

OpenAIは、GPT-4の内部表現を1600万もの特徴に分解する新たな方法を発表しました。この研究により、従来の方法に比べて拡張性が大幅に向上し、多くの特徴が人間にとって理解可能な概念に対応していることが明らかになりました。
AIモデルのニューラルネットワークの課題は、内部構造が予測不可能で、完全に解釈できない点にあります。各入力に対して常に多くの特徴が活性化するため、少数の重要な特徴を特定することが困難です。これに対し、OpenAIは「スパースオートエンコーダ」を用いることで、より解釈可能な特徴を見つけ出す方法論を開発しました。
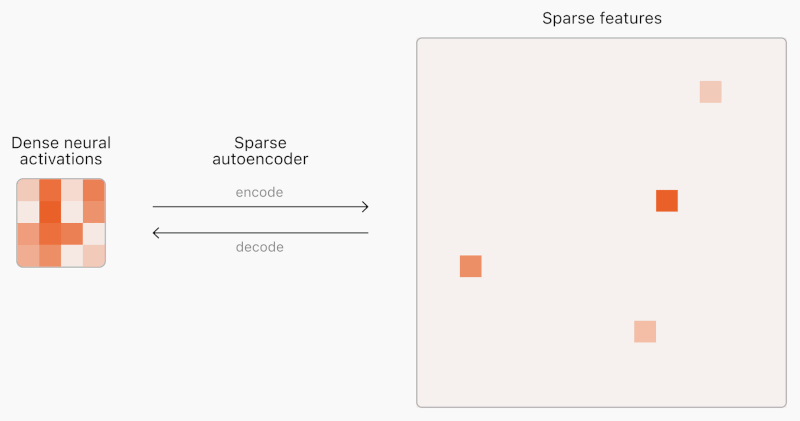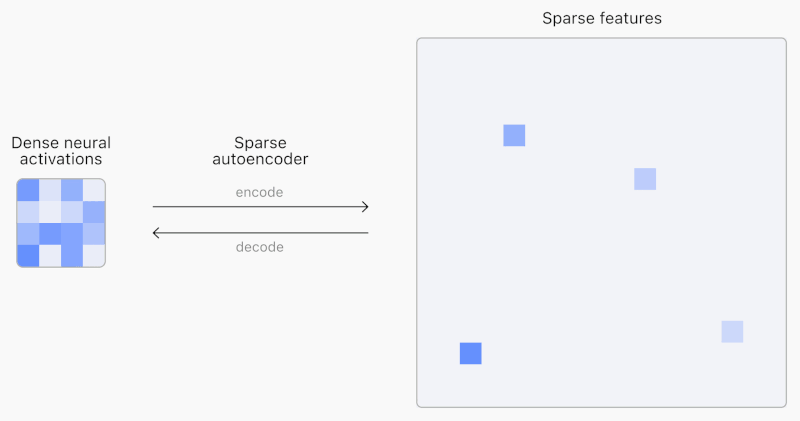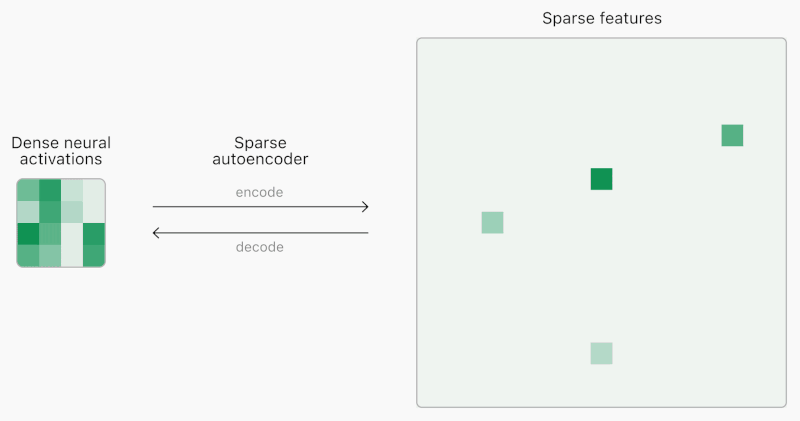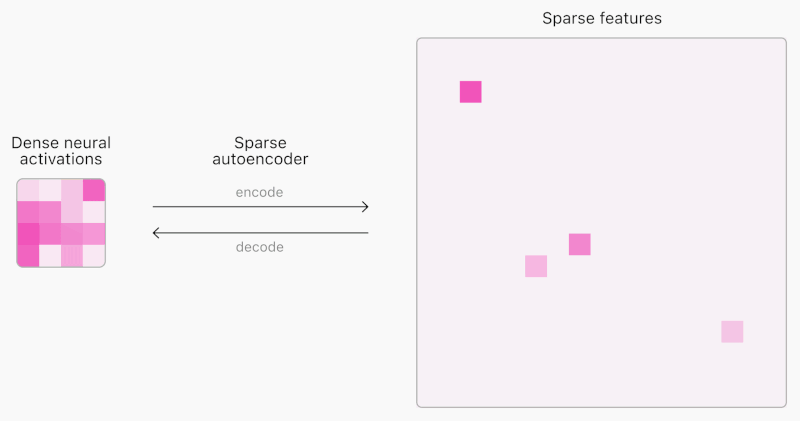
同社はこの方法論を用いて、GPT-2およびGPT-4の活性化データに対し1600万の特徴を抽出しました。これらの特徴は、文書のどこで活性化するかを視覚化することで、具体的な概念として理解できます。例えば、「人間の不完全さ」や「物価上昇」といった特徴が含まれます。
しかし、この研究には多くの課題が残されています。発見された特徴の一部は解釈が難しく、スパースオートエンコーダはAIモデルの全ての振る舞いを捉えることはできないため、更なるスケールアップが必要です。
同社はこの研究成果の論文とコードを研究コミュニティ向けに公開しています。将来的には、AIモデルの安全性と信頼性を高めるための新しい方法を提供することを目指すということです。