

Gemini 3.1 Flash-Liteとは、Googleが提供するGemini 3シリーズの中で最も安くて速いモデルで、翻訳・分類・要約といった高頻度の定型タスクを低コストで大量処理することに特化しています。 個人開発者から大規模なエンタープライズ環境まで、幅広い用途で活用できます。
この記事では、Gemini 3.1 Flash-Liteとは何か、料金体系や使い方、API導入手順について詳しく紹介します。
Gemini 3.1 Flash-Liteとは?高頻度処理を支える最速・最安モデルの立ち位置

Gemini 3.1シリーズにおいて、コストパフォーマンスと低遅延を極限まで追求した「Flash-Lite」の全容を解説します。
既存のFlashやProと何が違うのか、そして新機能「Thinking levels」が開発にどう影響するかを確認しましょう。
モデルの立ち位置(Flash/Proとの違い)
Gemini 3.1 Flash-LiteはGemini 3 シリーズの中で最も安くて速いモデルで、2026年3月3日にプレビュー公開されました。
翻訳・分類・コンテンツモデレーションといった「大量に繰り返す定型タスク」に最適化されており、コストを抑えながら高スループットで処理したい開発者向けに設計されています。
Gemini のモデルラインナップは、Pro・Flash・Flash-Liteの3段階に分かれており、それぞれ役割が異なります。
| モデル | 応答速度 | コスト | 品質・精度 | 主な用途 |
|---|---|---|---|---|
| Flash-Lite | 最速 | 最小 | 中 | 翻訳・分類・要約など高頻度の定型タスク |
| Flash | 速い | 中 | 高 | バランス重視・汎用速さと精度を両立した中程度のタスク |
| Pro | 普通〜遅い | 最大 | 最高 | 複雑推論・高精度コーディング |
中でもGemini 3.1 Flash-Liteは、速度・コスト・品質のバランスを重視した軽量モデルです。
Google DeepMindの公式ブログによると、Gemini 3.1 Flash-Liteは同クラスの他モデルを上回る推論力とマルチモーダル理解力を持っています。
ベンチマークでは、GPQA Diamond(科学的知識)で86.9%、MMMU-Pro(マルチモーダル理解)で76.8%を記録しており、前世代の上位モデルであるGemini 2.5 Flashをも上回る性能を発揮しています。
multimodal understanding benchmarks, including 86.9% on GPQA Diamond and 76.8% on MMMU Pro–even surpassing larger Gemini models from prior generations like 2.5 Flash.
和訳:マルチモーダル理解のベンチマークでは、GPQA Diamondで86.9%、MMMU Proで76.8%を達成しており、2.5 Flashなどの以前の世代の大型Geminiモデルをも上回っています。
出典:Google
速度面では、Artificial Analysisの計測によると、初回の回答トークンまでの時間はGemini 2.5 Flashの2.5倍速く、出力速度は363トークン/秒と45%向上しています。
According to internal benchmarks and third-party evaluations, Flash-Lite outperforms its predecessor, Gemini 2.5 Flash, with a 2.5X faster time to first token. Furthermore, it boasts a 45 percent increase in overall output speed — 363 tokens per second compared to 249.
