

ElevenLabsのScribe v2とは、高精度な文字起こしが可能なバッチ処理専用モデルです。
音声や動画のファイルからの文字起こしができ、議事録作成や字幕生成などを効率的に行えるようになります。
この記事では、Scribe v2の使い方や料金プラン、Scribe v2 Realtimeとの主な違いについて解説します。
\ 無料プランでお試し /
ElevenLabsのScribe v2とは?

まずはElevenLabsのScribe v2の概要について解説します。

Scribe v2の位置づけ
Scribe v2は、ElevenLabsが提供する音声認識モデルの中でも、最高の精度と信頼性を重視して設計されたバッチ処理専用のモデルです。リアルタイム性よりも正確さを優先する議事録作成や字幕生成、長時間の録音データの分析といった用途に最適化されています。
業界標準のベンチマークにおいて極めて低い単語誤り率を記録しており、複雑な音声や背景ノイズがある環境でも安定した結果を出力します。
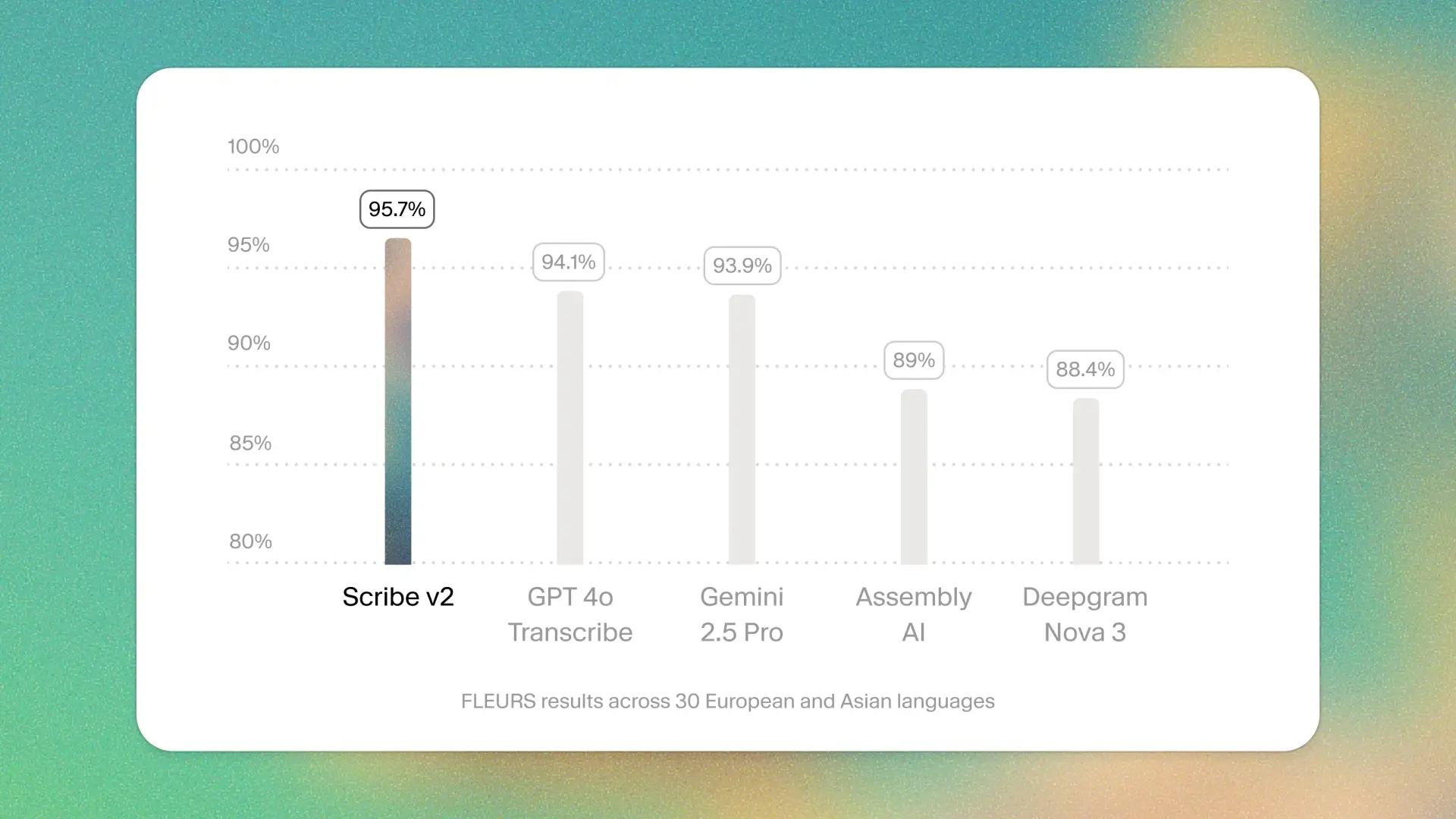
そのため、動画制作における字幕付けや、企業のコンプライアンス監査用ログのテキスト化など、事後処理としての利用でその真価を発揮します。
既存のリアルタイムモデルとは異なり、処理時間をかけて文脈を深く解析することで、高品質なトランスクリプトが提供可能です。
キータームプロンプトの概要
キータームプロンプトは、特定の専門用語や製品名、人名などを最大100個まで登録し、認識精度を向上させるための仕組みです。
従来の単なるキーワード登録とは異なり、Scribe v2は文脈を理解した上でその用語を適用すべきかどうかを判断します。例えば、同音異義語や独自の綴りを持つブランド名であっても、前後の会話の流れから正しい表記を選択することが可能です。
これにより、医療や法務、技術分野などの専門性が高いコンテンツでも、修正の手間を大幅に削減できます。
また、社内の固有名詞であっても正確に文字起こしできるようになり、手作業での修正を減らせます。
なお、この機能を使用する場合は追加料金がかかる点に注意が必要です。
エンティティ検出の概要
エンティティ検出は、音声データに含まれる個人情報や機密情報を自動的に特定し、その出現時間(タイムスタンプ)とともに検出する機能です。
氏名、住所、電話番号、クレジットカード番号、社会保障番号など、最大56種類のカテゴリから検出対象を指定することができます。
この機能により、大規模な機密情報のレビューやマスキング処理などが容易になり、自動化も可能となります。
自動多言語トランスクリプション
Scribe v2は90以上の言語に対応しており、音声ファイル内に複数の言語が混在している場合でも自動的に識別して文字起こしを行います。話者が途中で言語を切り替えたとしても、事前の設定なしにシームレスに認識し続けることが可能です。
この機能により、国際会議の録音や多言語インタビュー、海外コンテンツのローカライズ作業で言語ごとに分割してから文字起こしする手間が減り、劇的に効率化されます。
手動で言語セグメントを分ける必要がないため、グローバルなビジネスシーンや多文化共生社会におけるコミュニケーション記録に最適です。
追加の主要機能
Scribe v2には、誰がいつ話したかを識別する話者分離機能が含まれており、最大48人までの話者を区別することが可能です。
また、単語レベルで正確なタイムスタンプが付与されるため、動画編集ソフトと連携した字幕の同期や、特定のフレーズの検索が容易になります。
さらに、ダイナミック音声タグ機能により、拍手や笑い声、音楽といった非言語音も認識し、音声全体のコンテキストをより豊かに表現します。
これらのメタデータは、テキスト情報だけでは伝わらない現場の雰囲気やニュアンスを保存するのに役立ちます。高精度なテキストと詳細な付加情報の組み合わせが、アーカイブの価値を高めます。
UIで使える範囲とAPIでできることの整理
WebブラウザからアクセスできるStudio(UI)は、プログラミング知識がなくても直感的にファイルをアップロードし、字幕生成や翻訳を行える環境を提供しています。
一方、APIはシステムへの組み込みを前提としており、大量のファイルを自動処理したり、独自のアプリケーションに音声認識機能を統合したりする場合に使用されます。
UIでは基本的な設定と結果のダウンロードが主ですが、APIではキータームプロンプトやエンティティ検出といった高度なオプション機能をフルに活用できます。
クリエイターはUIで手軽に制作を行い、開発者はAPIでスケーラブルな自動化ワークフローを構築するという使い分けが想定されています。
なお、どちらのインターフェースも同一の高精度モデルを利用しているため、設定や条件が同じであれば品質に差はありません。
\ 無料プランでお試し /
ElevenLabsのScribe v2とScribe v2 Realtimeの違い

ElevenLabsにはScribe v2に加え、Scribe v2 Realtimeというモデルも存在します。
ここでは、これら2つのモデルの違いについて解説します。
Scribe v2 Realtimeの主要な特徴
Realtimeモデルは、ユーザーの発話区間を検知するVAD(Voice Activity Detection)を内蔵しており、無音区間をカットして効率的に処理を行います。
また、テキストコンディショニング機能により、直前の会話内容や文脈をモデルに引き継がせることで、途切れない自然な文字起こしを実現します。
さらに、手動コミット機能を使用すれば、開発者が任意のタイミングでテキストを確定させることができ、字幕の表示タイミングなどを細かく制御可能です。
これらの機能は、人間とAIが自然に会話するための即時性と制御性を高めるために実装されています。
Scribe v2とScribe v2 Realtimeの主な違い
Scribe v2とScribe v2 Realtimeの最大の違いは、処理の「タイミング」と「目的」にあります。
Scribe v2は、録音済みのデータを時間をかけて最高精度で解析するバッチ処理型で、アーカイブや字幕作成に向いています。
対してRealtimeは、通話や音声対話エージェントのために開発されたストリーミング型で、150ms未満という超低遅延で即座にテキストを返します。
it transcribes speech in under 150 ms across English, French, German, Italian, Spanish, and Portuguese, and 90 languages.
