

gpt-realtimeとは、OpenAIが新たに発表した音声モデルです。
音声の入力に対し、テキスト化をすることなく直接音声を生成する方式を取ることにより、以前のモデルと比べて低遅延なやり取りが可能となりました。
この記事では、gpt-realtimeの概要や性能、使い方について解説します。
なお、この記事ではPlaygroundを使用した方法をご紹介します。
gpt-realtimeとは?新モデルの全体像

gpt-realtimeは、OpenAIが発表した最新の音声対話に特化したAI音声モデルです。
このモデルは、人間同士の会話のように自然で、極めて低い遅延(レイテンシ)でのやり取りを実現することを目指して開発されました。
従来のモデルがテキストベースの対話から音声を生成していたのに対し、gpt-realtimeは音声から直接音声を生成するアプローチを採用しています。
これにより、応答の速さだけでなく、感情や抑揚といった非言語的なニュアンスも豊かに表現できるようになりました。
開発者はRealtime APIを通じて、この高度な音声対話機能を自身のアプリケーションやサービスに組み込むことが可能です。
何が新しいのか
gpt-realtimeの最大の新しさは、音声から音声への一体型処理にあります。
これにより、文字起こしと音声合成のプロセスを挟まないため、人間と話しているかのような低遅延でスムーズな会話が可能になりました。
さらに、会話の途中でユーザーが割り込んで話すことへの対応精度が向上し、よりスムーズな対話が実現されています。
また、機能も大幅に拡張され、新たに画像入力に対応し、ユーザーが見ているものをAIが認識して対話できます。
他にも、電話網と直接連携できるSIP(Session Initiation Protocol)や、AIが自律的に外部ツールを連続して操作するMCP(Model Context Protocol)にも対応し、単なる対話ツールを超えた実用的なAIエージェントの構築が可能になっています。

