

DeepSeek-V3.2とは、DeepSeekの新たなモデルであり、GPT-5に匹敵する性能を持ちながらもオープンソースモデルとして無料で公開されました。
特に高性能版のV3.2-Specialeは、Gemini 3 Pro級の数学・推論性能を示します
この記事では、DeepSeek-V3.2の使い方や料金、V3.2-Specialeや他社モデルとの違いについて解説します。
DeepSeek-V3.2とは?最新LLMの特徴とできること

まずはDeepSeek-V3.2の概要についてご説明します。
DeepSeek-V3.2の概要と開発背景
DeepSeek-V3.2は、DeepSeek V3ファミリーにおける最新のモデル群であり、日常利用から高度な推論までをカバーする汎用AIアシスタントとして設計されたバランス型モデルです。

V3.2標準版はGPT-5に近いレベルの性能を持ち、さらに高度な数学・推論タスクに特化したSpeciale版はGemini 3 Proに匹敵すると評価されています。
出典:DeepSeek-V3.2 Release
- 🔹 V3.2: Balanced inference vs. length. Your daily driver at GPT-5 level performance.
- 🔹 V3.2-Speciale: Maxed-out reasoning capabilities. Rivals Gemini-3.0-Pro.

開発の背景には、従来のオープンソースLLMが抱えていた長文処理の非効率性やポストトレーニング計算の不足といった課題を克服する狙いがありました。
V3.2-Expからの最大の進化は、独自のDeepSeek Sparse Attention(DSA)機構の導入と、事前学習コストの10%以上を投じた大規模かつ安定した強化学習フレームワークの適用です。この大規模な強化学習の投入により、モデルの推論能力が飛躍的に向上し、オープンモデルとしては最高水準のエージェント能力を実現しています。
V3.2は、効率的なアプローチによってフロンティアモデルと肩を並べる性能を達成した戦略的なリリースとして位置づけられています。
DeepSeek Sparse Attention(DSA)と長コンテキスト対応のポイント
DeepSeek Sparse Attention(DSA)は、DeepSeek-V3.2の根幹をなす技術革新であり、長文コンテキスト処理の効率を劇的に改善するために独自に開発されました。
従来のLLMで用いられるアテンション機構は、入力シーケンスが長くなるにつれて計算量が爆発的に増加するというボトルネックを抱えていました。DSAはこの課題を解決し、長距離依存性を維持しながら計算量を大幅に削減することを可能にしました。
この効率化により、DeepSeek-V3.2は128Kトークンという非常に長いコンテキストの入力を安定かつ効率的に処理することが可能です。
DSA技術は、Sparse Attentionを安定的に学習させるための技術的ブレークスルーを含んでおり、長文脈シナリオにおけるモデルの実用性を大きく高めています。
結果として、高い性能を維持しつつ、長文の要約や複雑なドキュメントの理解など、長コンテキストを要するワークロードの推論コスト低減に貢献しています。
思考モード・非思考モードとエージェント向け設計の特徴
DeepSeek-V3.2は、エージェント機能の強化を念頭に設計されており、ユーザーの要求に応じて深く推論する思考モードと、素早く応答する非思考モードを切り替えられます。
思考モードは、複雑な推論チェーンやツール使用が必要なタスクに適用され、多段階の意思決定プロセスを改善します。非思考モードは、日常的なチャットや簡単な質問応答など、迅速なレスポンスが求められるタスクに利用され、効率性を高めます。
このデュアルモードの実現は、大規模なエージェント的タスク合成パイプラインによって自動生成された高品質な学習データに支えられています。
モデルはツール利用時にこの思考を組み込むことを重視しており、エージェントがより賢く、より堅牢に動作できるように設計されています。
この設計により、DeepSeek-V3.2はオープンソースモデルの中で最高レベルのエージェント能力と汎化性能を実現しており、特に複雑なコーディングや数学的推論タスクで威力を発揮します。
オープンソース・MITライセンスでできること