出典:Introducing Scribe v2 Realtime
前者は正確さと分析の深さを、後者はスピードとレスポンスの良さを最優先事項としています。用途の中心が確定版生成であればScribe v2、リアルタイム応答ならRealtimeを選ぶのがいいでしょう。
Scribe v2とScribe v2 Realtimeの比較表
Scribe v2とScribe v2 Realtimeは、それぞれ「高精度の記録」と「即時応答」という異なる目的に特化しています。
以下の表は、どちらのモデルを採用すべきかを判断するための主な違いをまとめたものです。
| 項目 | Scribe v2 | Scribe v2 Realtime |
|---|---|---|
| 主な用途 | 議事録作成、動画字幕、コールログ分析 | AIボイスエージェント、ライブ字幕、同時通訳システム |
| 優先事項 | 認識精度と分析の深さ | 応答速度 |
| 処理方式 | HTTPリクエストによるファイル送信 | WebSocketによる双方向ストリーミング |
| 遅延 | 非同期 | 150ms未満(※アプリ/ネットワーク遅延を除く) |
| 入力形式 | 音声/動画ファイル | オーディオストリーム |
| 主要機能 | キータームプロンプト エンティティ検出 話者分離 | VAD テキストコンディショニング 手動コミット |
Scribe v2は、用途が字幕・議事録・データ分析であり、ファイルアップロード形式で処理を行い、遅延は考慮されませんが文脈理解や話者分離といった機能が充実しています。
一方、RealtimeはAIエージェントやライブ字幕を用途とし、WebSocketによるストリーミング形式で、150ms未満の応答速度を実現していますが、分析機能は軽量化されています。
入力形式も、Scribe v2はmp3やwavなどの完全なファイル、RealtimeはPCMなどのオーディオストリームを受け付けます。
運用面では、Scribe v2は非同期のシステム連携、Realtimeは常時接続の対話システムに適しています。
ユースケース別の選び方
録画された会議の議事録作成や、YouTube動画への字幕付けであれば、精度が高く話者分離も可能なScribe v2がおすすめです。
また、過去のコールセンターの通話ログを一括分析する場合も、エンティティ検出が使えるScribe v2が適しています。
一方で、AIボイスボットを使って顧客対応を行う場合や、ライブ配信にリアルタイムで字幕を付ける場合は、遅延の少ないScribe v2 Realtimeが必要です。
ユーザーが「今話していること」を処理するならRealtime、「過去に話したこと」を処理するならScribe v2という基準で選定しましょう。
2つのモデルの併用パターン