和訳:社内ベンチマークと第三者機関による評価によると、Flash-Liteは前バージョンのGemini 2.5 Flashを上回り、最初のトークン生成までの時間が2.5倍速くなっています。さらに、全体的な出力速度も45%向上し、毎秒249トークンから363トークンに増加しています。
出典:venturebeat.com
まず Flash-Liteで検証を始め、精度や推論深度が不足する場合に上位モデルへ移行するのが、コストを抑えながらスケールする基本的な考え方です。

対応モダリティと機能制限
Gemini 3.1 Flash-Liteは、テキスト・画像・音声・動画・PDF を入力として受け付けるマルチモーダルモデルです。
出力はテキストのみで、画像や音声の生成には対応していません。
主な対応機能は、テキスト生成・要約・翻訳をはじめ、構造化出力(JSON)・関数呼び出し・Google検索グラウンディング・コード実行・thinking levelsによる思考レベルの調整など、開発用途で必要になる機能はひと通り揃っています。
一方、画像・音声・動画の生成や、Live APIを使ったリアルタイムの音声・映像のやり取りには対応していません。
コンテキスト長は最大100万トークン、出力は最大約64,000トークンです。長い文書を丸ごと入力して要約・抽出するような用途にも対応できます。
思考レベル(thinking levels)の仕組み
Gemini 3.1 Flash-Liteでは、thinking_levelパラメータで、モデルが回答前にどれだけ「考える」かを制御できます。設定できるレベルはminimal・low・medium・highの4段階で、レベルを下げるほど速く安く、上げるほど精度が高くなりやすい傾向にあります。
指定しない場合はhighがデフォルトになるため、高頻度タスクでコストを抑えたい場合は明示的に指定することが重要です。
| thinking_level | 応答速度 | コスト | 品質・精度 | 向いているタスク例 |
|---|---|---|---|---|
| minimal | 最速 | 最小 | 低 | 翻訳・分類・定型抽出 |
| low | 速い | 小 | やや低 | 要約・簡単なQ&A |
| medium | 普通 | 中 | 中 | UI生成・指示追従・論理的な組み立て |
| high (デフォルト) | 遅い | 大 | 高 | 複数ステップの推論・複雑な問題解決 |
thinking_levelを minimalやlowに設定することで、3モデルの中で最もコストを抑えた運用が可能です。高頻度タスクではまずminimalから試し、品質が不十分な場合にレベルを上げて調整していくのがおすすめです。
Gemini 3.1 Flash-Liteの料金は?APIコストを最小化するための料金体系と最適化

100万トークンあたりの単価から無料枠の規定、さらに「思考トークン」の課金ルールまで、コスト構造を解説します。 大量のリクエストを安く回すためのバッチ処理やキャッシュ戦略についても触れていきます。
基本的な料金体系と無料枠の全体像
Gemini APIの料金プランは、無料で使える「無料枠(Free Tier)」 と、使った分だけ料金が発生する「有料枠(Paid Tier)」の2種類があります。Gemini 3.1 Flash-Liteはプレビュー段階ながら、無料枠での利用が可能です。
有料枠と無料枠でできることを比較します。
| 項目 | 有料枠 | 無料枠 |
|---|---|---|
| 入力(100万トークンあたり) | $0.25(テキスト/画像/動画) $0.50(音声) | 送信回数に上限あり |
| 出力(100万トークンあたり) | $1.50 | 送信回数に上限あり |
| よく使う入力の一時保存(キャッシュ) | $0.025(テキスト/画像/動画) $0.05(音声) $1.00/100万トークン/時間 | 利用不可 |
| Google検索によるグラウンディング | 5,000件/月のプロンプトまで無料 その後は、$14/検索クエリ1,000件 | 利用不可 |