DeepSeek-V3.2は、GPT-5級のフロンティア性能を持ちながら、オープンソースとして公開され、非常に自由度の高いMITライセンスを採用している点が最大の特徴です。
MITライセンスにより、ライセンス表記を維持すれば商用利用を含めほとんどの制限なしに商用目的で利用することが可能です。これにより、自社のサーバーやローカル環境での運用が自由に行えるため、API提供企業に依存せずにデータ主権を確保できます。
ユーザーはモデルを自社の特定のタスクやデータセットに合わせて自由にファインチューニングやカスタマイズを実施できます。
オープンソース化は、世界最高峰のAI性能を一部の大手テック企業だけでなく、より広範な開発者や企業に民主化するという、DeepSeekの戦略的な狙いを示しています。この戦略は、AIの技術革新と市場への影響力を加速させる重要な転換点として注目されています。
DeepSeek-V3.2の性能は?ベンチマークと得意分野

続いて、DeepSeek-V3.2の性能について、ベンチマークなどを踏まえながら解説していきます。
GPT-5・Gemini 3との性能比較
DeepSeek-V3.2は、オープンモデルでありながら、OpenAIのGPT-5やGoogleのGemini 3 Pro、AnthropicのClaude 4.5 Sonnetといったクローズドなフロンティアモデルと同等レベルのベンチマークスコアを記録している点が最大の特徴です。
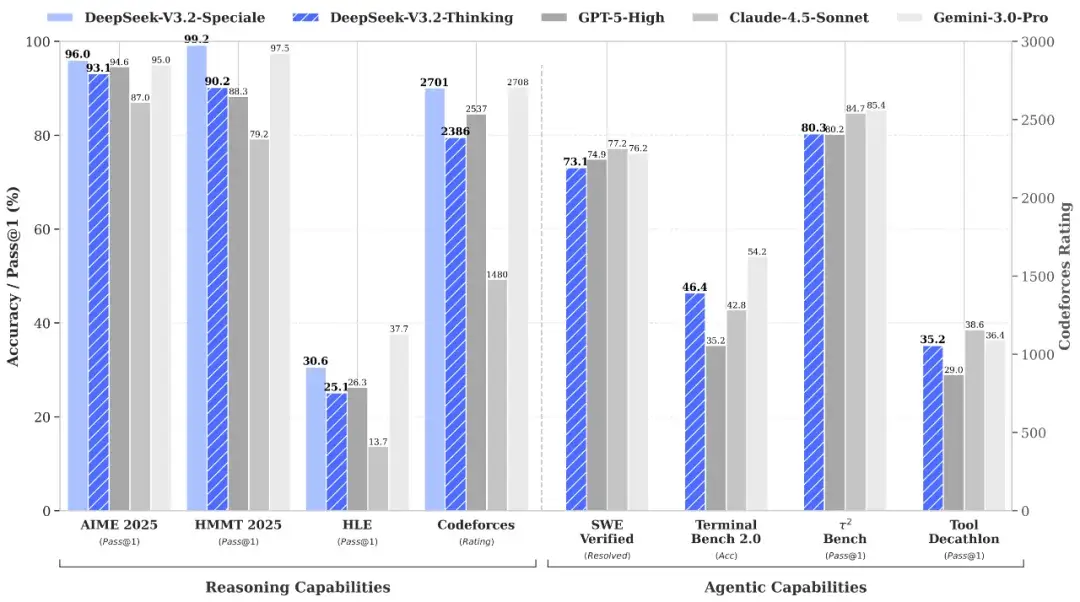
DeepSeek-V3.2の標準版は、多くのベンチマークでGPT-5に近い総合性能を達成しています。特にコーディングのバグ修正や対話型ターミナル操作などのエージェント関連タスクでは、GPT-5と肩を並べる、あるいは上回るケースも報告されています。
さらに高性能版のDeepSeek-V3.2-Specialeは、数学競技のAIMEやHMMTといった高難度タスクでGemini 3 Proに匹敵、あるいは凌駕する正答率を示しました。
ただし、Specialeは性能が高い代わりにトークン効率が低くなっています。
V3.2-Speciale dominates complex tasks but requires higher token usage.
出典:DeepSeek-V3.2 Release
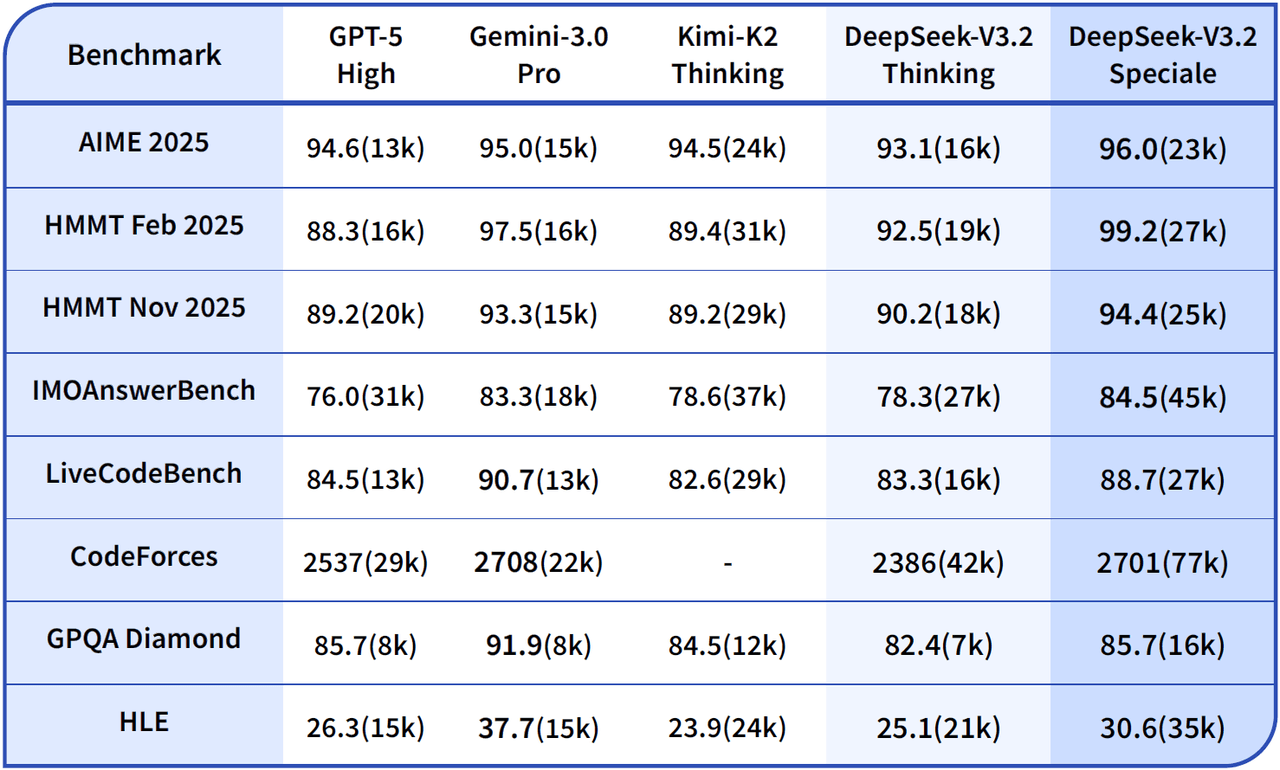
総じて、DeepSeek-V3.2ファミリーは、かつてのようなクローズドモデルとの絶対的な性能格差を埋めた、一大マイルストーンとして評価されています。
汎用モデルとしての強みと弱み
DeepSeek-V3.2は、特定のタスクに特化せず、幅広い領域で高い性能を発揮する汎用モデルとして設計されています。
強みとしては、前述の通り数学、推論、コーディングといった分野でフロンティアモデルと同等のスコアを出す高い知的能力と、ツール利用を前提としたエージェントタスクでの汎化性能が挙げられます。日常的なタスクにおいても、思考モードを有効にすることでGPT-5相当とされる性能を発揮し、高い回答品質を提供できます。
一方で、汎用モデルとして見た場合の弱みとして、創造性や人間のような自然な日常対話、感情的なニュアンスの理解といったタスクにおける評価が、まだ特定分野に特化したモデルや洗練されたクローズドモデルに比べ十分ではない可能性があります。
また、高性能を出すための内部思考トークンが長くなる傾向があるため、特に日常会話など、迅速で簡潔な応答が求められるシナリオでは、効率性の面で劣る可能性が指摘されています。
Specialeの数学特化性能
DeepSeek-V3.2-Specialeは、標準版と同じアーキテクチャをベースとしながらも、より長い内部思考トークンを許容する設計と、高難度な推論タスクに特化した調整が施された、ハイエンドな推論モデルです。
Specialeの最も顕著な強みは、数学と論理的推論における特化性能であり、高難度の数学競技(AIME、HMMT、IMOなど)や、情報科学の競技プログラミング(IOIやICPC World Finalsなど)といったタスクで、金メダル級の成績を収めています。
Gold-Medal Performance: V3.2-Speciale attains gold-level results in IMO, CMO, ICPC World Finals & IOI 2025.