高度なシステムでは、両方のモデルを組み合わせて利用するパターンも有効です。
例えば、ライブイベント中にはRealtimeモデルを使って遅延なく速報字幕を表示し、イベント終了後に録音データをScribe v2で再処理して、より高精度なアーカイブ用字幕を作成します。これにより、リアルタイムの即時性とアーカイブの品質という両方のメリットを享受できます。
また、AIエージェントの対話にはRealtimeを使い、会話終了後のログ分析やCRMへの記録にはScribe v2を使うことで、顧客体験とデータ品質の両立が可能になります。
迷った時の結論
どのモデルを使うべきか迷った場合、まずはリアルタイム性が必要かどうかを考えましょう。
遅延の少ない応答が必要な対話システムを構築する場合は、Realtimeを選択する必要があります。
一方、遅延を気にしない用途であれば、基本的には精度の高いScribe v2を選択するのが無難であり、満足度の高い結果が得られます。特に日本語を含む多言語環境や、専門用語が多いビジネスシーンでは、Scribe v2の文脈理解力が大きな助けとなります。
コストと精度のバランスを見る場合も、修正の手間を考慮すればScribe v2のコストパフォーマンスは非常に高いと言えるでしょう。
\ 無料プランでお試し /
ElevenLabsのScribe v2の使い方

続いて、ElevenLabsのScribe v2の使い方をご説明します。
使い方の全体フロー
Scribe v2を利用する方法は、手動操作を中心としたWeb UIと、システム連携を行うAPIの2つに大別されます。
UI運用は単発のファイル処理や視覚的な確認が必要な場合に適しており、アカウントにログインしてすぐに作業を開始できます。
API実装は、アプリやWebサービスに文字起こし機能を組み込む場合や、大量の過去データを一括処理する場合に選択されます。
どちらの方法でも、まずは音声データを準備し、目的に応じた設定を行った上で処理を実行するという基本構造は変わりません。最終的な出力形式はテキスト、SRT字幕ファイル、JSONなどから用途に合わせて選択します。
UIでの基本手順
UIでScribe v2を使う手順は以下の通りです。
「ファイルを文字起こし」をクリックし、音声または動画ファイルをアップロードします。
今回はSora 2で生成した以下の動画をアップロードしました。
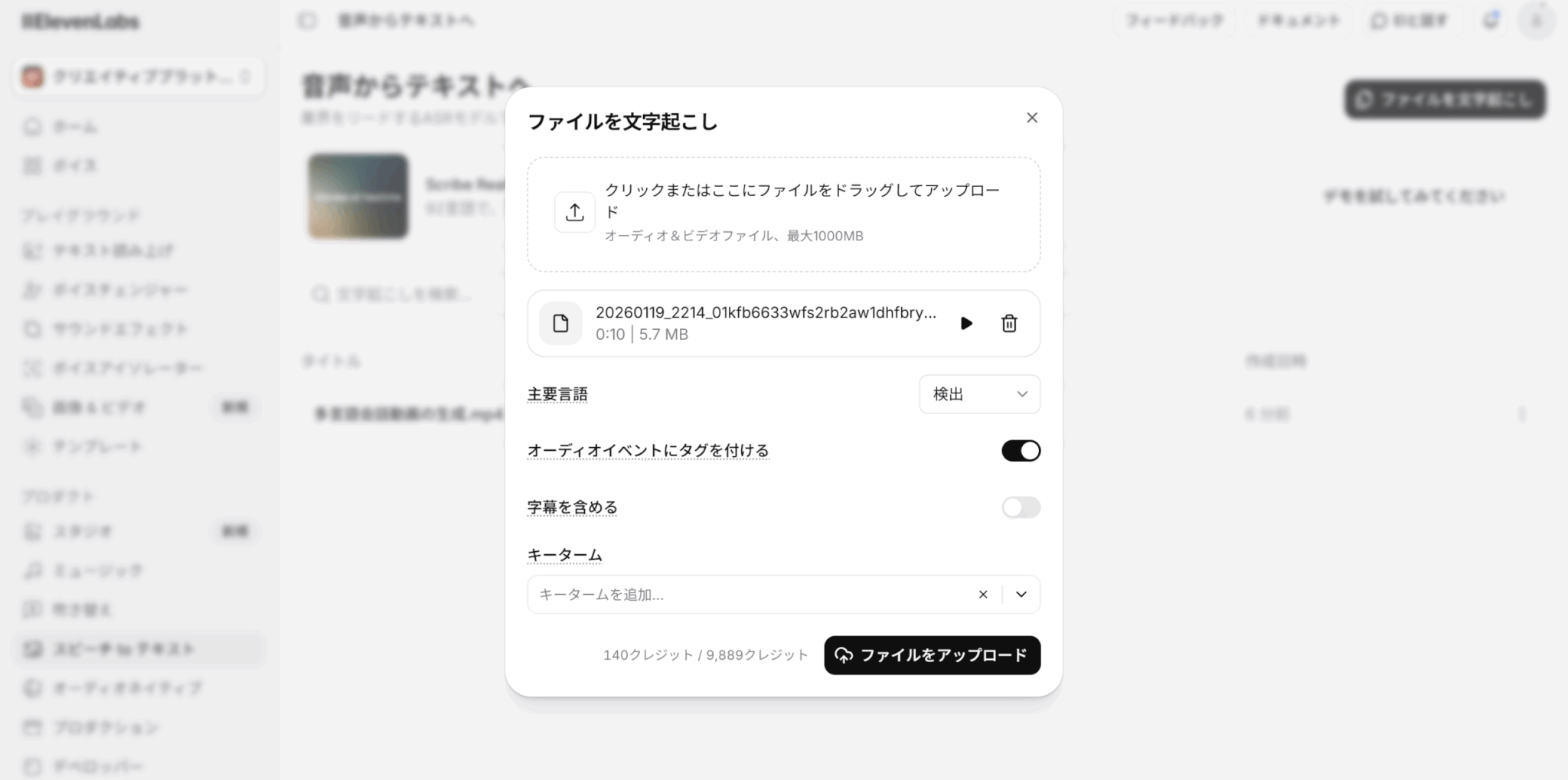
ファイルをアップロードする際、それぞれのオプションを選択します。
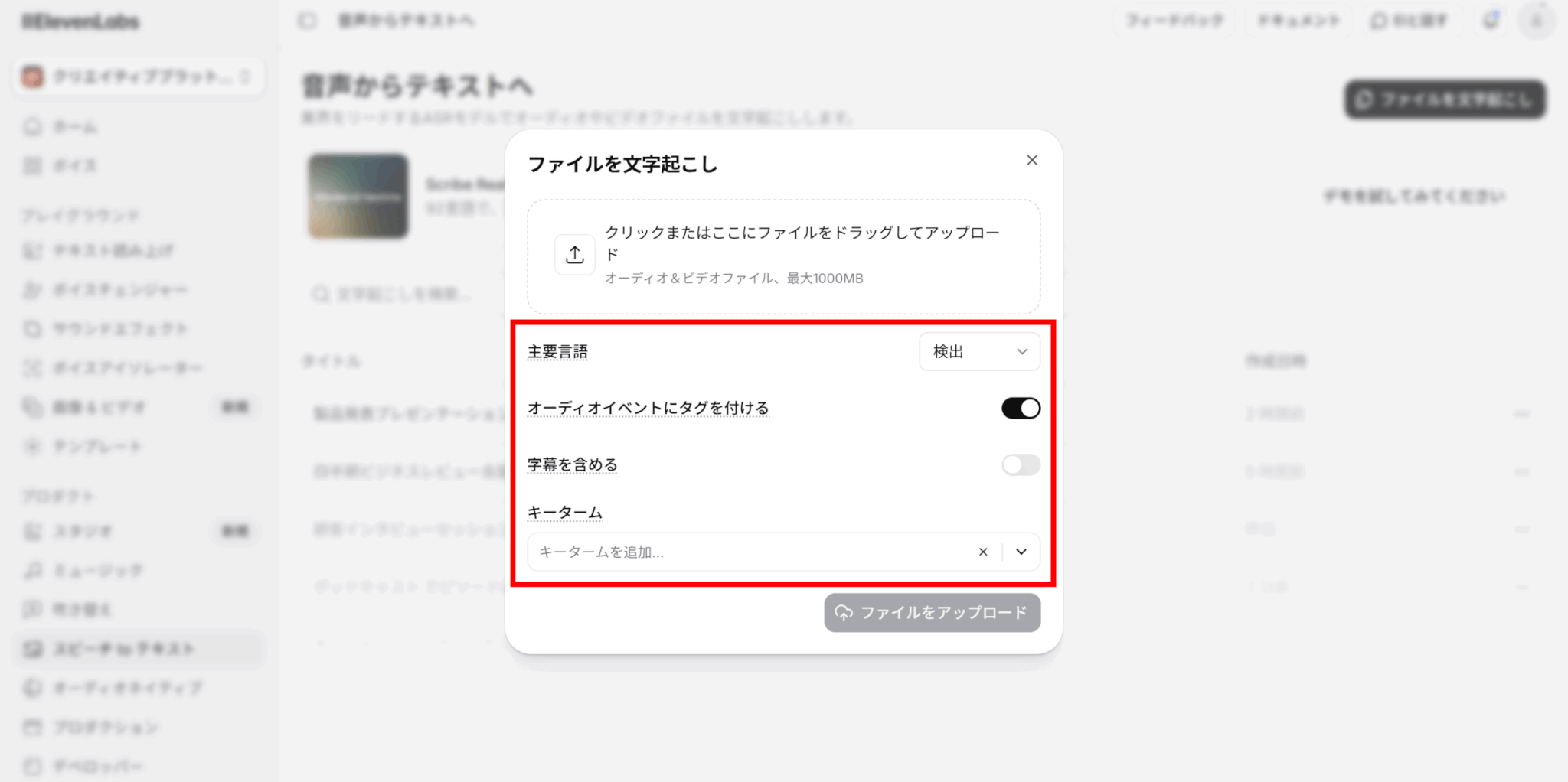
音声の主要な言語が分かっている場合は、その言語を選択しましょう。「検出」を選んでいる場合は、言語が自動で検出されます。
