

TranslateGemmaとは、Gemma 3をベースとして翻訳タスクに最適化されたオープンモデル群です。55言語の翻訳を対象に設計され、2段階のファインチューニングにより翻訳品質が向上しています。
本記事ではTranslateGemmaの特徴や使いどころを紹介します。またTranslateGemmaの使い方ガイドとして具体的な実行手順や設計ポイント、料金・運用の考え方について解説します。
TranslateGemmaとは|翻訳特化のGemmaモデル

TranslateGemmaは、Googleが公開したGemmaベースのオープンモデル群です。4B/12B/27Bの3サイズで提供され、55言語の翻訳を対象に設計されています。
Geminiや他のGemmaシリーズと比較した際のTranslateGemmaの特徴や、活用方法のポイントについて解説します。
GemmaシリーズとTranslateGemmaの特徴
Googleから提供されているAIモデルのうち、Geminiは幅広い用途(対話、推論、マルチモーダル等)での利用が可能です。一方、Gemmaは利用者が自分の環境で扱えるオープンモデルとして公開されています。
そのGemmaシリーズの中でもTranslateGemmaは翻訳タスクに特化したモデル群です。日本語・英語・中国語・スペイン語等の55言語を翻訳対象として、現在は4B/12B/27Bの3サイズが提供されています。
TranslateGemmaはGemma 3をベースとし、翻訳性能を向上させるためにSFT(教師ありファインチューニング)とRL(強化学習)という2段階でファインチューニングが行われています。
SFTでは、手動で翻訳されたデータに加え、最先端モデルが生成したデータも取り込んだ大規模データが学習に利用されています。正解例を学習するため、翻訳として望ましい出力(意味の忠実さ、自然さ、表現の安定性など)が生成されやすくなります。
RLでは、翻訳品質を評価するスコアが最大となるように最適化を行います。TranslateGemmaでは、翻訳品質の自動評価でも使われるMetricX-QEやAutoMQM等を組み合わせ、モデルの出力がより文脈に即した正確さ・自然さを持つように学習されます。
- SFT(教師ありファインチューニング)…大規模データの学習により翻訳の忠実度を向上
- RL(強化学習) …より自然な翻訳を行うように学習
TranslateGemmaの翻訳性能は、WMT24++での自動評価と、WMT25テストセットによる人手評価(MQM)で検証されています。
WMT24++とは55言語ペアの翻訳に関するベンチマークで、複数言語に対して同一条件で比較しやすい点が特徴です。
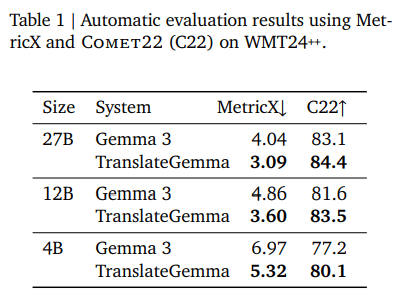
出典:TranslateGemma Technical Report
このWMT24++を用いて55言語ペアにわたる自動評価を行い、ベースラインのGemma 3モデルに対して一貫した改善が確認されています。人間によって評価されたWMT25のスコアについても同様に、多くの言語ペアでGemma 3よりもスコアが改善されています。
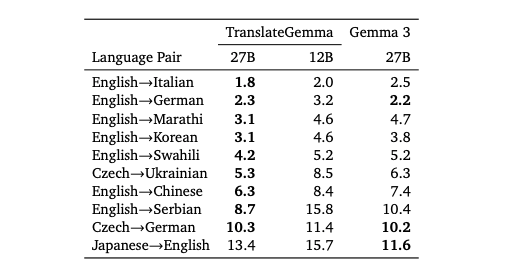
TranslateGemmaの特徴として、翻訳モデルでありながらGemma 3と同様にマルチモーダル能力を有しており、画像内の文字に対する翻訳も可能です。技術レポートでは、画像翻訳のベンチマークについてもGemma 3と比較してスコアが改善したことが述べられています。

【比較表】TranslateGemmaと汎用モデルの違い
