

OpenAIは、GPT-4を基盤とした新しいAIモデル「CriticGPT」を開発しました。この「CriticGPT」は、「ChatGPT」の応答を批評することで、人間のトレーナーがミスを見つけやすくすることを目的としています。
特にコードの出力に対して有効で、人間のトレーナーが「CriticGPT」の助けを借りることで、エラー検出の精度が60%向上しました。「CriticGPT」は、RLHF(人間のフィードバックによる強化学習)を利用してトレーニングされており、批評の質を高める上で重要な役割を果たしています。
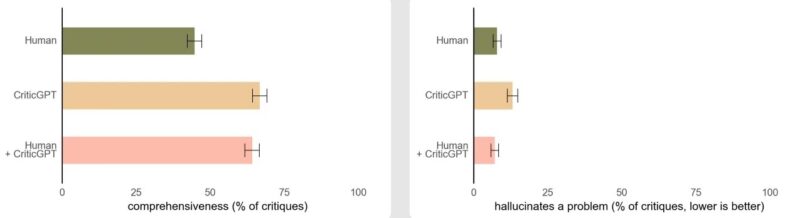
「ChatGPT」がより正確になり、ミスが分かりにくくなるにつれて、AIトレーナーが不正確さを見つけるのが難しくなっていました。「CriticGPT」はこの問題に対処するために設計され、ミスを強調する批評を生成します。実験では、「CriticGPT」と人間のトレーナーが協力することで、人間のトレーナーだけで作業する場合よりも多くの問題を発見し、より包括的な批評を行うことが示されました。

「CriticGPT」は、人間のトレーナーが意図的に挿入したエラーを識別するようにトレーニングされました。このプロセスでは、トレーナーが「ChatGPT」によって生成されたコードにエラーを手動で挿入し、そのエラーを見つけたかのようにフィードバックを記述します。このフィードバックに基づいて、「CriticGPT」が批評を生成し、他のトレーナーによる評価を受けます。
ただし、「CriticGPT」にも限界はあります。例えば、実際のエラーが複数の部分に分散している場合や、タスクや応答が非常に複雑な場合には、モデルが提供する支援が十分でないことがあります。今後は、長く複雑なタスクに対応するための方法を開発し、より高い精度でエラーを検出できるようにしていきます。
OpenAIは、「CriticGPT」をさらに大規模化し、実際に活用していく予定です。これにより、GPT-4やその後のAIシステムの出力をより効果的に評価し、人間のトレーナーの能力を強化することが期待されます。「CriticGPT」は、将来のAIシステムの調整に必要なツールとして重要な役割を果たしていくでしょう。