

gpt-ossとは、OpenAIが新たに発表したオープンウェイトの言語モデルです。
gpt-oss-120Bとgpt-oss-20Bという2つのモデルが存在し、それぞれパラメータ数が異なります。
重みがすべて公開されているため、ローカル環境にダウンロードして使用することが可能です。
この記事では、gpt-ossの概要や2つのモデルの違い、そしてOllamaやGroqを用いた使い方について解説します。
OpenAIのgpt-ossとは?

gpt-ossとは、2025年8月5日にOpenAIが発表した、新しいオープンウェイトの大規模言語モデル(LLM)です。
公開されたモデルには、1170億パラメータを持つ高性能版のgpt-oss-120Bと、210億パラメータの軽量版であるgpt-oss-20Bの2種類があります。
どちらのモデルもHugging Faceから無料で重みをダウンロードすることが可能です。
これは、OpenAIが2019年にGPT-2を公開して以来、数年ぶりにリリースしたオープンウェイトモデルであり、大きな戦略転換として注目されています。
Apache2.0ライセンスの下で公開されているため、研究者や開発者はもちろん、企業も商用目的で自由に利用、改変、配布することが可能です。
オープンウェイト化の背景
OpenAIがモデルのオープンウェイト化に踏み切った背景には、AI市場における競争環境の激化があります。
特に、GoogleのGemmaやMetaのLlama、AlibabaのQwenなどの高性能なオープンウェイトモデルが次々と発表され、開発者コミュニティで強い支持を得ていました。
このような市場の動向を受け、OpenAIも開発者や企業の多様なニーズに応える必要がありました。
データを外部に出せない、あるいは特定の用途に自由にカスタマイズしたいという声に応え、ローカルLLMでの影響力を確保する戦略的な判断が、今回のリリースにつながったと考えられます。
主な特徴
gpt-ossの主な特徴として、まず同規模のオープンモデルを凌駕する高い推論性能が挙げられます。
この性能は、特に複雑な思考を要するタスクで優れた能力を発揮します。