| Googleマップによるグラウンディング | 5,000件/月のプロンプトまで無料 その後は、$14/検索クエリ1,000件 | 利用不可 |
なお、思考レベルの設定(thinking_level)によって発生する内部の推論処理は、出力テキストの料金に含まれる形で課金されます。思考レベルをminimalやlowに下げると、出力量が減るため料金を抑えられます。
コストを最小限に抑えたい場合は、一括送信(有料枠)× 思考レベルminimal の組み合わせが最も効率的です。無料枠は動作確認や試作向けと割り切り、本番運用では有料枠への移行を前提に検討してください。
標準APIとバッチ処理の使い分け
リアルタイムで処理する「標準API」と、まとめて処理する「バッチAPI」の2つの呼び出し方があります。
バッチAPIを使うと料金が50%割引になり、入力・出力ともに標準APIの半額で利用できます。
| 項目 | 料金 |
|---|---|
| 入力(100万トークンあたり) | $0.215(テキスト/画像/動画) $0.25(音声) |
| 出力(100万トークンあたり) | $0.75 |
| よく使う入力の一時保存(キャッシュ) | $0.0125(テキスト/画像/動画) $0.025(音声) $0.50/100万トークン/時間 |
| Google検索によるグラウンディング | 5,000件/月のプロンプトまで無料 その後は、$14/検索クエリ1,000件 |
| Googleマップによるグラウンディング | 5,000件/月のプロンプトまで無料 その後は、$14/検索クエリ1,000件 |
なお、Google検索とGoogleマップによるグラウンディングは、通常料金と変わりません。
即時応答が不要な、翻訳・分類・要約などの処理にはバッチAPIが適しています。 一方、ユーザーの入力に即座に応答するチャットやリアルタイムのコンテンツ生成には、標準APIを選ぶ必要があります。
処理の性質に応じて使い分けるだけで、同じ処理量でもコストを大きく抑えられます。
コスト最適化と高頻度タスク設計
コストを抑えるうえで効果的な手段は3つあります。
1つ目はコンテキストキャッシュの活用です。 同じシステムプロンプトや背景情報を繰り返し送信する場合、キャッシュしておくことで入力トークンのコストを削減できます。
2つ目はモデルルーティングです。 すべてのリクエストをFlashやProに送るのではなく、シンプルなタスクはFlash-Lite で処理し、複雑なタスクだけ上位モデルに振り分けることで、全体のコストを大幅に下げられます。
3つ目は高頻度タスクの設計見直しです。 プロンプトを短く整理する、不要なコンテキストを削る、即時性が不要なタスクは Batch API にまとめるといった工夫だけで、トークン消費を継続的に削減できます。
Gemini 3.1 Flash-Liteの使い方|最短で実装するためのAPI・SDK導入ガイド

Google AI Studio・Gemini API・Vertex AIの3つの利用環境を目的別に整理します。
自分のユースケースに合った環境を選び、APIキーの発行から安全な管理方法まで確認しましょう。
利用環境(AI Studio / API / Vertex AI)
Gemini 3.1 Flash-Liteは、目的に応じてGoogle AI Studio・Gemini API・Vertex AIの3つの経路から利用できます。どの経路を選ぶかによって、セットアップ手順と操作画面が異なります。
Google AI Studioは、ブラウザ上でモデルを試せる無料のプレイグラウンドです。Googleアカウントさえあれば、インストールや設定なしにすぐ使い始められるため、まず動作を確認したい場合の出発点として最適です。後述するAPIキーの取得もこの画面から行います。
Gemini APIは、個人開発者向けの標準的な利用経路です。APIキーを取得すれば、PythonやJavaScriptなどのSDKからすぐに呼び出せます。無料枠の範囲内であればクレジットカード登録なしで利用できるため、個人開発の入り口としても使いやすい経路です。
