

ChatGPTを使った調べ物や記事作成で、答えをどこまで信じてよいか迷うことはありませんか。誤情報をそのまま採用して、公開後に修正したり、確認に余計な時間を取られたりする事態は避けたいはずです。
ChatGPTのハルシネーションとは何か、ChatGPTの嘘をつく現象への向き合い方、ChatGPTに嘘をつかせない考え方やハルシネーション対策のプロンプトまで押さえると、確認が必要な回答を見分けやすくなります。
この記事では、ChatGPTのハルシネーション対策を、原因・起きやすい場面・確認方法まで実例付きで整理します。
ChatGPTのハルシネーションとは?

ChatGPTのハルシネーションとは、事実と異なる内容や、根拠を確認できない内容を、自然な文章として返してしまう現象です。
文章が整っているほど正しく見えやすいため、まずは「自然な答え」と「正確な答え」は同じではないと押さえることが大切です。
もっともらしい回答を生成する
ChatGPTが「嘘をつく」と言われるのは、誤った内容でも、それらしく言い切る形で返す場合があるためです。
OpenAIは2025年の解説で、ハルシネーションをもっともらしいが誤った文と位置づけています。
ハルシネーションとは、言語モデルが生成する、もっともらしく聞こえるが正しくない発言のことです。一見単純に見える質問に対してでさえ、ハルシネーションが予想もせずおきる場合があります。
出典:OpenAI
それらしい回答が提示されると、意図的な虚偽ではなくても嘘をつかれたと受け取りやすくなります。
OpenAIの公式発表では、さらに言語モデルの不確実さを認め、より推測して答えやすい構造を説明しています。GPT-5.4はGPT-5.2と比べて誤りが減っている一方で、誤情報そのものがなくなったわけではないと分かります。
ユーザーが事実誤りを指摘した匿名化済みプロンプトのセットで評価したところ、個々の主張が誤っている確率は、GPT‑5.2と比べて相対的に33%低く、回答全体に何らかの誤りが含まれる確率も相対的に18%低いことが確認されました。
出典:OpenAI
つまり、新しいモデルだからといって、回答をそのまま使ってよいとは言えません。滑らかさではなく、出典・固有名詞・数値で確かめる意識を持った方が、ハルシネーションを見抜きやすくなります。
実在しない情報を出すことがある
ハルシネーションが分かりやすく表れるのは、実在しない情報をもっともらしく補ってしまう場面です。
OpenAIは2025年の記事で、誕生日や博士論文名のように本来は一つに定まる事実でも、異なる誤答が返る例を示しています。つまり、単純な事実質問でも、答えが自然に見えるからといって正しいとは限りません。
最近のモデルであるChatGPT-5.4は、最も事実性の高いモデルと位置付けられていますが、それは実在確認が不要という意味ではありません。回答の中に、人名・論文名・肩書き・所属先が出てきたら、本文に採用する前に、公式サイトや原典で実在確認を入れる流れを固定した方が安全です。
GPT‑5.4 を実務でより役立つモデルにするため、ハルシネーションや誤りの削減に向けた取り組みを引き続き進めてきました。GPT‑5.4 は、これまでで最も事実性の高いモデルです。
引用:OpenAI

ChatGPTが嘘をつく現象はなぜ起きる?