また、軽量版のgpt-oss-20Bは一般的なGPUでも動作するほど効率的に設計されており、ローカル環境での開発やアプリケーションへの組み込みを容易にします。
さらに、最大128kトークンのコンテキスト長をサポートしているため、長文の文書を扱うタスクにも強力です。
OpenAIのgpt-oss-120Bとgpt-oss-20Bの違い
今回公開されたモデルは、gpt-oss-120Bとgpt-oss-20Bの2つです。
ここでは、これら2種類のモデルの違いについて解説します。
パラメータ数・推論速度・推奨VRAM
以下に2つのモデルの主な違いを示します。
| モデル | パラメータ数 | 推論速度 | VRAM |
|---|---|---|---|
| gpt-oss-120B | 1170億 | 遅い | 80GB |
| gpt-oss-20B | 210億 | 高速 | 16GB |
gpt-oss-120Bとgpt-oss-20Bの最も大きな違いは、モデルの規模とそれに伴う要求スペックです。
gpt-oss-120Bは合計1170億パラメータを持ち、複雑で精度の高いタスクを実行できますが、推論には80GB程度のVRAMを持つNVIDIA H100のような高性能GPUが必要です。
一方、gpt-oss-20Bは210億パラメータと小規模で、より高速な推論が可能です。
そのため、16GB程度のVRAMでも動作し、一般的なゲーミングPCやワークステーションでも扱いやすくなっています。
目的や利用環境に応じたモデルを選ぶことが大切です。
性能評価
各種ベンチマークテストにおいて、gpt-ossは高い性能を示しています。
特にgpt-oss-120Bは、競技コーディングや一般的な問題解決、ツール呼び出しなどといった高度なタスクで、OpenAIのクローズドモデルであるo4-miniに匹敵するレベルに達しています。
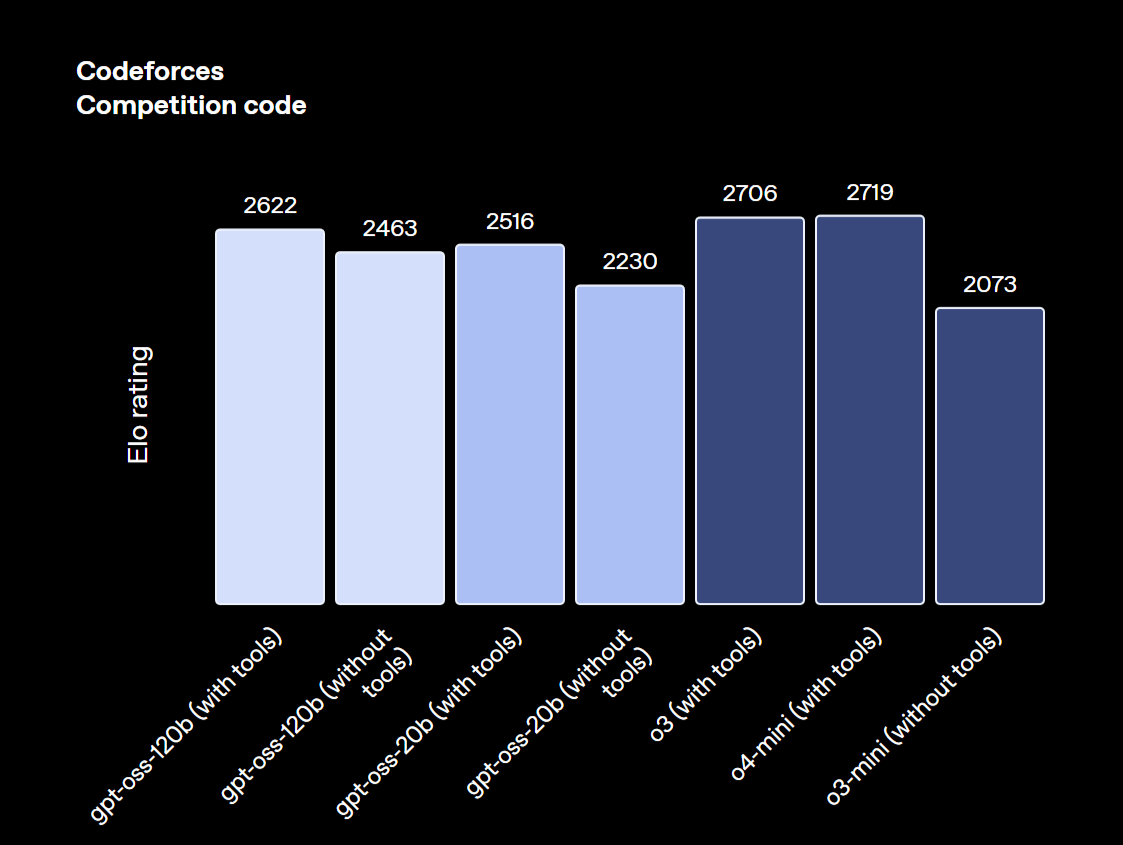
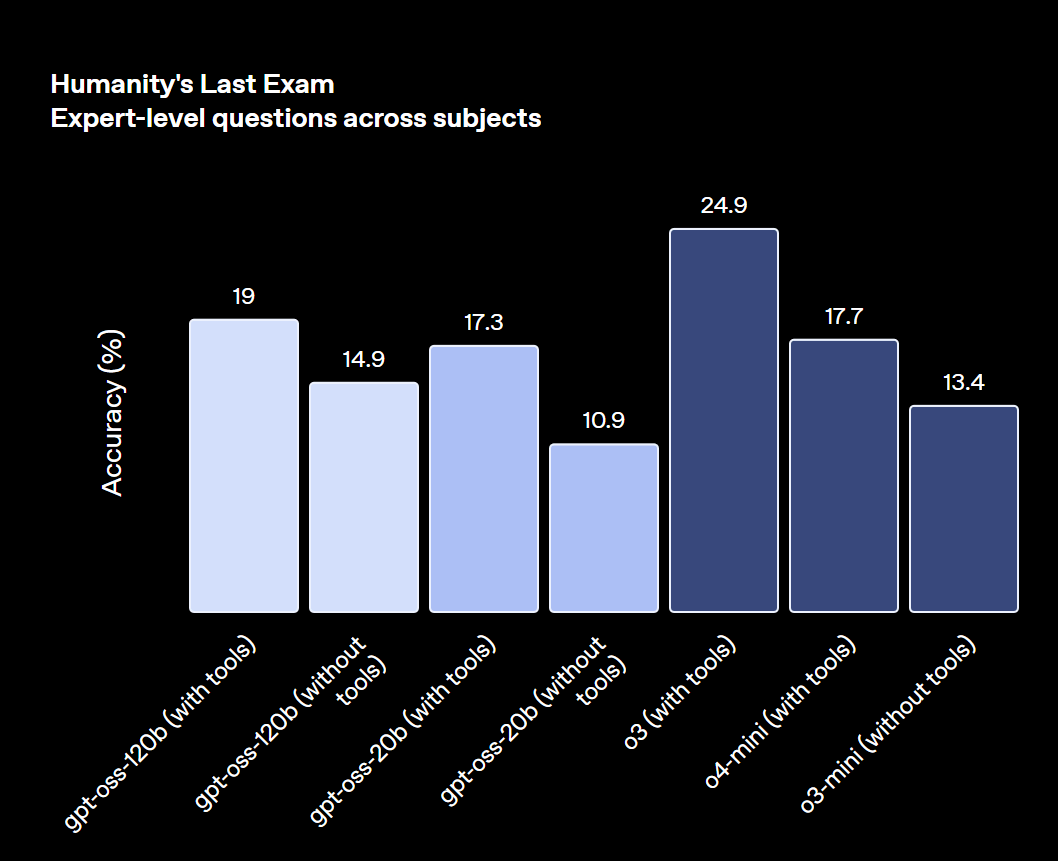