Vertex AIは、Google Cloud上のエンタープライズ向け環境です。社内のセキュリティ要件が厳しい本番運用や、他のGoogle Cloudサービスと組み合わせる場合に適していますが、利用開始までの手順はGemini APIと比べて複雑になります。
とにかく今すぐ試したい人にはGoogle AI Studio、個人・小規模アプリを作りたいにはGemini API、企業システムに組み込みたいにはVertex AIがおすすめです。
まずGoogle AI Studio でプロンプトの動作を確認 → Gemini API で実装という流れが最もスムーズです。
Google AI Studioでの手順(ブラウザで今すぐ試す)
ブラウザですぐに試すならGoogle AI Studioがおすすめです。ログインから実行の手順を解説します。
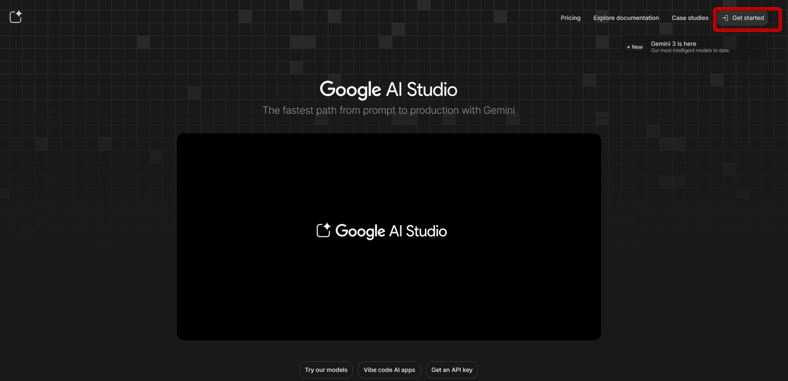
右側のモデル選択メニュー(Run settings)から「Gemini 3.1 Flash-Lite」を選択します。
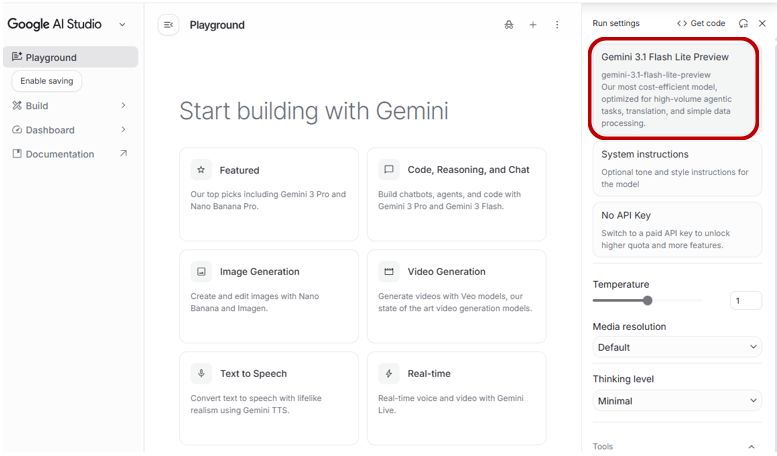
プロンプトを入力して「Run」を押すだけで、インストール不要でモデルを試せます。
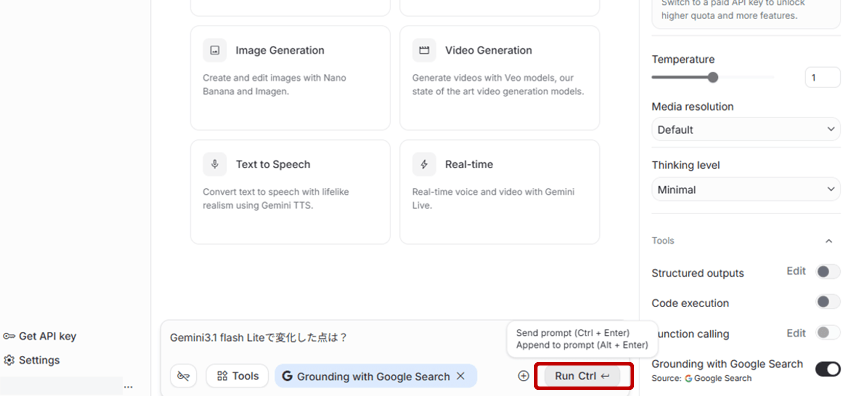

コードを書かずに動作確認したい場合や、後述のAPIキーを取得する際の起点として使います。

Gemini APIでの手順(個人開発・アプリ実装向け)
ローカル環境やクラウドサービス上に自前のアプリを構築する場合の標準的な経路です。
Gemini API を使うには、まずAPIキーを取得します。Google AI Studio から数分で発行できます。
Google AI Studioの左メニューから「APIキー」を選択し、「APIキーを作成」をクリックします。
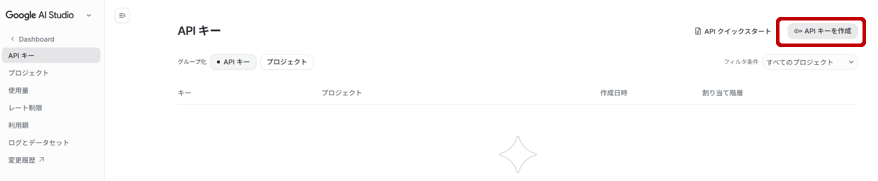
ポップアップ画面の「キーを作成」を押すと、APIキーが作成されます。
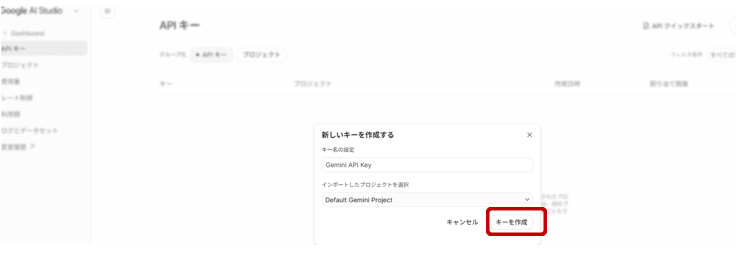
生成されたキーをコピーします。割り当て結果の下部にある赤い円で囲まれたコピーのマークをクリックするとコピーされます。

Googleアカウントがあれば無料で発行でき、クレジットカード登録は不要です。
取得したAPIキーは、test.py などのコードファイルに直接書き込まないようにしましょう。コードファイルをそのままGitHubにアップロードすると、APIキーが外部に漏れて悪用されるリスクがあります。
代わりに envファイルにAPIキーを保存し、コードからは env を読み込む形で管理します。
プロジェクトのルートディレクトリに env ファイルを作成します。
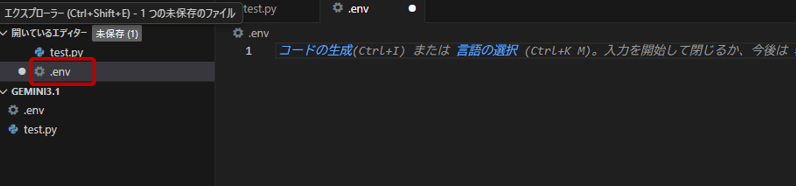
以下の形式でAPIキーを記述して保存します
GEMINI_API_KEY=APIキーを入力
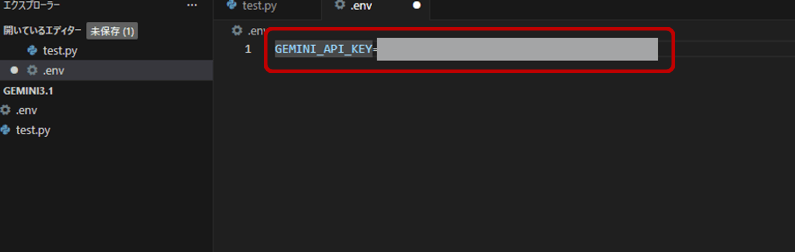
VCodeでpip install python-dotenvと入力し、実行します。
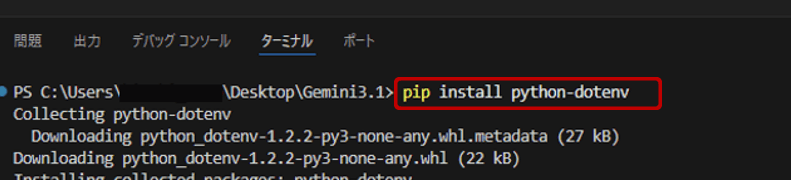
test.py を以下のように書き換えます。
これで env ファイルからAPIキーを安全に読み込めるようになります。
from google import genai
from dotenv import load_dotenv
import os
load_dotenv()
client = genai.Client(api_key=os.environ.get("GEMINI_API_KEY"))
response = client.models.generate_content(
model="gemini-3.1-flash-lite-preview",
contents="日本の首都はどこですか?"