出典:DeepSeek-V3.2 Release
この性能が特に活かされるのは、多段階の思考連鎖を必要とする複雑な問題や、深い論理的洞察が求められるタスクです。
例えば、高度な数学の証明問題、複雑に絡み合った条件からの真実の導出、複数の制約を満たすコードの生成など、推論の深さと正確性が結果を大きく左右するタスクでSpecialeは標準版や他の競合モデルとの差を広げます。
Specialeは、その高い推論力を活かし、アカデミアや研究開発における複雑な解析作業、高度な技術的課題の解決といった、計算量の増大を厭わないプロフェッショナルなタスクに最適化されています。
実務での得意シナリオ
DeepSeek-V3.2は、その技術的特徴により、実務において特に以下のシナリオで強みを発揮します。
まず、独自のDSA技術により128Kトークンという超長コンテキストを効率的に処理できるため、企業ドキュメントのナレッジ活用や、数十ページにわたる法務文書の長文要約、大規模プロジェクトにおけるコードベースのレビューなどで高い実用性を誇ります。
次に、エージェント向けに最適化された設計と高いコーディング能力により、コードレビューやバグ修正、さらには複数の外部ツールを連携させる複雑な自動化ワークフローの実行に優れています。
また、 Speciale版の高度な推論能力は、金融工学やサプライチェーン最適化といった、高度な数理モデルに基づく複雑なデータ分析タスクで威力を発揮します。
総じて、DeepSeek-V3.2は、長大な情報処理と多段階の論理的思考が求められる、エンタープライズ領域の専門的なタスクを効率的かつ正確にこなすための強力な基盤モデルとして機能します。
DeepSeek-V3.2の各モデルと他社LLMとの違い

ここでは、DeepSeek-V3.2の各モデルや過去のモデル、他社のLLMとの違いについてさらに詳しく見ていきましょう。
DeepSeek-V3.2とDeepSeek-V3.2-Specialeの違い
DeepSeek-V3.2は、日常的な対話から複雑なタスク処理まで幅広く対応するバランス型モデルであり、思考モードと高速な非思考モードを切り替えられるのが特徴です。
一方、DeepSeek-V3.2-Specialeは、数学や高度な論理推論に特化したスペシャリストであり、強化学習において推論プロセスのみを徹底的に学習させています。Specialeは、標準版にある長さのペナルティが緩和されており、回答に至るまでの思考トークンを極端に長く生成することで、Gemini 3 Proを凌駕する数学性能を実現しています。
提供形態としては、両モデルともオープンソースで公開されていますが、Specialeは公式のWebやAPIでは2025年12月15日に提供終了しているため、ローカルで動かす必要があります。
用途として、標準版はWeb検索やツール利用を含む汎用エージェントタスクに向き、Specialeは純粋な数学的証明や競技プログラミングのような複雑なタスクに最適化されています。
DeepSeek-V3.2とDeepSeek V3/V3.2-Expの違い
DeepSeek-V3.2の最大の特徴は、前世代のDeepSeek-V3や実験版であるV3.2-Expで検証されたDSAを正式に実装し、完成度を高めた点にあります。
V3では長文脈処理における計算コストが課題でしたが、V3.2ではDSAにより計算量が劇的に削減され、128Kトークンの長文脈でも推論速度と精度を両立しています。
V3.2-Expは2025年9月にリリースされた技術検証モデルであり、DSAの効果を実証する役割を果たしましたが、正式版のV3.2ではさらに強化学習の安定性が向上し、エージェント性能が強化されています。