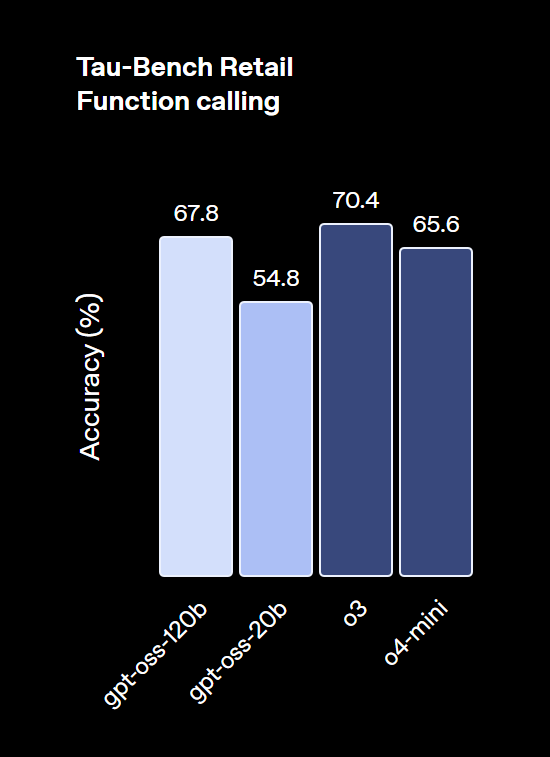
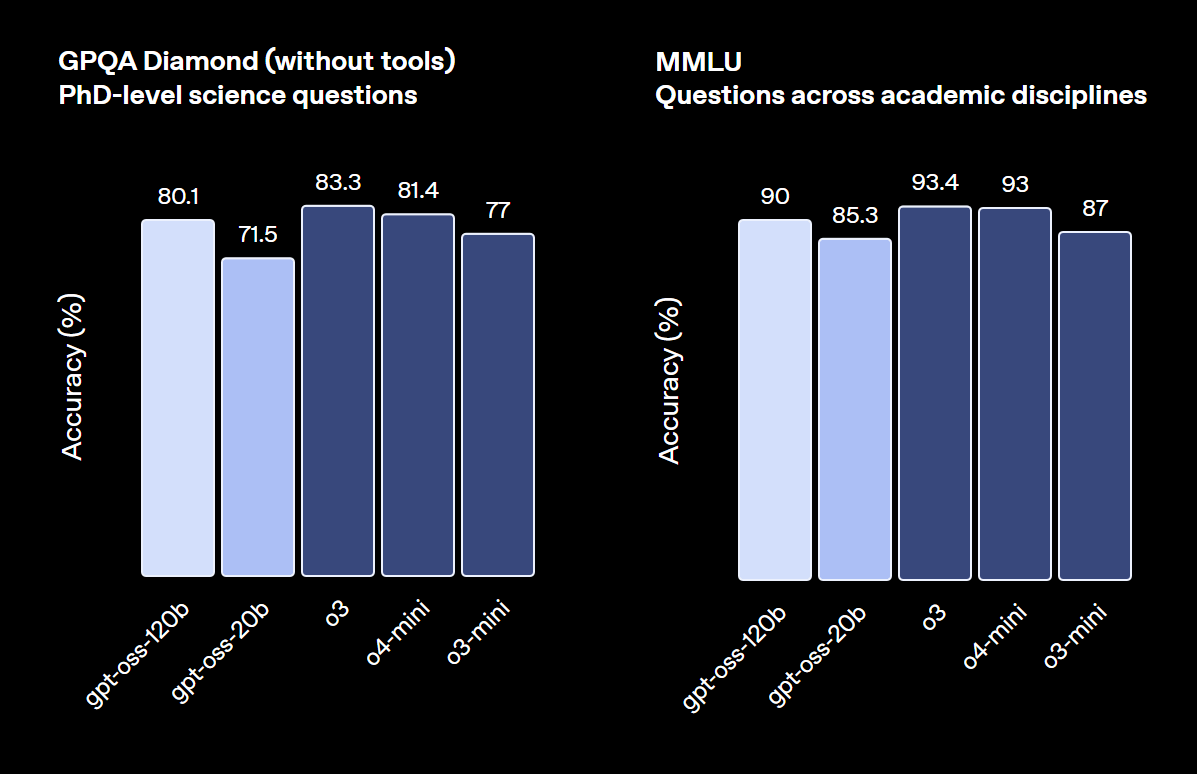

一方でgpt-oss-20Bも、より小規模ながらo3-miniと同等の性能を発揮し、特に医療関連のベンチマークや競技数学のタスクでは優れた結果を見せるなど、軽量モデルとしては卓越した能力を持つことが証明されています。
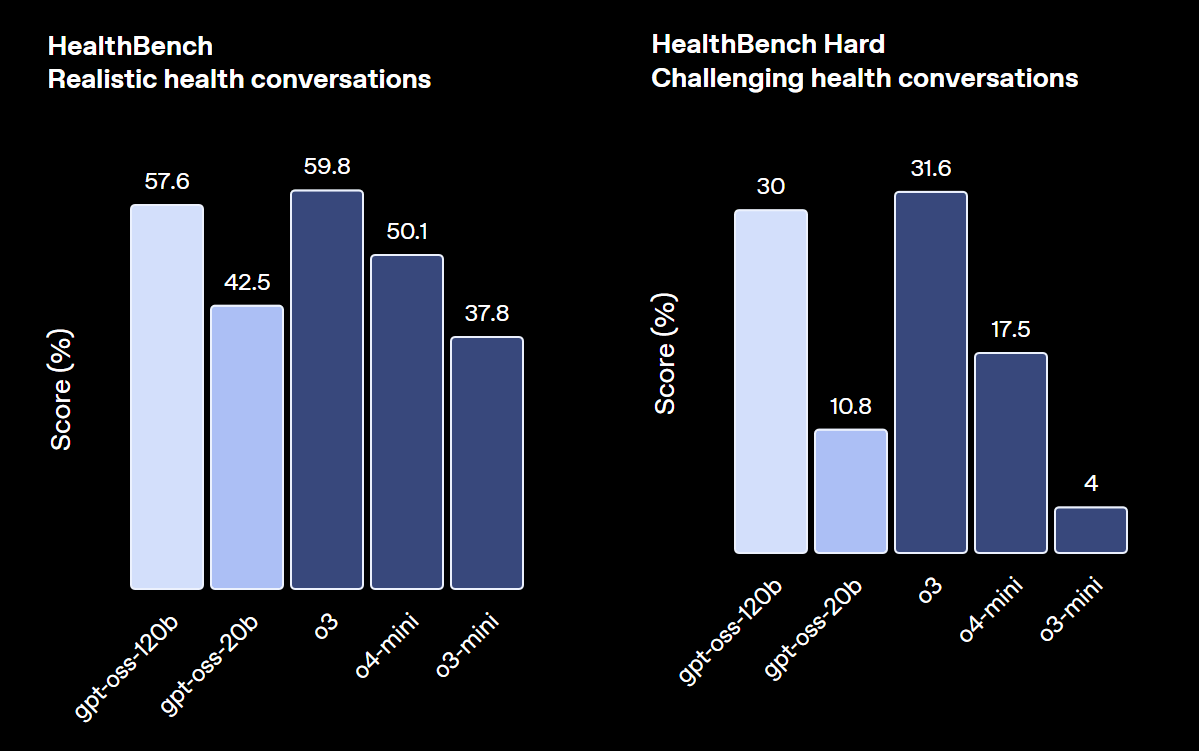
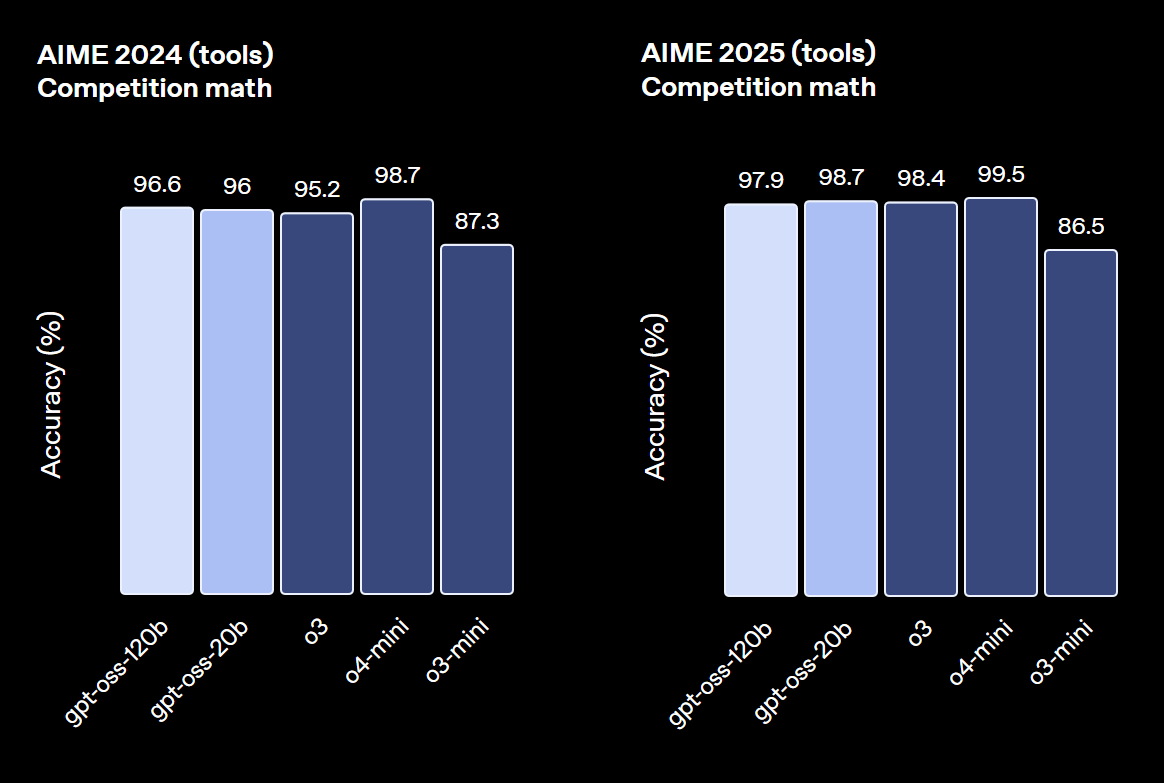
ユースケース別の選び方
どちらのモデルを選ぶかは、目的とする用途によって明確に分かれます。
高い精度と深い思考力が求められる学術研究、専門的な内容の分析、複雑なコーディング支援といった高度なタスクには、gpt-oss-120Bが最適です。
OpenAIのクローズドモデルであるo4-miniに匹敵する推論能力で、高度なタスクを実行できます。
対照的に、リアルタイム性が重要なチャットボット、FAQ応答、一般的な文章作成、コーディングの補助など、速度とコスト効率を重視する場面ではgpt-oss-20Bが適しています。
多くの日常的なタスクを、より手軽にローカル環境でこなすことが可能です。
コストとスケーラビリティ比較
コストとスケーラビリティの観点では、両モデルの性格が大きく異なります。
gpt-oss-20Bは、ローカル環境や比較的安価なクラウドで実行できるため、初期コストと運用コストを低く抑えることができます。
そのため、個人開発者や中小企業がスモールスタートでAIを導入するのに最適です。
一方、gpt-oss-120Bは高性能なGPUインフラが必要となるため、初期投資と運用コストは高額になります。
しかし、その分高い性能を持つため、大規模なサービスや高度なAI機能を持つアプリケーションへのスケールアップに適しており、長期的な投資価値が見込めます。
Ollamaを用いたgpt-oss-20Bの使い方

次に、gpt-oss-20Bの使い方をご紹介します。
gpt-oss-20Bは、OllamaまたはLM studioというサービスを通して利用可能です。