)
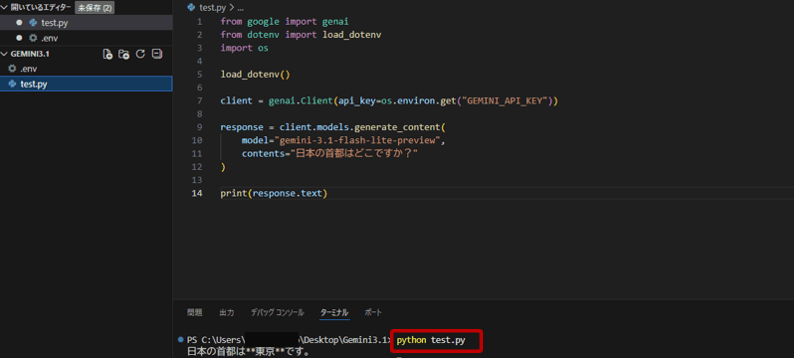
print(response.text)VS Codeのターミナルで以下を実行します。
python test.py
Google AI Studio では、APIキーをプロジェクトごとに発行・管理できます。用途別にキーを分けておくと、不要になったキーだけを無効化でき、セキュリティリスクを最小限に抑えられます。
Vertex AIでの手順(Google Cloud・エンタープライズ向け)
社内セキュリティ要件が厳しい本番運用や、BigQuery・Cloud Storageなど他のGoogle Cloudサービスと連携する場合に適した経路です。
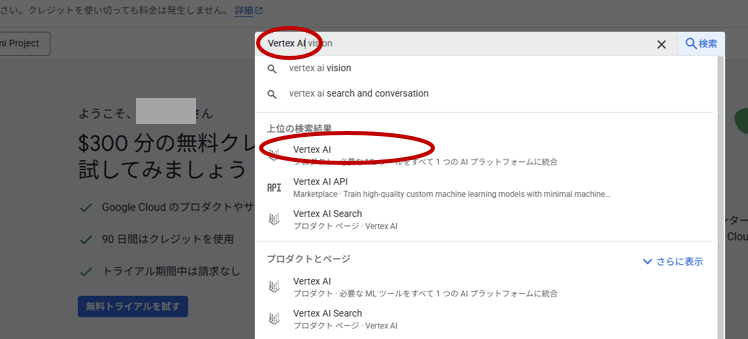
検索窓で「Vertex AI」と入力し、一番上に出てくる「Vertex AI」をクリックします。
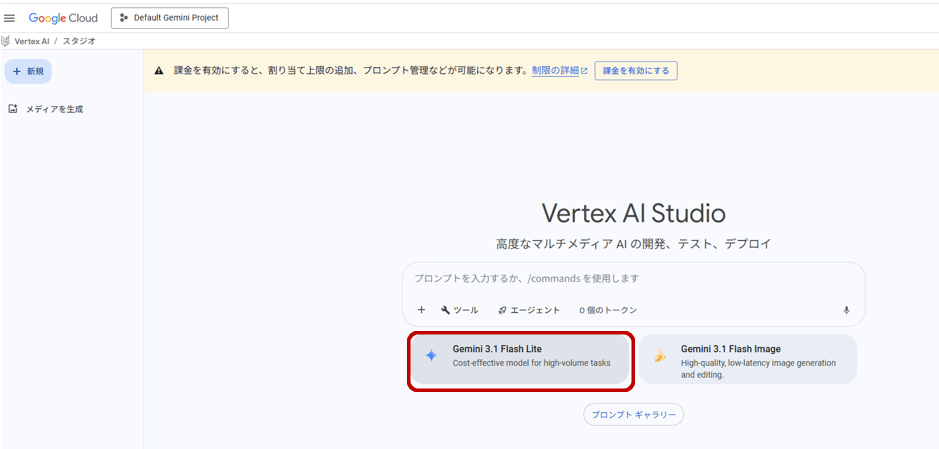
Vertex AI Studioの画面が開いたら、「Gemini 3.1 Flash Lite」をクリックします。
Gemini 3.1 Flash-Liteの実装・コーディングガイド

最小構成のサンプルコードをベースに、マルチモーダル入力や構造化出力など、実践的な実装パターンを解説します。