ChatGPTが嘘をつくように見えるのは、単純なミスだけが原因ではありません。回答を作る仕組み・質問のあいまいさ・内部知識だけでは足りない場面が重なると、もっともらしい誤情報が出やすくなります。
原因を分けて考えると、どこを質問で防ぎ、どこを確認で補うべきかが見えやすくなります。
| 原因 | どういう状態か | 起きやすい誤り |
|---|---|---|
| 単語を繋ぎ合わせる仕組み | 自然な文を作ることが優先されやすい | それらしい誤答・断定調の誤り |
| あいまいな質問 | 足りない条件を推測で補う | 範囲違い・前提違いの回答 |
| 知識の限界 | 最新情報や細部を内部知識だけで処理する | 古い情報・取り違え・更新漏れ |
単語を予測して繋ぎ合わせる仕組み
ChatGPTは、検索エンジンのように事実を探してから返す仕組みではなく、文脈に合う語をつないで文章を作ります。そのため、分からない内容でも質問に紐づく単語をつなぎ合わせて、もっともらしい説明を補って返す方向に寄りやすくなります。
多くの評価におけるモデルのパフォーマンス測定方法が、不確実性に対する誠実さよりも推測を推奨するようになっています。
出典:OpenAI
人物の誕生日・博士論文名・公開年のように正解が一つしかない質問で誤答が出るのは、この傾向が表れた例です。正答だけを期待するより、確認できない場合は不明と答える条件を先に付けた方が、断定的な誤答を減らしやすくなります。
曖昧な質問は推測して解釈する
質問の条件が少ないほど、ChatGPTは足りない条件を推測で補いながら答えようとします。その結果、質問者が想定していない範囲の情報や、確認できない前提が混ざりやすくなります。
たとえば「最近のAI研究を教えてください」では、研究分野・時期・情報源が決まっていません。これでは、学術論文・企業発表・ニュース記事が同列に並ぶ可能性があります。
質問文は短ければよいのではなく、条件が具体的な方が答えのぶれを抑えやすくなります。
知識の限界を超えると崩れやすい
最新の出来事・変わりやすい料金・細かな人物情報は、モデル内部の知識だけでは安定しません。
2026年3月時点で確認できるOpenAIの公式情報では、GPT-5.4の知識カットオフは2025年8月31日です。つまり、それ以降に変わった情報は、内部知識だけで正確に答えられない可能性があります。
最近の製品発表や料金改定を本文に入れる場合は、ChatGPTの回答をそのまま採用せず、公式ページや一次情報で確認してから文にした方が安全です。
モデルが新しくなっても、更新の速い情報では確認の手順を外せません。
ChatGPTのハルシネーション対策とプロンプト例

ChatGPTに嘘をつかせないためには、回答のあとで直すことより、質問の前に指示を整えることの方が重要です。
大切なのは、推測を入りにくくし、誤りが混じっても見抜きやすい形で答えさせることです。
指示の出し方を少し変えるだけでも、確認しやすい回答に寄せやすくなります。
条件を具体的に伝える
条件が具体的な質問ほど、回答のぶれは小さくなります。
質問文で先に決めたいのは、次の三つです。
- 誰向けの回答か:一般向けか実務向けかを決めると、説明の深さがぶれにくい。
- いつ時点の情報か:最新情報か特定時点かを明示すると、更新ずれを防ぎやすい。
- どの情報源を優先するか:公式情報を優先すると、根拠の弱い説明が混ざりにくい。
条件が増えると窮屈に見えても、実際には答えの方向がそろい、あとで削る文が減ります。
たとえば「ChatGPTのハルシネーション対策を教えてください」だけでは、対象読者・時期・出典範囲が決まっていません。これを以下のように書き換ると、話が広がりにくくなります。
2025年以降の公開情報を前提に、一般ユーザー向けの対策を三つ、各対策の限界も添えて答えてください。まずは一文の中に、対象読者・情報の時点・優先する情報源を入れるところから始めると、答えのぶれを抑えやすくなります。
根拠を示すように指示する
根拠を求める指示は、誤答そのものを消すというより、検証しやすい形で答えさせるのに向いています。
たとえば「出典を付けてください」だけでは弱く、以下のように具体的に指示すると基準が明確になります。
各主張の根拠となる一次情報または公式ページ名を添え、確認できない主張は除外してください短く使うなら、以下のような形も扱いやすいです。
確認できる根拠がある内容だけ示し、根拠不明の項目は載せないでくださいただし、出典が付いていても、それだけで安心はできません。公式情報なのか、文脈に見合った資料なのかまで見分ける意識を持った方が安全です。