この記事では、Ollamaを利用した使い方を解説します。
Ollamaの概要と動作要件
Ollamaとは、LLMを自分のローカル環境で手軽に実行するためのオープンソースツールです。
簡単なコマンドでモデルのダウンロードや起動ができ、プライバシーを守りながらオフラインでAIを利用できるのが大きな魅力です。
動作要件は使用するモデルの大きさによって変わり、gpt-oss-20Bを動かす場合、16GB以上のVRAM(または統合メモリ)が推奨です。VRAMが不足する場合はCPUへオフロードされ、速度が大幅に低下します。
CPUfのみでも動作しますが、推論速度が大幅に低下するため、快適に利用するにはVRAMも16GB以上あるNVIDIA製のGPUを搭載していることが望ましいです。
なお、OSはWindows、macOS、Linuxのいずれにも対応しています。
Ollamaのインストール手順と環境設定
まずはOllamaをインストールして設定を進めていきます。
Ollamaの公式サイトにアクセスし、利用環境に合ったものをダウンロードします。
インストーラを起動し、Ollamaをインストールしましょう。
コマンドプロンプトで以下のコマンドを実行し、ヘルプ画面が表示されればインストール完了です。
ollama --help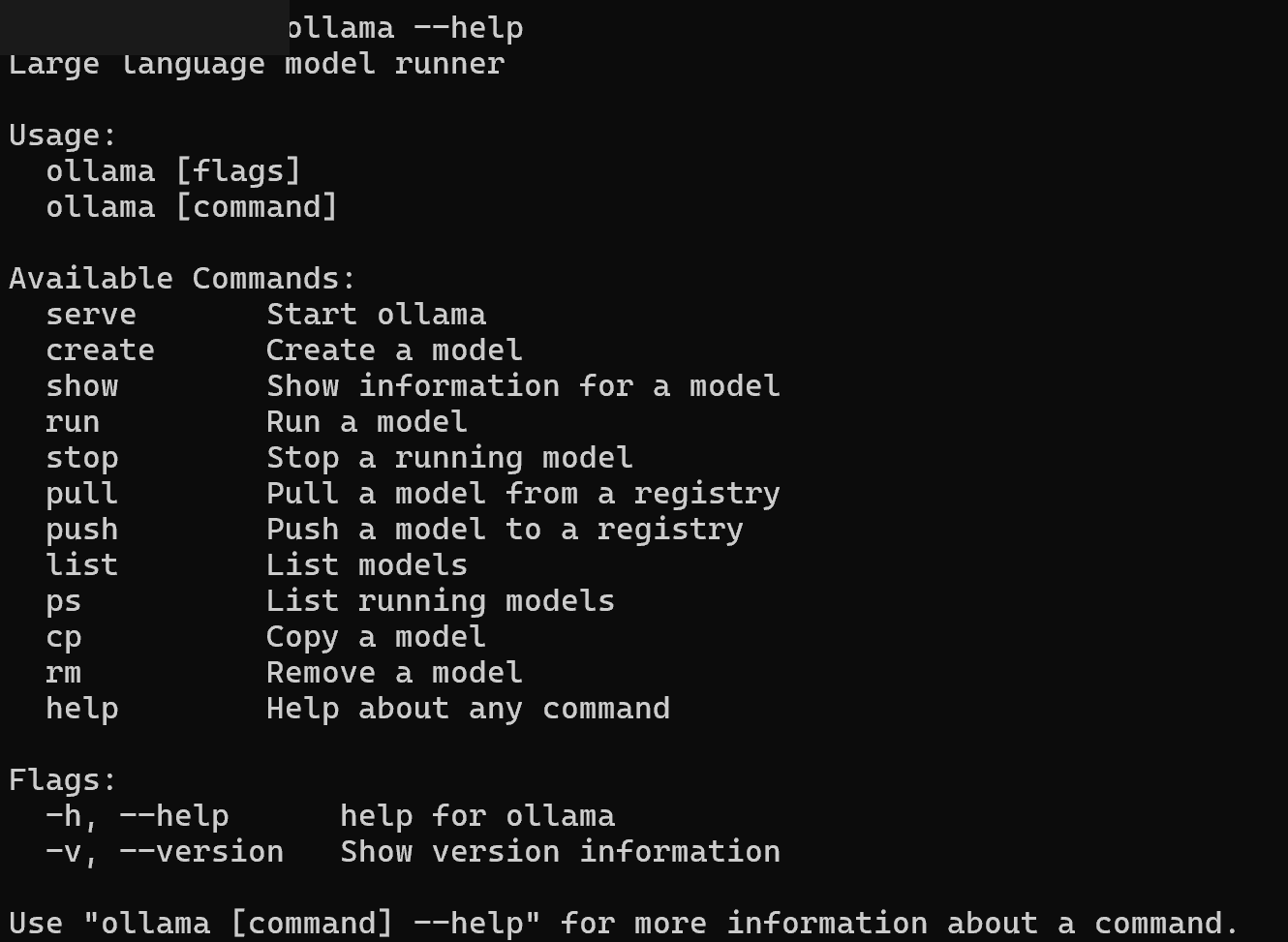
Ollamaの実行方法は、GUIとCUIがあります。
まずは簡単なGUIから説明します。
インストールしたOllamaを開くと、チャット画面が表示されます。
右下のモデルからgpt-oss-20Bを選択しましょう。
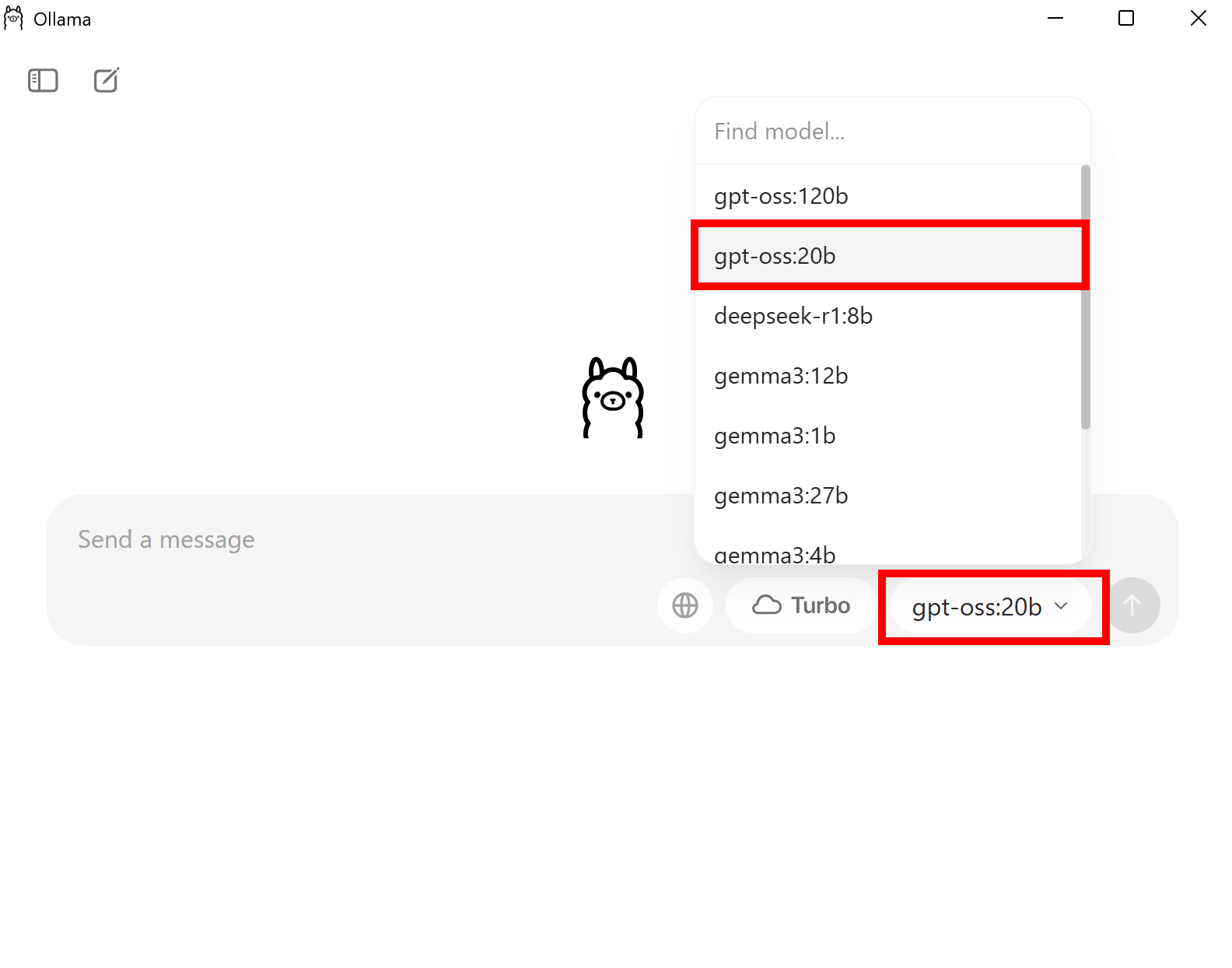
あとはメッセージを送信することで、gpt-oss-20Bが利用できます。
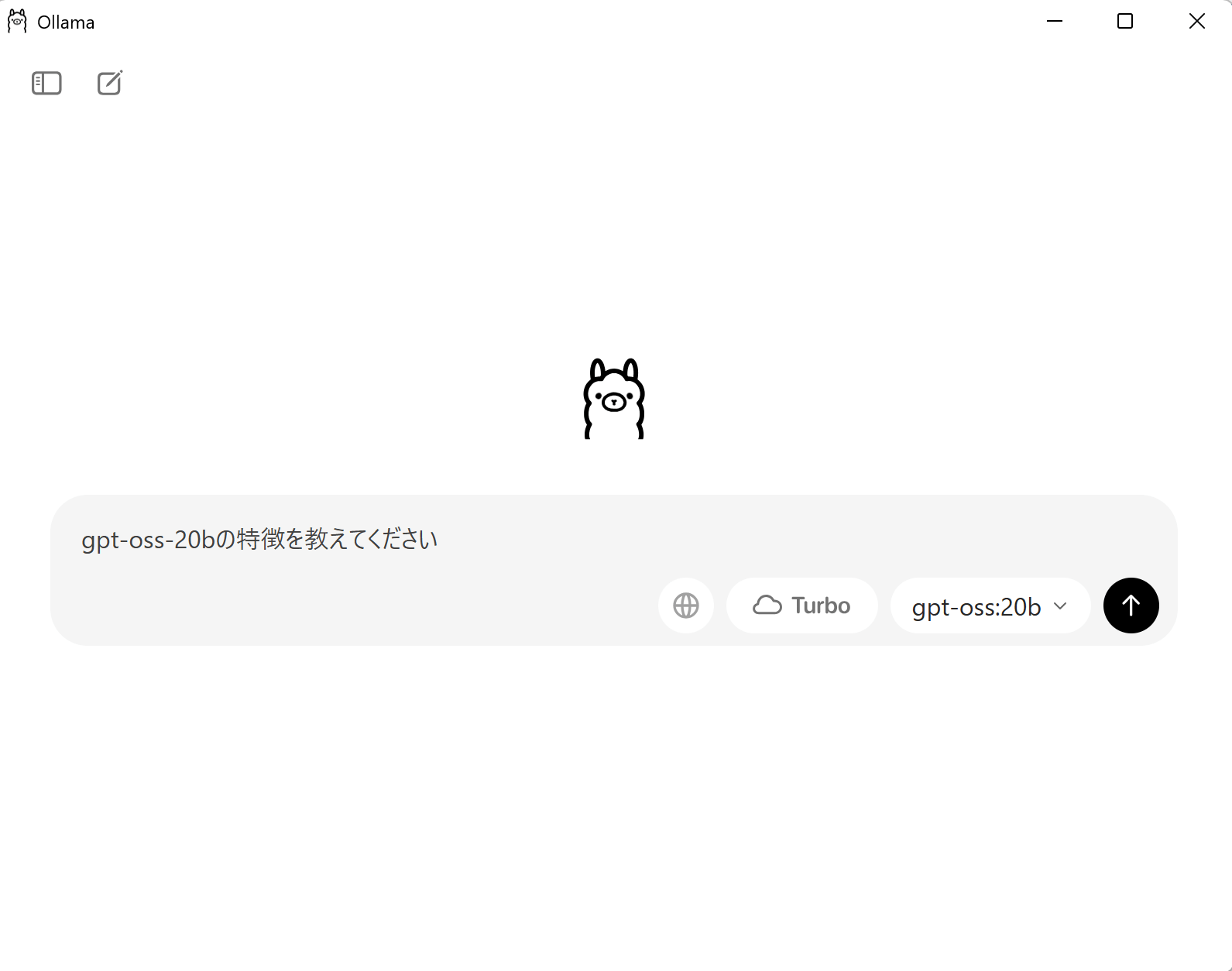
なお、初めてそのモデルを使用する場合は、モデルのダウンロードが始まります。
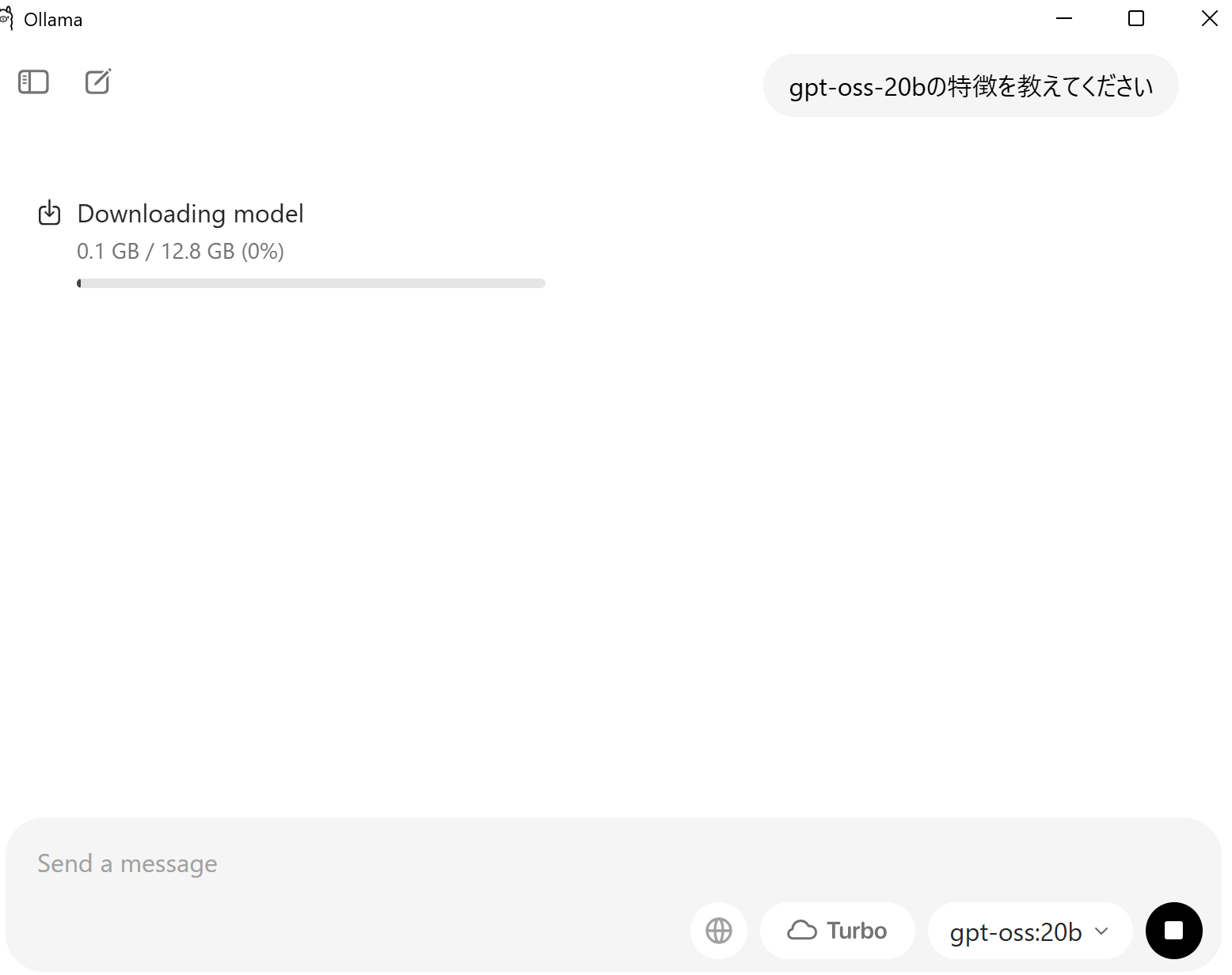