思考レベル(Thinking levels)のパラメータ設定など、Flash-Lite特有の挙動も押さえておきましょう。
最小構成での実装手順
ここでは、Gemini 3.1 Flash-Lite を最短で動かすまでの手順を説明します。
ターミナル(またはコマンドプロンプト)で以下を実行します。
pip install google-genai
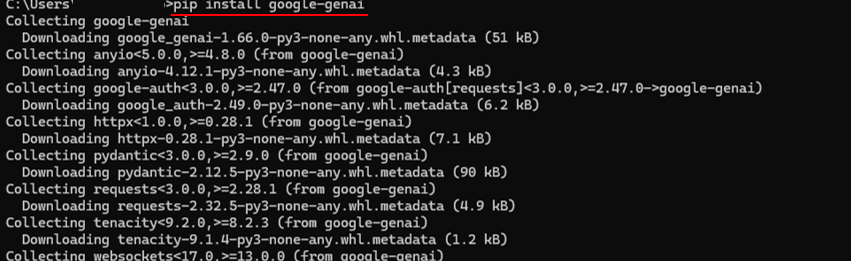
インストールが完了したら、以下のコマンドが正しく入っているか確認します。
pip show google-genai
Version: の行が表示されれば成功です。

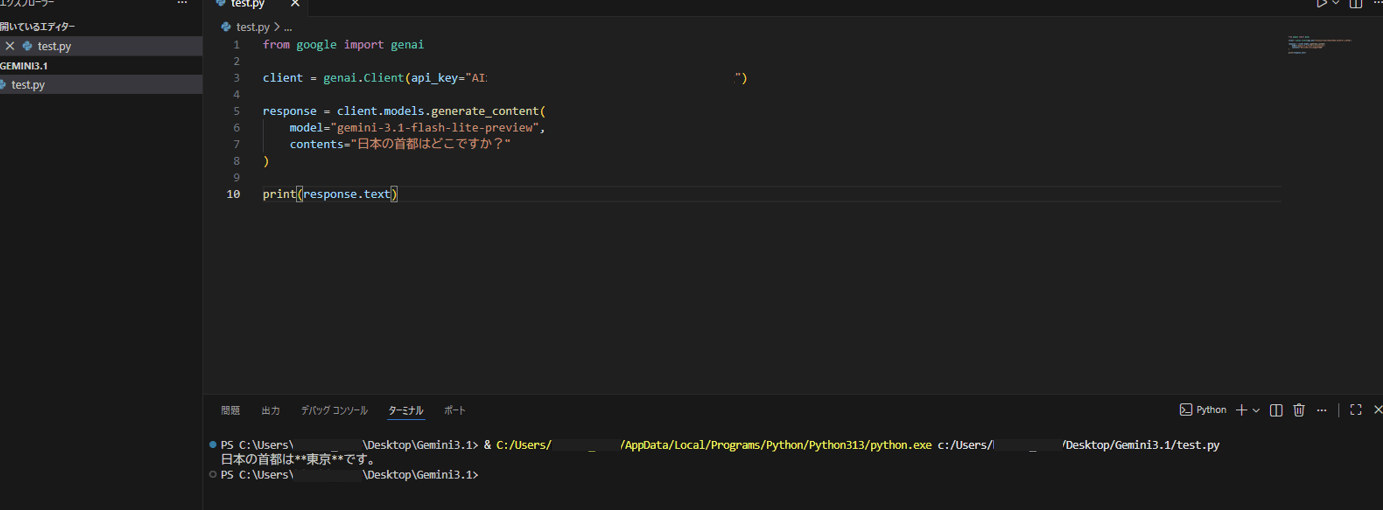
以下のコードを test.py という名前で保存します。api_key= の “” の中に、STEP2でコピーしたAPIキーを直接貼り付けてください。
from google import genai
client = genai.Client(api_key="ここに実際のAPIキーを貼り付ける")
response = client.models.generate_content(
model="gemini-3.1-flash-lite-preview",
contents="日本の首都はどこですか?"
