

ConoHa AI Canvasは、Stable Diffusionをクラウド上で手軽に使えるサービスです。高性能PCを持っていなくても、ブラウザからアクセスするだけで高品質な画像生成が可能です。
本記事では、ConoHa AI Canvasの使い方や料金プラン、LoRAの導入手順をわかりやすく解説します。また、実際にエントリープランを契約して操作した体験を踏まえ、レビューとして利用感も紹介します。
\ MiraLab AIの読者限定で500円割引適用中 /
ConoHa AI Canvasとは?通常のStable Diffusionとの違いは?
ConoHa AI Canvasは、GMOインターネットグループが提供するAI画像生成プラットフォームで、Stable Diffusion XLをベースにしています。
通常のStable Diffusionは、高性能なPCや複雑なセットアップが必要で、始めるまでに大きなハードルがありました。

ConoHa AI Canvasならクラウド上で環境が整っているため、アカウントを作成するだけですぐに画像生成を始められます。
ここでは、ConoHa AI Canvasと通常のStable Diffusionの違いを詳しく見ていきましょう。
ConoHa AI CanvasでStable Diffusionを使うメリット
ConoHa AI Canvasを使えば、面倒な環境構築や高性能PCの準備なしで、すぐにStable Diffusionによる画像生成を始められます。アカウントを作るだけで、初心者から中上級者まで手軽に利用可能です。
主なメリットは次のとおりです。
- 環境構築不要:ブラウザ上で動作するため、PCの性能に左右されずに利用できる
- 日本語UI対応:主要な操作が日本語化されており、初めての人でも迷いにくい
- 一括アップロード対応:ファイルマネージャーからLoRAやモデルをまとめて追加可能
- プリインストールCheckpoint:Stable Diffusion XLなど主要モデルが最初から利用可能
- クラウドストレージ:生成した画像やモデルをオンラインで管理でき、ローカル容量を圧迫しない
使えない機能などの違い
ConoHa AI Canvasには、クラウドサービスならではの制約があります。
一つ目は「自動終了タイマー」です。一定時間操作しないまま放置するとセッションが自動的に終了します。
これによって余計な課金が発生しない仕組みになっていますが、長時間離席して再開したいときには再起動が必要になる場合があります。
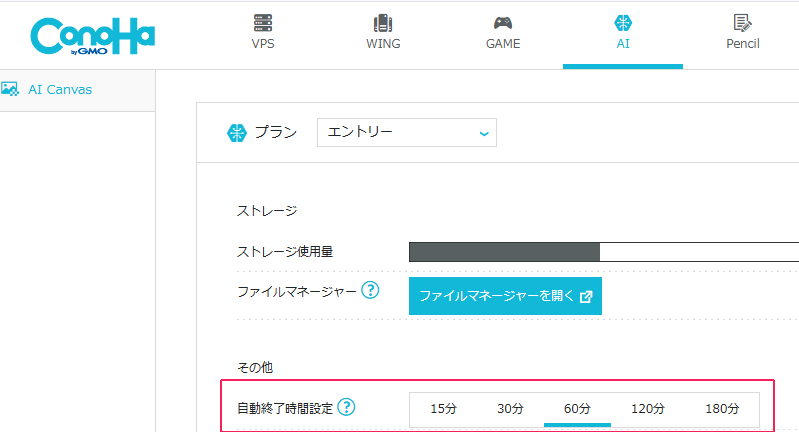
二つ目は「同時起動制限」です。1アカウントで同時に立ち上げられるインスタンスは基本的に1つまでで、複数のWebUIを並行して動かすことはできません。ただし、必要に応じてAUTOMATIC1111とComfyUIを切り替えて利用することは可能です。
こうした制約はあるものの、通常の画像生成やLoRAの利用には十分で、むしろ環境構築や設定を気にせず安定して使える点が大きな魅力といえるでしょう。
WebUIの選択肢(AUTOMATIC1111 / ComfyUI)