容量が大きいため、ダウンロードにはそれなりに時間がかかります。
ダウンロードが終了すると、送信したプロンプトに対する返答が生成されます。
次に、コマンドプロンプトを使ってgpt-oss-20Bを利用する方法を説明します。
CUIでOllamaを使用するには、以下のコマンドを実行します。
ollama run <モデル名>今回は以下のコマンドを実行しましょう。
ollama run gpt-oss:20bなお、モデル名は公式サイトで調べると出てきます。
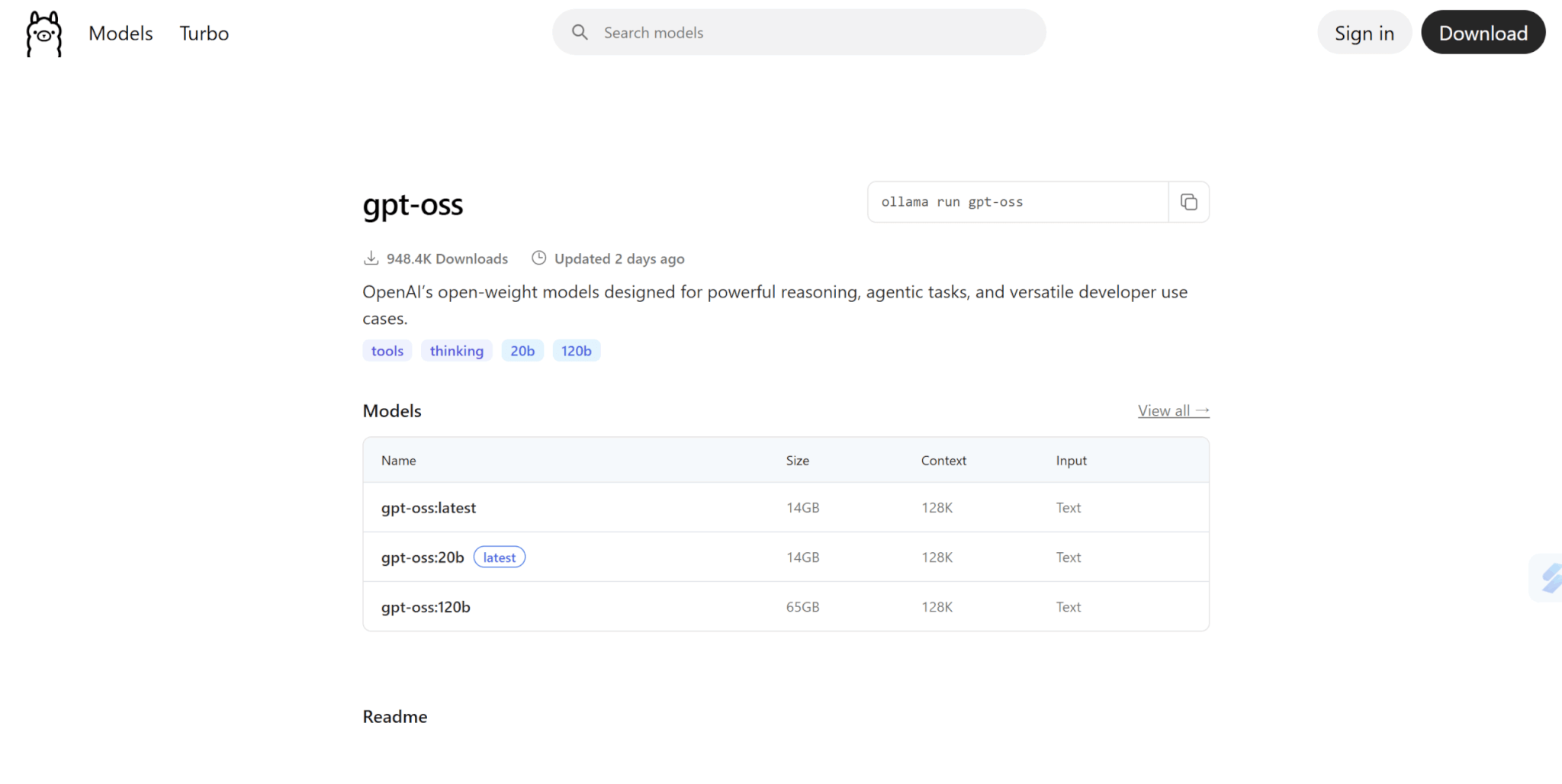
GUIと同様、初めて使用するモデルの場合はモデルのダウンロードが始まります。
ダウンロード終了後は、そのままコマンドプロンプトにメッセージを書き込むことでgpt-oss-20Bを使ってやり取りができます。
なお、ダウンロード済みモデルは以下のコマンドで確認可能です。
ollama list
よくあるエラーと対策
Ollamaでgpt-oss-20Bを利用する際、最も多いエラーはメモリ不足です。
Internal Server Error: model requires more system memoryなどと表示された場合、RAMまたはVRAMが足りていないため、不要なアプリケーションを終了したり、システム要件を満たしているか再確認しましょう。
次に、推論速度が極端に遅い場合は、GPUが正しく認識されていない可能性があります。
NVIDIAの最新ドライバがインストールされているか、またOllamaがGPUを利用する設定になっているかを確認してください。
モデルのダウンロードに失敗する際は、インターネット接続を確認し、コマンドを再実行することで解決する可能性が高いです。
Groqを用いたgpt-oss-120Bの使い方

続いて、gpt-oss-120Bの使い方を解説します。
こちらはかなり大きなモデルとなっているため、通常のローカル環境では動かすことがかなり難しいでしょう。
そこで、今回はGroqを用いてgpt-oss-120Bを動かす方法を説明します。
Groqとは?