)
print(response.text)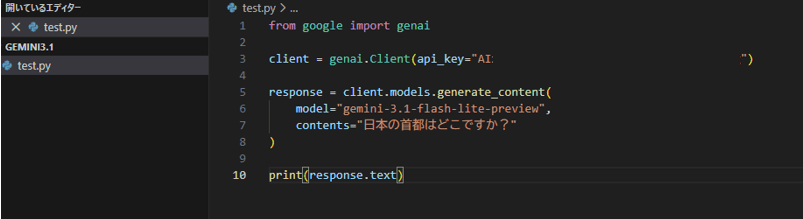
「日本の首都は東京です。」と出力が表示されれば、Gemini 3.1 Flash-Liteの動作確認は完了です。
この最小構成で動作が確認できたら、次のセクションで紹介するマルチモーダル入力や構造化出力などの機能を順に試していきましょう。
マルチモーダル入力の実装方法
Gemini 3.1 Flash-Liteは、テキスト以外に画像・音声・動画・PDFを入力として扱えます。
それぞれの入力形式の注意点は以下のとおりです。
| 入力形式 | 注意点 |
|---|---|
| ページごとにテキスト、画像などコンテンツを分析。長いPDFは必要ページに絞るとコスト削減に有効 | |
| 音声 | 複数チャンネルは自動で1チャンネルに変換。MP3・WAV・AAC・FLACなど主要形式に対応 |
| 動画 | Files API 経由が基本。長時間動画はトークン消費に注意 |
画像は20MB、動画は100MB未満の入力が目安になります。サイズに応じて、ファイルの渡し方は2通りから選びます。
- 小さなファイル:Base64エンコードで直接渡す(〜20MB目安)
- 大きなファイル:Files API で事前アップロードする(20MB超・動画など)
画像などの小さなファイルは、Base64エンコードに変換してリクエストに直接含める方法が使えます。
以下は画像ファイルを読み込んで内容を説明させる例です。
client = genai.Client()
import base64
from google import genai
with open("image.jpg", "rb") as f:
image_data = base64.b64encode(f.read()).decode("utf-8")
response = client.models.generate_content(
model="gemini-3.1-flash-lite-preview",
contents=[
{"inline_data": {"mime_type": "image/jpeg", "data": image_data}},
{"text": "この画像を説明してください"}
]
)
print(response.text)動画など容量の大きなファイルは、Files APIを使って事前にアップロードし、そのファイルのURLをモデルに渡す方法を使います。大きなデータを直接リクエストに含める必要がないため、通信の負荷を抑えられます。
from google import genai
# ファイルをアップロードしてURIを取得
file = client.files.upload(file="video.mp4")
response = client.models.generate_content(
model="gemini-3.1-flash-lite-preview",
contents=[file, "この動画の内容を要約してください"]
)
print(response.text)構造化出力と関数呼び出し
構造化出力とは、モデルの回答をJSON形式で受け取る機能です。
分類結果や抽出データを後続処理にそのまま渡したい場合に活用できます。response_mime_type に application/json を指定するだけで有効になり、スキーマを合わせて渡すことでフィールド名や型を固定した安定した出力を得られます。
response = client.models.generate_content(
model="gemini-3.1-flash-lite-preview",
contents="以下のレビューをポジティブ・ネガティブ・中立で分類してください:「商品の品質は良いが、配送が遅かった」",
config={
"response_mime_type": "application/json",
"response_schema": {
"type": "object",
"properties": {
"sentiment": {"type": "string"},
"reason": {"type": "string"}
}
}
}
)
print(response.text)
# 出力例: {"sentiment": "中立", "reason": "品質は高評価だが配送に不満あり"}関数呼び出し(Function Calling)は、モデルが「外部処理が必要」と判断したとき、引数をJSON形式で返す機能です。データベース検索や外部サービス連携など、モデル単体では完結しない処理を組み込む際に使います。
tools = [{
"function_declarations": [{
"name": "get_weather",
"description": "指定した都市の現在の天気を取得する",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "都市名"}
},
"required": ["city"]
}
}]
}]
response = client.models.generate_content(
model="gemini-3.1-flash-lite-preview",
contents="東京の天気を教えてください",