「オーディオイベントにタグを付ける」をオンにすると、笑い声や拍手などの音声イベントにタグを付けることができます。
キータームプロンプトもここで設定しましょう。
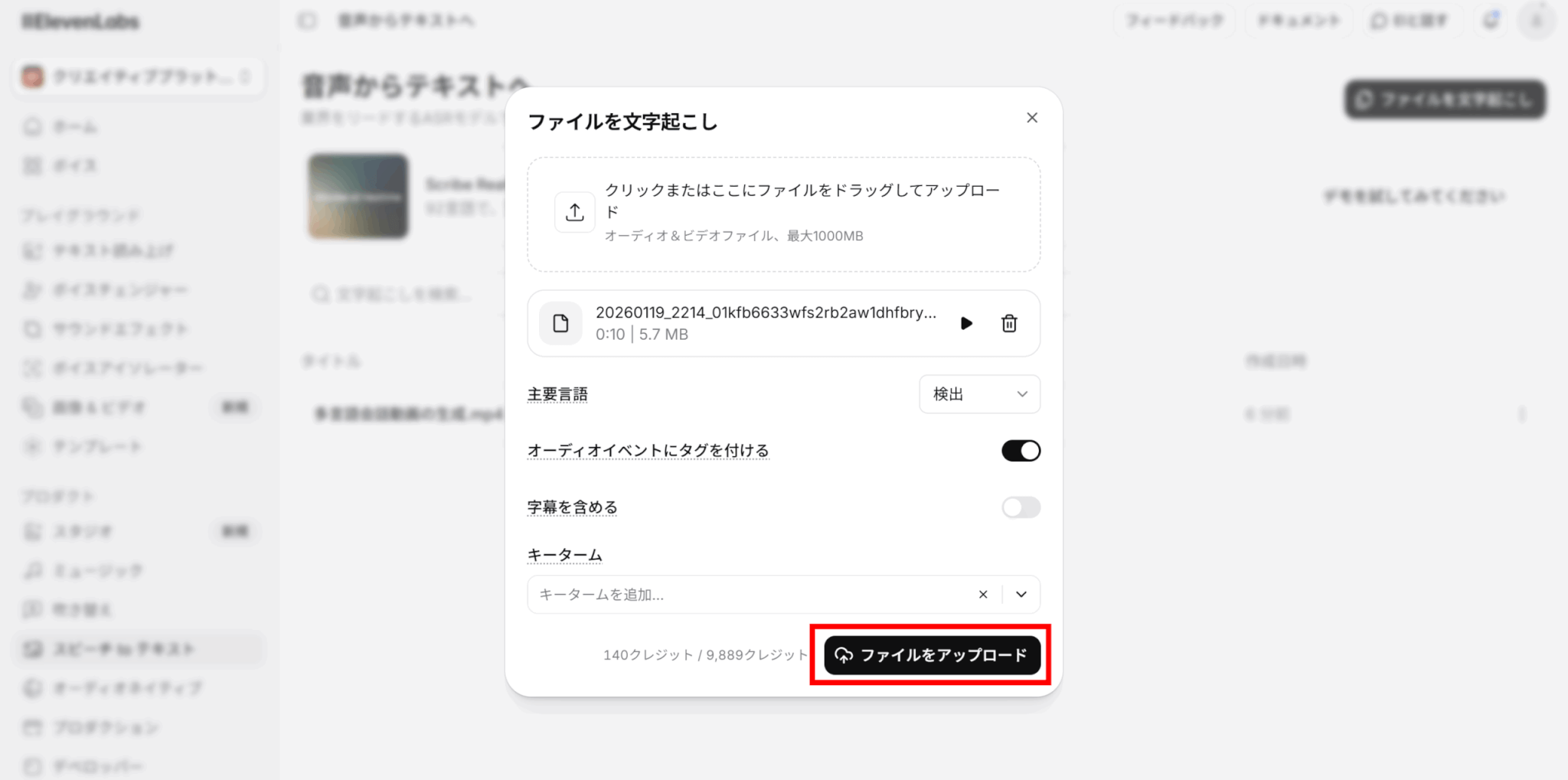
オプションの設定が完了したら、「ファイルをアップロード」をクリックします。
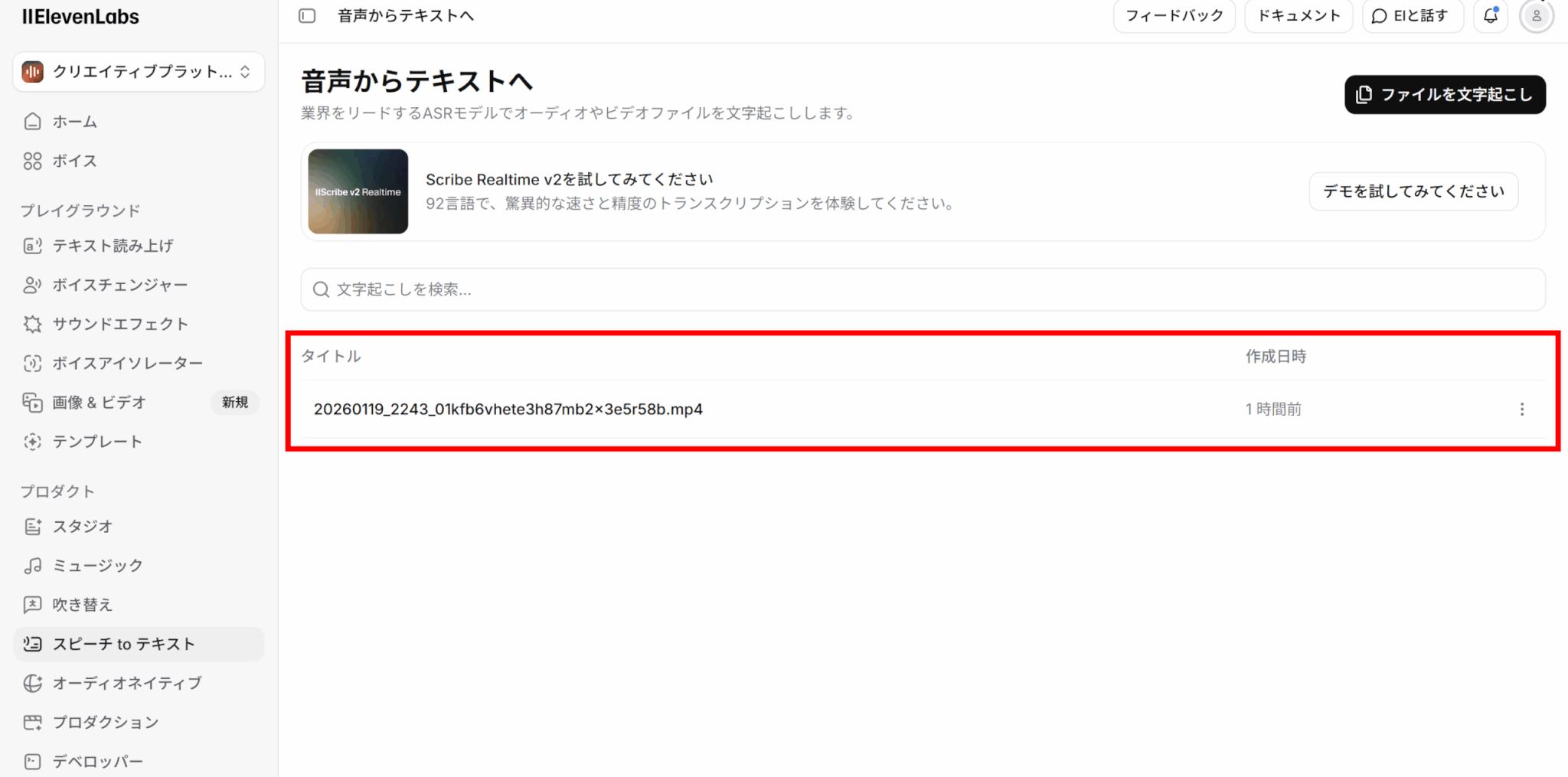
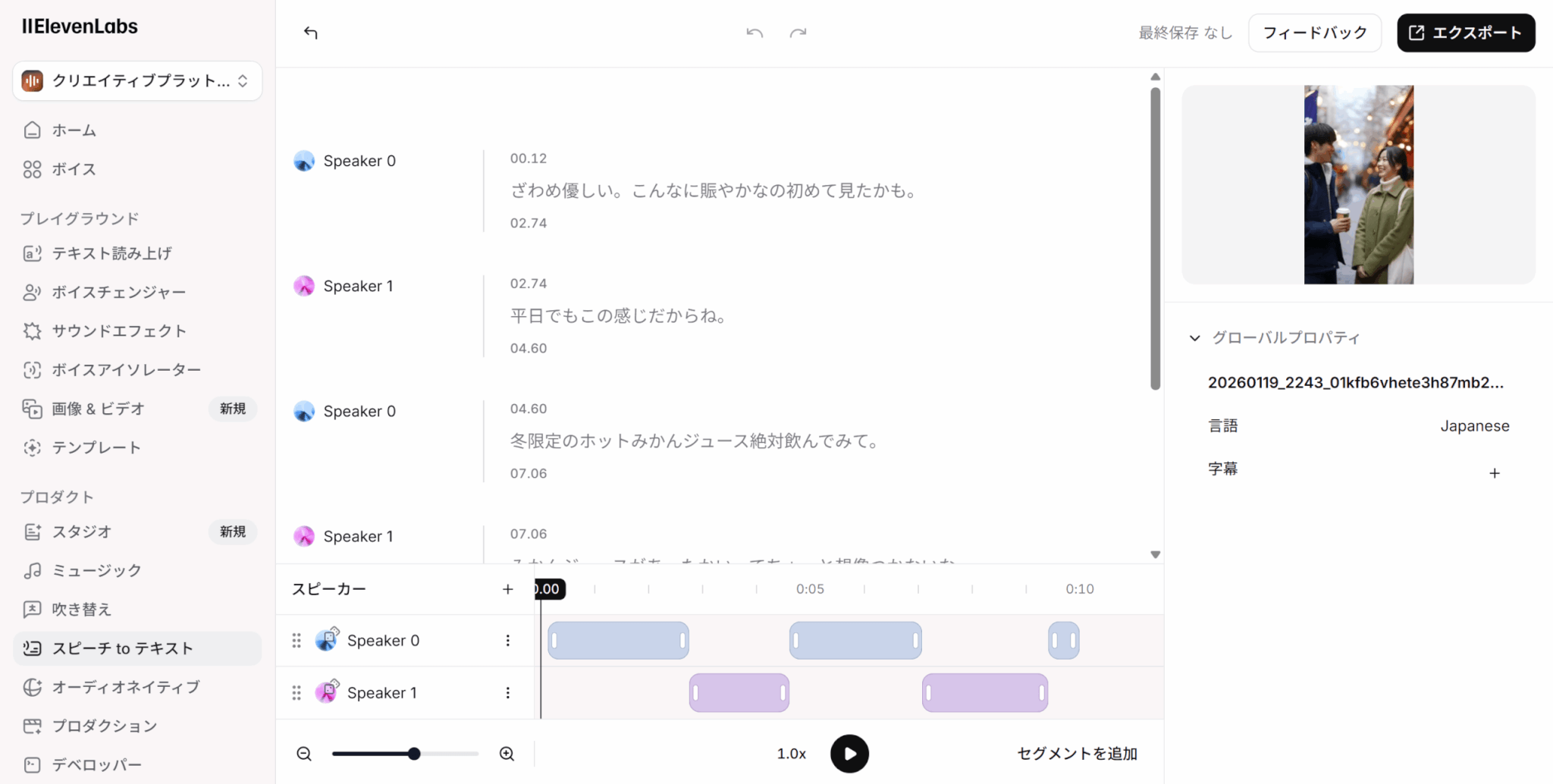
アップロードすると、画面下部にアップロードしたファイル名が表示されます。ここをクリックすると、処理結果を見ることができます。
今回は、以下のように文字起こしされました。正確な文字起こしと話者分離ができていることが分かります。
APIでの基本手順
続いて、APIでScribe v2を使う手順を解説します。なお、この記事ではPythonを使って実装していきます。
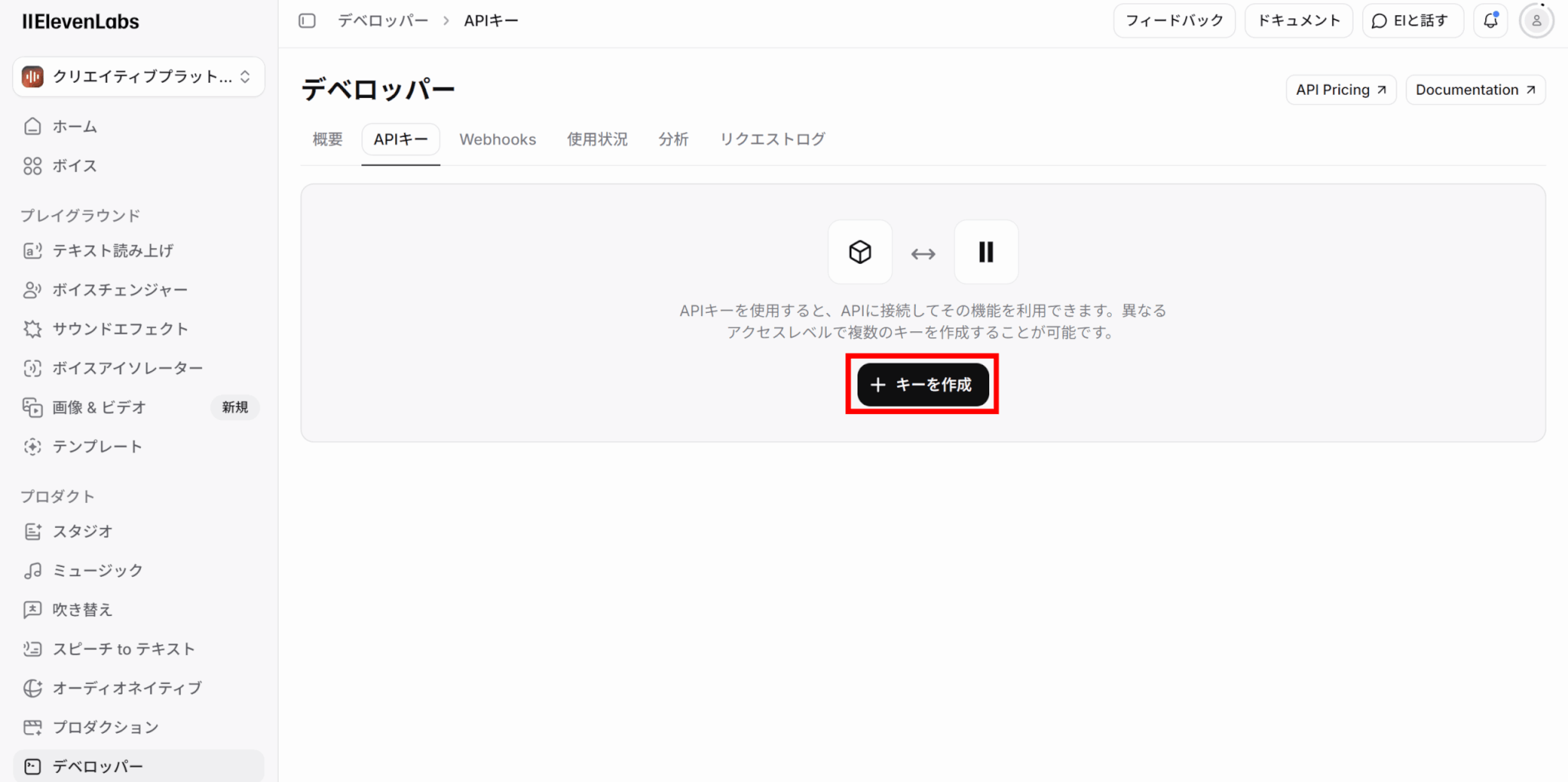
APIキーのダッシュボードに移動し、「キーを作成」をクリックしてAPIキーを作成します。
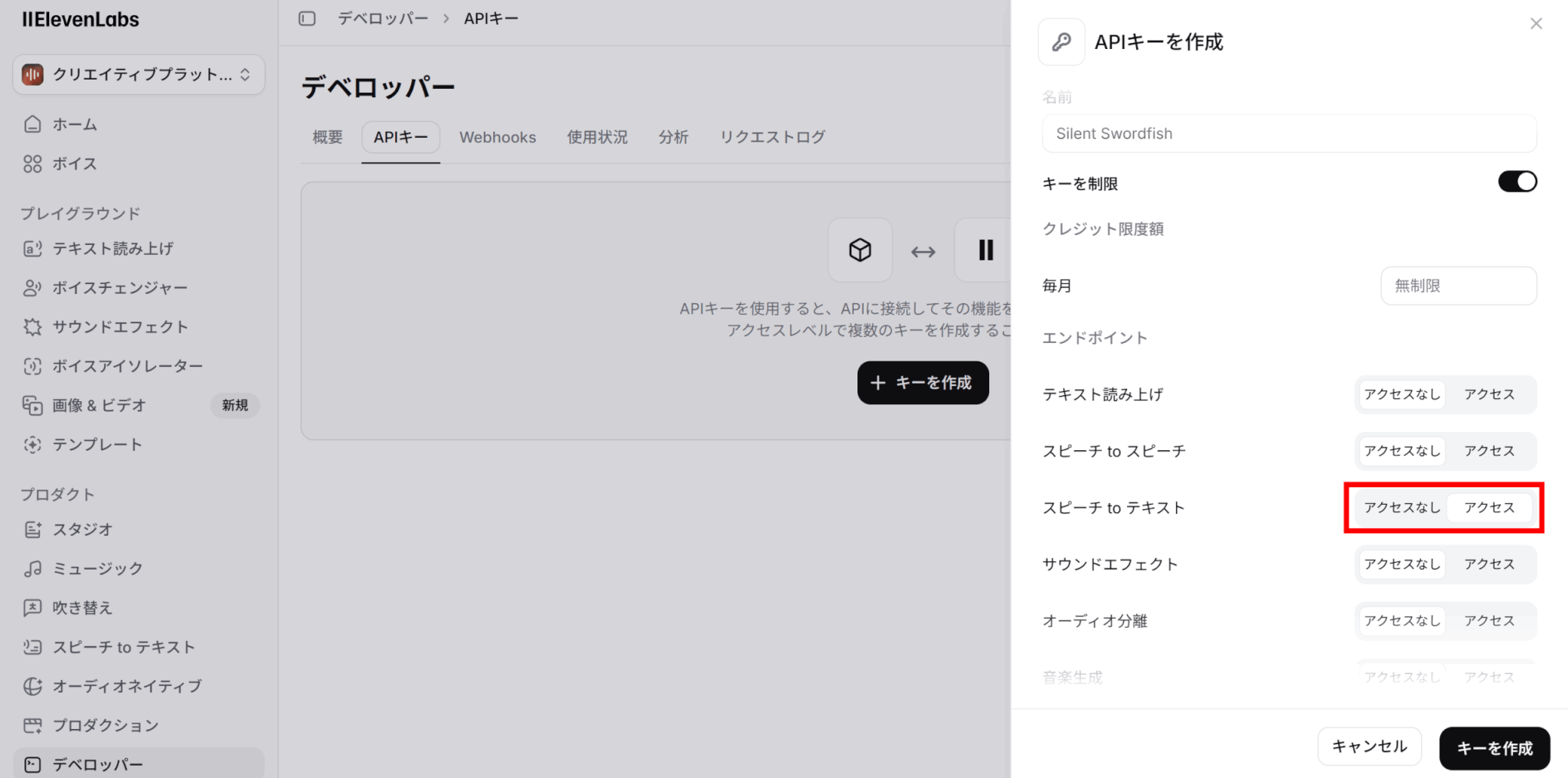
キーの名前を入力し、権限などの設定をします。ここでは「スピーチ to テキスト」のアクセスを許可します。
「キーを作成」をクリックすると、APIキーが作成されます。
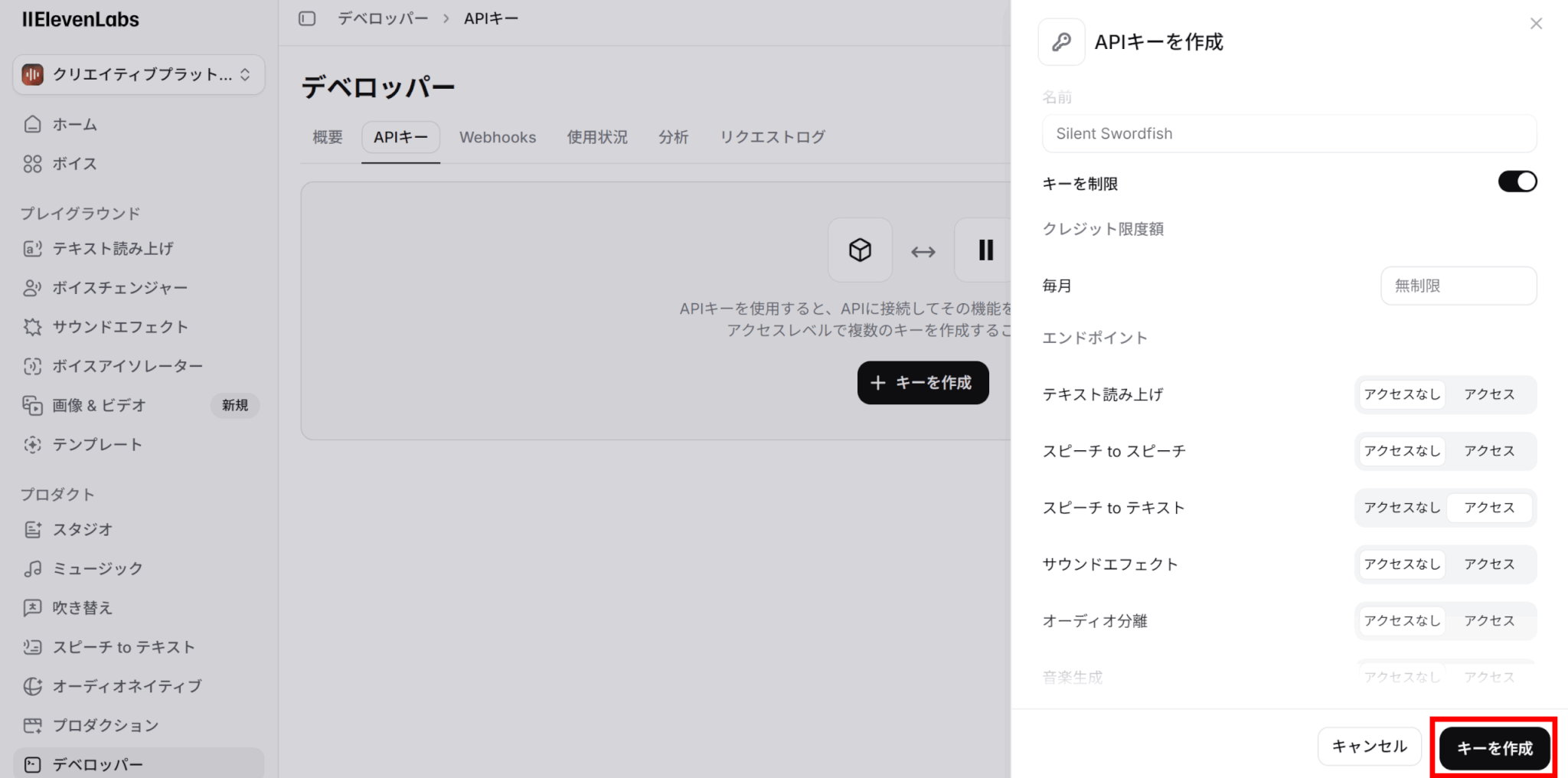
表示されたAPIキーをコピーし、安全な場所に保管しておきましょう。一度閉じると二度とキーを見ることはできないため注意してください。
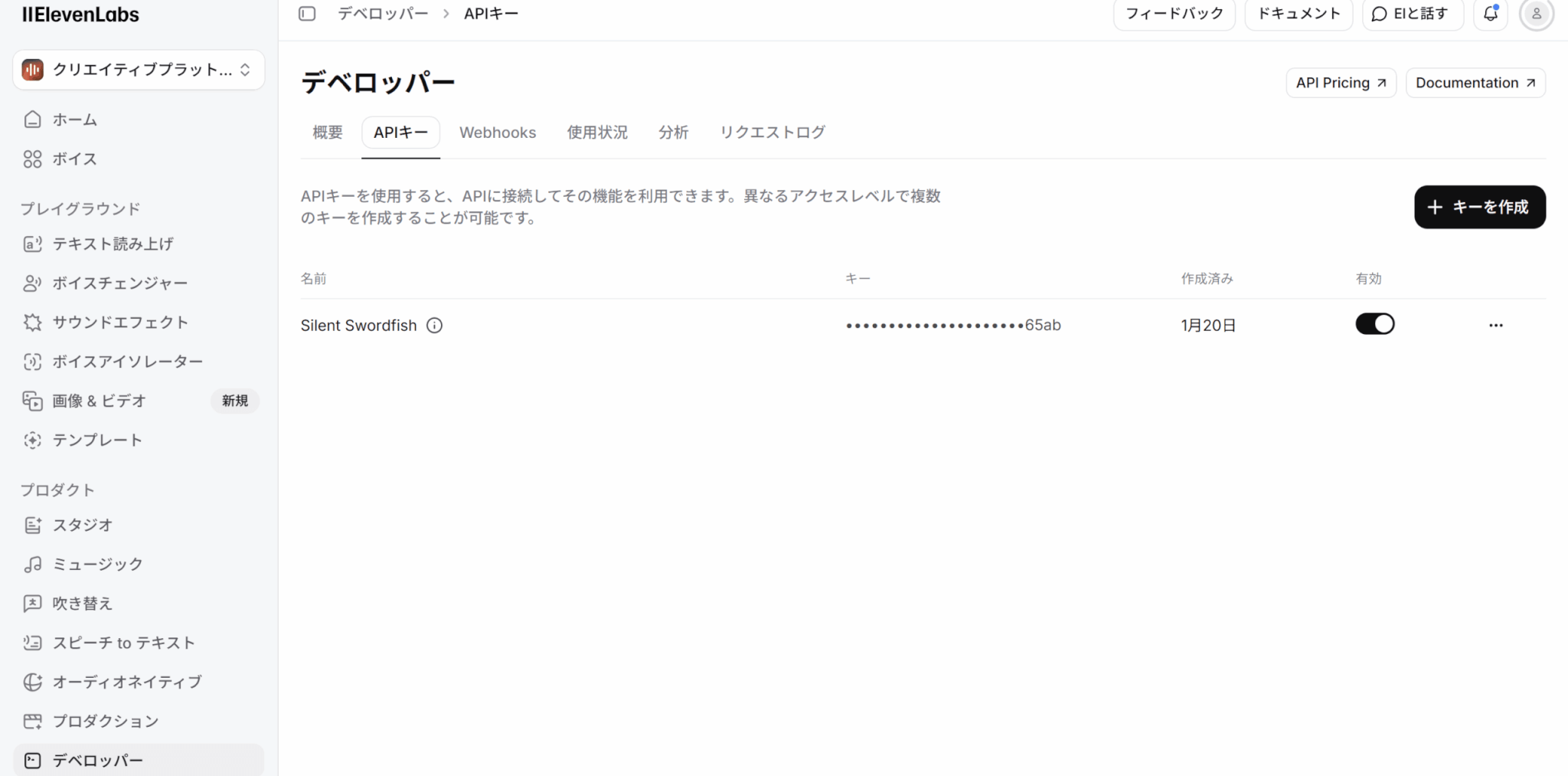
作成したAPIキーをプロジェクトの環境変数として設定します。
.envファイルに以下の文を追記してください。
ELEVENLABS_API_KEY=<your_api_key_here>ターミナルで以下のコマンドを実行して、ElevenLabsのSDKをインストールします。
pip install elevenlabsまた、dotenvが入っていない人はこちらもインストールしておきましょう。
pip install python-dotenvコードファイルを作成し、コード内でAPIリクエストを行います。
以下のようにコードを記述することで、APIを使用して文字起こしができます。
import os
from dotenv import load_dotenv
from io import BytesIO
import requests
from elevenlabs.client import ElevenLabs
load_dotenv()
elevenlabs = ElevenLabs(