アーキテクチャ面では、Mixture-of-Experts(MoE)とDSAを組み合わせることで、パラメータ規模を維持しつつ、アクティブな計算量を抑える効率的な設計が確立されました。
これにより、V3.2はV3と比較して、同じハードウェアリソースでより長いコンテキストと複雑な推論を扱える実用的なモデルへと進化しています。
DeepSeek-V3.2とChatGPT/Gemini/Claudeの違い
DeepSeek-V3.2は、ChatGPTやGemini、Claudeといった米国のフロンティアモデルと比較して、コストパフォーマンスとオープンな提供形態が最大の差別化要因です。


性能面では、DeepSeek-V3.2は推論やコーディングにおいてGPT-5に匹敵し、Speciale版は特定の数学タスクでGemini 3 Proを上回りますが、マルチモーダルの総合力ではGemini 3やGPT-5に分があります。
価格に関しては、DeepSeekはAPIコストが競合の10分の1以下に設定されているほか、MITライセンスによるローカル運用が可能であるため、機密情報を扱う企業にとってデータの主権を確保しやすい利点があります。
一方で、制約として、DeepSeekはテキストとコード処理に特化しており、文脈の機微を読み取るクリエイティブな文章作成や、ネイティブな画像理解能力は現時点では限定的です。
ユースケース別モデル選択法
タスクの性質に応じて最適なモデルを選ぶことが重要です。それぞれのモデルの比較は以下の通りです。
| モデル | 推奨ユースケース | 強み | 注意点 |
|---|---|---|---|
| DeepSeek-V3.2 | 社内RAG コード生成 長文要約 ツール利用 | コスト効率 長文脈 ローカル運用可 | 創造的表現はGPT-5に劣る場合あり |
| DeepSeek-V3.2-Speciale (API提供終了) | 数学・科学技術計算 複雑な論理パズル 競技プログラミング | 推論能力 数学性能 | 思考時間が長くレスポンスが遅い ローカル環境でのみ使用可能 |
| GPT/Gemini/Claude | マルチモーダル分析 クリエイティブ執筆 多言語のニュアンス | 総合力 画像/動画理解 エコシステム | コストが高い データが外部に出る |
一般的なビジネスチャット、長文ドキュメントの要約、あるいはRAGを用いた社内検索システムには、コストと速度のバランスが良いDeepSeek-V3.2が最適です。
一方で、高度な数学的検証、金融モデリング、あるいは複雑なアルゴリズムの実装といった、思考の深さが結果に直結するタスクにはDeepSeek-V3.2-Specialeを選ぶといいでしょう。ただし、思考時間の長さやトークン効率の低さには注意が必要です。また、使用するにはHugging Faceから重みをダウンロードしてローカルで動かす必要があります。
画像を含む資料の解析や、人間らしい感性を重視したマーケティングコピーの作成には、依然としてマルチモーダル性能に優れたGPT-5やGemini 3が適しています。その分コストが高いことや入力データが外部に出てしまう注意点もあります。
DeepSeek-V3.2の使い方
次に、DeepSeek-V3.2の使い方についてご紹介します。
無料で試す:公式Web/アプリでの始め方と基本UIの使い方
DeepSeek-V3.2を無料で試す方法として、公式Webサイトやスマホアプリを利用する方法があります。
Webやアプリでの始め方は以下の通りです。

ログイン後は、ChatGPTやGeminiと同様にメッセージウィンドウにプロンプトを入力して送信します。
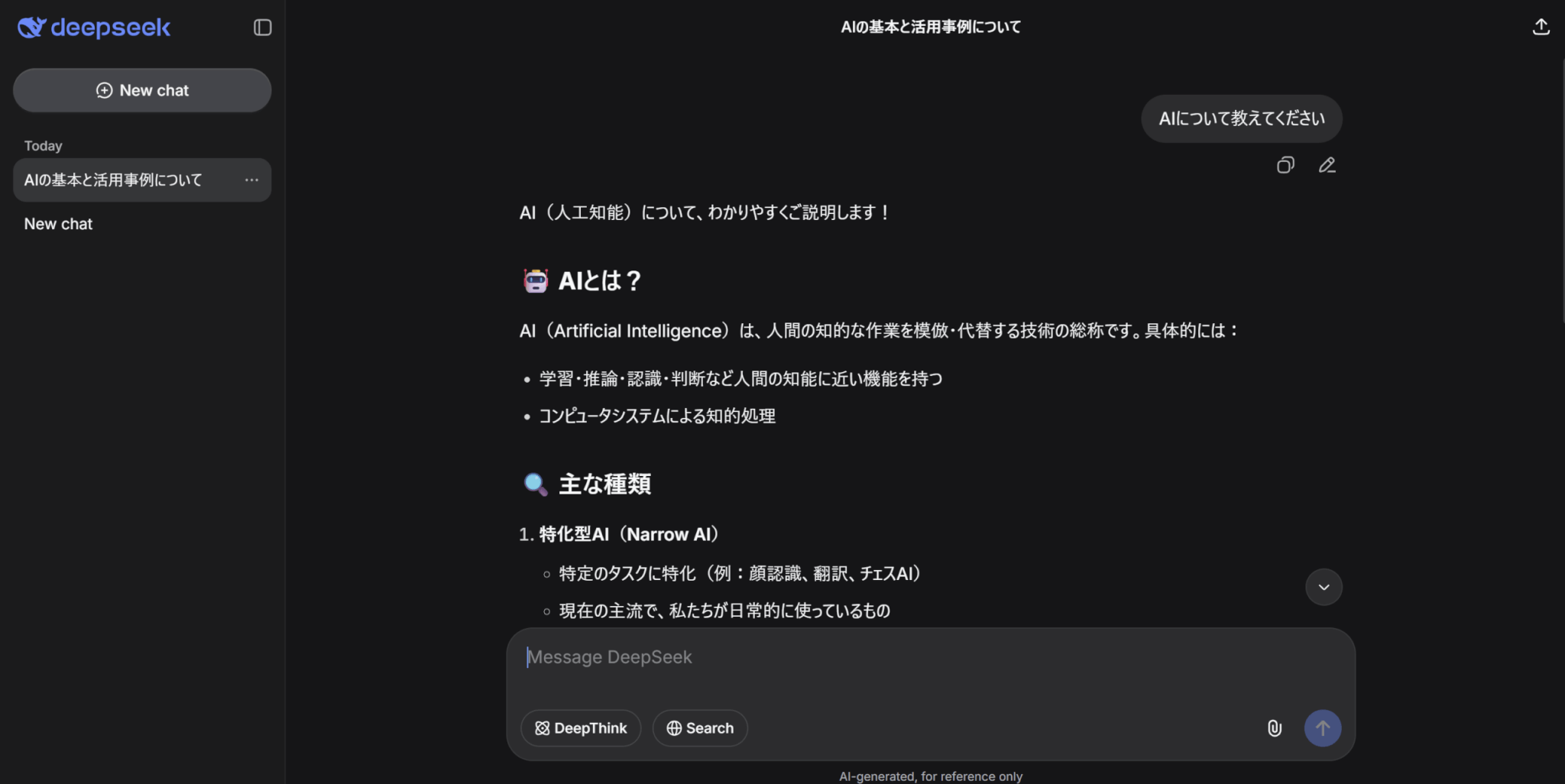
なお、現時点のWeb版ではDeepSeek-V3.2が既定で使用されます。
