
この記事のポイント
- ElevenLabsが新たな音声認識モデル「Scribe」をリリース
- 主要ベンチマークでGemini 2.0やOpenAI Whisper v3、Deepgramを上回る精度
- 合計99言語に対応し、従来精度が低かった言語(セルビア語・広東語・グジャラート語など)の性能も改善
- UIとAPIを通じて利用可能で、価格は1時間あたり0.40ドル
- リリース後6週間の期間限定で50%割引キャンペーンを実施
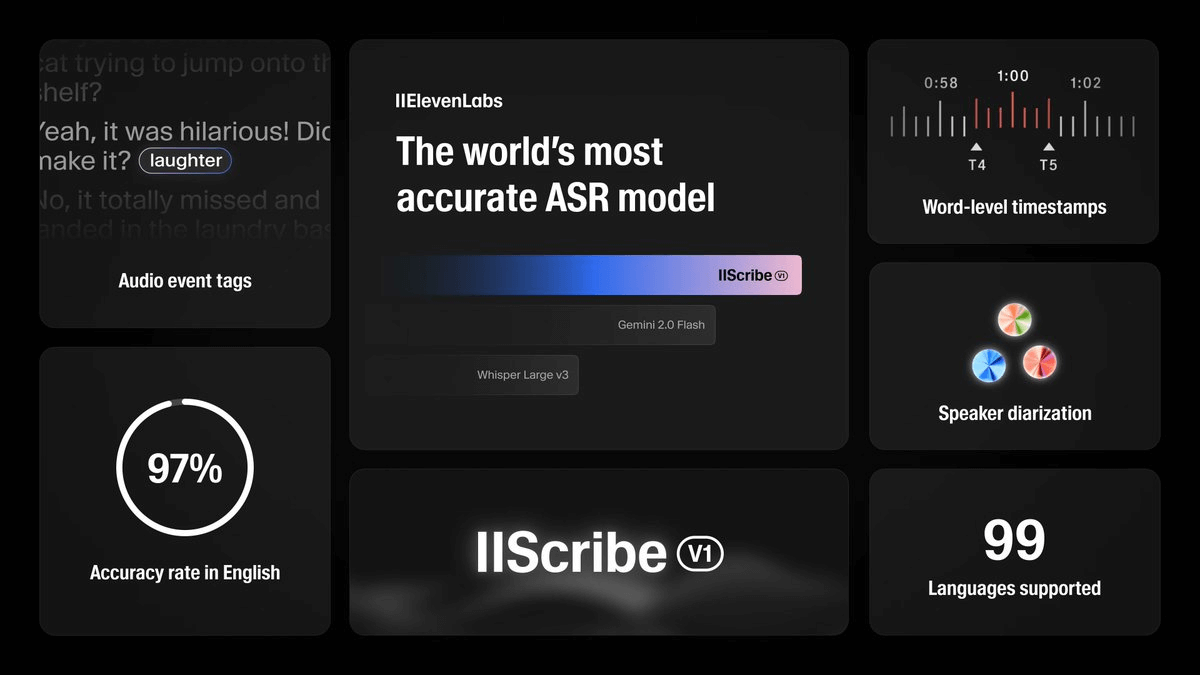
AI音声ソリューションを手掛けるElevenLabsは、新たな音声認識モデル「Scribe」をリリースしました。
英語やスペイン語、イタリア語をはじめとする主要言語に加え、合計99の言語に対応し、既存の先端モデルであるGemini 2.0、OpenAI Whisper v3、Deepgramをほぼすべての主要ベンチマークで上回る精度を達成したとしています。
Scribeの特徴として、スピーカーを正確に分離する「スピーカー・ダイアライゼーション」や、音楽・笑い声などの非言語音声イベントの認識、文字レベルでのタイムスタンプ取得など多彩な機能が挙げられます。
特に従来あまり対応が進んでいなかったセルビア語や広東語、グジャラート語などの言語に対しても精度が大幅に改善されており、多言語での利用ニーズに応える設計となっています。
また今後は低遅延版Scribeの提供を予定しており、リアルタイム性が求められるユースケースやライブ配信での活用が期待されています。すでにElevenLabsのユーザーインターフェース(UI)およびAPIを通じて利用でき、価格は入力音声1時間あたり0.40ドルです。
さらに、リリース直後の6週間に限り50%割引のキャンペーンが適用されるため、早期導入を検討する企業や開発者にとっては魅力的な条件といえるでしょう。
ElevenLabsのリード研究者はSNS上で「数カ月にわたる研究開発の成果であり、音声認識を『理解』のレベルまで引き上げる」と述べ、公式ブログには詳細なベンチマーク結果や機能紹介が掲載されています。日々進化する音声認識技術の分野において、Scribeは新たなベースラインとなる可能性が注目されています。