翻訳・要約・対話・推論など1つのモデルで幅広いタスクに対応するモデルを「汎用モデル」と呼びます。汎用モデルとは異なり、TranslateGemmaは翻訳の品質・安定性を重視して、テキストや画像の翻訳タスクに特化した設計となっています。
TranslateGemmaと汎用モデルの違いを以下の通り整理しました。
| 項目 | TranslateGemma | 汎用モデル(Gemini/Gemma 3等) |
|---|---|---|
| 特徴 | 翻訳タスクに最適化 | 多用途(対話・要約・計算等) |
| 入力 | 翻訳専用テンプレートあり | 自由な形式で指示 |
| 出力 | 基本的に「翻訳結果」のみ | 会話形式が多く、入力された指示に従って出力 |
| 注意点 | 翻訳以外の用途については想定されていない | 翻訳用途の場合、出力形式等について詳細な指示が必要 |
AIに任せるタスクの自由度が高い場合には、汎用モデルの対応力の高さが活かされますが、翻訳タスクに限定する場合ではTranslateGemmaの方が利用しやすいと言えます。
TranslateGemmaの活用が向いているケース・向いていないケース
翻訳を主目的としてAIを活用したい場合には、TranslateGemmaの導入が向いています。
翻訳用プロンプトの使用により出力のばらつきが抑えられるため、特に「決まった形式の文章で安定して翻訳したい」という用途で強みを発揮します。具体的には、社内ドキュメントの多言語化、プロダクトや管理画面のUI翻訳などが挙げられます。
また、ローカル環境や自社クラウドで翻訳を内製化したい場合にも適しています。
TranslateGemmaはラップトップ、デスクトップでの実行も想定されており、機密情報を外部に送信せずに処理したいという要件を実現できます。オープンモデルであるため、用途に応じた検証(PoC)を行ったうえで採用判断をしやすい点もメリットです。
一方で、翻訳以外のタスクや自由な対話も必要な用途では、汎用モデルの方が適しています。
また、TranslateGemmaは総入力コンテキストが2,000トークンという制約がある点は注意が必要です。長い文書を一括で処理したい場合は分割しながら翻訳する設計を行うか、入力コンテキストの上限がより大きなモデルを利用することを検討しましょう。
- 向いているケース …AIの利用目的が翻訳のみ、外部に情報を送信したくない等
- 向いていないケース …AIに翻訳以外のタスクも対応させたい、入力が2,000トークンを超える長文となる等
TranslateGemmaのモデルサイズと選び方
TranslateGemmaでは現在、4B/12B/27Bの3サイズが公開されています。
「B」は「Billion(10億)」を意味しており、パラメータ数(学習済み重みの数)を表します。一般的にパラメータの数が増えるほど「表現力(難しい文脈・語彙・例外処理への対応等)」が向上する一方で、モデルの実行に必要なメモリサイズや計算量が増え、遅延・コストも増加する傾向にあります。
つまりモデルサイズの選択では、翻訳品質・スループット等の翻訳性能と、翻訳にかかる時間・計算コスト等の適切なバランスを見極めることが重要です。
| モデルサイズ | モデルの位置づけ | 想定されるユースケース |
|---|---|---|
| 4B | コスト効率がよい 12Bモデルに匹敵する翻訳性能 | 検証・PoCで手軽にモデルを実行したい スループット数を重視 エッジ/オンプレ/小規模GPUでの翻訳 |
| 12B | コストと性能のバランス型 ベンチマークでGemma 3(27B)よりも高いスコアを示す | 一定の品質が求められ、レビュー負荷を減らしたい ドメインが複数あり、文章タイプのばらつきが大きい 4Bでは誤訳・訳抜け・不自然さが目立つケース |