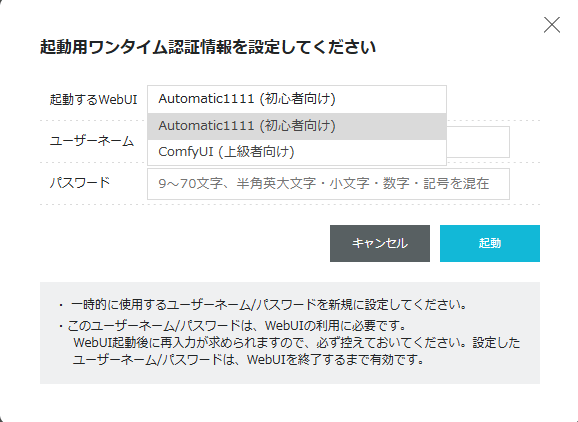
ConoHa AI Canvasでは、サーバー起動時に「AUTOMATIC1111」か「ComfyUI」を選んで利用できます。
従来はAUTOMATIC1111のみ利用できましたが、新たにComfyUIも加わったことで、ユーザーの用途に合わせたUI選択が可能になりました。
AUTOMATIC1111は、Stable Diffusionの定番WebUIで、シンプルな操作性と拡張機能の豊富さが魅力です。直感的に画像生成を始められるので、初めてStable Diffusionを触る方にも使いやすい環境といえます。
ComfyUIはノードベースのUIで、生成処理の流れをブロックとして自由に組み替えられるのが特徴です。標準でテンプレートが用意されており、高度なワークフローや動画生成なども柔軟に実行できます。
初期状態のUIと拡張機能
ConoHa AI Canvasでは、初期状態で「AUTOMATIC1111」と「ComfyUI」の2種類のWebUIが用意されており、拡張機能を組み合わせることで用途に応じた柔軟な環境を整えることができます。
AUTOMATIC1111は日本語化拡張機能がプリインストールされ既定で有効のため、初回起動時から日本語表示です。また、ComfyUIは既定で日本語表記です。
また、Stable Diffusion WebUI(AUTOMATIC1111)で動作する拡張機能のひとつPrompt All in Oneは、プロンプト入力を整理しやすくするのが特徴です。ポジティブプロンプトやネガティブプロンプトといった複数の入力欄をまとめて管理でき、タグ補完や翻訳支援、よく使うプロンプトのプリセット呼び出しも可能です。
ConoHa AI Canvasには最初からPrompt All in Oneが導入されており、追加インストールの必要がなく、初心者でも効率的にプロンプトを組み立てられる環境が整っています。
ConoHa AI Canvasでは、Checkpoint(モデル)があらかじめ用意されています。初期状態で導入されていると、公式で発表されているCheckpoint(モデル)は、ComfyUIの「v1-5-pruned-emaonly」です。
しかし、AUTOMATIC1111でも以下のCheckpoint(モデル)が初期導入されていました。またComfyUIでも、以下のモデルの他、Flux系列のモデルもプリインストールされていました。(2025年8月時点)
| モデル名 | 系列 | 画風 | 利用用途 |
| 512-inpainting-ema | Stable Diffusion 2 | 汎用系 | 画像の一部分を修正・再生成(インペインティング) |
| v1-5-pruned-emaonly | Stable Diffusion 1.5 | アニメ・マンガ風 | 高解像度で精巧なアニメ風イラストの生成 |
| realDream_15SD15 | Stable Diffusion 1.5 | 実写・リアル系 | 写真のような高品質な人物や風景の生成 |
| yayoiMix_v25 | Stable Diffusion 1.5 | 和風・東洋風 | 和風や東洋的なテイストのイラストの生成 |