APIで使う:APIキー発行〜エンドポイント設定・モデル指定
次に、APIでDeepSeek-V3.2を使う方法を解説します。
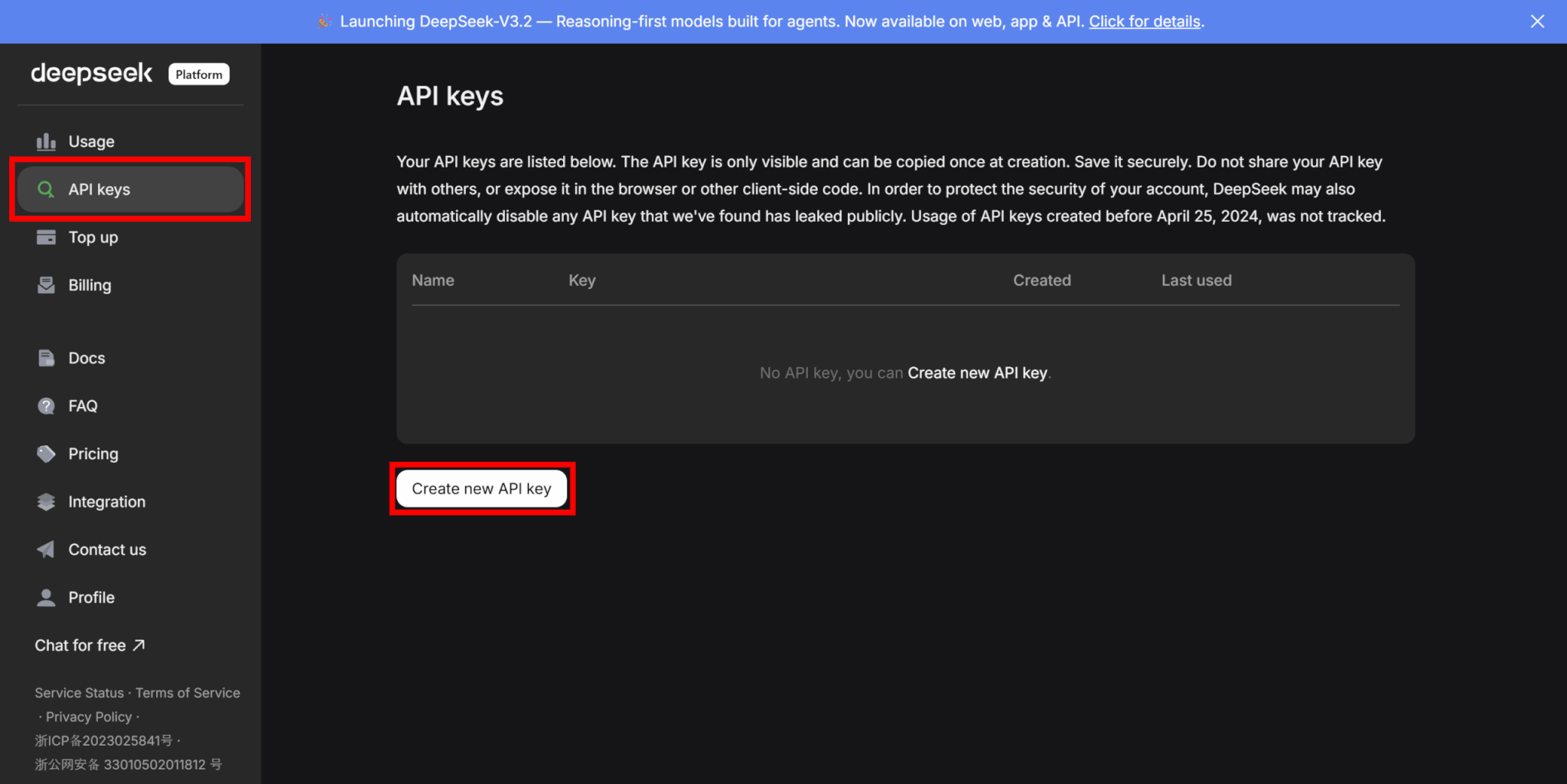
ログインができたら、「API keys」タブに移動し、「Create new API key」をクリックします。
名前を入力してAPIキーを作成しましょう。
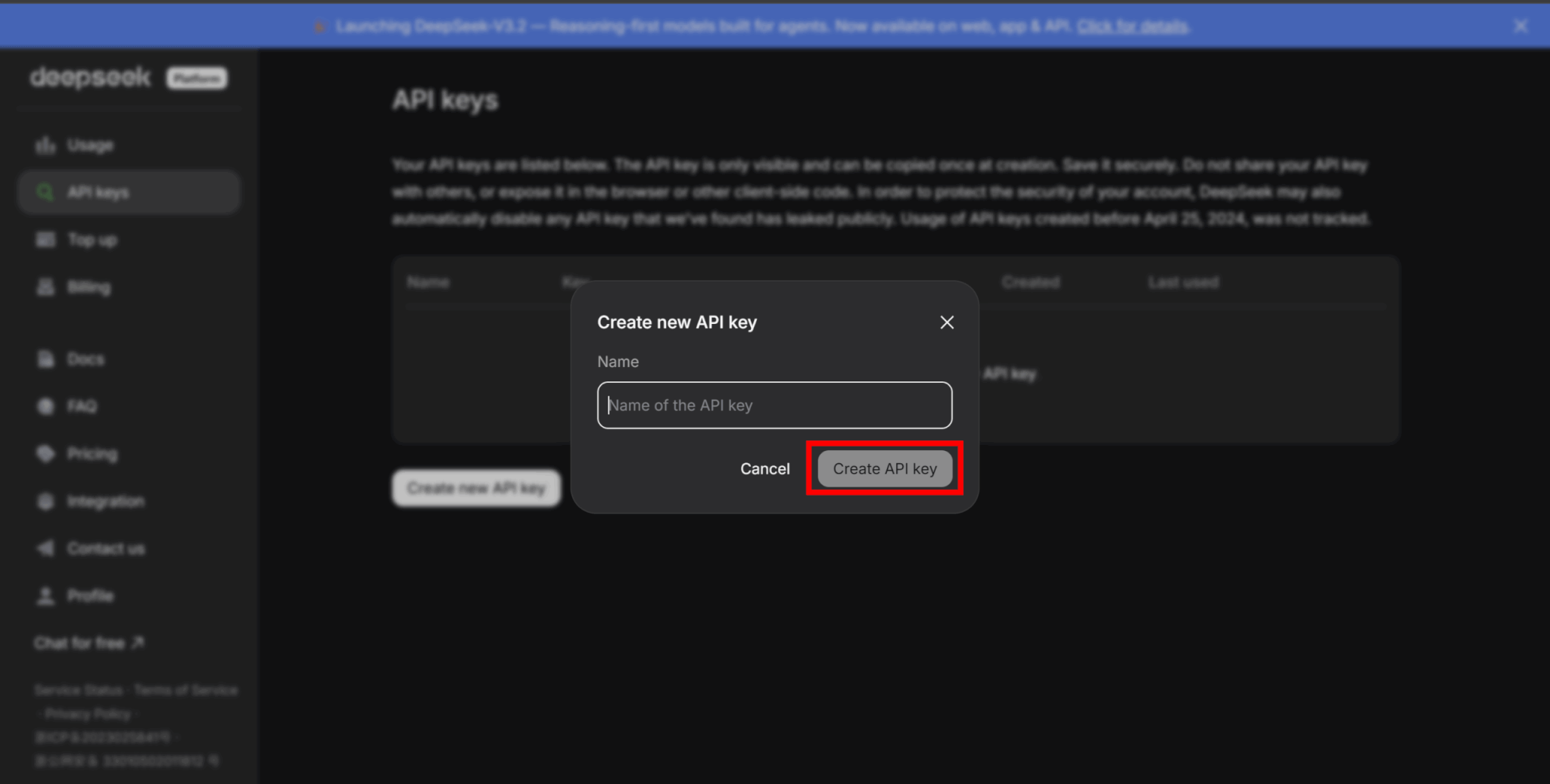
「Create API key」をクリックするとAPIキーが表示されるので、コピーして安全な場所に保管してください。
なお、一度APIキーの表示画面を閉じると二度とキーを見ることができないため、必ずコピーするようにしましょう。
APIでDeepSeekを利用するには、有料のクレジットが必要です。
「Top up」タブに移動し、購入するクレジット数を選択し、支払い方法を設定してクレジットを購入しましょう。
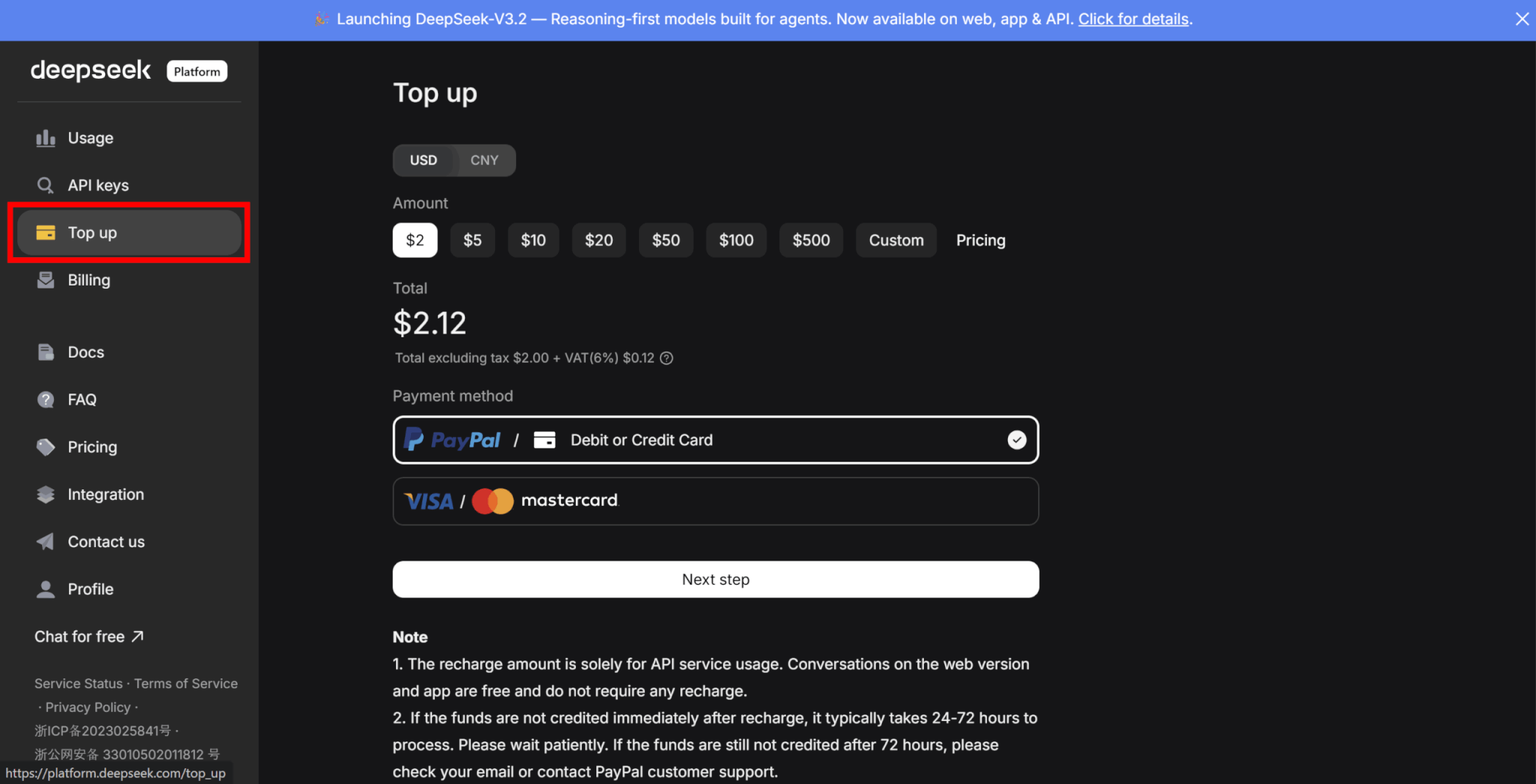
APIを使用するディレクトリの環境変数にAPIキーを設定します。
.envファイルに以下の記述を追加してください。
DEEPSEEK_API_KEY=<YOUR_API_KEY>DeepSeekのAPIは、OpenAIと互換性のあるAPIフォーマットを採用しています。そのため、スクリプトでAPIを使用する際は、OpenAI APIと同じように使うことができます。
ここでは、Pythonを使ってAPIを呼び出す方法をご紹介します。
まずは以下のコマンドを実行し、OpenAI SDKをインストールしましょう。
pip install openaiあとは以下のようにコードを書いて実行することで、APIキーを呼び出して使用することができます。
import os
from openai import OpenAI
client = OpenAI(api_key=os.environ.get('DEEPSEEK_API_KEY'), base_url="https://api.deepseek.com")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False
)
print(response.choices[0].message.content)なお、2025年12月26日現在、APIで呼び出せるモデルの一覧は以下の通りです。
| モデル名 | モデルのバージョン |
|---|---|
| deepseek-chat | DeepSeek-V3.2(非思考モード) |
| deepseek-reasoner | DeepSeek-V3.2(思考モード) |
ツール利用・エージェントワークフローの実装イメージ
DeepSeek-V3.2はツール呼び出しの精度が高く、LangChainやLlamaIndexなどのフレームワークを用いた自律型エージェントの実装に最適化されています。

実装時は、ツール定義をJSONスキーマとしてモデルに渡すことで、モデルがユーザーの意図を解釈し、Web検索や計算機、データベース操作などの外部ツールを自律的に実行します。
特にV3.2の強みは、思考モードとツール利用をシームレスに連携できる点にあり、「計画立案→ツール実行→結果検証」という堅牢なループを構築できます。これにより、従来のモデルでは失敗しやすかった多段階の複雑なワークフローでも、論理的な整合性を保ちながらタスクを完遂することが可能です。
開発者はプロンプトエンジニアリングで「思考してからツールを使う」よう指示するだけで、エラー耐性の高いエージェントを構築できます。
なお、DeepSeek-V3.2-Specialeではツールは使用できません。