| 27B | 最もモデルサイズが大きい | 誤訳の許容度が低い 低リソース言語や複雑な文章が多い 十分な計算リソースが用意できる |
TranslateGemmaの4Bは、限られたリソースでも動かしやすいコスト効率型のモデルです。4Bの翻訳品質はより大きい12Bモデルに匹敵することも示されており、IoT等のエッジでの実行や社内のオンプレ環境等、小規模GPUでの実行に向いています。
次に大きいサイズである12Bモデルは、TranslateGemmaシリーズの中ではバランス型に位置付けられます。Googleから公開されている記事ではTranslateGemmaの12Bが、2倍以上のパラメータ数を持つGemma 3(27B)を上回るスコアを残したことが示されています。
品質を上げつつ計算コストを抑えたいケースでは、12Bが有力な選択肢となります。
最もサイズの大きい27Bは高い翻訳品質を得たい場合や、専門文書・低リソース言語等の複雑な条件で利用する場合に向いています。
一方でモデルの実行に必要な計算量は増えるため、処理時間やコストは4B/12Bより大きくなる傾向にあります。レイテンシや費用よりも翻訳精度を優先する場合は、27Bの利用も選択肢に入れるとよいでしょう。
TranslateGemmaの使い方ガイド|検証手順と実装のポイント

TranslateGemmaは公開モデルのため、Kaggle/Hugging Faceといったプラットフォームからロードして活用可能です。
モデルアクセスのための手順や、最低限の実装でTranslateGemmaを利用する方法について具体的な手順を紹介します。また実行環境の選択肢や、実行環境にデプロイする際のポイントについてもお伝えします。
【事前準備】TranslateGemmaのアクセストークンを取得
TranslateGemmaを利用するためにはアクセストークンを取得し、利用規約に同意する必要があります。操作手順は以下の通りです。
画面右上のプロフィールアイコンをクリックし、「Settings」をクリックします。
左側のナビゲーションで「Access Tokens」をクリックします。
Access Tokensの管理画面が表示されるので、「+ Create new token」ボタンをクリックします。
以下の通り設定し、「Create token」ボタンをクリックします。
- Token Type:Read を選択
- Token name:任意の名前を設定
Access Tokensが表示されるので、「Copy」ボタンをクリックしてコピーします。この後の手順で使用するため、Access Tokensはメモ帳等に記載しておきます。
TranslateGemmaを利用するためには、モデルの利用規約に同意する必要があります。Hugging Faceの検索画面からモデルを検索し、モデルの公開ページに移動します。
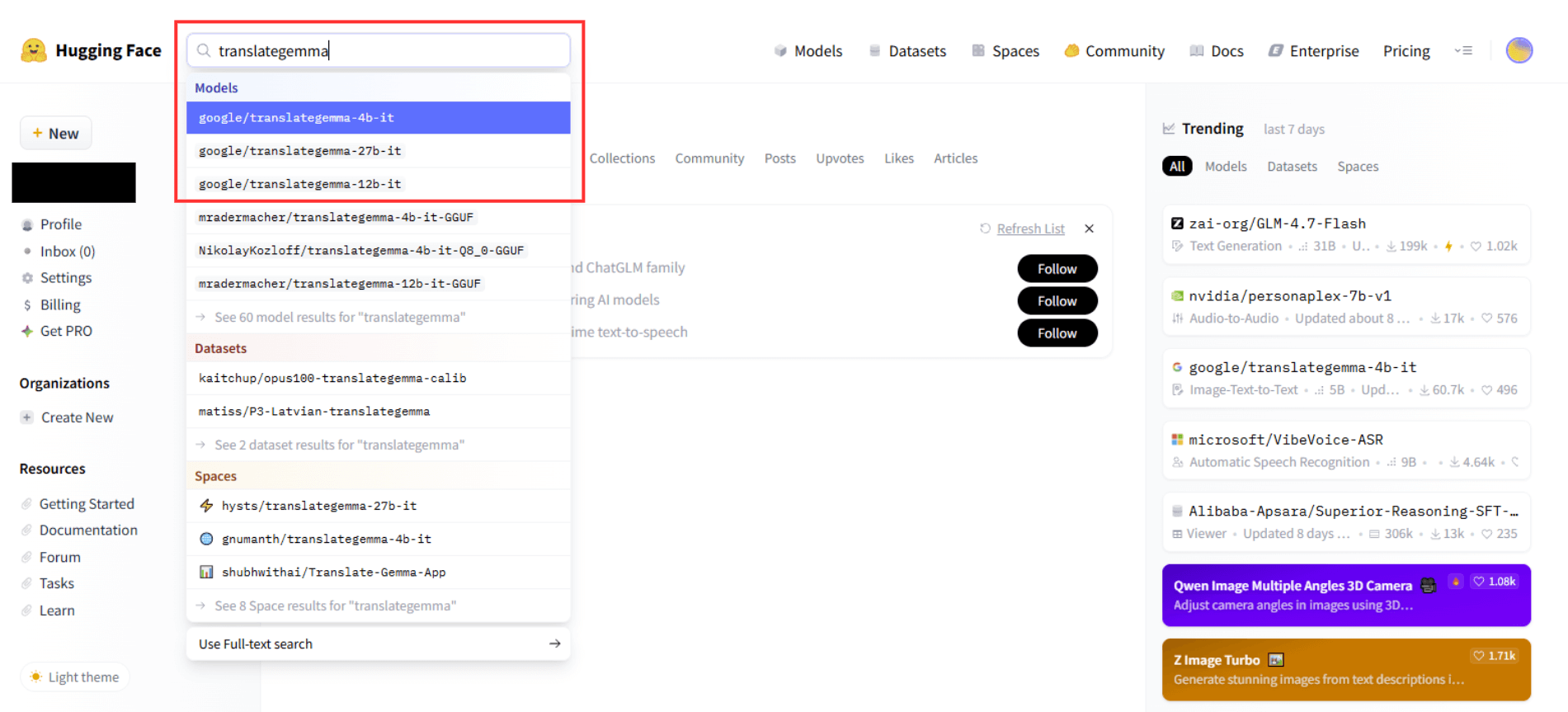
今回は「translategemma-4b-it」を使用するため、「translategemma-4b-it」の公開ページに移動します。使用するモデルサイズごとに公開ページが異なるため、適宜読み替えてください。
- 4B … translategemma-4b-it
- 12B … translategemma-12b-it
- 27B … translategemma-27b-it
モデル公開ページに移動すると、「Acknowledge license」ボタンが表示されるのでクリックします。