Groqとは、AIの推論処理に特化したLPU(Language Processing Unit)という独自の半導体を開発するアメリカの企業とサービスの総称です。
その最大の特徴は、一般的なGPUを遥かに凌ぐ圧倒的な推論速度と低遅延を実現することにあります。
この驚異的なスピードは、言語モデルの逐次的な処理に最適化された、GPUとは根本的に異なるアーキテクチャによって達成されています。
ユーザーは、Groqが提供するクラウドプラットフォーム「GroqCloud」を通じて、API経由でこの高速な推論エンジンを利用できます。
これにより開発者は、gpt-oss-120Bのような大規模モデルを、リアルタイム性が求められるアプリケーションに組み込むことが可能です。
GroqのLPUアーキテクチャの概要
GroqのLPU(Language Processing Unit)は、AIの推論処理に特化して設計された新しいプロセッサです。
一般的なGPUが並列処理を得意とするのに対し、LPUは決定論的な逐次処理を行うことで、言語モデルの処理でボトルネックとなるメモリ帯域の問題を解消します。
具体的には、コンパイラがハードウェアを完全に制御し、キャッシュやスイッチを排除したシンプルな構造により、データがチップ内をスムーズに流れます。
このTensor Streaming Processor (TSP) と呼ばれるアーキテクチャが、一貫して低遅延かつ驚異的な推論速度を実現する理由です。
Groqでgpt-oss-120Bを動かす方法
それでは実際に、Groqを用いてgpt-oss-120Bを動かす方法を解説していきます。
ここでは、Groq CloudというWeb上で使用できるサービスを使ったやり方を説明します。
Groqのアカウントを持っていない方は、公式サイトから登録しましょう。
「Start Building」をクリックすると、アカウント登録画面に遷移します。
GoogleアカウントやGitHubアカウント、またはメールアドレスで登録可能です。
送られてきたメールの「Continue」をクリックすると、登録完了です。

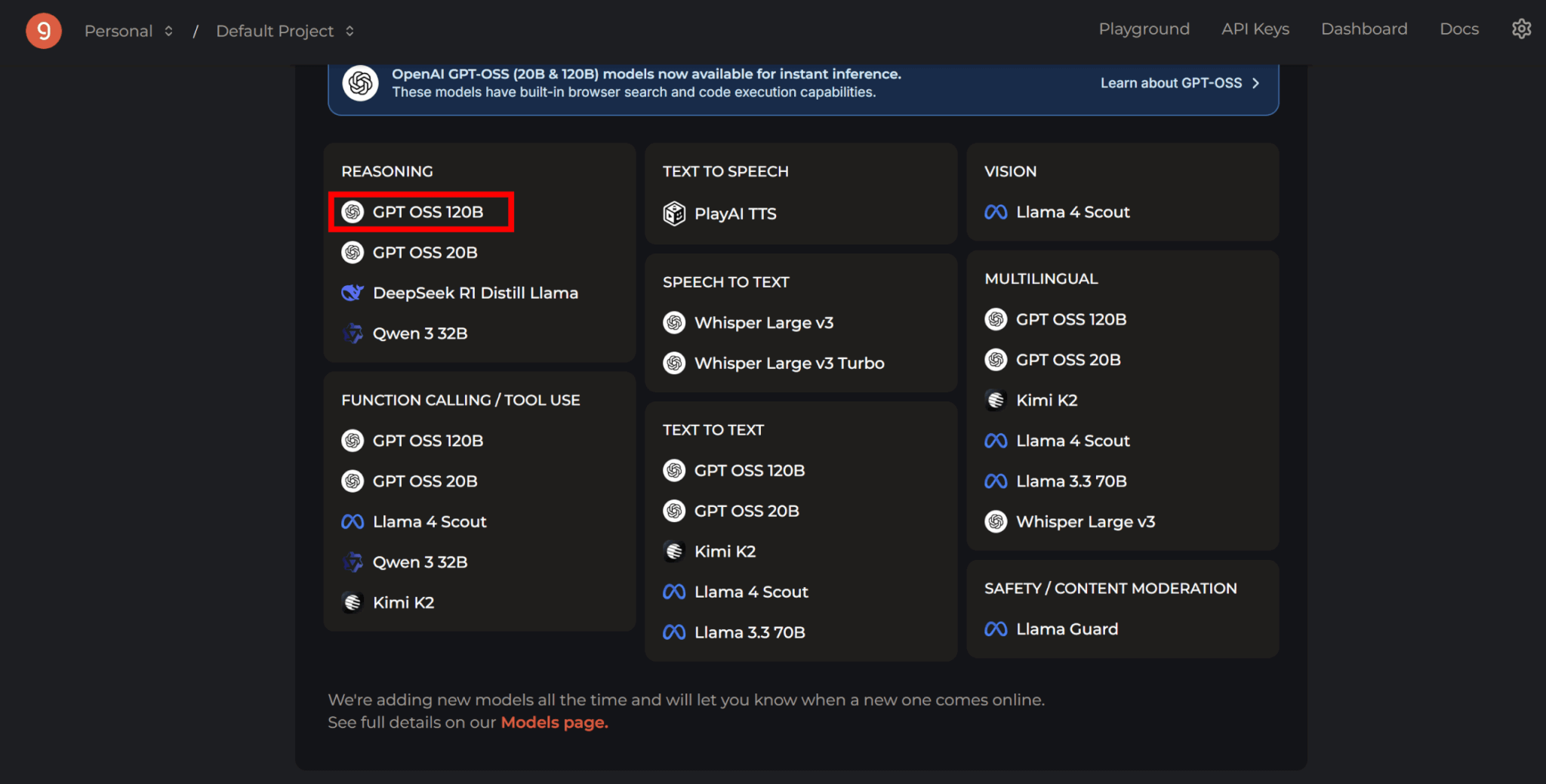
ログイン後、表示されているモデル一覧の中から「GPT OSS 120B」を選択します。
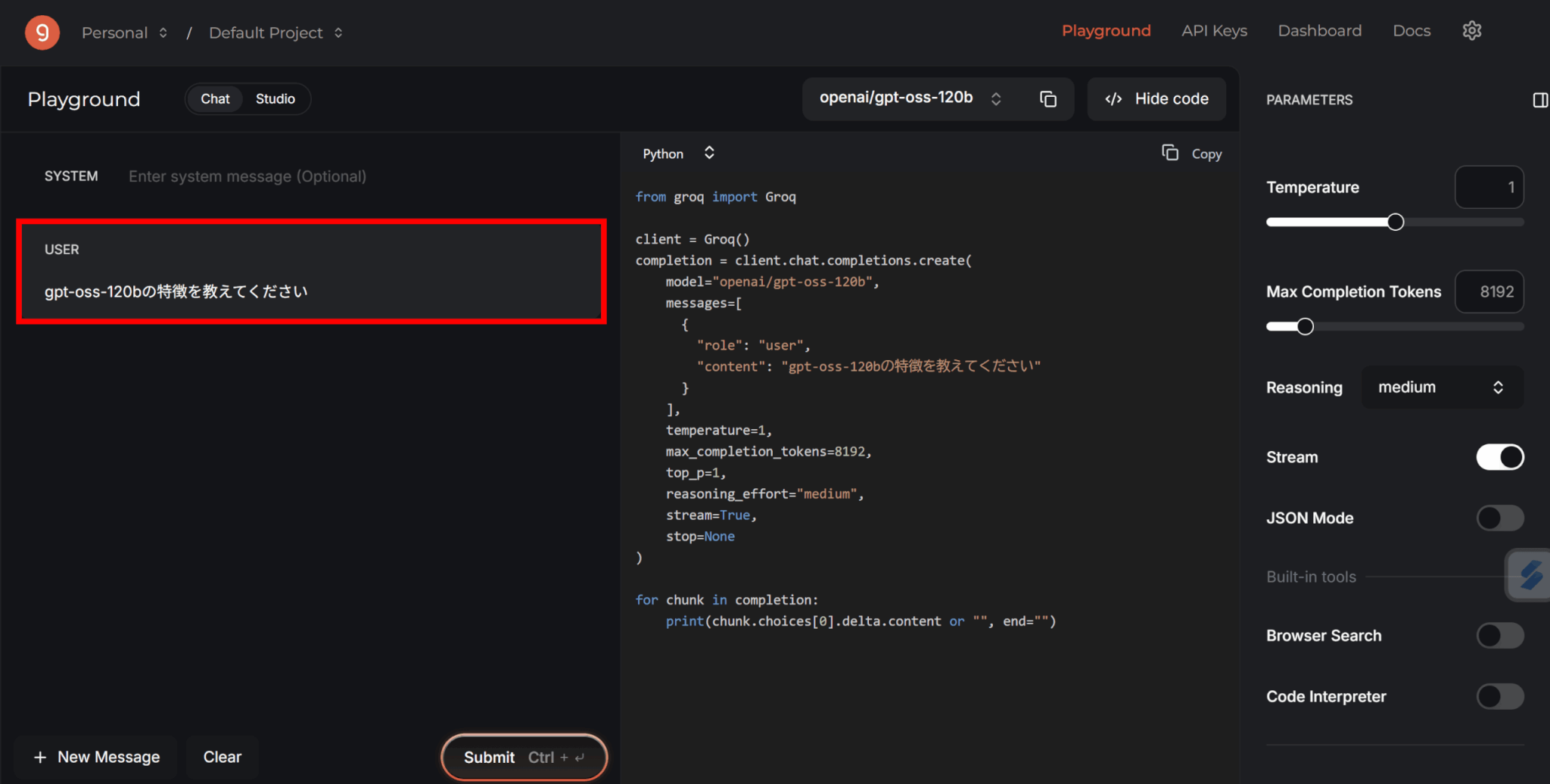
画面左にチャット欄が現れるため、ここにプロンプトを入力しましょう。
下の「Submit」をクリックすると、プロンプトが送信されてAIから返答が来ます。
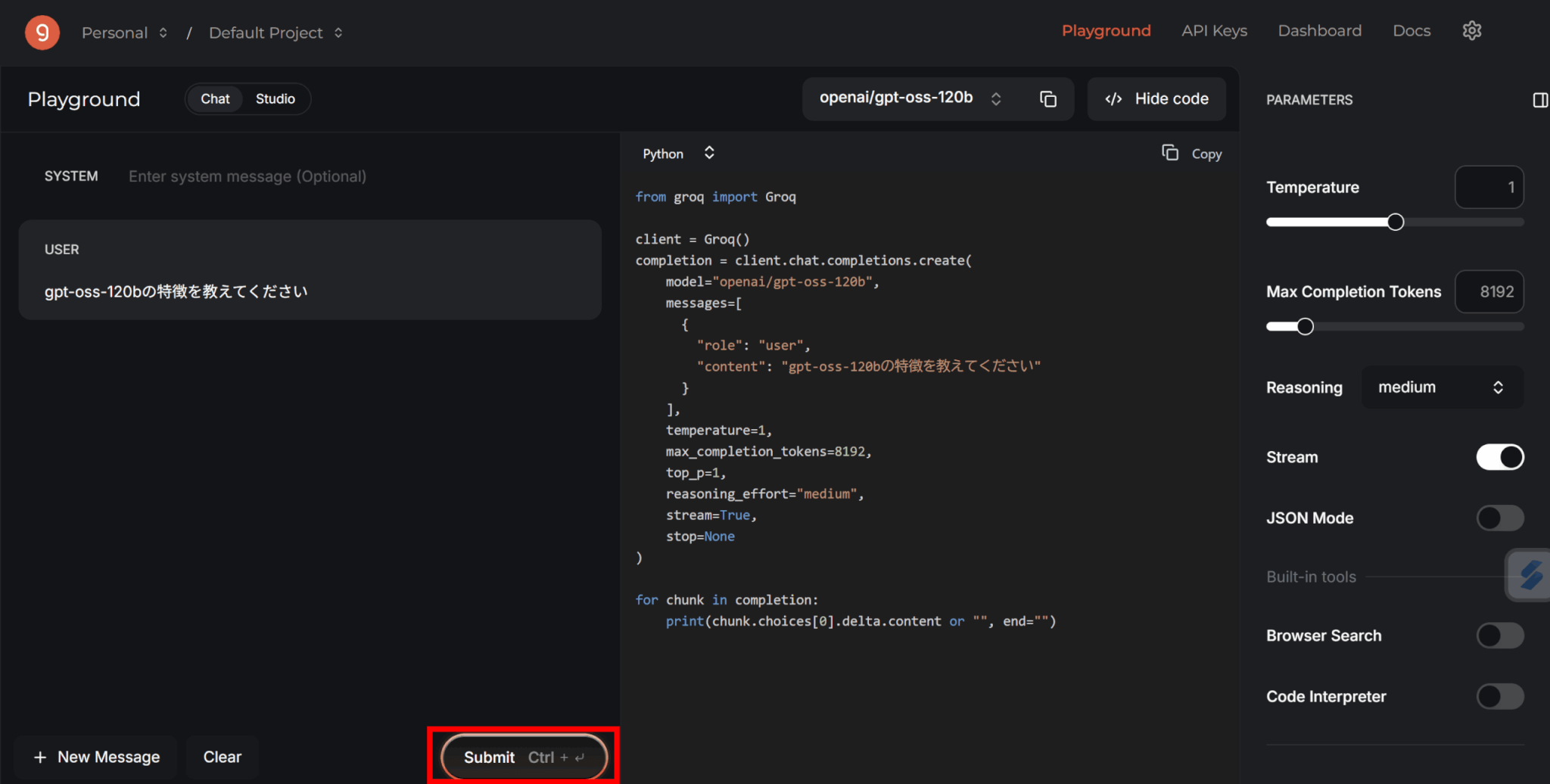
120Bというローカルで動かすにはかなり大きなモデルですが、あっという間に回答を生成してくれました。
APIを使ったやり方
GroqはAPIキーを使用することで、チャットボットなどにAIモデルを活用することもできます。
APIキーを使ったやり方は以下のようになっています。
まずは画面右上の「API Keys」をクリックします。
次に「Create API Key」をクリックします。