従来のモデルとの違いと料金
gpt-realtimeは従来のモデルであるgpt-4o-realtime-previewと比較して、性能とコスト効率の両面で大きく進化しています。
最も大きな違いは、応答速度と表現力です。
テキストを介さないため、会話のテンポが人間同士のそれに近づき、声のトーンや感情の表現も格段に豊かになりました。
また、Function Calling(関数呼び出し)の精度も向上しており、外部ツールとの連携がよりスムーズになっています。
料金面では、gpt-realtimeは従来のモデルと比較して約20%安価に設定されています。
We’re reducing prices for gpt-realtime by 20% compared to gpt-4o-realtime-preview—$32 / 1M audio input tokens ($0.40 for cached input tokens) and $64 / 1M audio output tokens (see detailed pricing(opens in a new window)).
出典:Introducing gpt-realtime and Realtime API updates for production voice agents
2025年9月現在の具体的な料金表を以下に示します。
| 種類 | 入力トークン (100万トークンあたり) | キャッシュされた 入力トークン (100万トークンあたり) | 出力トークン (100万トークンあたり) |
|---|---|---|---|
| テキスト | $4.00 | $0.40 | $16.00 |
| 音声 | $32.00 | $0.40 | $64.00 |
| 画像 | $5.00 | $0.50 | – |
これにより、高性能な音声AIをより低コストで本番環境に導入しやすくなりました。
主なユースケース
gpt-realtimeの能力が最も活かされるのは、リアルタイム性が重視される対話型のサービスです。
例えば、24時間365日対応可能なカスタマーサポートのAIエージェントや、ハンズフリーで操作できる高機能な音声アシスタントなどが代表例です。
SIP連携が可能になったことで、従来の電話システムとAIを直接接続し、予約受付や問い合わせ対応を自動化できます。
また、多言語に即座に対応できる能力を活かしたリアルタイム翻訳ツールとしても活用が期待されます。
教育分野においては、対話形式で学習を進めるAIチューターや、言語学習の発音練習パートナーとしての応用可能です。
gpt-realtimeの性能|認識精度や音声品質
ここでは、gpt-realtimeの性能について詳しく解説していきます。
ベンチマーク概要
gpt-realtimeの性能は、複数のベンチマークで旧モデルを大幅に上回っています。
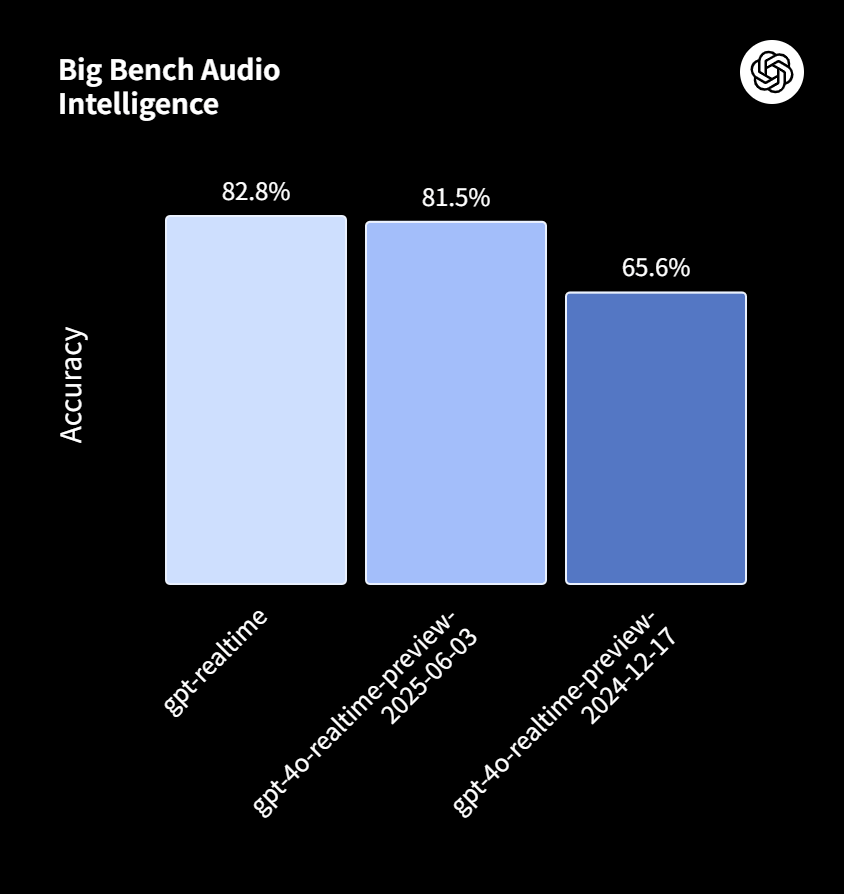
例えば、音声による高度な推論能力を測る「Big Bench Audio」では、正解率が旧モデルの65.6%から82.8%へと向上しました。
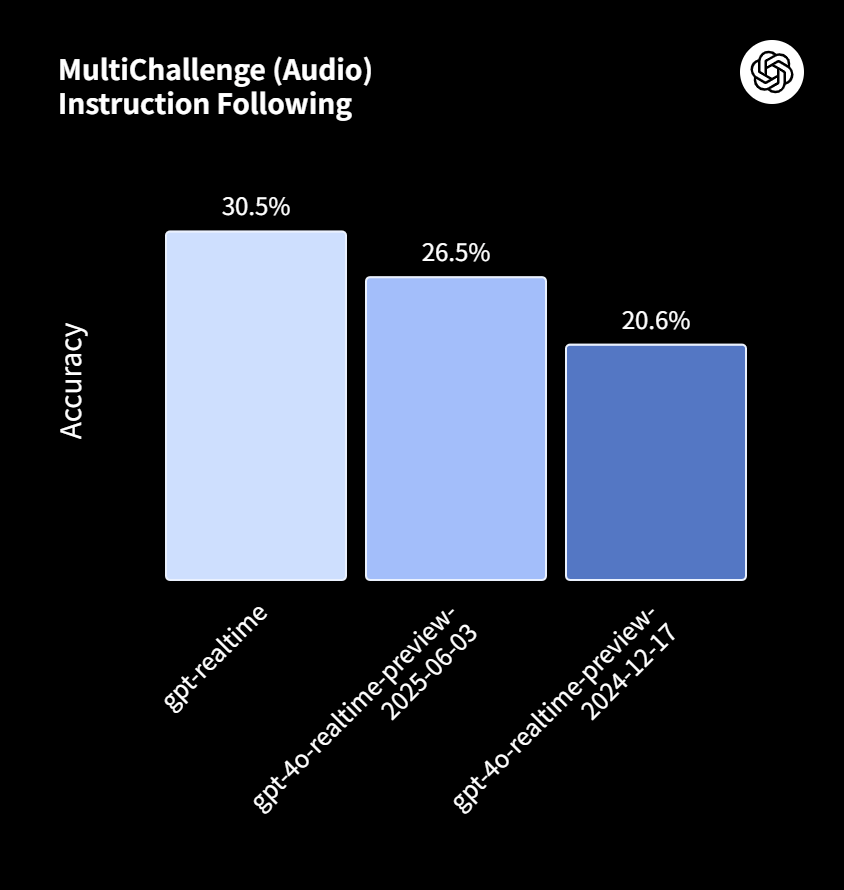
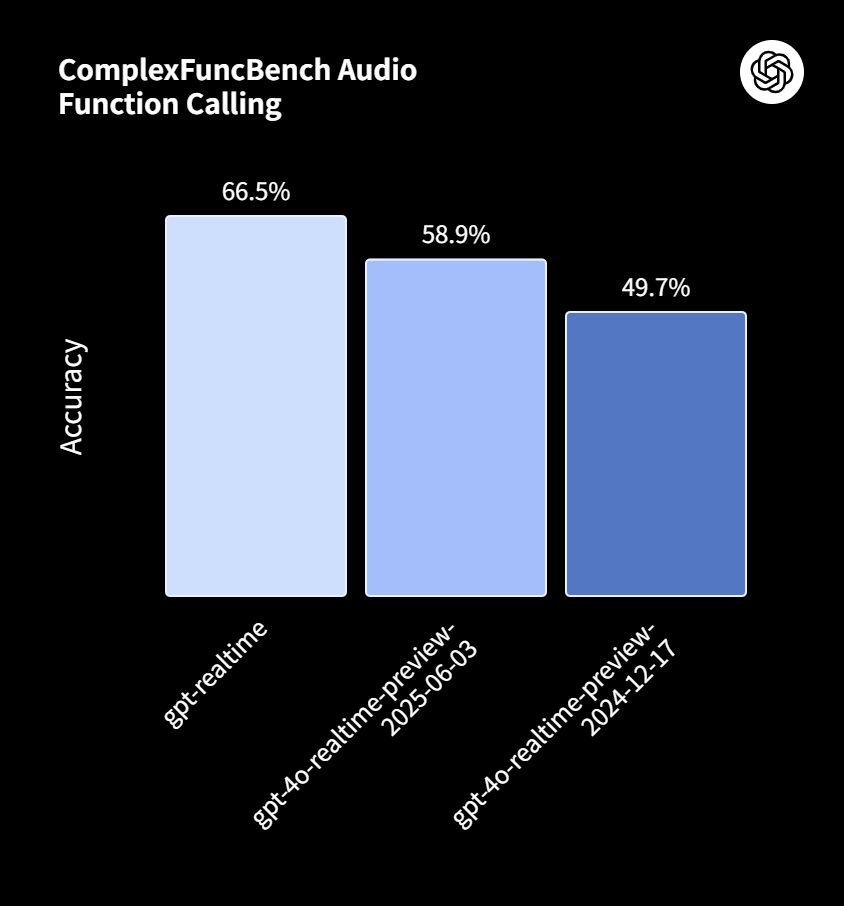
また、複雑な指示にどれだけ正確に従えるかを示す「MultiChallenge」では、スコアが20.6%から30.5%に、外部ツールを呼び出す関数呼び出しの精度を測る「ComplexFuncBench」では、49.7%から66.5%へとそれぞれ大きく改善しました。
これらの数値は、AIがユーザーの要求をより深く、かつ正確に実行できるようになったことを客観的に示しています。