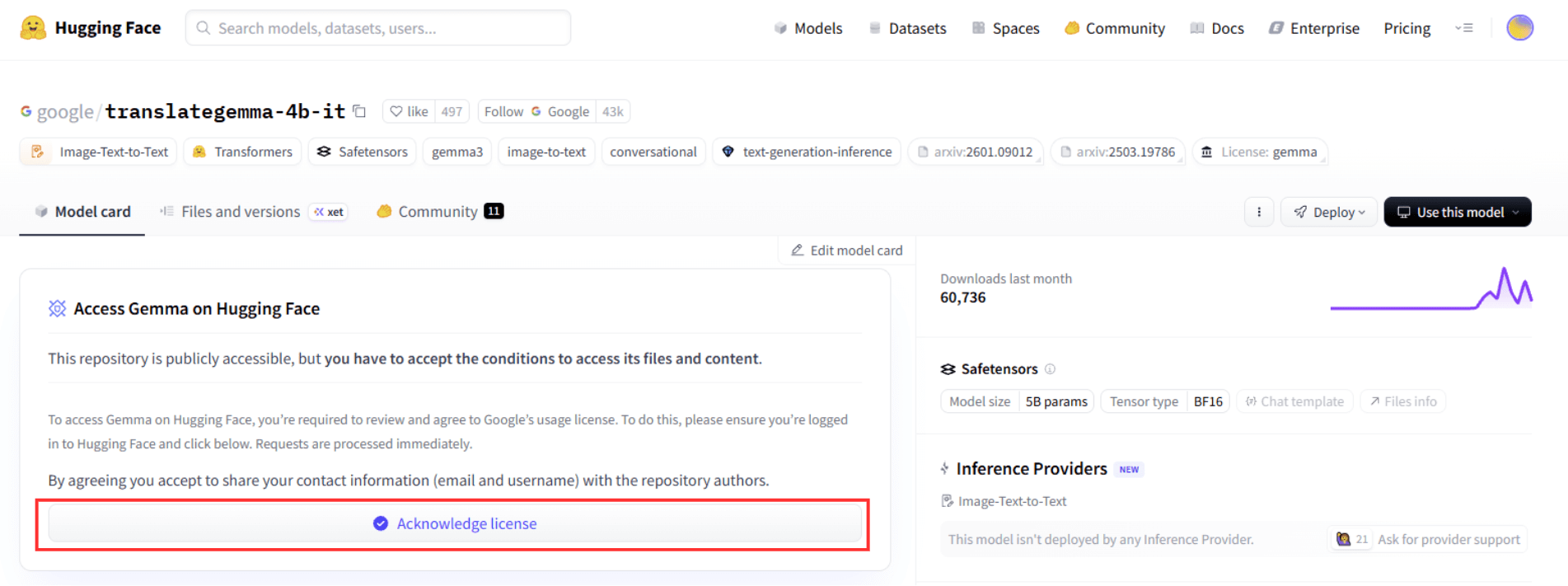
利用規約が表示されるため、内容を確認し問題がなければ「Accept」ボタンをクリックします。
以上の手順により、作成したアクセストークンを使ってTranslateGemmaを使用できるようになりました。
モデルが公開されているHugging Faceについて、詳細は以下の記事を参照してください。

【今すぐ試す】ローカル環境でTranslateGemmaを実行する
Hugging Faceで公開されているTranslateGemmaは、モデルをローカル環境にダウンロードして翻訳を実行することが可能です。
今回はノートPC上でチャットアプリを起動して、TranslateGemmaによるテキスト翻訳を行う手順を紹介します。
Linux系コマンドを使用するため、Windowsの場合 wsl -d <ディストリビューション名> でWSLを起動します。今回は以下のコマンドを実行して、Ubuntuを指定してWSLを起動しました。
wsl -d Ubuntu以下のコマンドを実行して、今回の手順で利用するパッケージをインストールします。
sudo apt update
sudo apt install -y git cmake build-essential python3 git-lfs pipx
pipx ensurepath
pipx install huggingface-hub今回はノートPCでモデルを動かすため、CPUでも大規模モデルを高速に動かすための「llama.cpp」を使用します。以下のコマンドを実行し、llama.cppをビルドします。
cd ~
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
cmake -S . -B build -DGGML_NATIVE=ON
cmake --build buildHugging Faceからモデルをダウンロードするために、以下のコマンドを実行してログインを行います。
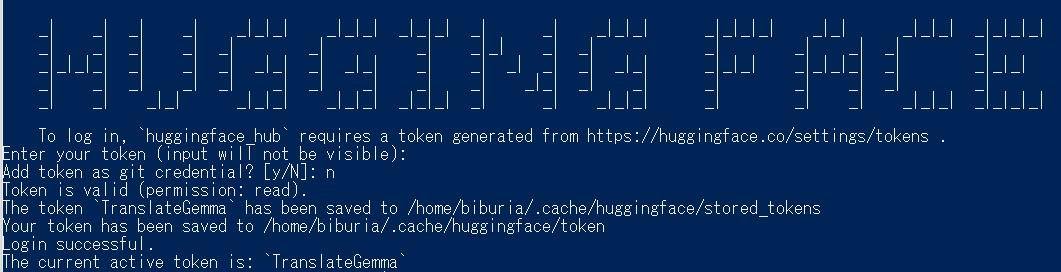
hf auth login以下のようにアクセストークンの入力が求められるため、「【事前準備】TranslateGemmaのアクセストークンを取得」のSTEP5で控えたアクセストークンを入力してください。

Add token as git credential? [y/N] については、 n と入力します。以下の通り、The current active token is: `<設定したアクセストークン名>` が表示されていればログイン成功です。
以下のコマンドを実行して、Hugging FaceからTranslateGemmaのモデルをダウンロードします。
mkdir -p ~/hf_models/translategemma-4b-it
hf download google/translategemma-4b-it --local-dir ~/hf_models/translategemma-4b-it今回は最も軽量な4Bのモデルをダウンロードしました。4B以外のサイズを利用する場合は、「translategemma-4b-it」の部分を読み替えてください。
- 4B … translategemma-4b-it
- 12B … translategemma-12b-it
- 27B … translategemma-27b-it
llama.cppを使ってCPUでモデルを実行するために、モデルをGGUFファイルに変換する必要があります。以下のコマンドを実行して、Hugging Face形式でダウンロードしたモデルをGGUFファイルに変換します。