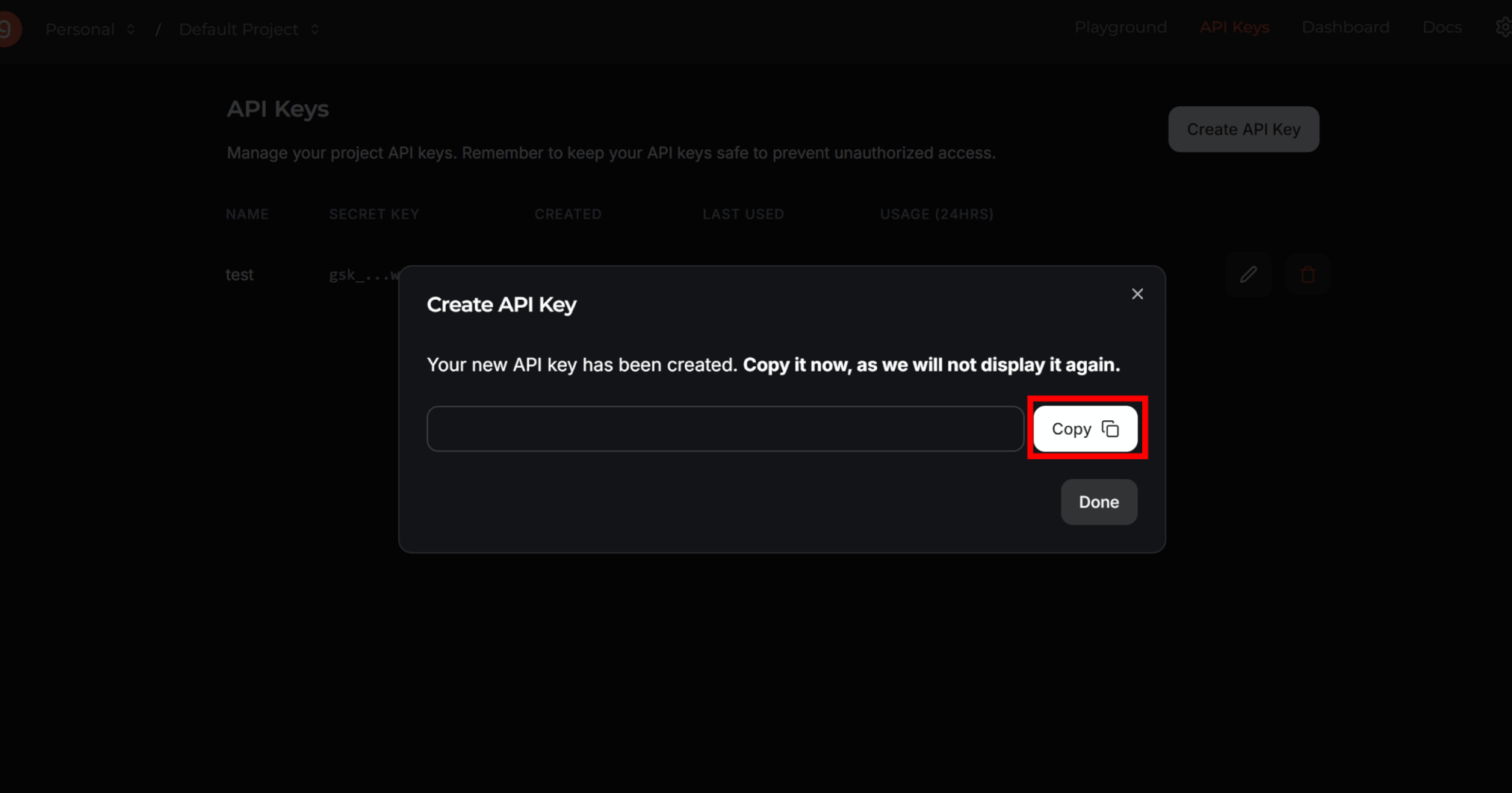
APIキーの名前を決め、「Submit」をクリックするとキーが作成されます。
ここで表示されるキーは二度と見られないので、「Copy」を押してコピーし、安全な場所に保管しておきましょう。
続いて、取得したAPIキーを環境変数に設定します。
APIキーはコードに直接書き込んでも動きますが、安全性を考えて環境変数で使用することをおすすめします。
プロジェクトに使用するファイルの.envファイルに以下のコードを書き加えましょう。
GROQ_API_KEY=YOUR_API_KEY次に、Groq APIを使用したコードを作成します。
なお、Groq CloudではAIモデルを使用するためのコードが自動で生成されているため、こちらをコピペすると簡単です。
好きな言語を選択してコピーしましょう。
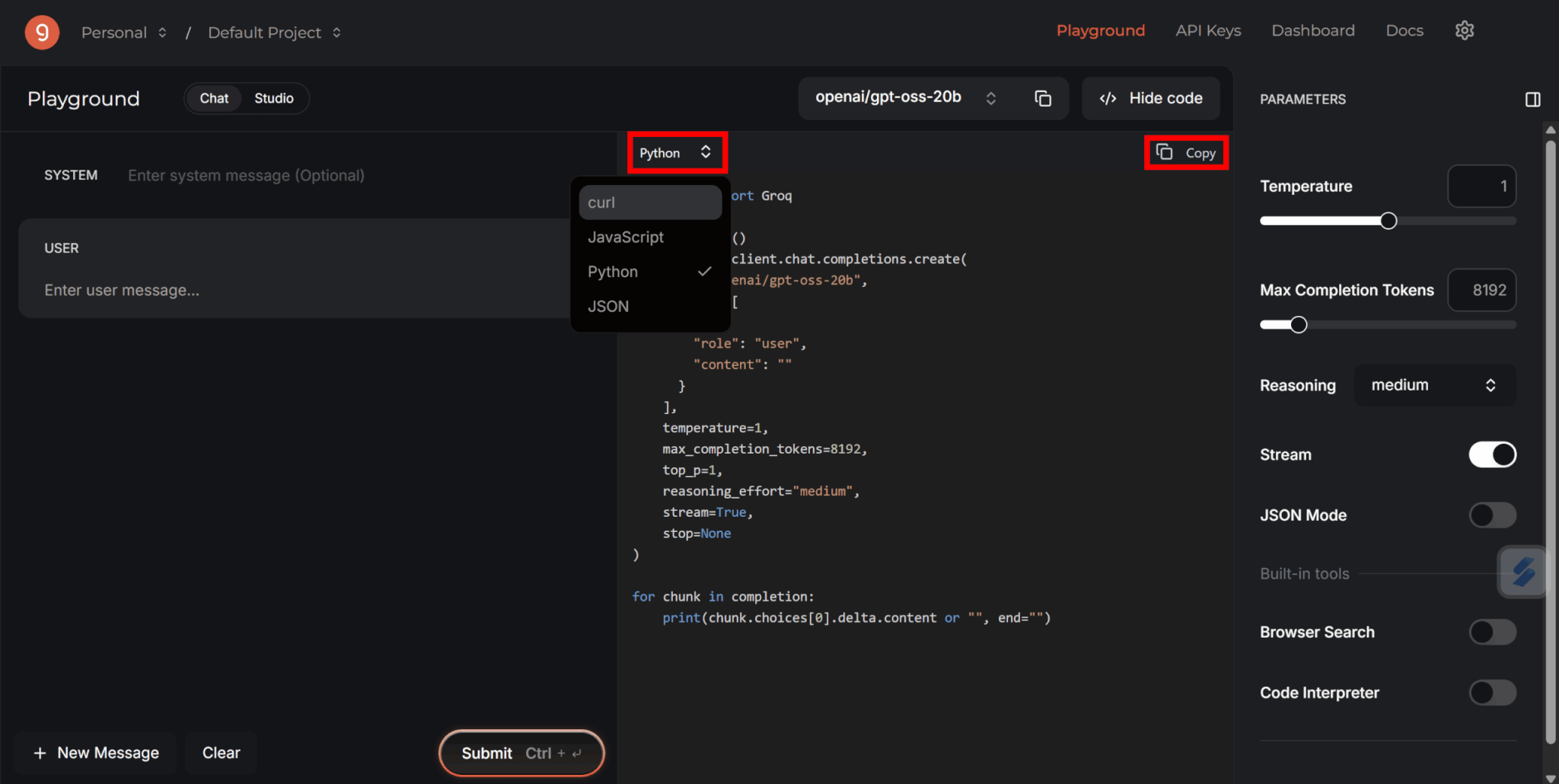
この記事ではPythonを使用して進めます。
コピーしたコードを貼り付けた後、最初の部分を以下のように書き換えてください。
import os
from groq import Groq
from dotenv import load_dotenv
load_dotenv()
client = Groq(api_key=os.environ.get("GROQ_API_KEY"))
コードを実行する前に、Groqのライブラリをインストールします。
pip install groqインストールが完了すれば、先ほど作成したコードを実行しましょう。
今回は単純な返答生成でしたが、うまく活用すればチャットボットなどさまざまなプロダクトにAIを組み込むことが可能です。
ランニングコストと運用時の注意点
Groqには無料枠があるため、レート制限までは無料で利用可能です。
2025年8月現在のレート制限は以下のようになっています。
| モデル | リクエスト数/分 | リクエスト数/日 | トークン数/分 | トークン数/日 |
|---|---|---|---|---|
| gpt-oss-120B | 30 | 1,000 | 8,000 | 20万 |
| gpt-oss-20B | 30 | 1,000 | 8,000 | 20万 |
アップグレードして利用する場合、ランニングコストはトークン単位の従量課金制です。
100万トークン単位の料金は以下のようになっています。
| モデル | 速度(トークン数/秒) | 入力トークン | 出力トークン |
|---|---|---|---|
| gpt-oss-120B | 500 | 0.15ドル | 0.75ドル |
| gpt-oss-20B | 1,000 | 0.10ドル | 0.50ドル |
料金は他のクラウドサービスと比較しても安めの設定となっています。
しかし注意点として、GroqはAPI経由での利用が基本であり、ローカル環境で動かすOllamaとは異なり、常時インターネット接続が必要です。
また、その速度ゆえに、意図せず大量のトークンを消費してしまう可能性もあるため、開発段階では使用量の上限設定やモニタリングをこまめに行うことが重要です。
