

OpenAIは、新モデル「GPT-5.5」をリリースしました。同社はGPT-5.5について、これまでで最も賢く、直感的に使いやすいモデルと位置づけており、コンピュータ上で仕事を進める新しい方法に向けた次のステップだと説明しています。
GPT-5.5は、ユーザーが何をしようとしているのかをより速く理解し、作業の多くを自律的に進められる点が特徴です。コードの作成やデバッグ、オンライン調査、データ分析、文書やスプレッドシートの作成、ソフトウェア操作などに対応し、複数のツールをまたぎながらタスク完了まで進められます。細かな手順を毎回指示しなくても、複雑で曖昧な依頼に対して計画を立て、ツールを使い、自らの作業を検証しながら継続できるとしています。
性能向上が特に大きい領域としては、エージェント型コーディング、コンピュータ操作、ナレッジワーク、初期段階の科学研究が挙げられています。GPT-5.5は、より高い知能を備えながら、実運用環境におけるトークンごとのレイテンシはGPT-5.4と同等です。Codexの同じタスクを完了する際に必要なトークン数も少なく、処理効率の面でも改善されました。
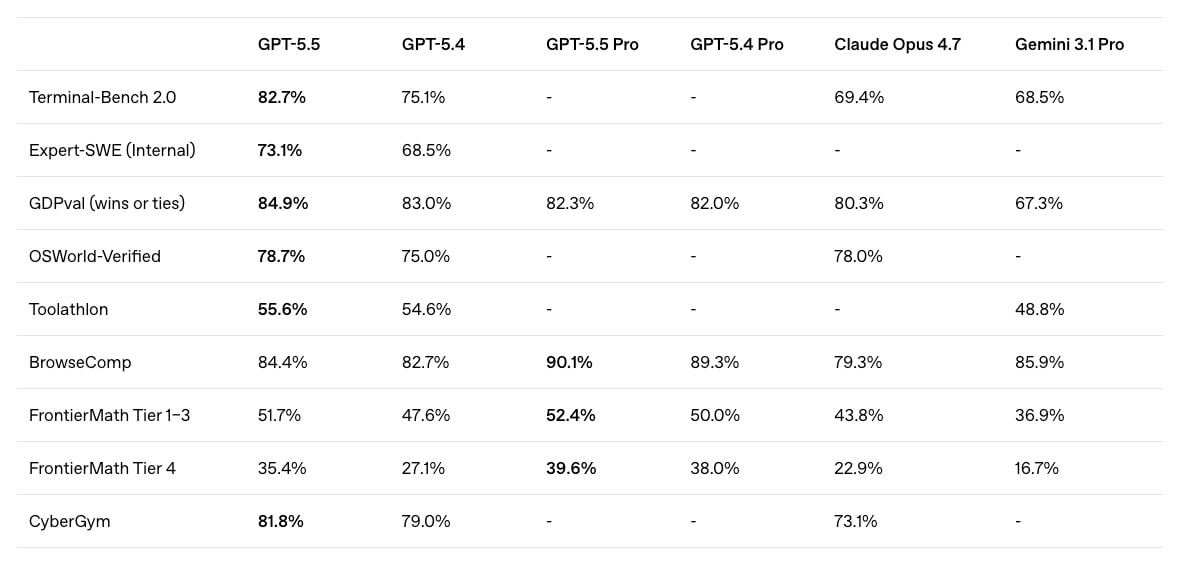
ベンチマークでは、複雑なコマンドライン作業を評価するTerminal-Bench 2.0で82.7%を記録し、GPT-5.4の75.1%、Claude Opus 4.7の69.4%、Gemini 3.1 Proの68.5%を上回りました。実世界のGitHub課題解決を評価するSWE-Bench Proでは58.6%、OpenAI内部評価のExpert-SWEでは73.1%となっています。ナレッジワークを測るGDPvalでは84.9%、実際のコンピュータ環境を操作する能力を測るOSWorld-Verifiedでは78.7%を記録しました。
また、BrowseCompではGPT-5.5が84.4%、GPT-5.5 Proが90.1%を達成しました。FrontierMath Tier 1–3ではGPT-5.5が51.7%、Tier 4では35.4%となり、数学や高度な推論を含む評価でもGPT-5.4を上回っています。サイバーセキュリティ領域のCyberGymでは81.8%を記録し、GPT-5.4の79.0%、Claude Opus 4.7の73.1%を上回りました。
OpenAIは、安全対策についても強化したと説明しています。社内外のレッドチームによる検証に加え、高度なサイバーセキュリティや生物学分野の能力に関する追加テストを実施し、約200の信頼済み早期アクセスパートナーからのフィードバックも反映しました。生物・化学およびサイバーセキュリティ能力については、Preparedness Framework上でHighと扱われています。
GPT-5.5は、ChatGPTとCodexでPlus、Pro、Business、Enterpriseユーザー向けに順次提供されます。GPT-5.5 Proは、ChatGPTでPro、Business、Enterpriseユーザー向けに提供されます。APIについては近日中に提供予定で、gpt-5.5は100万入力トークンあたり5ドル、100万出力トークンあたり30ドル、gpt-5.5-proは100万入力トークンあたり30ドル、100万出力トークンあたり180ドルで提供される予定です。