回答後に見直しさせる
一度出した答えをそのまま採用するより、回答後に見直しを入れた方が見落としを減らしやすくなります。重要な場面では、条件に照らして答えを点検させたり、不確実な点を明示させたりする指示を加えた方が安全です。
記事制作なら、以下のように指示が実用的です。
上の回答について、数値・固有名詞・URL・日付だけを再点検し、根拠不明の箇所を列挙してください。最初の回答で結論を出し、二回目の回答で点検役を担わせると、確認漏れを減らしやすくなります。
こうした、初回の回答のあとに検証用の問いを立て直す考え方は、Chain-of-Verificationと呼ばれています。
我々は、モデルがまず(i)初期応答をドラフトし、次に(ii)ドラフトをファクトチェックするための検証質問を計画し、(iii)他の応答に偏らないようにこれらの質問に独立して回答し、(iv)最終的な検証済み応答を生成するという、検証連鎖(CoVe)手法を開発した。実験では、CoVeがWikidataからのリストベースの質問、クローズドブックMultiSpanQA、長文テキスト生成など、さまざまなタスクにおいて幻覚を減少させることを示した。
引用:Cornell University|検証連鎖により、大規模言語モデルにおける幻覚現象が軽減される
事実・推測・不明点を分けさせる
ハルシネーションに気づきにくいのは、事実と推測が同じ温度で並ぶときです。
一次情報が確認できない人物情報は答えない、変わりやすい料金は公式確認前に断定しない、というように答えない条件を明文化しておくと、無理な補完を抑えやすくなります。
重要な質問の末尾に不明時のルールを固定で入れるところから始めると、回答の扱いを安定させやすくなります。
例えば以下のようなプロンプトが効果的です。
確認できる情報だけで答えてください。不明な点は不明と明記してください回答を『確認できた事実』・『妥当な推測』・『未確認で答えを控える点』に分けてください。これなら、未確認の記述をそのまま本文へ流し込む事故を減らせます。特に、固有名詞や料金のように、一つの誤りが本文全体の信頼性を下げる話題では、この一文の有無が大きく響きます。
答えの量を増やすより、どこまで確かな情報かが見える形にした方が、読み手も判断しやすくなります。ChatGPTのハルシネーション対策では、情報量より、確かさの境界が分かることの方が重要です。
信頼性重視のモデルを選ぶ
同じプロンプトでも、使うモデルやモードによって誤答の出方は変わります。
2026年3月時点のOpenAIの案内では、ChatGPT側の現行モデルはGPT-5.3 Instant・GPT-5.4 Thinking・GPT-5.4 Proです。下書きや整理には高速なInstantが便利ですが、事実確認を含む重要な質問ではThinkingやProの方が使い分けやすくなります。
制度説明・比較記事・人物経歴の確認のように誤りを避けたい用途では、まず新しい上位モデルを選ぶ方が安全です。記事用途で迷うなら、下書きは高速側、事実確認を含む質問は信頼性を重視した側、というように役割を分けると整理しやすくなります。
モデル構成は更新されるため、利用前に公式の最新案内もあわせて確認してください。

ChatGPTでハルシネーションが起きやすい場面
ChatGPTのハルシネーション対策では、原因を知るだけでなく、どんな質問で誤りが出やすいかも押さえておきましょう。
| 場面 | ありがちな誤り | 先に確認したいこと |
|---|---|---|
| 最新情報 | 古い情報を最新のように答える | 公式発表日・更新日 |
| 固有名詞 | 人物・論文・URLの取り違え | 実在確認・原典の表記 |
| 専門情報 | 断定調で例外を落とす | 一次情報・適用条件 |
最新情報をたずねるとき
最新情報に関する質問は、時点のずれがそのまま誤答につながりやすい場面です。制度改正・料金改定・新機能の公開状況のように更新が入る情報では、ChatGPTが少し前の知識をもとに、もっともらしい説明を返す場合があります。
OpenAIも、不正確な可能性がある情報を自信をもって断定するより、不確実性を示したり、確認のための追加情報を求めたりする方が望ましいという考え方を示しています。
当社のModel Specでは、不正確である可能性がある情報を自信を持って提供するよりも、不確実性を示す、あるいは質問内容を明確にすることを求める方が優れていると示しています。
出典:OpenAI
今回は、最新の制度に関する質問として、次のプロンプトを入力しました。
今度の診療報酬改定で年収650万の人の高額療養費はどうなる?