多言語での英数字認識/非言語信号の理解
このモデルはグローバルな利用を想定しており、多様な言語において高いパフォーマンスを発揮します。
OpenAIの社内評価では、日本語を含む複数の言語で電話番号や車両識別番号といった英数字の羅列を、より正確に認識できることが確認されました。
According to internal evaluations, the model also shows more accurate performance in detecting alphanumeric sequences (such as phone numbers, VINs, etc) in other languages, including Spanish, Chinese, Japanese, and French.
出典:Introducing gpt-realtime and Realtime API updates for production voice agents
さらに、会話の中の笑い声や間の取り方といった非言語的な信号を認識し、応答に反映させることができます。
これにより、単なる情報伝達に留まらない、感情的な文脈を汲み取った対話が実現可能になっています。
音声品質と新ボイスの特徴
gpt-realtimeでは音声品質が全体的に向上し、より人間らしく自然なイントネーションや感情表現が可能になりました。
このアップデートに伴い、新たに2種類のボイス「Marin」と「Cedar」が追加されています。
さらに、従来の8つのボイスもアップデートされました。
これらのボイスは、従来の音声よりもさらに表現力と明瞭さが追求されており、プロフェッショナルな顧客対応から親しみやすいアシスタントまで、用途に応じて最適な声質を選ぶことができます。