pipx install "transformers>=4.41" sentencepiece safetensors torch numpy tqdm
python ~/llama.cpp/convert_hf_to_gguf.py ~/hf_models/translategemma-4b-it --outtype f16 --outfile ~/models/translategemma-4b-it.f16.gguf今回はモデルの計算コストを下げるため、以下のコマンドを実行して量子化も行います。
~/llama.cpp/build/bin/llama-quantize \
~/models/translategemma-4b-it.f16.gguf \
~/models/translategemma-4b-it.Q4_K_M.gguf \
Q4_K_M量子化によりモデルが低ビットで表現され、メモリ使用量の削減・CPU実行速度の向上が期待できます。翻訳品質が低下する可能性もあるため、量子化については実行環境や要件に応じて判断してください。
llama.cppにはHTTPサーバーとしてモデルを実行し、Web UIとしてチャット画面を提供する機能があります。以下のコマンドで、HTTPサーバーを起動します。
~/llama.cpp/build/bin/llama-server -m ~/models/translategemma-4b-it.Q4_K_M.gguf \
--jinja --chat-template-file ~/hf_models/translategemma-4b-it/chat_template.jinja \
-c 2048 --host 127.0.0.1 --port 8080「STEP7:モデルの量子化(任意)」を実施していない場合は、translategemma-4b-it.Q4_K_M.gguf をtranslategemma-4b-it.f16.gguf に置き換えてコマンドを実行してください。
Webブラウザから http://127.0.0.1:8080/ にアクセスすると、以下の通りllamaサーバーのチャットUIが表示されます。
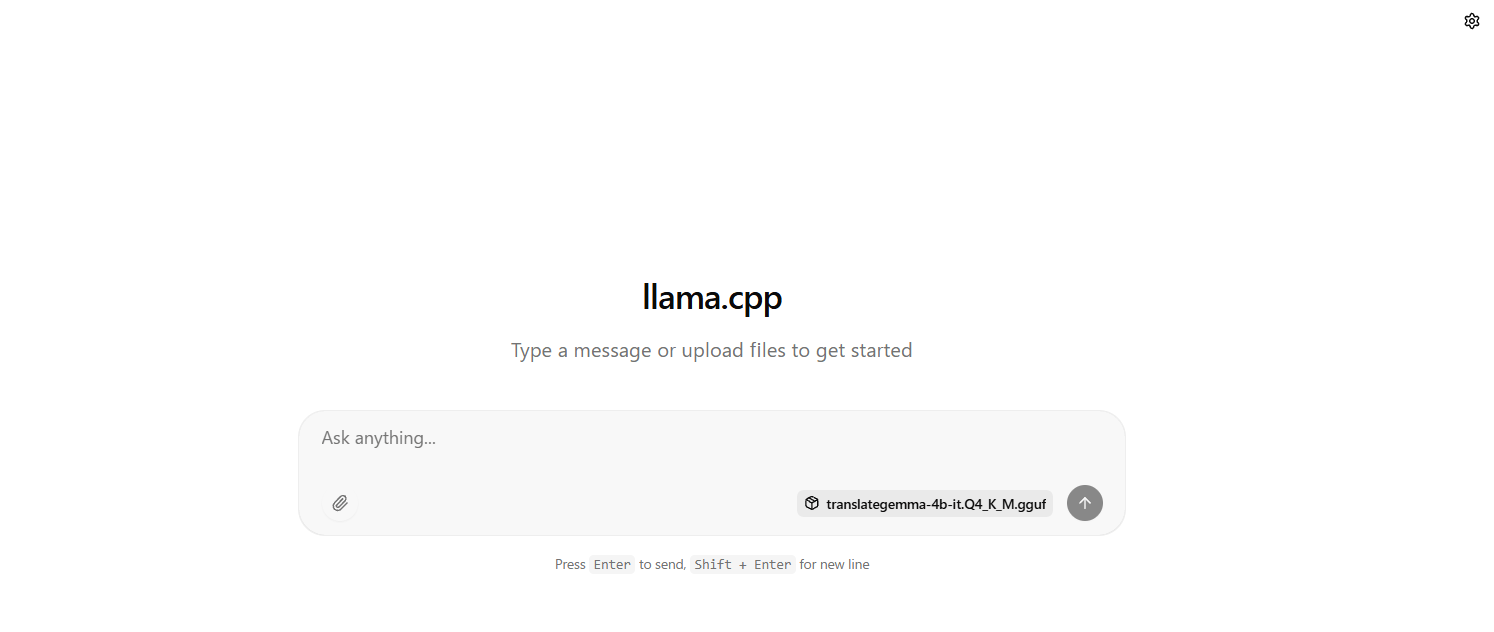
チャット画面右上の歯車のマークをクリックし、「System Message」にプロンプトを入力したら「Save Setting」ボタンをクリックします。
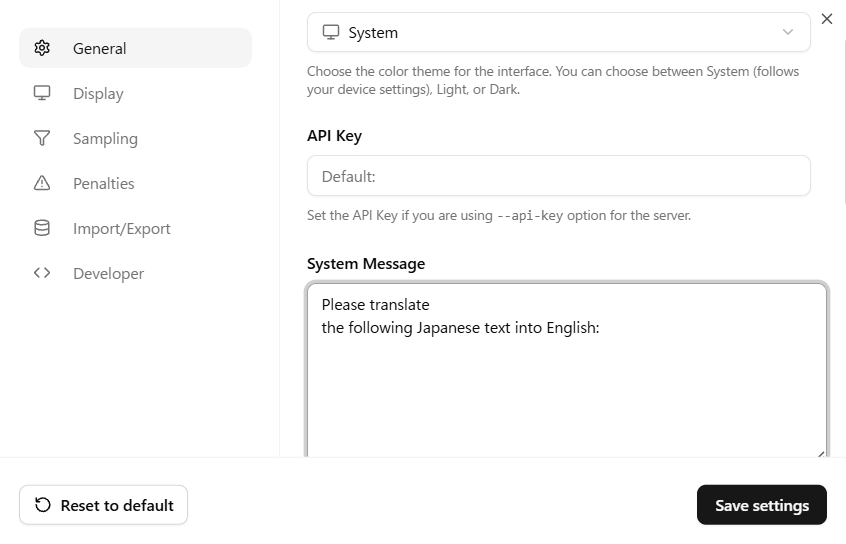
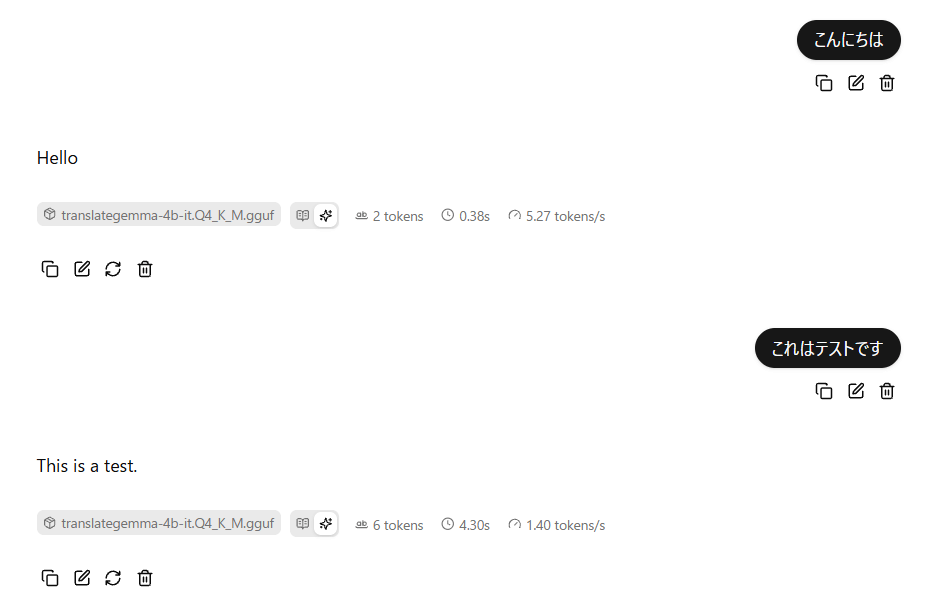
今回、システムプロンプトには日本語から英語に翻訳するように以下を設定しました。
Please translate the following Japanese text into English:以上の手順により、チャット画面に入力した文章を指定の言語に翻訳することができます。
TranslateGemmaの実行環境(AWS・Google Cloud・Google Colab)
Hugging Faceで公開されているモデルは、複数のクラウドサービス上で簡単に実行できるように統合されています。
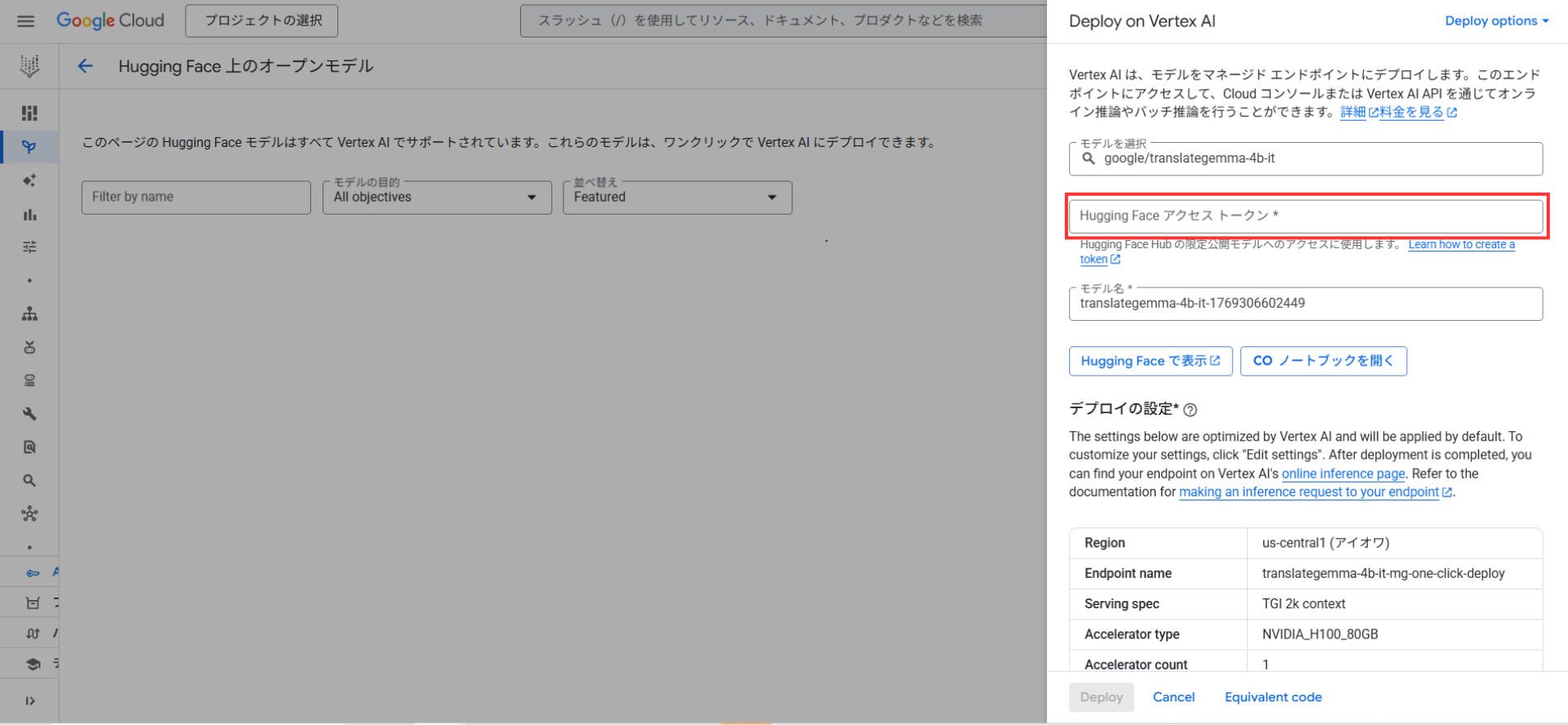
具体的には、各モデルページ上の「Deploy」「Use this model」機能から、クラウド環境やNotebook環境が選択できます。この機能を活用することで、ローカル構築を行わずにAWS・Google Cloud・Google Colabといった代表的な環境でTranslateGemmaを実行することも可能です。