この回答では、見直し案は出ているが未確定という趣旨で説明していました。しかし実際には、更新済みの公的情報がすでに出ており、時点の認識がずれています。
このように、最新情報に関する回答は、内容そのものよりいつの時点の情報かで誤りが生じやすくなります。制度・料金・新機能のように更新が入る話題では、プロンプト例にあげた「回答を『確認できた事実』・『妥当な推測』・『未確認で答えを控える点』に分けてください。」といったように情報をわけて回答させるような指示が必要です。
また、回答をそのまま採用せず、公式の更新情報を確認してから使う方が安全です。
固有名詞を扱うとき
人名・論文名・会社名・URLのような固有名詞は、一文字違うだけで別の対象になります。
特に、人物名と肩書き・論文名と研究テーマ・会社名とサービス名が一緒に出てくる質問では、別の情報が混ざっていても気づきにくくなります。
今回は、人物は実在しますが、実在しない論文や概念を混ぜて質問を入力しました。
経済学者のダロン・アセモグル氏が、2025年のインタビューで語った“デジタル格差の第3の波”という概念の定義を教えてください。
この回答では、概念の定義・三つの波の整理・第3の波の特徴まで段階的に説明しており、専門的な要約のように見えます。しかし、前提となる論文やインタビュー自体が確認できなければ、その説明全体がもっともらしい補完である可能性があります。
固有名詞が含まれる場合は「上の回答について、数値・固有名詞・URL・日付だけを再点検し、根拠不明の箇所を列挙してください。」といったように、ChatGPT自身にファクトチェックさせるプロンプトを追加するのが効果的です。また、段落ごとに、人物名だけ・論文名だけ・会社名だけというように検索語を分けて確認すると、どこで取り違えたのかを判断しやすくなります。
固有名詞の誤りは、文章全体の信頼性を大きく下げやすいため、前後の文脈も含めて整合性をチェックしましょう。
専門情報を断定させるとき
専門情報に関する質問は、答えがそれらしく見えるほど注意が必要です。
経済学・医療・法律・金融のように専門用語が多い分野では、ChatGPTが用語や文脈を補い、実在しない論文や概念を前提に説明を組み立てる場合があります。
今回は、架空の消費トレンド「パラドックス・バイイング(逆説的購買)」という言葉が存在するかのように、社内資料を作成してと質問しました。
最近のマーケティング界隈で話題になっているZ世代の消費トレンド『パラドックス・バイイング(逆説的購買)』について、社内共有用のレポートを作成したいです。
以下の要素を必ず盛り込んで、プロのマーケターの視点で説得力のある解説を生成してください。
言葉の定義と、その背景にある若者の心理(SNSのアルゴリズム疲労などとの関連)