config={"tools": tools}
)
# モデルが{"city": "東京"}という引数を返すので、自前の天気APIに渡して処理するどちらも高頻度タスクとの相性がよく、Flash-Liteの処理速度とコスト効率を活かしやすい機能です。
思考レベルの設定パラメータ例
Gemini 3.1 Flash-Lite では、thinking_level パラメータでモデルの推論の深さを制御できます。設定しない場合は high がデフォルトになるため、コストを抑えたい場合は明示的に指定することが重要です。
4つの思考レベルはそれぞれ以下の用途に適しています。
- minimal:翻訳・分類・定型抽出など単純な処理
- low:要約や簡単なQ&A
- medium:UI生成や指示追従など論理的な組み立てが必要な処理
- high:複数ステップの推論や複雑な問題解決
思考レベルを設定するには、以下を参考にしてください。
response = client.models.generate_content(
model="gemini-3.1-flash-lite-preview",
contents="以下のテキストを日本語に翻訳してください:Hello, world.",
config={"thinking_level": "minimal"}
)
print(response.text)高頻度タスクではminimalまたはlowから試し始め、出力品質が不十分な場合にレベルを上げて調整するのがおすすめです。thinking_levelを1段階下げるだけで、コストを大幅に削減できるケースもあります。
エラー回避とレート制限の対策
実装後に直面しやすいエラーやレート制限の仕様を整理しましょう。
まず押さえておきたいのが、現在プレビュー段階であるという点です。モデルIDや仕様が予告なく変更される可能性があるため、本番運用への組み込みは正式リリース後を推奨します。
レート制限はプロジェクト単位で適用されます。 無料版はレート制限が厳しく、高頻度で呼び出すとすぐに上限に達してしまいます。ある程度の量を試したい場合は早めに有料版へ移行しておくとスムーズです。
課金まわりで混乱しやすいのが、Google AI StudioとGoogle Cloud(Vertex AI)で操作画面や課金導線が異なっている点です。どちらの環境で使っているかを意識せずに進めると、想定外の請求先に課金されるケースがあります。 利用環境と紐づいているプロジェクト・請求先アカウントを事前に確認しておきましょう。
コスト重視の最速軽量モデルとしての活用シーン|実務での導入パターン

Liteモデルが最も輝くのは、スピードとコストが優先される大量の定型処理です。 上位モデル(Flash/Pro)へアップグレードすべき境界線についても、具体的な判断基準を提示します。
定型タスク(翻訳・分類・抽出・要約)
Gemini 3.1 Flash-Liteが最も力を発揮するのが、同じ種類の処理を大量に繰り返す定型タスクです。
翻訳・テキスト分類・情報抽出・要約といった処理は、1リクエストあたりの複雑度が低く、Flash-Liteの速度とコスト効率を最大限に活かせます。
Google DeepMindの公式発表によると、ファッションアプリのWheringがFlash-Liteを商品分類のパイプラインに導入したところ、複雑なファッションカテゴリを含む商品タグ付けにおいて100%の一貫性を達成し、ラベル割り当ての信頼性が大幅に向上したとのことです。
高頻度かつ低複雑度のタスクであれば、上位モデルと遜色ない品質を、大幅に低いコストで実現できます。
モデルルーティングの分類器として活用
Gemini 3.1 Flash-Liteは、エージェントシステムの「入り口」となる分類器としても有効です。
受け取ったリクエストの複雑度や種類をFlash-Liteで素早く判定し、その結果に応じて後続の処理を Flash や Pro に振り分けるという使い方です。
すべてのリクエストを上位モデルに送るのではなく、シンプルなタスクはFlash-Liteで完結させることで、システム全体のコストとレイテンシを大幅に削減できます。 大量のリクエストを捌く本番環境ほど、この設計の効果が大きくなります。
上位モデルへ切り替える判断基準
Flash-Liteで試してみて、以下のような問題が出始めたら上位モデルへの移行を検討するタイミングです。
回答の論理的な一貫性が保てない、複数ステップの推論で誤りが増えるといった場合はFlashが適しています。 高品質なコード生成、深い専門知識が必要な分析、長文コンテキストを正確に扱う処理が求められる場面ではProを選ぶのが無難です。
コストと品質のバランスを取るうえで重要なのは、まずFlash-Liteで動かして品質を計測することです。 感覚ではなく実際の出力品質をもとに判断することで、不必要なコスト増を避けられます。
まとめ
Gemini 3.1 Flash-Liteの活用は、タスクの複雑度とコストのバランスを意識した使い分けが重要です。
翻訳・分類・要約など高頻度の定型タスクではFlash-Liteを起点に、精度が求められる場面ではFlashやProへ段階的に移行することで、コストを抑えながら品質を確保できます。
まずはGoogle AI Studioでプロンプトを試し、APIキーを取得して最小構成で動かすところから始めてみてください。