AWSの場合、AI/MLモデルの学習・実行を行うためのAmazon SageMakerというサービスへのデプロイ手順が整備されています。このデプロイ手順であれば、利用者のAWSアカウントへ個別にモデルファイルを配置する必要はありません。Google CloudではVertex AI上へのデプロイが統合されており、GUI操作だけで簡単にデプロイ可能です。
より手軽にTranslateGemmaを使用する方法として、TranslateGemmaを実行するJupyter Notebookも公開されています。
Jupyter Notebookの実行サービスとして、Google ColabやKaggleと連携できます。Google Colabは一般的なML/データ分析をすぐ試す用途、Kaggle Notebooksは特定のデータセットに対する分析を共有する用途が想定されます。
Google Colabの使い方・料金等の詳細を以下の記事で紹介していますので、必要に応じて参照してください。

その他にも、ローカル環境で実行する場合のサンプルコード等が用意されています。
いずれの実行環境を利用する場合も、アクセストークンが必要です。アクセストークンの取得方法は、本記事内の「【事前準備】TranslateGemmaのアクセストークンを取得」を参照してください。
翻訳APIとして組み込む際のポイント
AIをアプリケーション等に組み込む場合、事前にモデルに与える指示であるシステムプロンプトがAIの振る舞いに大きな影響を与えます。
翻訳タスクに特化しているTranslateGemmaでは長いプロンプトや創造的なロール設定は不要で、「翻訳のみを行う」ことを明示する簡潔な指示が適しています。
また翻訳する文章を入力する前に、翻訳元の言語と翻訳先の言語を指定することが推奨されます。モデルが55言語対応の多言語翻訳器として学習されているため、翻訳元/先の言語を指定することで、翻訳の言語・文体を安定させるためです。
TranslateGemmaを利用する場合、以上の点を踏まえた翻訳タスク専用のテンプレートの利用が想定されています。
You are a professional {source_lang} ({src_lang_code}) to {target_lang}
({tgt_lang_code}) translator. Your goal is to accurately convey the meaning and
nuances of the original {source_lang} text while adhering to {target_lang} grammar,
vocabulary, and cultural sensitivities. Produce only the {target_lang}
translation, without any additional explanations or commentary. Please translate
the following {source_lang} text into {target_lang}:\n\n\n{text}テンプレート内の{}の部分が、翻訳タスクごとに指定する変数となります。それぞれ、以下を指定します。
| 変数 | 値 | 例 |
|---|---|---|
{source_lang} {target_lang} | 翻訳元/翻訳先の言語を英語で指定 | English, Japanese 等 |