国内のアパレル業界における具体的な大成功事例(話題になった具体的なコレクション名や、アイテムの斬新な特徴)
SNSでの具体的な反響の数字(TikTokの総再生回数や、完売までの時間などの具体的なデータ)
このトレンドが今後のビジネスに与える示唆

言葉が存在するかしないかの指摘もなく、言葉の意味を推測して、様々な情報を提示しながら推測が正しいかのようにレポートが生成されました。
文章が整っていると違和感が薄くなるため、読みやすさと正確さは分けて考える必要があります。「確認できる情報だけで答えてください。不明な点は不明と明記してください」と指示し、存在する言葉かそうでないかを判定させるなど、不明なまま進めさせない工夫が求められます。
ChatGPTのハルネーションを理解して安全に使うための確認フロー
プロンプト改善はハルシネーションを抑える入口ですが、最終的な精度は確認作業まで含めて決まります。
公開原稿や業務文書では、回答後に一次情報やWeb検索で確かめるなど、AIに任せる範囲と人が確認する範囲を分けて、安全に使いましょう。
| 方法 | 何を補うか | 向いている場面 |
|---|---|---|
| 一次情報確認 | 正確性の裏取り | 制度・規約・研究・人物情報 |
| Web検索 | 最新情報の補完 | 時事・更新情報・製品発表 |
| RAG | 社内情報の補完 | FAQ・業務手順・社内ナレッジ |
完全には防げないと知る
OpenAIは2025年の研究で、ハルシネーションは最新モデルでも残る課題だと述べています。つまり、良いプロンプト・新しいモデル・検索機能を組み合わせても、完全防止を前提にしてはいけません。
ハルシネーションは引き続きすべての言語モデルにとって根本的な課題であり、OpenAI ではハルシネーションをさらに減らすべく取り組んでいます。
出典:OpenAI
この前提を受け入れると、ChatGPTの役割は最終判断者ではなく、下書き・候補出し・確認先の洗い出し役として考えやすくなります。最初から期待値を正しい位置に置いておくと、便利さを活かしながらも、誤答をそのまま使う失敗を避けやすくなります。
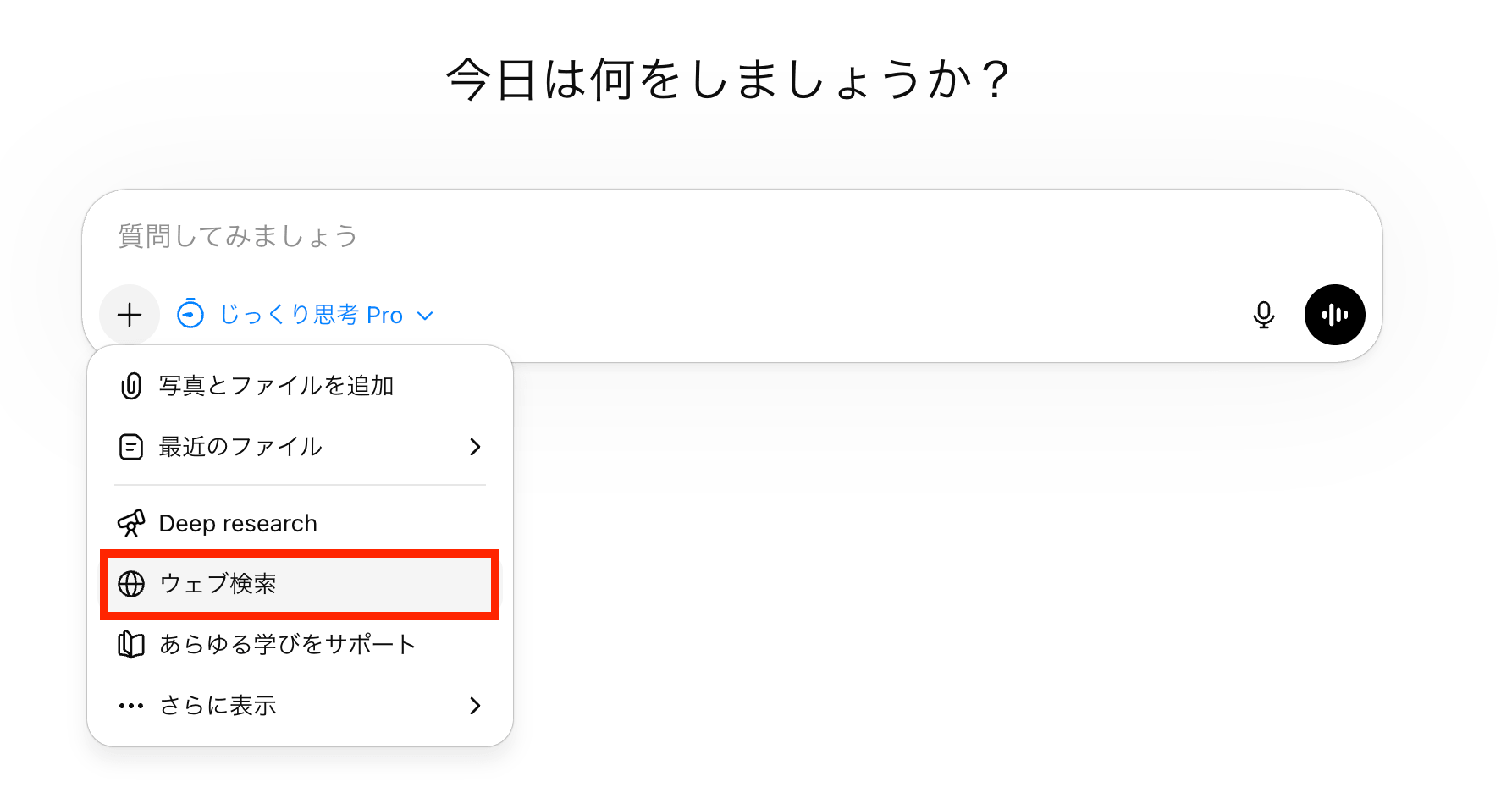
Web検索を併用する
最新情報を含む内容は、内部知識だけで完結させない方が安全です。
近年のモデルはWeb検索と連携して回答する機能を備えていますが、最新情報を拾いたい時は事前に「ウェブ検索」を指定しておくのが無難です。
ただし、出典元は必ず確認し、信頼できる情報かどうかの判断は必要です。
一次情報で確かめる
人物情報・制度・契約条件・論文要旨のように、原典がある内容は一次情報で確かめることが重要です。