api_key=os.getenv("ELEVENLABS_API_KEY"),
)
audio_url = (
"https://storage.googleapis.com/eleven-public-cdn/audio/marketing/nicole.mp3"
)
response = requests.get(audio_url)
audio_data = BytesIO(response.content)
transcription = elevenlabs.speech_to_text.convert(
file=audio_data,
model_id="scribe_v2", # 使用するモデル
tag_audio_events=True, # 笑い声や拍手などのオーディオイベントにタグを付ける
language_code=None, # 音声ファイルの言語。Noneに設定すると、モデルが自動的に言語を検出する
diarize=True, # 誰が話しているかを注釈するか
)
print(transcription)“model_id”はscribe_v2を指定しましょう。
コードができたら、実行してみましょう。
先ほどのコードの実行結果が以下の通りです。
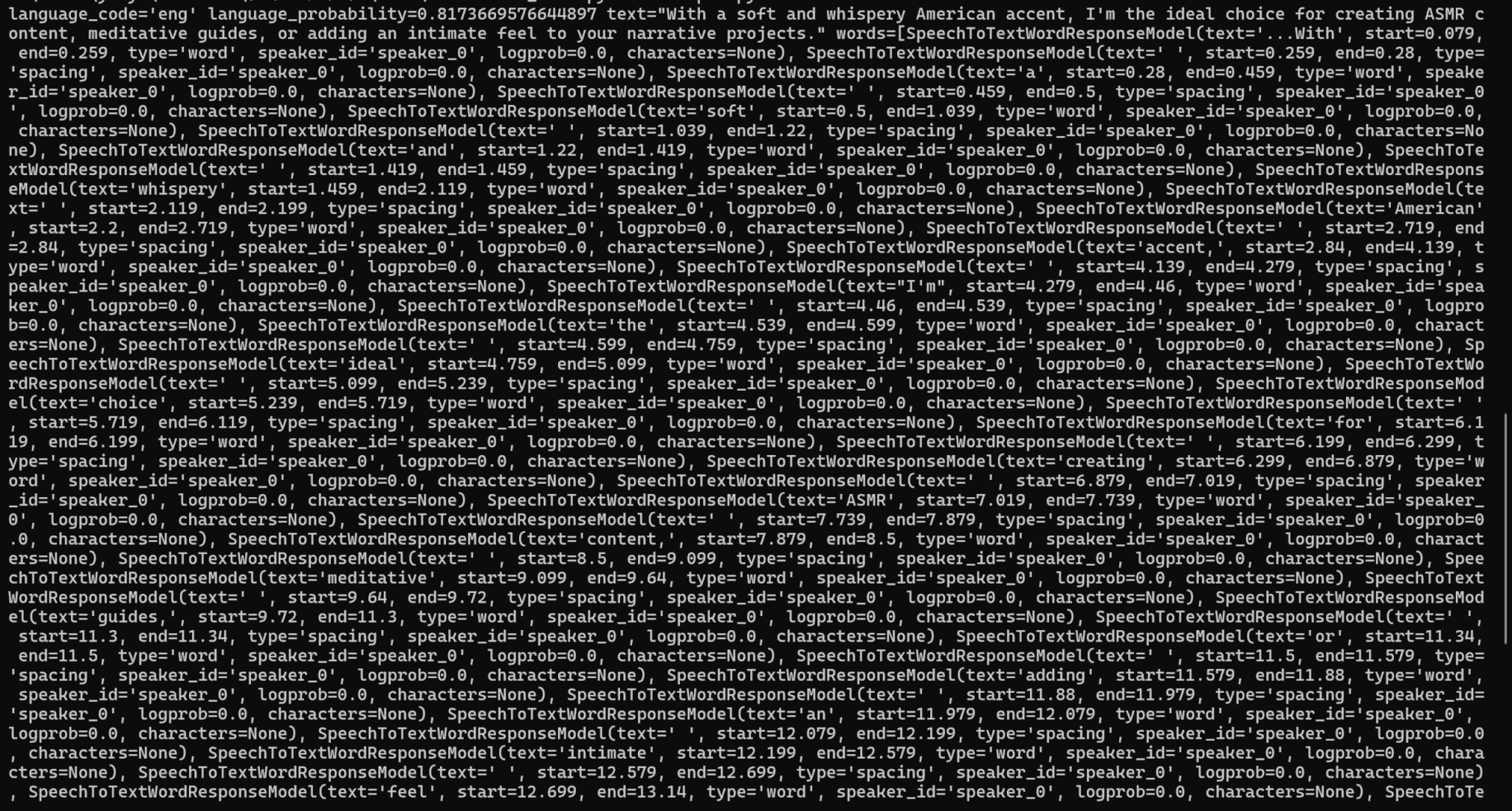
精度と運用性を上げる要点
認識精度を最大化するためには、録音環境を整え、可能な限りノイズの少ないクリアな音声データを用意することが基本です。
その上で、業界特有の用語や固有名詞が多い場合は、キータームプロンプト機能を活用してモデルに事前の知識を与えましょう。
また、複数人が話すシナリオでは、マイクのチャンネルを分けたり、話者が重ならないように会話を整理したりすることで、話者分離の精度が向上します。
音声ファイルの前処理として音量レベルを正規化することも、認識エラーを減らす有効な手段です。
これらの技術的・運用的な工夫を組み合わせることで、修正工数を最小限に抑えることができます。
大量処理の考え方
長尺の音声データや大量のファイルを処理する場合、サーバーへの負荷分散とエラーハンドリングを考慮した設計が必要です。
APIを利用する際は、リクエストを投げた後に処理完了を通知するWebhooksの仕組みを活用し、ポーリングによる無駄な通信を削減します。
また、ネットワークエラーや一時的な障害に備えて、自動的な再試行ロジックを組み込むことが重要です。処理結果やエラーログをデータベースに記録しておくことで、どのファイルがいつ処理されたかを追跡でき、監査やコスト管理にも役立ちます。
スケーラブルなパイプラインを構築することで、安定した大量処理が実現します。
\ 無料プランでお試し /
ElevenLabsのScribe v2の料金プラン