ローカル・オンプレで動かす方法と必要スペックの目安
DeepSeek-V3.2はオープンウェイトモデルとしてHugging Faceで公開されており、機密情報を扱う企業などはオンプレミス環境で運用可能です。セキュリティの高い運用ができるほか、ファインチューニングによって特定のタスクに特化したモデルにカスタマイズすることも可能です。
特に、Specialeは現時点でこの方法でしか利用できません。
以下のようなコードで、モデルの重みをダウンロードすると、ローカル利用ができます。
import transformers
from encoding_dsv32 import encode_messages, parse_message_from_completion_text
tokenizer = transformers.AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-V3.2")
messages = [
{"role": "user", "content": "hello"},
{"role": "assistant", "content": "Hello! I am DeepSeek.", "reasoning_content": "thinking..."},
{"role": "user", "content": "1+1=?"}
]
encode_config = dict(thinking_mode="thinking", drop_thinking=True, add_default_bos_token=True)
prompt = encode_messages(messages, **encode_config)
tokens = tokenizer.encode(prompt)ただし、総パラメータ数が約685Bという巨大なMoEモデルであるため、フル精度で動かすにはH100やA100などのハイエンドGPUが複数枚必要となるのが一般的です。
もしスペックの低いPCやサーバーで動かしたい場合は、モデルを量子化してダウンロードすることも検討する必要があります。
また、モデルデータだけで数百GBを要するため、大容量のストレージも必須です。
DeepSeek-V3.2の使用にかかる料金|API料金とコストを抑える使い方

DeepSeekはオープンウェイトモデルであるため、アプリでの使用やモデルの重みをダウンロードしてローカルで使用する場合にはAPI利用料金がかかりません。
一方でAPIを通して利用する場合には使用トークンに応じた利用料金がかかります。そのため、ここでは主にAPIの利用にかかる料金についてご紹介します。
DeepSeek-V3.2のAPI料金テーブル
DeepSeek-V3.2の各モデルを使用する際にかかるAPI料金は以下の通りです。なお、すべて100万トークンあたりの料金です。
| モデル | バージョン | 入力(ヒット) | 入力(ミス) | 出力 |
|---|---|---|---|---|
| deepseek-chat | DeepSeek-V3.2(非思考モード) | $0.028 | $0.28 | $0.42 |
| deepseek-reasoner | DeepSeek-V3.2(思考モード) |
DeepSeek-V3.2にはAPI経由で2つのモデルを提供していますが、すべてのモデルで同じ料金体系となっています。ただし、思考モードはユーザーに見えない内部思考プロセスで大量のトークンを生成・消費するため、実質的な1リクエストあたりの料金は高くなる傾向があります。
また、コンテキストキャッシュ機能があり、キャッシュがヒットした場合の入力料金は10分の1にまで減少します。