また、「早口でプロフェッショナルに」「共感的に話して」といった細かいスタイル指示にも対応し、口調を柔軟に変化させることが可能です。
gpt-realtimeの使い方【最短導入ガイド】

続いて、gpt-realtimeの使い方を解説します。
この記事では、OpenAIのPlaygroundを使用したやり方をご紹介します。
開始手順
gpt-realtimeを使うには、Playgroundを使用するのが最も簡単です。

Playgroundでgpt-realtimeを使う手順は以下の通りです。
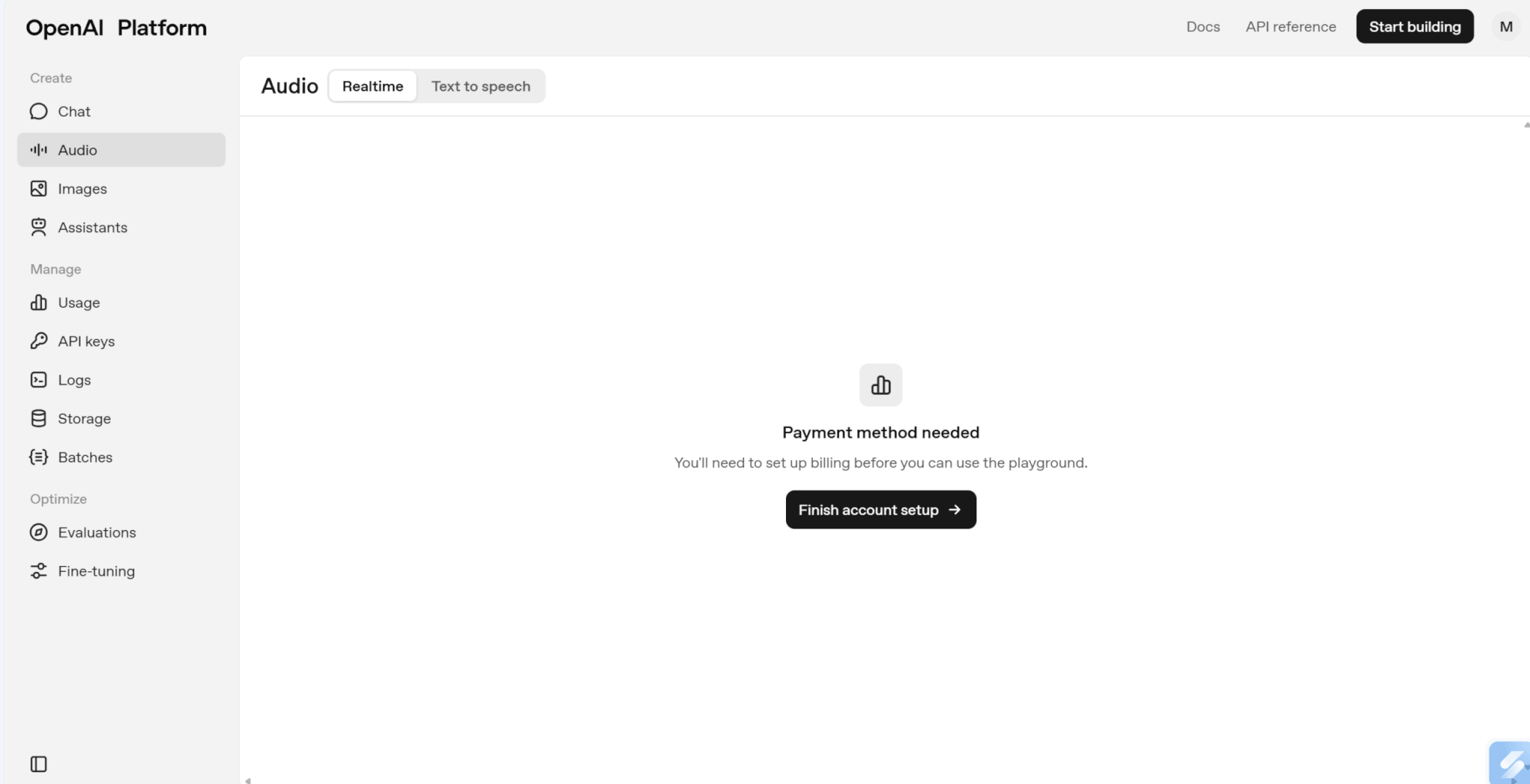
画面左の「Audio」タブを選択し、「Realtime」を選びます。
OpenAIのAPIの課金設定をしていない人は、「Finish account setup」をクリックして支払い方法を設定しましょう。
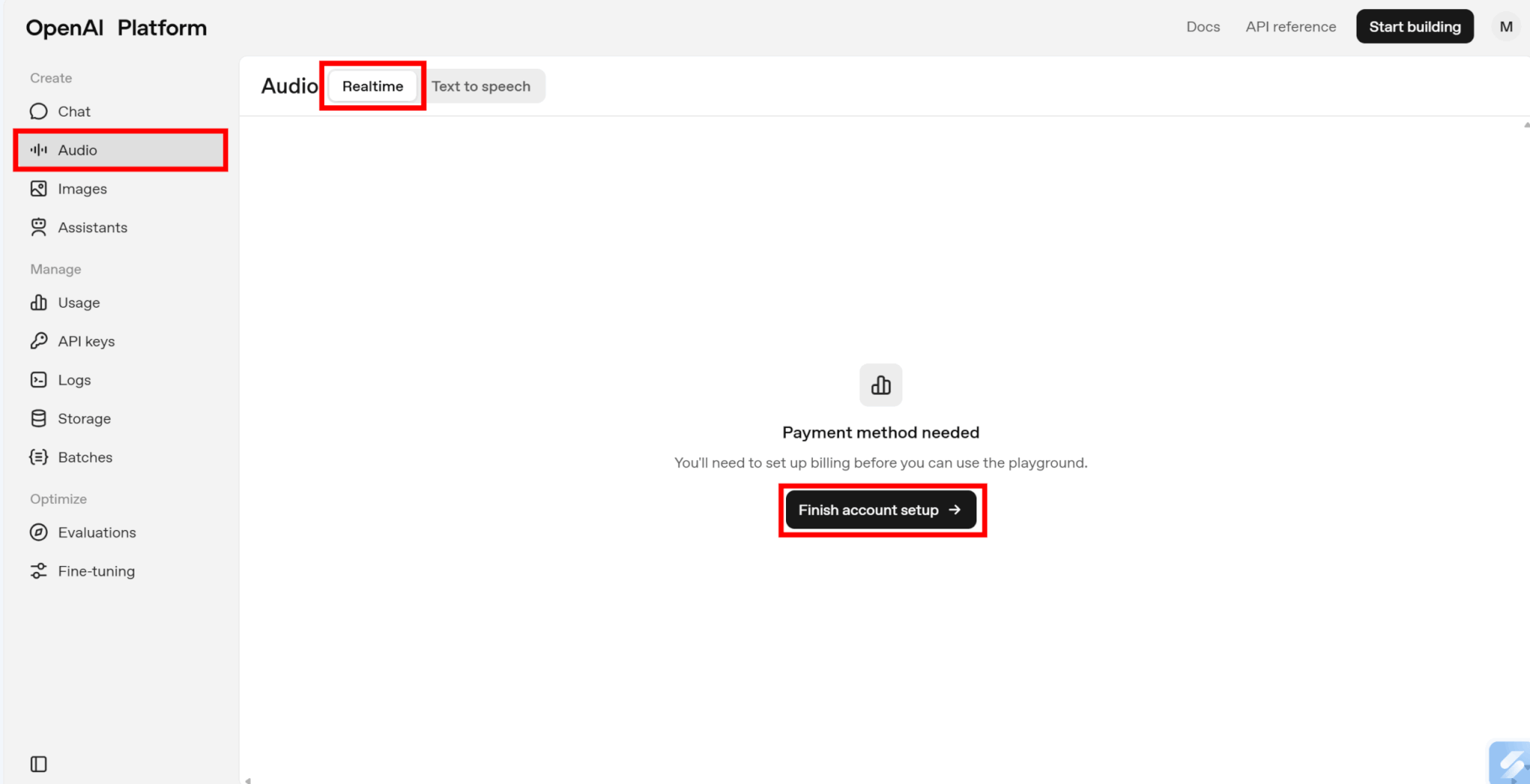
APIが使用できるようになったら、「Create」をクリックしましょう。
画面右側でモデルや各種パラメータを設定できます。
「model」でgpt-realtimeを選択します。
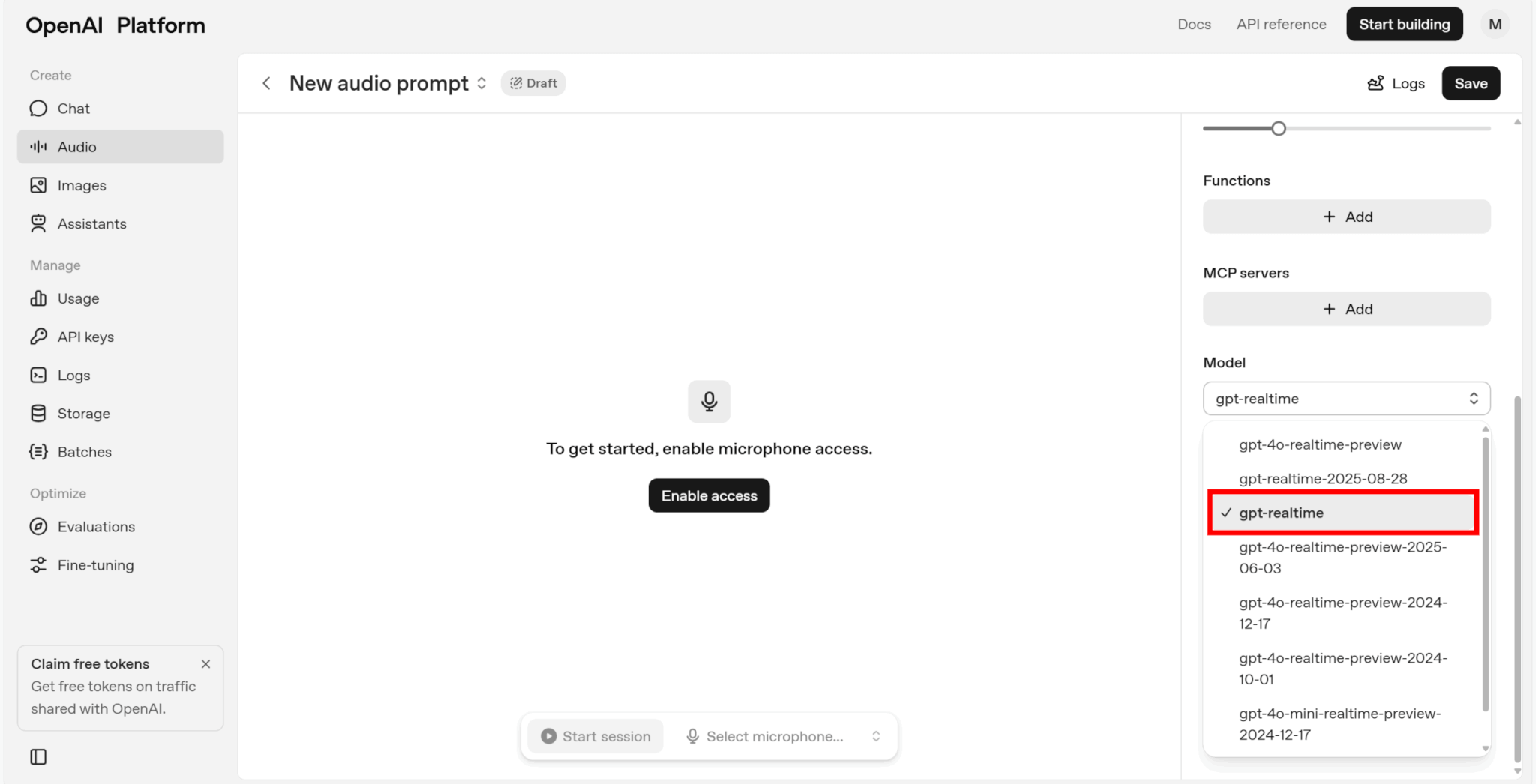
その他のパラメータについては以下の通りです。
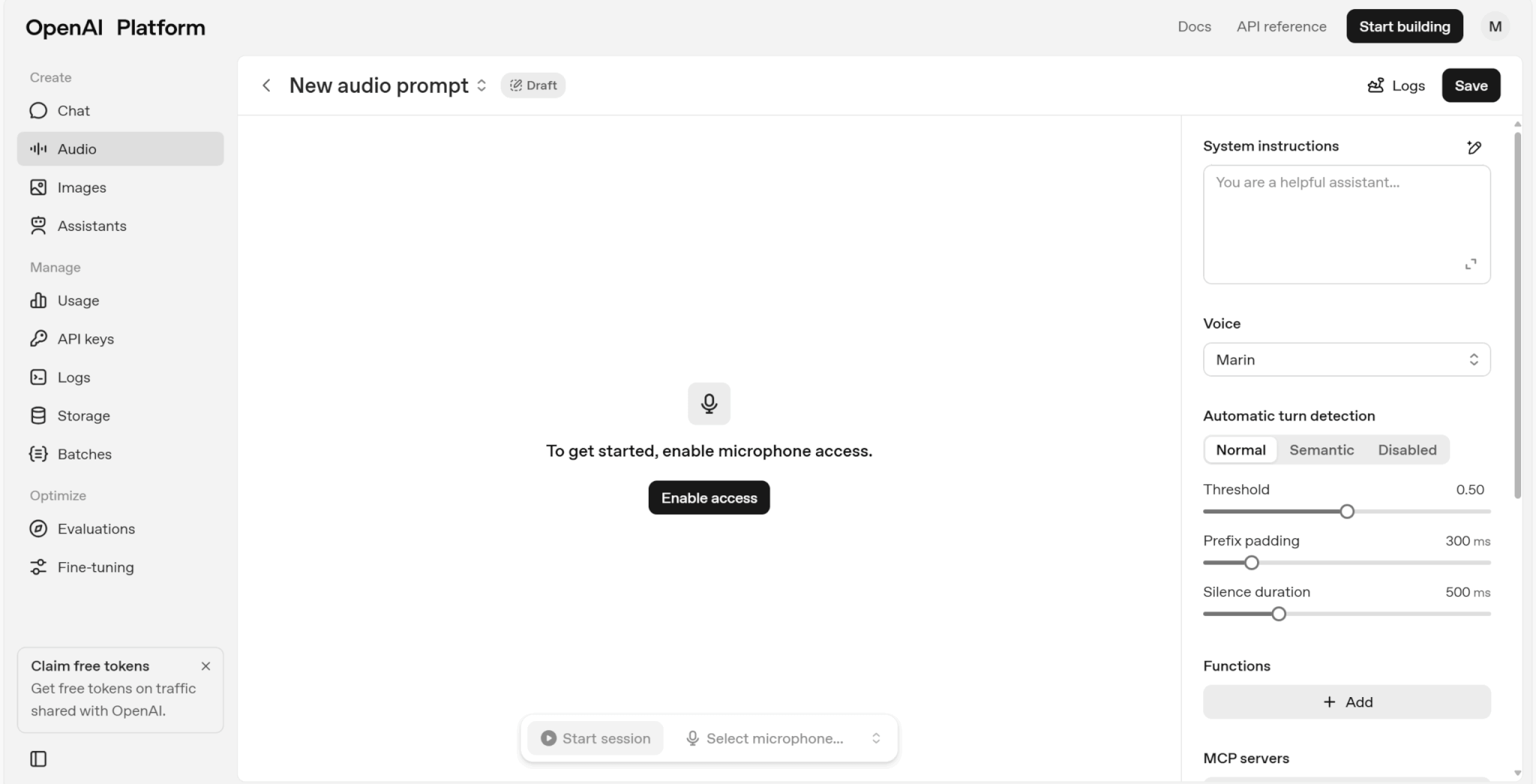
- System instructions
-
モデルに与える役割の指示であり、キャラクター性や会話スタイルを制御可能。
- Voice
-
出力する音声の種類を選択可能。
- Automatic turn detection
-
音声入力の区切り方を制御できる。Normalは音量や無音をもとに区切りを判断、Semanticは内容のまとまりを検出して区切りを判断、Disabledは自動区切りなし。
- Threshold
-