{src_lang_code} {tgt_lang_code} | 翻訳元/翻訳先の言語コードを指定 言語コードはISO 639-1 Alpha-2言語コード、ISO 3166-1 Alpha-2 国コードに準拠 | en, en_US 等 |
{text} | 翻訳する文章 | 「これはテスト用の文章です」 |
TranslateGemmaの料金|イニシャルコストとランニングコスト解説

TranslateGemmaの導入判断では、コスト構造を適切に把握することが重要です。費用は大きく、導入時に発生するイニシャルコストと運用を続ける中で発生するランニングコストに分けられます。
各コストの考え方を整理し、見積もり時に押さえるべきポイントを解説します。
TranslateGemmaのライセンスと利用条件
TranslateGemmaのモデルはHugging Faceなどを通じて公開されており、任意の実行環境でTranslateGemmaを動作させることができます。モデルの利用にあたって、API利用料金のようなモデルの利用料金は発生しません。
一方で、モデルを実行するためのコンピューティング環境(GPU/TPU/CPUやストレージ、ネットワーク等)は利用者が用意し、料金も負担する必要があります。したがって、TranslateGemmaを利用するための初期費用・運用費用については、どのような実行環境を採用するかに依存します。
またTranslateGemmaの利用・運用にあたっては、Gemma Terms of UseおよびGemma Prohibited Use Policy への遵守が求められることに注意が必要です。これらのポリシーでは、違法行為や有害コンテンツの生成、ポリシー違反用途への利用が禁止されています。
オープンモデルであっても、無制限・無条件で利用が許可されているわけではない点を踏まえて導入判断を行ってください。
TranslateGemma実行環境のコストの考え方
TranslateGemmaはオープンモデルとして公開されており、任意の環境で実行できます。そのため、TranslateGemmaの利用にかかる初期コストと運用コストはどのような実行環境を選択するかによって決まります。
社内サーバーやオンプレミスでモデルを実行するのであれば、多くの場合はサーバー購入費が初期コストとして発生します。運用コストとしてはサーバーの運用・保守費用が発生しますが、事前に定められた一定の金額であるケースが多いため、発生するコストは見積もりやすいです。
一方でGoogle Cloud等のクラウドサービスを利用する場合、多くのサービスは利用時間に応じて課金する従量課金制のため、運用コストのみが発生します。利用頻度が不定期な場合はクラウドサービスの方がコストを抑えられます。
ただし事前に利用料金を固定できないため、日々の利用量をモニタリングする等、コスト管理が必要になります。
| 実行環境 | 初期コスト | 運用コスト | コスト管理の負担 |
|---|---|---|---|
| 社内サーバー/オンプレミス | 一定のコストが発生するケースが多い | 小さい傾向 | |
| クラウドサービス | 不要なケースが多い | 従量課金のケースが多い | 大きい傾向 |
TranslateGemmaを利用する期間や実行時間・実行頻度等を踏まえて、どの料金形態の実行環境が適切か判断しましょう。
TranslateGemmaの翻訳性能と運用における注意点

TranslateGemmaを業務利用する際には、モデルの仕様を踏まえた導入判断が必要になります。また適切な利用のためには、翻訳結果のモニタリングや人間によるレビューが推奨されています。