次に、ElevenLabsでScribe v2を使用するために必要な料金についてご紹介します。
すべて2026年1月時点の情報です。最新の料金は公式サイトも合わせてご確認ください。
料金体系の全体像
ElevenLabsの音声認識料金は、基本的にプラン料金であり、超過分は処理した音声の長さに基づく従量課金制となります。
サブスクリプションプランには毎月一定のクレジットが付与され、Scribe v2の利用分もクレジットから差し引かれます。UIからの利用とAPIからの利用で消費レートや単価が異なるため、自身の契約プランの詳細を確認しましょう。
Realtimeモデルとバッチ処理のScribe v2は異なる単価設定になっており、用途に応じたコスト試算が求められます。また、上位プランになるほど、超過分の単価が割安になる傾向があります。
各プランの料金とクレジットの比較は以下の通りです。クリエイター以上のプランでは、追加で料金を支払うことでより多くの利用が可能となります。
| 対象 | プラン | 月額料金 | 月間クレジット |
|---|---|---|---|
| 個人 | 無料 | $0 | 10,000 |
| スターター | $5 | 30,000 | |
| クリエイター | $22 | 100,000 | |
| プロ | $99 | 500,000 | |
| ビジネス | スケール | $330 | 2,000,000 |
| ビジネス | $1,320 | 11,000,000 |
なお、ビジネス向けでは機能や料金を細かくカスタムできるエンタープライズプランもあります。

UI利用枠の考え方
Scribe v2をUIで利用する場合のプラン別の利用枠は以下の通りです。
| 対象 | プラン | 利用可能時間 | 追加1時間あたりの料金 |
|---|---|---|---|
| 個人 | 無料 | 12分 | ー |
| スターター | 1時間 | ー | |
| クリエイター | 4時間53分 | $4.5 | |
| プロ | 24時間45分 | $4 | |
| ビジネス | スケール | 94時間17分 | $3.5 |
| ビジネス | 440時間 | $3 |
UIの利用はAPI利用と比べてクレジットの消費量が多く、追加で利用する場合も1時間あたりの料金が高く設定されています。
また、チームで利用する場合、複数のメンバーが同じワークスペースのクレジットを共有することになるため、一人の大量利用が全体の残高に影響します。
管理者は、月初のクレジット付与タイミングと現在の消費ペースを把握し、必要に応じてプランのアップグレードや制限を検討する必要があります。
API利用枠の見方
Scribe v2をAPIで利用する場合のプラン別の利用枠は以下の通りです。