音声を話し声として判別するしきい値を設定できる。小さくすると小さな声でも認識できるが、ノイズを拾いやすくなる。
- Prefix padding
-
モデルが音声を検出した際、どれくらいさかのぼって録音を含めるかの設定。長くすると言葉の最初の部分が切れにくくなる。
- Silence duration
-
無音が続いたときに発話が終わったと判断するまでの時間。値を小さくするとレスポンスは速くなるが、途中の間を誤検出することもある。一方で値を大きくすると、会話の途中の「間」を待てるようになるが、応答は遅くなる。
- Temperature
-
応答の創造性を設定可能。大きくすると創造性の高い応答が、小さくすると確定的な応答が出力されるようになる。
なお、今回はすべてのパラメータをデフォルトのまま使用しました。
設定が完了したら、「Enable access」をクリックしましょう。
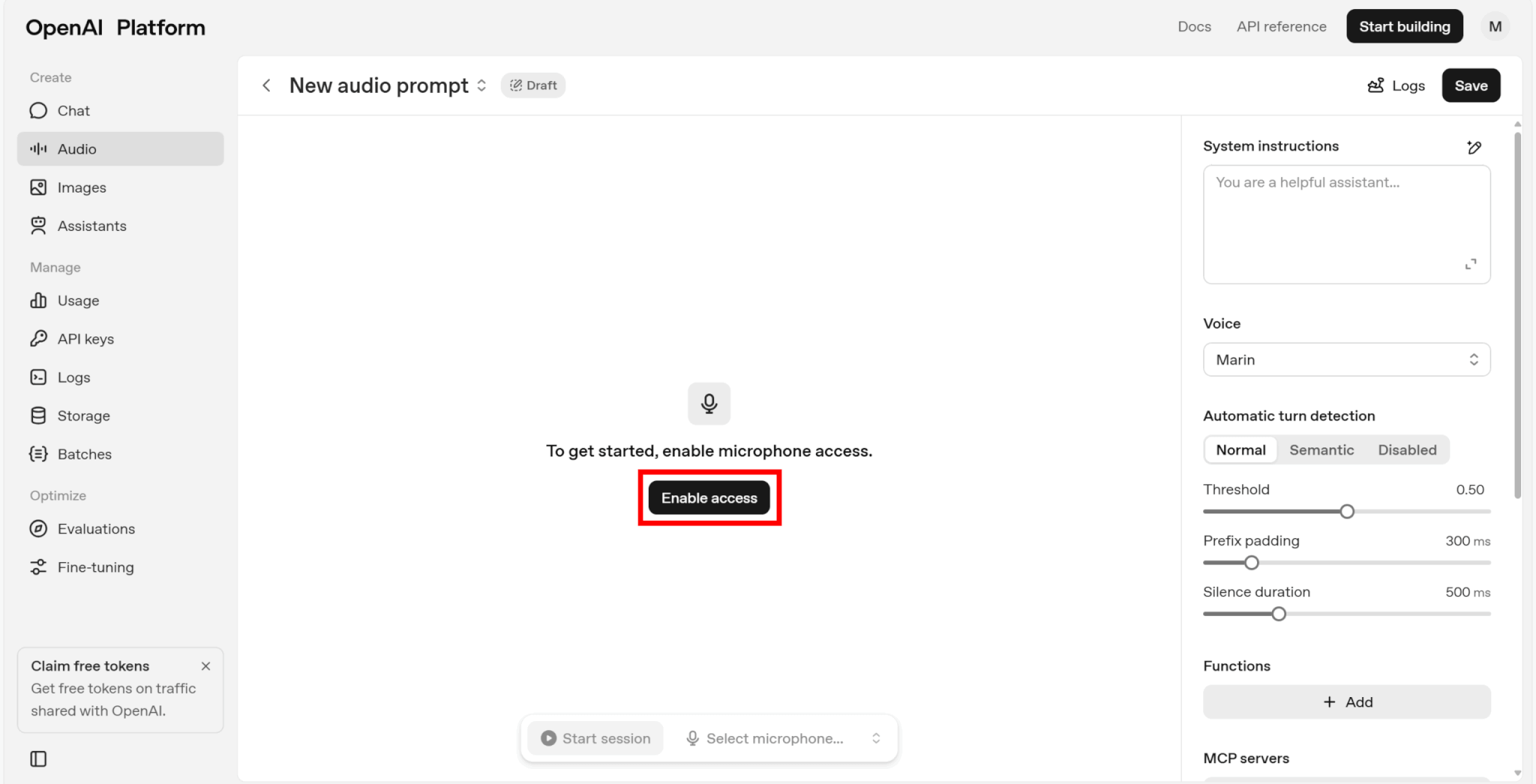
その後、マイクを設定し、「Start session」をクリックすると会話を始められます。
実際に会話してみた例がこちらです。
AIが発言している途中の割り込みにも対応していることが分かります(動画開始1:00あたり)。
なお、この記事ではPlaygroundを使用しましたが、自分でコードを書くことでWebRTCやWebSocketに接続して使用したり、SIPと連携させたりすることもできます。
詳しくは以下の記事をご覧ください。

ツール連携の実装ポイント
gpt-realtimeは、事前に定義した関数を自動で呼び出すFunction Callingや、より高度な連携としてMCPがあります。
ツール連携の実装ポイントとしては、各ツールやプロシージャの役割とパラメータをモデルに分かりやすく説明すること、そしてモデルからの実行リクエストを正確に処理し、結果を返すロジックを確実に構築することです。