公式ドキュメントの内容をもとに、TranslateGemmaを実運用する際のポイントを紹介します。
TranslateGemmaの言語カバレッジと品質の違い
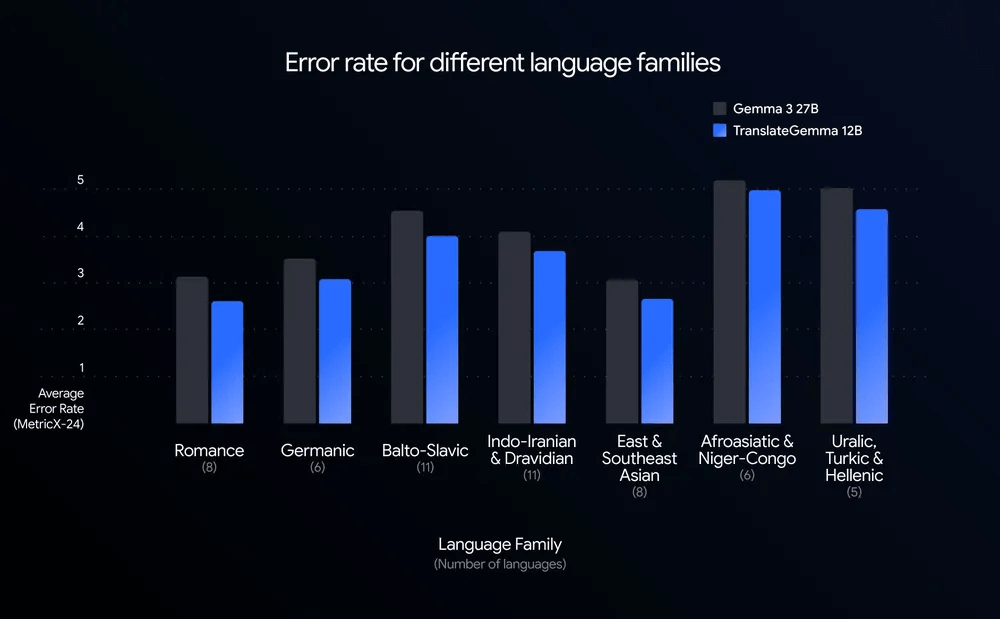
TranslateGemmaによる翻訳は、55の言語ペアを自動評価したベンチマークにおいて、同規模以上のGemma 3ベースラインに匹敵する翻訳品質が示されています。
ただし注意点として、すべての言語ペアで同一水準の翻訳品質が保証されるわけではありません。同じ手法でトレーニングを実施しても、翻訳精度は学習データの量や質、言語構造等の影響を受けます。
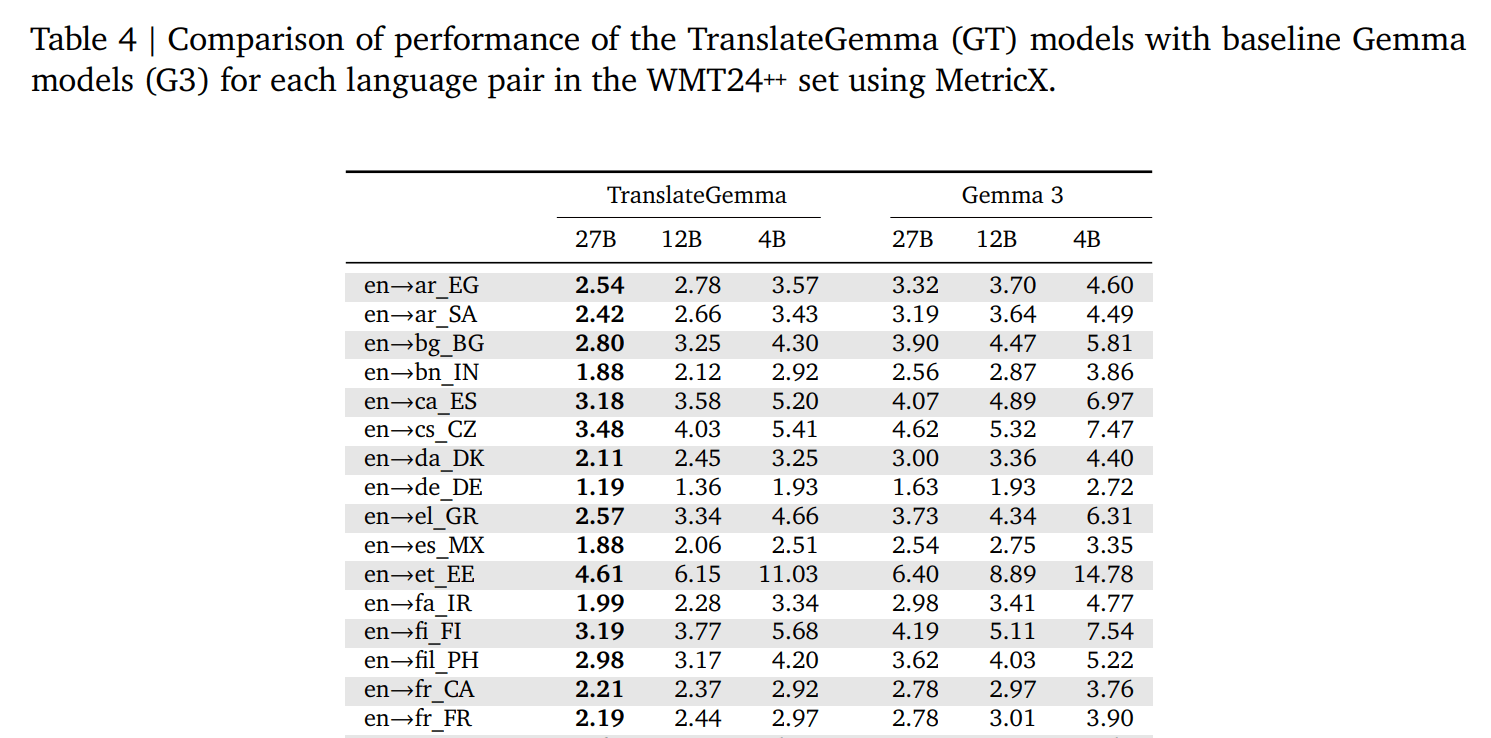
出典:TranslateGemma Technical Report
また同一言語であっても、文体(技術文書・契約文・チャット等)やドメイン(IT、法務、医療等)によって翻訳品質は変動します。ドメイン固有の専門用語や慣用表現については、事前検証や追加ルール、人手による補完等の対応が必要になるケースもあります。
ベンチマーク結果はあくまで比較指標であり、実際の業務でどの程度活用できるかは実データを用いた検証が不可欠です。
TranslateGemmaによる翻訳結果の確認ポイント
TranslateGemmaの利用にあたっては、翻訳モデルが誤訳やバイアスを完全に排除できないことを考慮し、人間によるレビューやモニタリングを行うことが推奨されています。業務利用や外部公開を前提とする場合、一度評価して終わりではなく、継続的な品質確認とモニタリングを行う運用体制も検討しておくことが重要です。
Hugging Faceのモデルカードでは、4つのリスクとその軽減策が示されています。
| リスク | リスク軽減策 |
|---|---|
| バイアスの永続化 | モデルの利用や再学習においてモデルの出力をモニタリングし、バイアスを特定・除去する |
| 有害コンテンツの生成 | モデルのユースケースに基づいて適切なコンテンツ/有害なコンテンツを定義し、有害なコンテンツが生成されない仕組みを実装する |
| 悪意のある目的での誤用 | Gemma使用禁止ポリシーを確認し、ポリシーに違反する行為(違法行為・危害を与える行為・性的に露骨なコンテンツの生成等)を防止する |
| プライバシー侵害 | モデルの利用や再学習において、プライバシー規制を遵守する |
特に契約文書等の重要な業務にTranslateGemmaを利用する場合には、人間による最終確認を前提とした運用を検討するようにしましょう。
まとめ
本記事ではTranslateGemmaをローカル環境で実行する具体的な手順や、簡単にデプロイ可能なクラウドサービスについて紹介しました。
TranslateGemmaは、Googleが公開した翻訳特化のオープンモデルです。Gemma 3をベースに、翻訳品質を高めるために2段階のファインチューニングが行われています。Gemma 3よりモデルサイズが小さい12Bでも、ベンチマークのスコアが上回る評価がされており、翻訳タスクにおいては非常に効率の良いモデルと言えます。
導入の際には、対象言語やドメイン固有の表現(固有名詞・専門用語・表記揺れ)を自社データで検証することや利用規約の確認が重要です。モデルはオープンに入手できますが、実行環境によっては初期コスト・運用コストが発生するため、事前にモデルをどのように実行するかも検討しておく必要があります。
本記事の内容を参考に、まずはTranslateGemmaを検証するための実行環境について検討してみてはいかがでしょうか。