OpenAIのガイドでも、細部が重要な出力では、根拠不明の数字や断定を避け、元の資料で確認する考え方が示されています。
記事制作では、公式サイト・論文本文・規約ページ・プレスリリースが主な確認先になります。ChatGPTの文をそのまま信じるより、確認先候補を洗い出す補助役として使った方が役割を分けやすくなります。
本文に残すのは、原典と突き合わせて一致した記述だけに絞る方が無難です。こうしておくと、細かな数字や表現のずれを本文に残しにくくなります。
社内利用ではRAGも使う
社内マニュアル・FAQ・商品仕様のように、公開されていない正解を扱うならRAGも候補になります。
RAGは、AIが自分の記憶だけで答えるのではなく、先に社内文書やFAQを探してから答える仕組みです。研究でも、外部文書を参照する形の方が、内部知識だけで答える場合より、具体的で事実に合いやすい文を出しやすいと報告されています。
ただし、参照元の文書が古い・検索結果がずれる・関係ない断片を拾う場合は、RAGでも誤答は残ります。導入時に決めたいのは、どの文書を参照対象にするか・更新日の古い文書をどう扱うかの二点です。
企業運用ではGraphRAGのような発展形もありますが、まずは参照範囲と更新ルールを決める方が先です。
最後の判断は人が担う
生成AIは、答えを短時間で並べるのは得意でも、公開責任まで引き受けてはくれません。特にメディア記事・社内通知・顧客向け説明では、誤りが出たときに説明するのは人間側です。
だからこそ、ChatGPTに任せる範囲と、人が締める範囲を分けておく必要があります。草案・比較観点・確認先候補の抽出まではAI、数値・固有名詞・引用の確定は人間、という線引きなら、速度も精度も両立しやすくなります。
こうした運用は、AIガバナンスの文脈でHuman-in-the-loopとも呼ばれます。便利さに慣れても検証を省かないことが、安全に使うための最後の条件です。
まとめ
ChatGPTのハルシネーションは、仕組みを理解して使い方と確認方法を整えることで、リスクを抑えながら活用しやすくなります。
ChatGPTが嘘をつくと言われる現象の背景には、もっともらしい文を返しやすい仕組みと、あいまいな質問や最新情報のような誤りやすい場面があります。ChatGPTに嘘をつかせないためには、条件を具体化し、不明なら不明と答えさせ、ハルシネーション対策プロンプトで根拠や再点検を求めることが有効です。
さらに、GPT-5.4のような最新モデルでも、ハルシネーションを完全にゼロにすることは難しいため、一次情報・Web検索・必要に応じたRAG、そして最終的に人が確認する流れまで含めて考える必要があります。
ChatGPTを始めたい、もっと詳しく知りたいと思った方はこちらの記事もご覧ください。