| 対象 | プラン | 利用可能時間 | 1時間あたりの料金 | 追加1時間あたりの料金 | エンティティ検出 | キータームプロンプト |
|---|---|---|---|---|---|---|
| 個人 | 無料 | 2時間30分 | $0 | ー | ー | ー |
| スターター | 12時間30分 | $0.4 | ー | $0.08/時間 | $0.12/時間 | |
| クリエイター | 62時間51分 | $0.35 | $0.48 | $0.07/時間 | $0.11/時間 | |
| プロ | 300時間 | $0.33 | $0.4 | $0.07/時間 | $0.1/時間 | |
| ビジネス | スケール | 1100時間 | $0.3 | $0.33 | $0.06/時間 | $0.09/時間 |
| ビジネス | 6000時間 | $0.22 | $0.22 | $0.04/時間 | $0.07/時間 |
上位プランになるほど1時間あたりの料金は安くなり、枠を超過した場合の追加料金についても上位プランの方が安価になります。
また、Scribe v2の高度な機能であるキータームプロンプトやエンティティ検出は基本料金に対するアドオン課金として扱われます。
キータームプロンプトを利用すると基本単価の約30%、エンティティ検出を利用すると約20%が加算される仕組みです。これらを併用するとコストが増加するため、必要なファイルにのみオプションを適用する制御がコスト削減の鍵となります。
目的別のコスト見積もり例
議事録作成のように単なるテキスト化の場合は、基本機能のみを利用するため最も安価に済みます。
一方、字幕制作で専門用語の正確さが求められる場合はキータームプロンプトの費用を加算して見積もる必要があります。
また、コールセンターの解析業務などで個人情報の検出が必須となる場合は、基本料金に加えエンティティ検出のアドオン費用が発生し、トータルコストは高くなります。
月間100時間の処理を行う場合、どのオプションを有効にするかで数千円から数万円の差が生じる可能性があります。事前にサンプルデータでコスト感を掴んでおくことが推奨されます。
以下に、クリエイタープラン(月額$22)を契約した場合の目的別コスト試算を示します(API利用)。100時間あたりのコストでは、月額料金に加え、アドオン料金や追加利用時間のコストを加味して算出しています。
| 目的 | 機能構成 | 1時間あたりのコスト | 100時間(月間)あたりのコスト |
|---|---|---|---|
| 議事録 | 基本機能 | $0.35 | $39.83 |
| 専門動画の字幕 | 基本機能 キータームプロンプト | $0.46 ($0.35+$0.11) | $50.83 |
