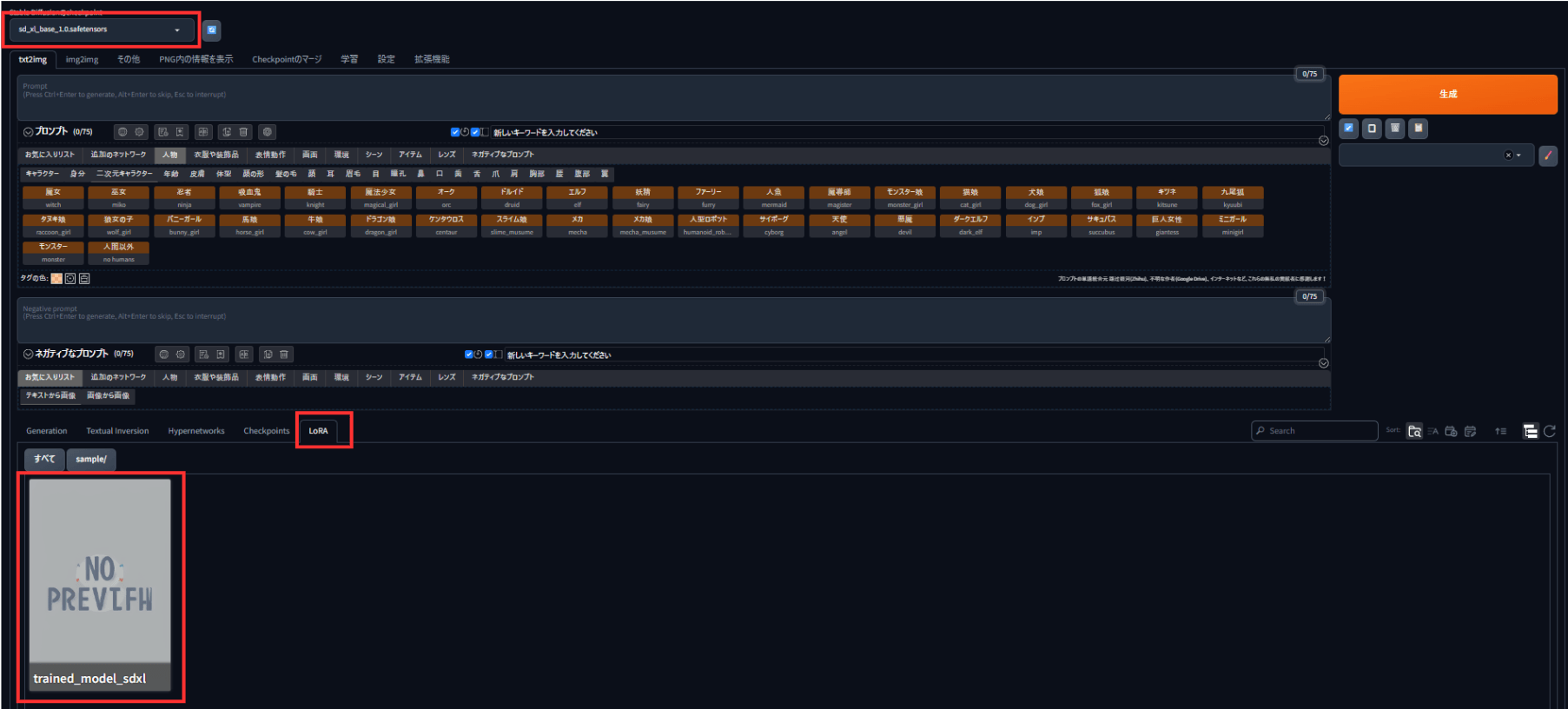
画面にLoRAが表示されていれば、画像生成にそのLoRAを適用できます。
LoRAがAutomatic1111上に表示されていない場合は、左上の「Stable DiffusionのCheckpoint」が適切か、/home/data/models/LoraにLoRAが配置されているかなどを確認してください。
LoRAを利用する際のプロンプト
使い方は簡単で、<lora:ファイル名:強度> という形でプロンプトに記述します。
Automatic1111上でLoRAをクリックすると、プロンプト入力欄に自動で<lora:ファイル名:1>と入力されるため、そのプロンプトを編集するとよいでしょう。

強度の値によって、どの程度LoRAが生成画像に反映されるか決まります。一般的には、0.5〜0.8だと自然な反映がされ、1.0以上だとLoRAの特徴が強調されます。
強度が小さいとLoRAの効果が小さく、大きすぎる強度だと画像が破綻します。まず0.7あたりから試してみるのが良いでしょう。
今回作成したLoRAを使用すると、以下の画像が生成されました。強度0.8とし、学習用画像のキャプションと同じプロンプトを入力しています。

実際に入力したプロンプトは以下です。
1girl,solo,long_hair,looking_at_viewer,blue_eyes,simple_background,shirt,black_hair,white_background,red_eyes,closed_mouth,school_uniform,collarbone,upper_body,serafuku,sailor_collar,black_shirt,neckerchief,heterochromia,transparent_background,red_neckerchief,black_sailor_collar,black_serafuku,<lora:trained_model_sdxl:0.8>LoRAを追加せず、同じプロンプトを入力した場合は以下の画像が生成されました。