なお、料金については変更になる可能性があるため、公式のドキュメントを参照するようにしてください。
GPT・Geminiとの料金比較
DeepSeekのAPI料金をGPTやGeminiのAPI料金と比較した表がこちらです。すべて100万トークンあたりの料金となります。
| モデル | 入力 | キャッシュされた入力 | 出力 |
|---|---|---|---|
| DeepSeek-V3.2 | $0.28 | $0.028 | $0.42 |
| GPT-5 | $1.25 | $0.125 | $10.00 |
| Gemini 3 Pro | $2.00 (<= 200, 000トークン) $4.00 (>200, 000トークン) | $0.20 (<= 200, 000トークン) $0.40 (>200, 000トークン) | $12.00 (<=200, 000トークン) $18.00 (>200, 000トークン) |
同等の知能レベルを持つGPT-5やGemini 3 Proと比較して、およそ10分の1から20分の1という圧倒的な安さを誇ります。
例えば、GPT-5クラスのモデルで100万トークンを処理すると数ドルから10ドル以上のコストがかかるのが一般的ですが、DeepSeekであればわずか数十セントで完結します。
これを月額コストでシミュレーションすると、中規模なAIサービス運用において他社APIで月額3,000ドル(約45万円)かかるワークロードが、DeepSeekに切り替えるだけで月額150ドル(約2万円強)程度に圧縮される計算になります。
この圧倒的な低価格の実現は、スタートアップや個人の開発者にとって、高度なAI機能を実装するハードルを大きく下げる要因となるでしょう。
コストを抑えるプロンプト設計・運用のコツ
コストを最小限に抑えるための最も重要なポイントは、コンテキストキャッシュのヒット率を高めるプロンプト設計と、思考モードの適切な利用です。
システムプロンプトやナレッジベースのプレフィックスを統一し、キャッシュを効かせることで、入力コストの大部分を削減することが可能です。
また、思考モードは強力ですが、単純な質問に対しても長考してトークンを消費する傾向があるため、数学や複雑な論理が必要な場合以外は非思考モードモデルにルーティングする設計が推奨されます。
さらに、出力トークン数を節約するために、冗長な挨拶を省き、JSON形式のみで回答させるような指示を加えることも、長期的な運用コスト削減に寄与します。
ローカル運用時にかかるハードウェア・電気代の考え方
ローカル運用を選択すれば利用料金は無料になりますが、代わりに高額なハードウェア投資と継続的な電気代という固定費が発生します。
DeepSeek-V3.2のような巨大モデルを快適に動かすには、最低でもH100や複数枚のRTX 5090などといったハイエンドGPUが必要であり、初期導入コストは数百万円から一千万円規模に達します。
さらに、これらのシステムを常時稼働させると消費電力が大きくなり、日本の電気料金換算で月額数万円〜10万円程度の電気代がかかるケースも珍しくありません。
そのため、機密情報の保護が絶対条件である場合や、24時間休みなく大量の推論を行う大規模システムでない限り、トータルコストの観点からはAPIを利用する方が経済的合理性が高い場合が多いです。
DeepSeek-V3.2の活用例|業務でどう使うか
最後に、DeepSeek-V3.2の具体的な活用例をご紹介します。
開発チームでの活用:コード生成・レビュー・設計補助
DeepSeek-V3.2は、多くのプログラミングベンチマークで最高水準のスコアを記録しており、開発現場ではコーディング支援ツールのバックエンドとして即戦力となります。特にコードの途中補完やリファクタリングにおいて、前後の文脈を考慮した精度の高い提案が可能です。