| コールセンター解析 | 基本機能 エンティティ検出 | $0.42 ($0.35+$0.07) | $46.83 |
| 医療・法務記録 | 基本機能 キータームプロンプト エンティティ検出 | $0.53 ($0.35+$0.11+$0.07) | $57.83 |
料金を比較検討する時の判断軸
料金を比較する際は、単なる1分あたりの単価だけでなく、修正にかかる人件費を含めたトータルコストで判断することが重要です。
安価で精度の低いモデルを使って修正作業に時間をかけるよりは、高精度なScribe v2を使用した方が、結果的に安上がりになるケースが多くあります。
また、リアルタイム処理が必要か、それともバッチ処理で良いかという遅延の許容度も大きな選定基準です。遅延要件が厳しい場合はRealtimeの低遅延とストリーミング機能が効きますが、確定版の品質はバッチ側で取り直す併用も現実的です。
データのセキュリティ要件や多言語対応の必要性も加味し、自社の運用フローに最も合うプランとモデルを選定すべきです。
\ 無料プランでお試し /
ElevenLabsのScribe v2の導入前チェックリスト

Scribe v2の導入をスムーズに進めるためには、まず扱う音声データの形式や平均的な録音時間、対応が必要な言語数を整理し、Scribe v2の技術仕様と合致しているかを確認しましょう。
次に、誰がどのタイミングでファイルをアップロードし、生成されたテキストをどのように確認・修正するかという具体的な運用フローを策定します。開発リソースが必要なAPI連携を行うか、手軽なWeb UIで完結させるかもこの段階で決定すべき重要な分岐点です。
料金面では、月間の想定利用時間に基づいて最適なプランを選定し、キータームプロンプトなどの有料アドオンを使用する場合の追加コストも漏れなく試算に含めます。
最後に、機密情報の取り扱いやデータの保存期間に関する規定を精査し、自社のセキュリティポリシーやGDPRなどのコンプライアンス要件を満たしているかを厳格にチェックすることが不可欠です。
特に個人情報を含むデータを扱う場合は、エンティティ検出機能による自動マスキングの必要性も併せて検討してください。
\ 無料プランでお試し /
まとめ
ElevenLabsのScribe v2は、高精度な文字起こしが可能な音声認識モデルです。
キータームプロンプト機能による認識精度向上や、エンティティ検出機能による個人情報の特定などにより、議事録の作成や字幕生成などを効率化可能です。
リアルタイム性が必要な場面に強いScribe v2 Realtimeと使い分けることで、文字起こしの自動化を図ることができます。
Web UIとAPIで利用することができ、無料でも使い始めることができるため、気になる方は実際にScribe v2の精度や機能を確かめてみてください。
\ 無料プランでお試し /