入力したプロンプトは以下です。(LoRA適用以外は同じプロンプト)
1girl,solo,long_hair,looking_at_viewer,blue_eyes,simple_background,shirt,black_hair,white_background,red_eyes,closed_mouth,school_uniform,collarbone,upper_body,serafuku,sailor_collar,black_shirt,neckerchief,heterochromia,transparent_background,red_neckerchief,black_sailor_collar,black_serafuku,LoRAを追加することで、プロンプト入力だけよりも画風やキャラクターの特徴(オッドアイ、セーラー服など)が反映されていることが分かります。
SD1.5モデル/SDXLモデルでのLoRAの使用と注意点
SD1.5系列のLoRAと、SDXL系列のLoRAには互換性がありません。専用のベースモデル・スクリプトで学習させる必要があります。
プロンプトの記法やファイル構成も異なるため、必ずSDXL対応のものかどうかを確認してください。
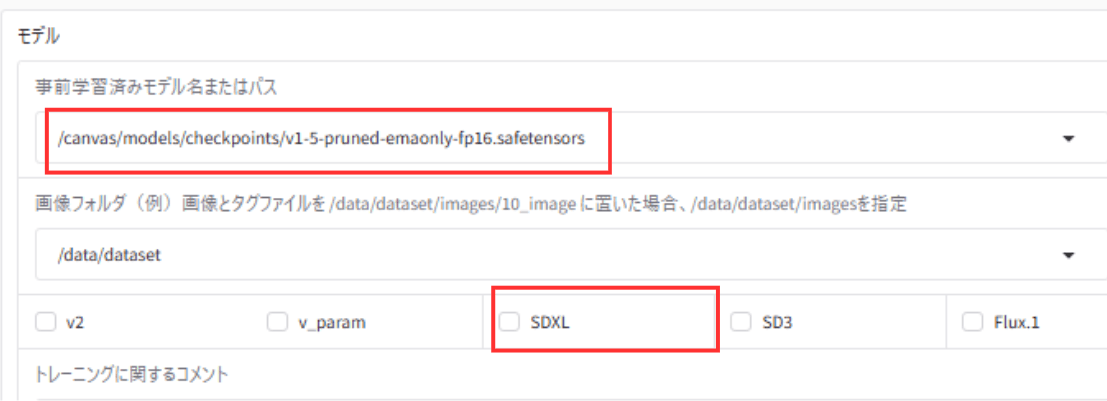
基本的にはベースモデルの選定の際にSD1.5系列のモデルを選び、下記の画像の赤枠部分のSDXLのチェックを外せば学習できます。逆に、このチェックマークを外してもSDXL系列のモデルを選んでいると学習できないため注意してください。
よくある質問とトラブル対処法
LoRA作成中には、出力崩壊・色ずれなどのトラブルが起こることがあります。
これらの対処について解説します。
崩壊・色ずれなどを防ぐTips
LoRAを適用した画像が破綻したり着色がずれる場合、原因は学習率が高すぎる、画像の一貫性が欠如している、キャプションが過剰であるのいずれかです。
学習率はデフォルトでは0.0001になっていますが、下げることで安定することもあります。
キャプションについては最低限のキャプションをつけるようにしましょう。
例えば今回の例に用いた画像の場合、black hair, heterochromia, blue eye, red eyeのみをキャプションにすると品質が向上する可能性があります。
画像の一貫性について、例えば「金髪キャラを作りたいのに影の入り方で金髪の色味が違う」「髪型によって見えなくなる部分があるが学習枚数が少ない」などの場合、LoRAの学習がうまくいきにくいため、明るさなどを調整しましょう。
キャラクターLoRAでは上記の部分が問題となることが多いですが、作りたいLoRAによって画像の選び方は異なります。水彩風LoRAなどでは、鉛筆やアニメ塗りなどの絵がノイズになってしまうため、同じ画風の画像を選びましょう。
LoRAを配布する場合のマナーとライセンス
LoRAを配布する際は、元画像の著作権やライセンスに注意が必要です。
自分で生成した画像で作成したLoRAでも、もともとのライセンスに「このモデルを使った生成物を配布する場合にはクレジット表記が必要」など書いてある場合があります。利用する画像やツールの規約を必ず確認し、従いましょう。特に二次創作LoRAは元作品の規約に注意してください。
LoRAを配布する際にはCivitaiなどの共有サイトの利用が一般的です。使用条件・学習元の明記・サンプル画像の添付を忘れずに行ってください。
まとめ
今回は、ConoHa AI Canvasを使ってLoRAを作成する方法をご紹介しました。
必要な画像やキャプションの用意、学習設定、出力までの一連の流れを丁寧に解説しました。初めてでもConoHa AI Canvasを使うことで、簡単にLoRAを作成できます。
LoRAの学習と聞くと「難しそう」「高性能な環境が必要そう」と感じるかもしれませんが、実際には30枚程度の画像と適切な設定があれば、十分に高品質なLoRAを作ることが可能です。
自分だけのキャラクターやスタイルを形にして、Stable Diffusionの世界をさらに広げていきましょう。
\ MiraLab AIの読者限定で500円割引適用中 /