リポジトリ全体をコンテキストとして読み込ませても、DSA技術により高速に処理できるため、大規模プロジェクトにおける複雑な依存関係を理解した上でのバグ修正やコードレビューに威力を発揮します。
APIコストが極めて安価であるため、CI/CDパイプラインに組み込み、プルリクエストごとに自動レビューを実施させる運用も現実的です。
ビジネス部門での活用:レポート生成・ナレッジ検索・問い合わせ対応
ビジネスサイドでは、DeepSeek-V3.2の128Kトークンという長いコンテキストウィンドウと、コンテキストキャッシュ機能が業務効率化の鍵となります。
例えば、社内の膨大なマニュアルや過去の議事録、契約書などを一度読み込ませてキャッシュ化することで、RAGシステムを低コストで構築でき、社員からの問い合わせに即座に回答する社内AIアシスタントを実現できます。
マーケティングや企画業務においては、思考モードを活用することで、市場調査データや競合レポートを深く分析させ、表面的な要約にとどまらない洞察を含んだ戦略レポートを作成させる使い方が有効です。
安価なAPI料金を活かし、顧客からの問い合わせメールに対する一次回答案を全件自動生成させ、担当者が確認・修正するフローを組むことで、対応工数を大幅に削減することも可能です。
セキュリティ重視プロジェクトでのローカルLLMとしての使い方
金融機関、医療機関、あるいは政府系プロジェクトなど、データを外部クラウドに送信することが許されない厳格な環境において、DeepSeek-V3.2は最適なソリューションとなります。
オープンウェイトモデルであるため、自社のオンプレミスサーバーに構築したGPUサーバーにモデルを展開することで、インターネットから隔離された完全にセキュアな環境でGPT-5級のAI能力を利用できます。
この運用により、顧客の個人情報や企業の未公開技術情報が第三者のサーバーに保存されたり、AIの学習データとして利用されたりするリスクを低減できます。
また、自社のドメイン知識を学習させるファインチューニングを自社環境内で完結できるため、セキュリティを維持したまま、業務特化型の高性能AIを独自に育成・資産化することが可能です。
既存のChatGPT/Gemini/Claude環境との併用パターン
単一のモデルに依存せず、DeepSeek-V3.2と他社モデルを適材適所で使い分けるハイブリッド運用も有効です。
コストパフォーマンスに優れるDeepSeek-V3.2をデフォルトのモデルとして日常的なタスクや大量のデータ処理に割り当て、より高い創造性や繊細な日本語表現、あるいは高度な画像認識が必要な場面でのみ、GPTやGemini、Claudeに切り替えるルーティング設計がおすすめです。
また、重要な意思決定や複雑なコード生成においては、DeepSeek-V3.2(思考モード)とGPT-5の両方に同じ指示を出し、それぞれの回答を比較検討するセカンドオピニオンとしての使い方も有効です。
特にGPTの場合、DeepSeekはOpenAI互換のAPIを持っているため、既存のシステム設定をわずかに変更するだけでこのような併用環境を容易に構築でき、コスト削減と品質向上を両立できます。
まとめ
DeepSeek-V3.2はオープンソースでありながらも、OpenAIやGoogleの最新モデルに迫る性能を持ったモデルです。
公式のアプリから無料で利用できるほか、重みをダウンロードしてローカル環境で運用することも可能です。
また、API料金が他社モデルと比べて非常に安価であるため、ローカル運用の環境構築が難しい場合でも低コストでシステムに組み込むことができます。
最新のオープンソースモデルの性能をぜひ体感してみてください。