gpt-ossを導入するメリットと注意点

最後に、gpt-ossを導入するメリットや、使う上での注意点をまとめます。
コスト・ライセンスの利点
gpt-ossを導入する最大のメリットは、コストとライセンスの柔軟性にあります。
APIベースのモデルと異なり、一度ハードウェアを準備すれば、トークンごとの従量課金を気にすることなく無制限に利用できます。
そのため、運用コストを大幅に削減できます。
また、Apache 2.0という非常に寛容なライセンスが採用されている点も大きな利点と言えます。
これにより、誰でも無料でモデルをダウンロードし、研究、改変、そして商用サービスへの組み込みまで自由に行うことが可能です。
このオープンなライセンス形態によって、企業のAI導入のハードルが下がり、さまざまな開発に利用できるようになるでしょう。
セキュリティとプライバシー
セキュリティとプライバシーが確保できることは、オープンウェイトモデルであるgpt-ossを導入する上で重要なメリットでしょう。
モデルを自社で管理するサーバーやローカルPC上で完全に動作させることができるため、ローカル推論に限れば、機密情報を外部サーバーへ送信する必要はありません。
これにより、情報漏洩のリスクが減り、GDPRや医療、金融といった厳格なコンプライアンス要件が求められる業界でも安心してAIを活用できます。
外部APIを利用する場合に常に付きまとうプライバシーの懸念から解放される点は、多くの企業にとって大きな魅力と言えるでしょう。
競合モデルとの比較
gpt-ossは、数ある競合オープンソースモデルの中でも、特に推論能力の高さで際立っています。
特にgpt-oss-120Bは、OpenAIの高性能クローズドモデルであるo4-miniに匹敵する能力を持ちながら、商用利用可能なライセンスで提供される点が大きな強みです。
競合モデルには商用利用に制限があるものも存在する中で、この性能とライセンスの組み合わせが、gpt-ossの競合モデルに対する優位性と言えます。
gpt-ossを使用する場合の注意点
gpt-ossの利用にはいくつかの注意点も存在します。
まず、モデルをローカル環境で動かすためには、高性能なGPUや大容量のメモリといった高価なハードウェアへの初期投資が必要不可欠です。
また、モデルのセットアップや保守、ファインチューニングには、専門的な技術知識を持つ人材が求められ、自社で運用体制を構築する必要があります。
さらに、不適切なコンテンツを生成しないよう、安全対策や倫理的配慮も自社で行う責任が生じます。
もちろん、生成AIを使用する際の注意点であるハルシネーションにも気を付けなければなりません。

まとめ
gpt-ossは高い性能を持つオープンウェイトの言語モデルであり、ダウンロードすることでローカル環境でもAIを利用できます。
さまざまなプロダクトに組み込むことも可能であるため、うまく活用することでこれまでよりも運用コストを減らすことができるでしょう。
一方でモデルを動かすための要件はそれなりに高いので、PCのスペックがあまり高くない場合はGroqなどのサービスを活用しながら利用するのがおすすめです。