Playgroundでは、設定で追加することでこれらの機能が使用できます。
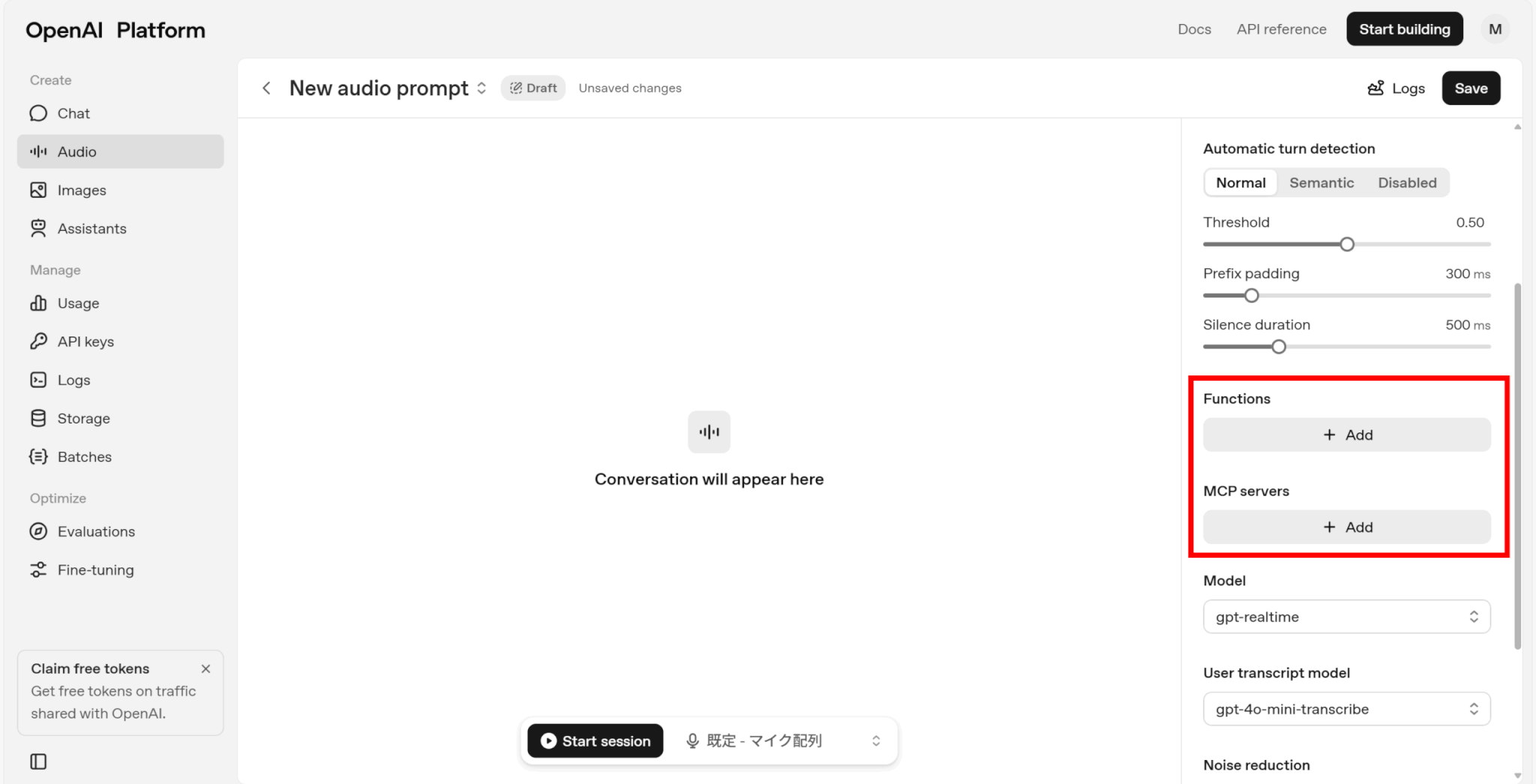
ツール連携の手順は以下の通りです。
「Function」の「Add」をクリックします。
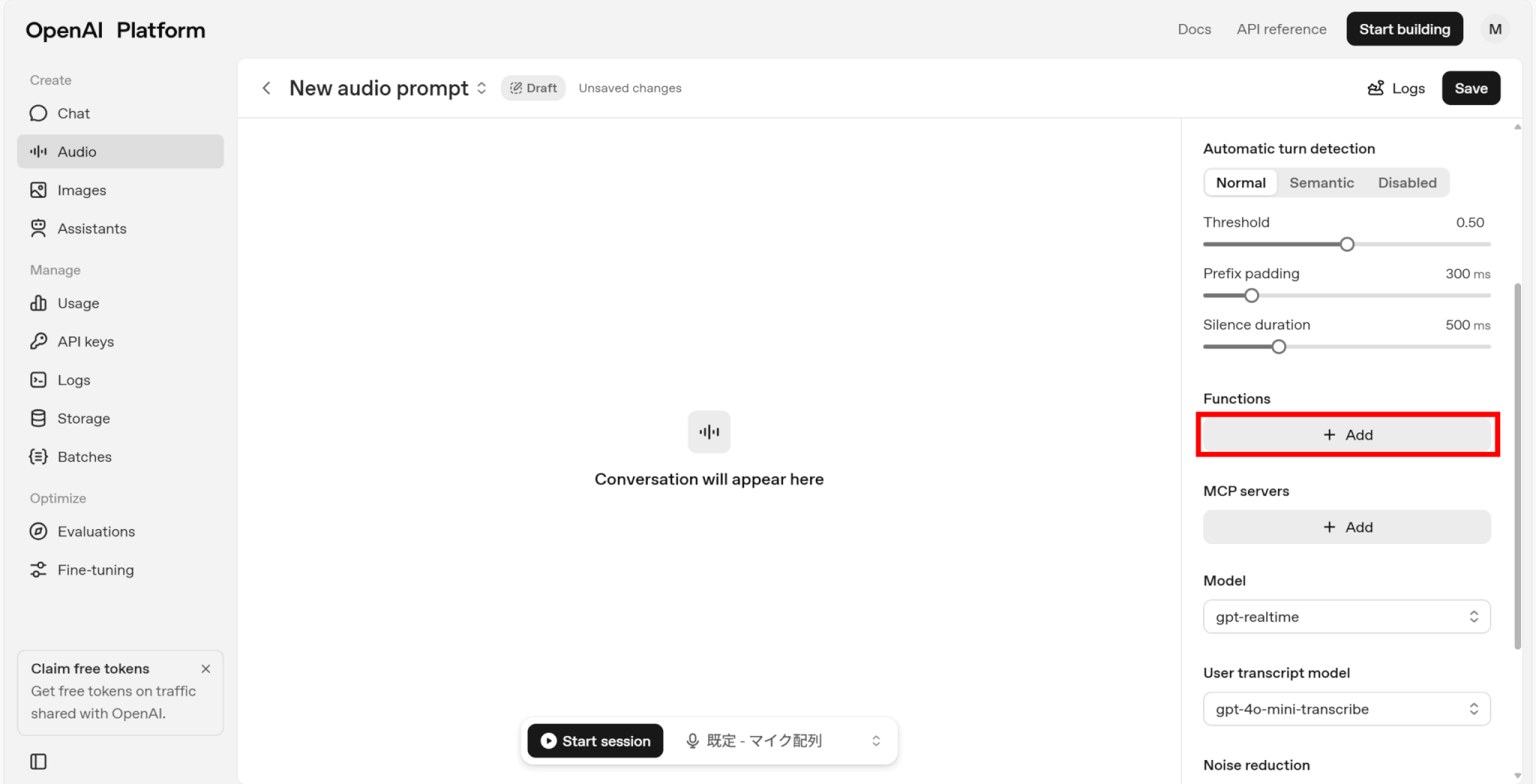
関数の追加画面が表示されるため、「Examples」で関数例を使用するか、「Generate」で使いたい関数を生成しましょう。
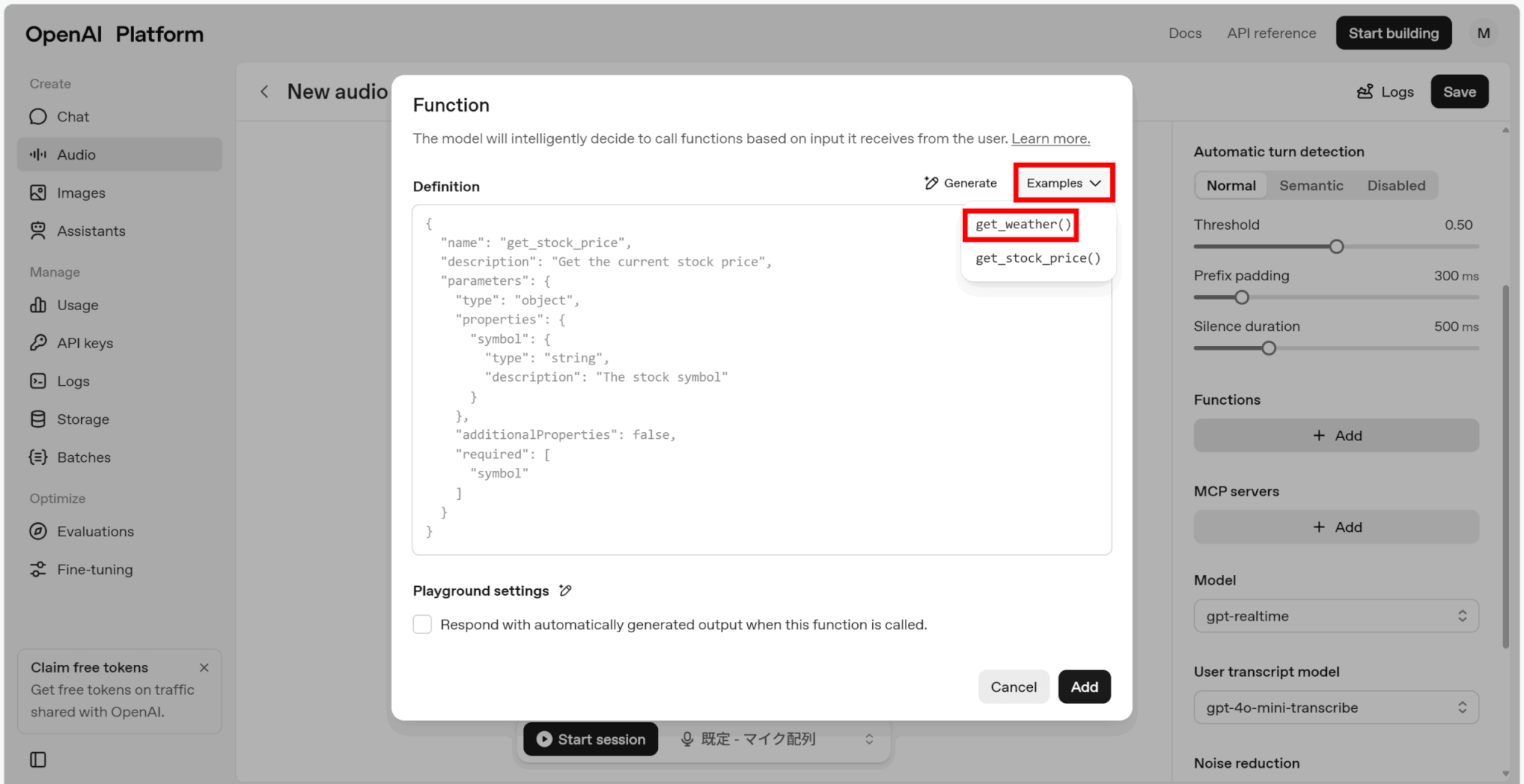
ここでは、「Examples」の「get_weather()」を使用して天気情報を取得する関数を追加します。
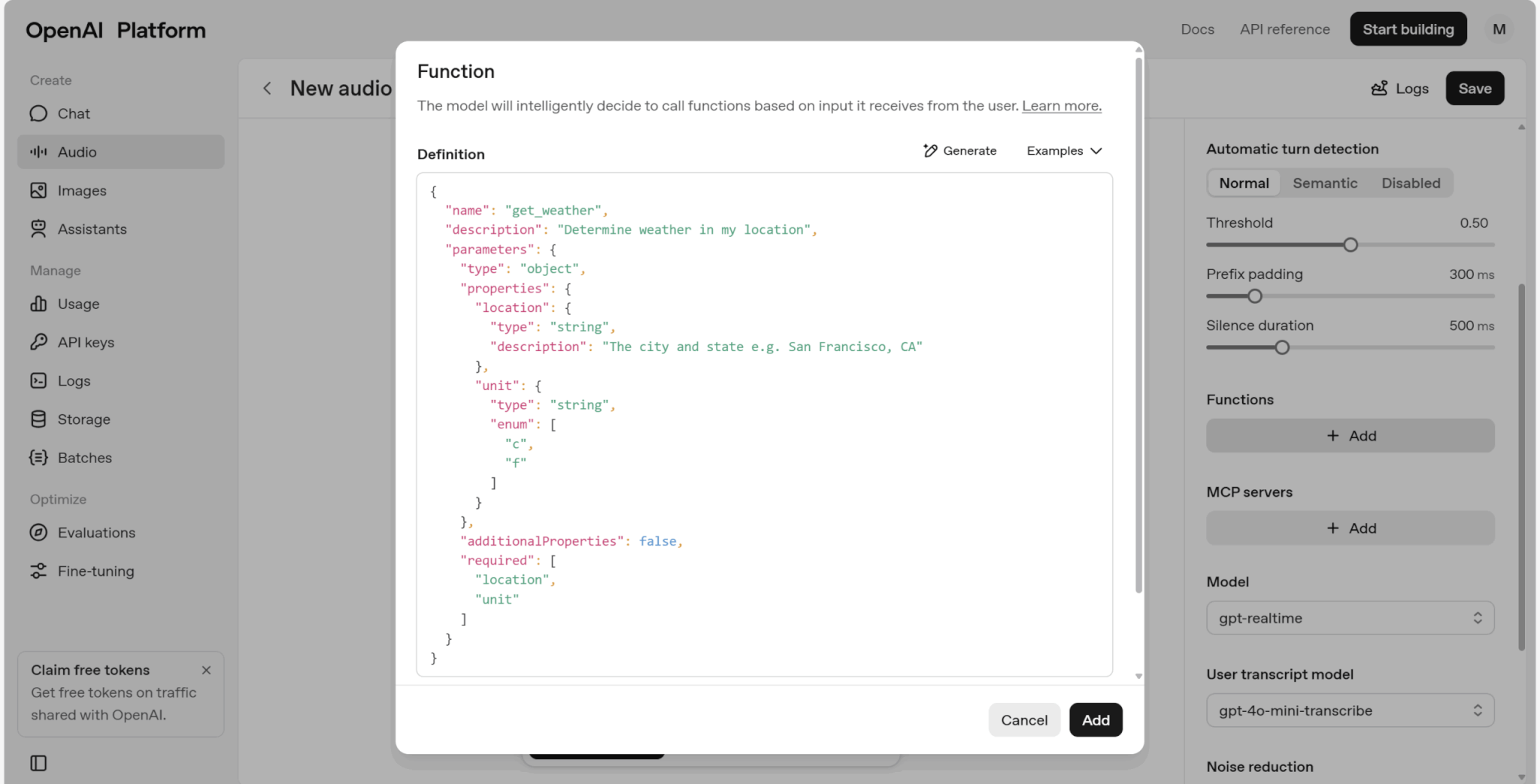
関数は自由に編集可能です。
ここでは、取得する天気情報の位置を「Tokyo」に変更します。
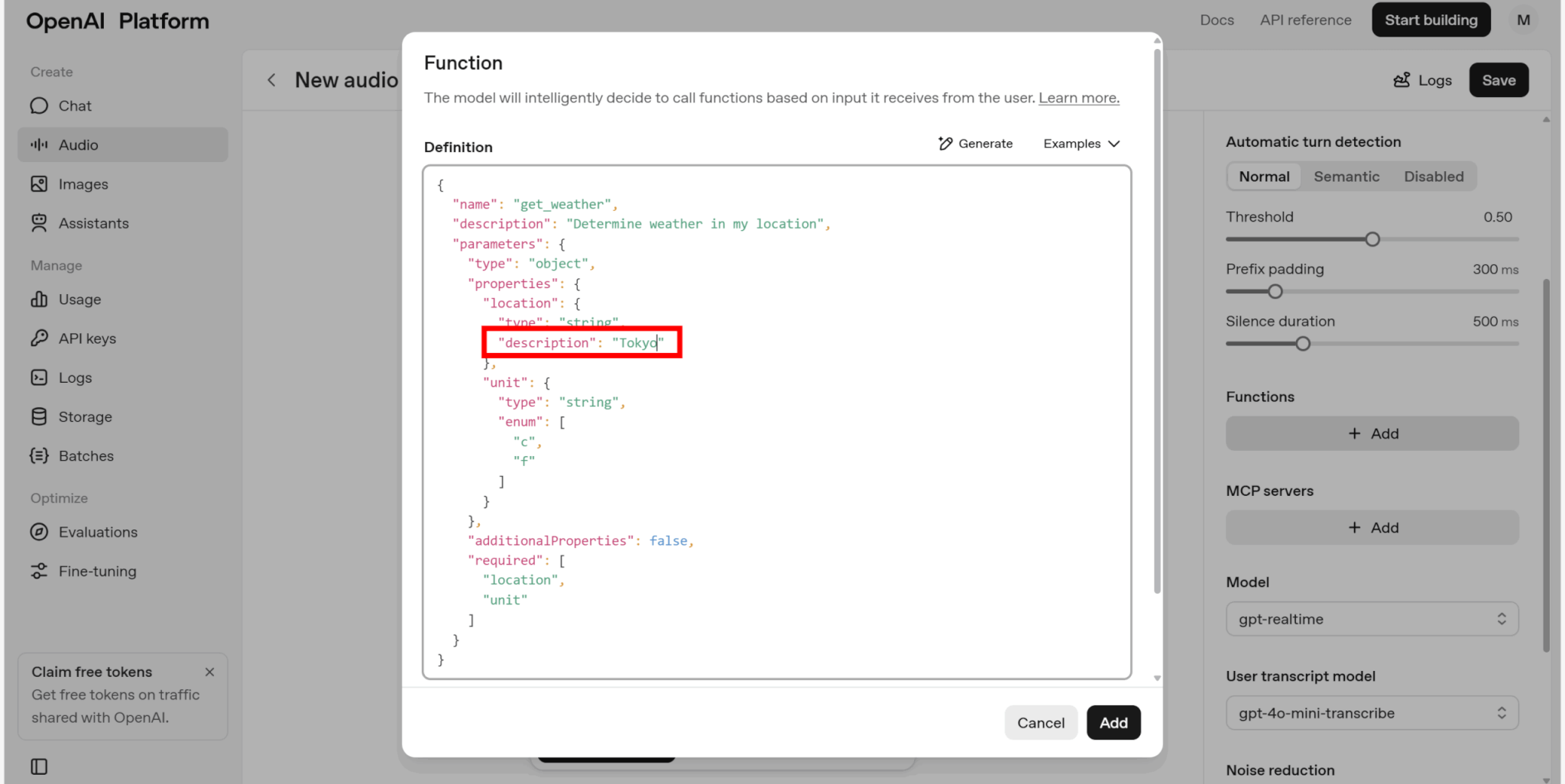
Functionsに追加した関数の名前が表示されていれば完了です。
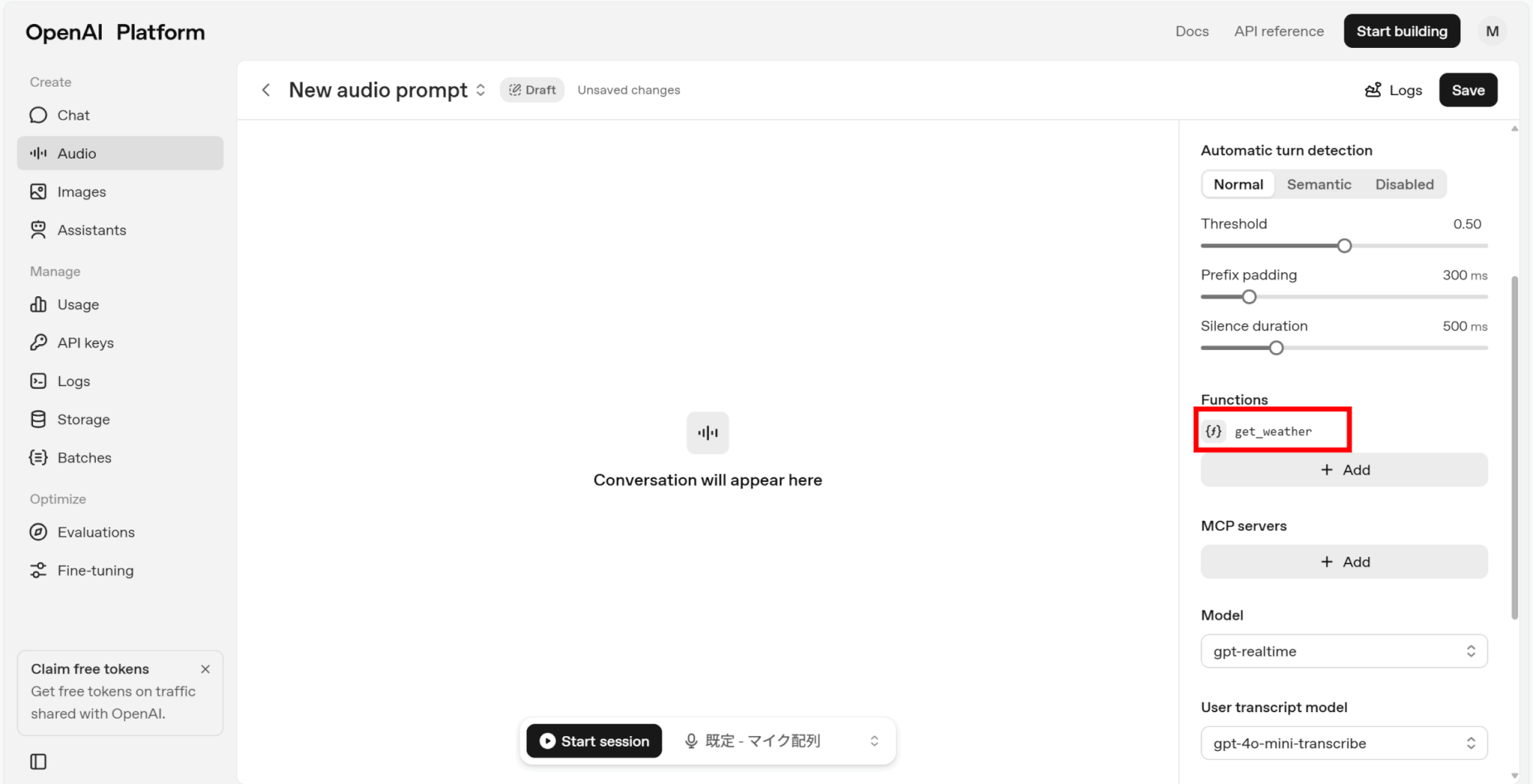
MCPサーバーを追加したい場合は、「MCP servers」の「Add」をクリックしましょう。
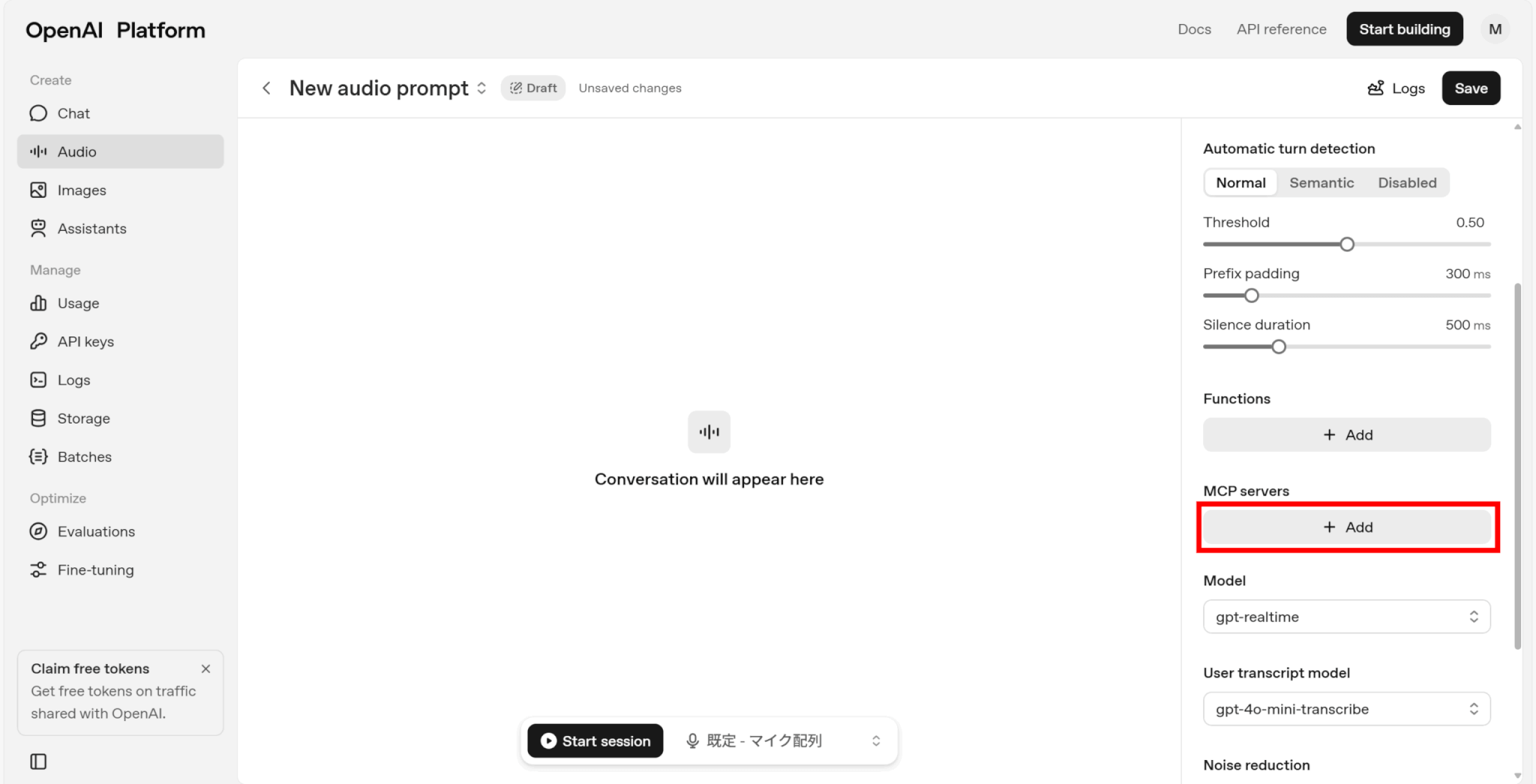
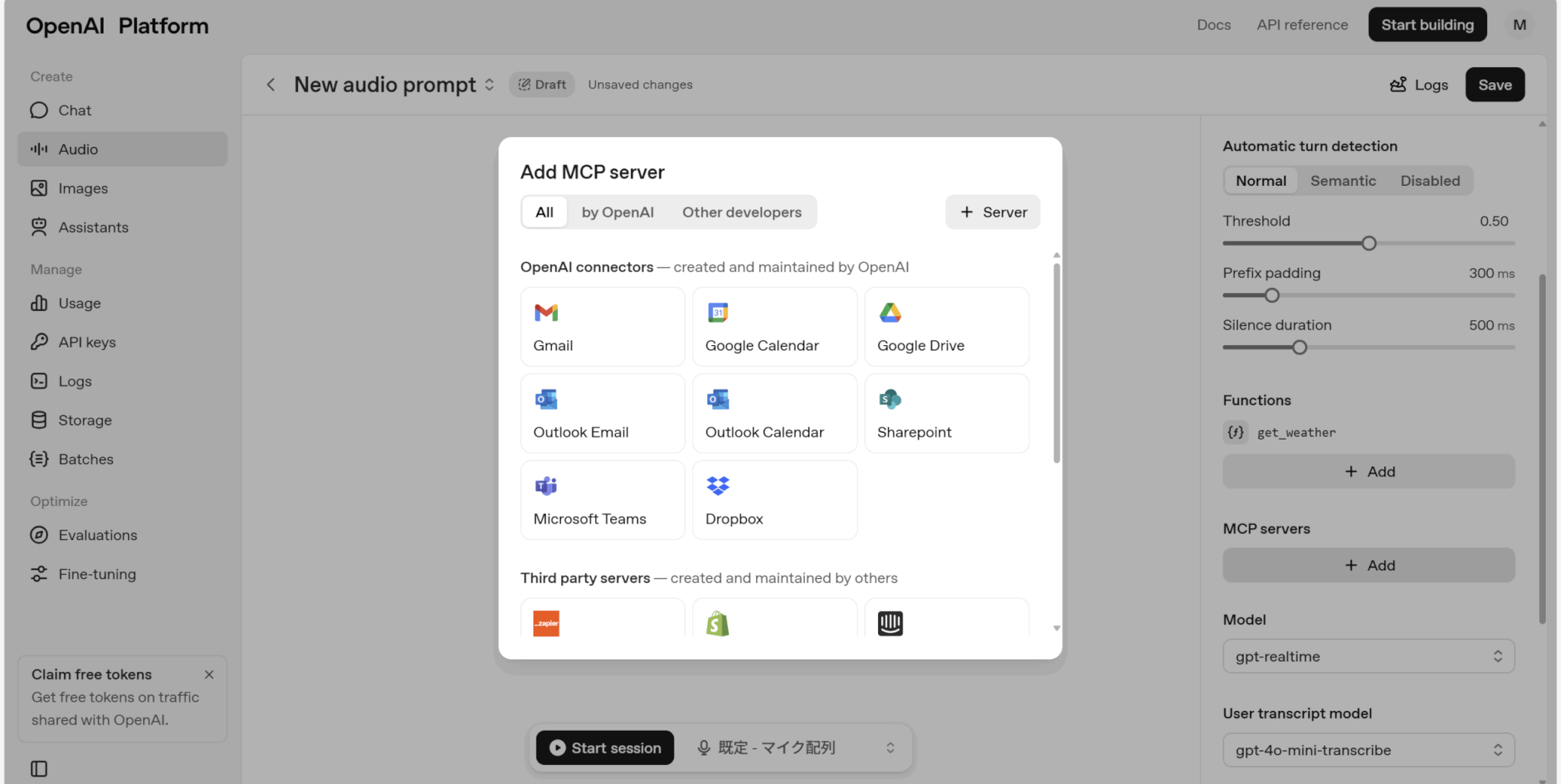
使用できるMCPサーバーが表示されるため、使いたいものを選択しましょう。
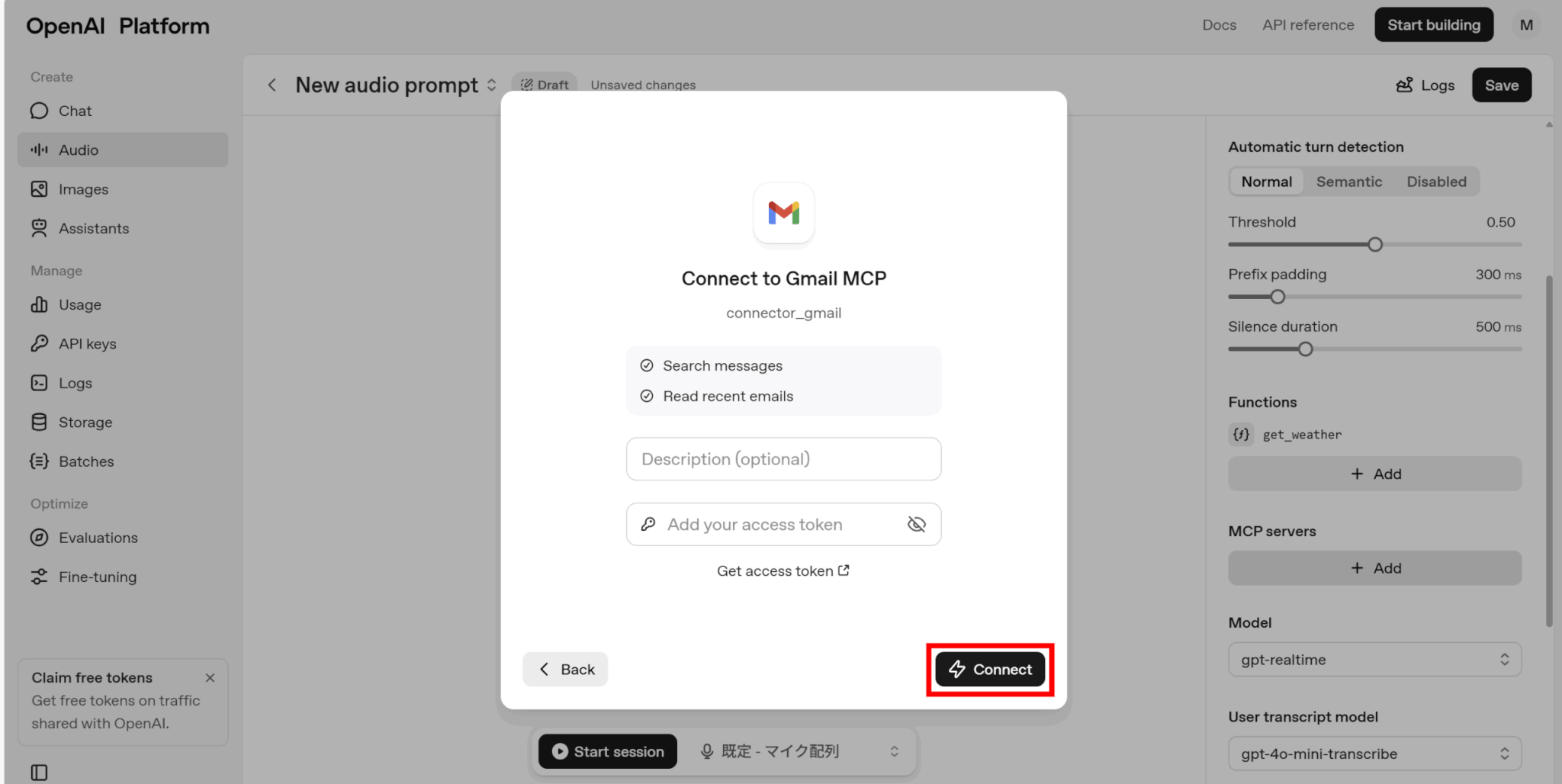
必要事項を記入して「Connect」をクリックしてください。
なお、今回はMCP連携はせずに進めていきます。
ツールを追加すると、画面右側の一番下にツールの使用設定が現れます。
基本的には「auto」に設定しておくと問題ないでしょう。
必要なツールを追加できれば、会話を開始しましょう。
会話内容に応じて、先ほど追加した関数やMCPサーバーが自動的に使用されます。
実際の会話内容は以下の通りです。
なお、実際の東京の天気はこちらです。
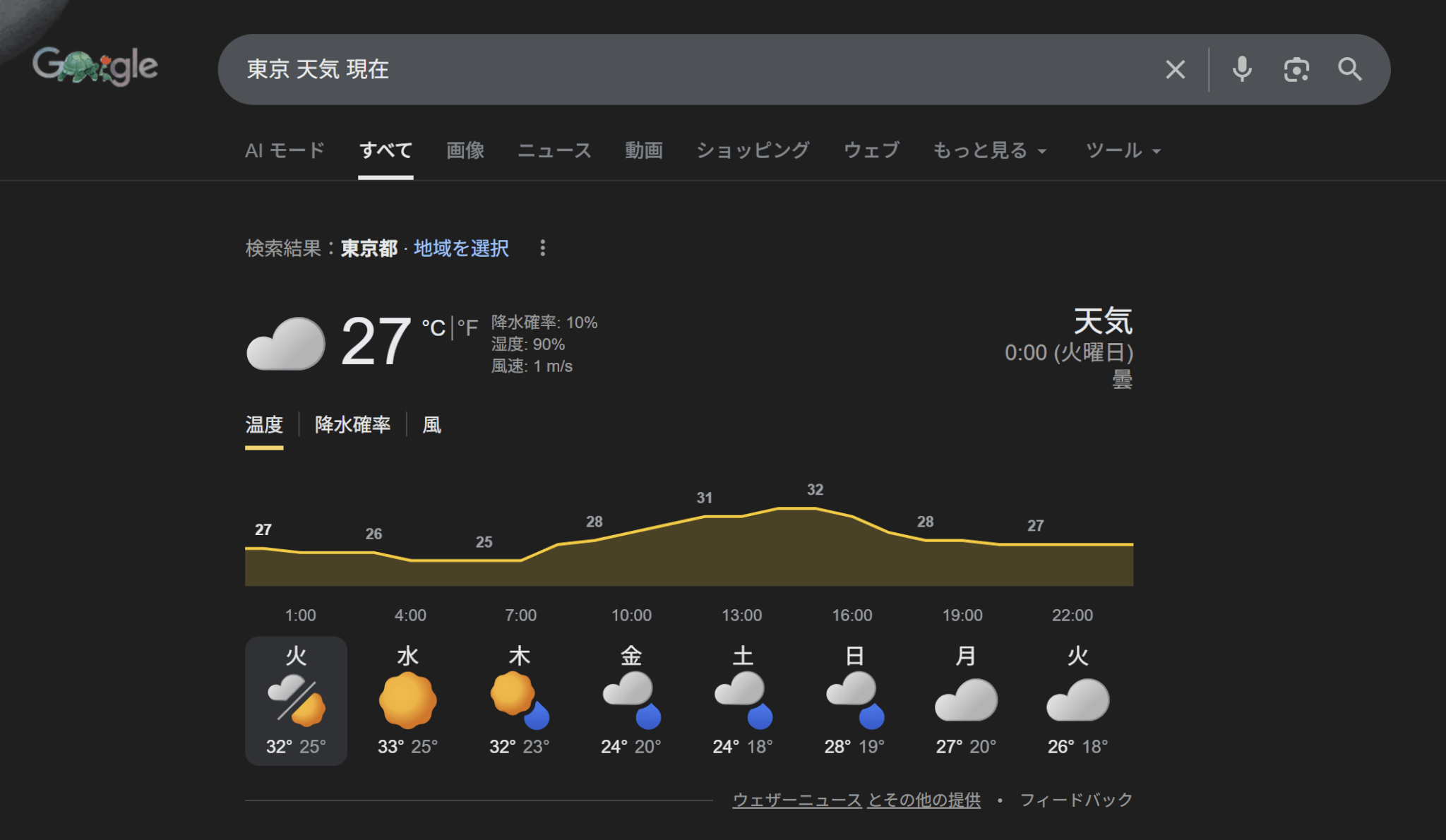
例の関数を使用しただけであるため、精度についてはあまりよくありませんでした。
ただし、実際には自分で関数を作成できるため、適切な関数を設定することで精度はよくできるでしょう。
プロンプト設計と運用Tips
gpt-realtimeを活用する際は、システムプロンプトに「アシスタントの役割」や「会話のトーン」を明示しておくと、安定した応答が得られます。
リアルタイム会話ではユーザーの発話を遮るケースもあるため、割り込み制御の設定(無音判定の時間やしきい値)を調整して自然なやり取りを実現しましょう。
また、WebRTCやWebSocketを使用して実装する場合、ログ管理を導入して会話履歴を確認できるようにすると、改善点や誤動作の原因を追いやすくなります。
さらに、API利用時にはトークン消費量を把握しておくことが重要です。
無駄な応答や過剰な情報出力を避けるために、出力長やリクエスト回数を制御する設計が推奨されます。
こうした工夫を積み重ねることで、安定性とコスト効率の両立が可能になります。
まとめ
gpt-realtimeとは、音声を直接処理することによって低遅延な会話を可能とした音声モデルです。
自然で表現力豊かな音声や割り込み制御によって、人間同士のような自然な会話ができるようになります。
高性能な音声アシスタントや、SIP連携を活用したカスタマーサポートなどに利用可能です。
Playgroundを使えば簡単に試すことができるため、気になる方は応答性能や音声品質を確認し、導入の可否を判断することをおすすめします。