| v2-1_768-ema-pruned | Stable Diffusion 2.1 | 汎用系 | 高解像度の汎用的な画像生成、幅広い用途に対応 |
| fudukiMix_v20 | Stable Diffusion XL | 実写・リアル系 | 写真のような高品質な人物や風景の生成 |
| animagine-xl-4.0 | Stable Diffusion XL | アニメ・マンガ風 | 高解像度で精巧なアニメ風イラストの生成 |
| sd_xl_base_1.0 | Stable Diffusion XL | 汎用系 | 高品質な高解像度画像生成の土台、多様なジャンルに対応 |
| sd_xl_refiner_1.0 | Stable Diffusion XL | 汎用系 | 他のモデル(sd_xl_base_1.0など)で生成した画像のディテール向上 |
これらのモデルのうち、512-inpainting-emaとsd_xl_refiner_1.0に関しては、画像を生成する際に選択するモデルではなく、画像を加工する際に選択するモデルとなっているので注意が必要です。
\ MiraLab AIの読者限定で500円割引適用中 /
ConoHa AI Canvasの料金プラン

ConoHa AI Canvasは、利用者のニーズに合わせた3つの料金プランを提供しており、それぞれが異なる利用量やストレージ容量に対応しています。
これにより、初心者からプロフェッショナルまで、さまざまなレベルのユーザーが自分に合ったプランを選択できます。
以下に各プランの詳細を比較し、それぞれがどのような利用シーンに適しているかを見ていきましょう。
料金プランの比較表
ConoHa AI Canvasの各プランでは、無料生成時間が付与されるほか、それを超えた分は従量課金で利用可能です。従量課金の料金は1分あたり6.6円で、必要に応じて柔軟に利用を拡張できます。
各プランの料金と無料生成時間の詳細をまとめました。
| プラン名 | 月額料金(税込) | ストレージ容量 | WebUI無料利用時間 | おすすめユーザー |
|---|---|---|---|---|
| エントリー | 1,100円 | 30GB | 10時間 | 初心者・ライトユーザー |
| スタンダード | 4,378円 | 100GB | 50時間 | 定期的に利用するユーザー |
| アドバンス | 9,878円 | 500GB | 100時間 | プロジェクトが大きい場合 または企業 |
なお、生成枚数には上限はありません。
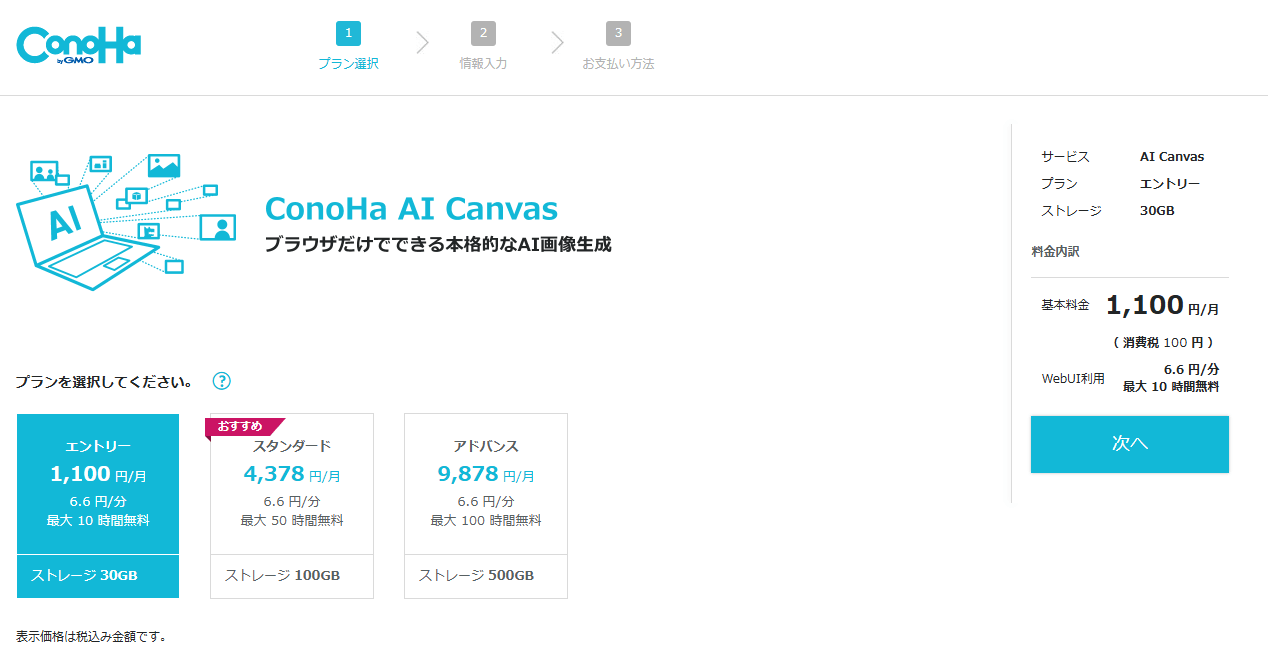
エントリープラン
エントリープランは、ConoHa AI Canvasを気軽に試してみたい初心者向けのプランです。
30GBのストレージと10時間のWebUI無料利用時間が含まれており、AI画像生成の初心者に最適です。
以前は1時間だったのが現在は10時間まで増えており、少量の画像生成や短時間の利用を想定している方なら十分満足できるプランです。
- おすすめユーザー:少ない利用頻度で十分なライトユーザー
- メリット:低価格で手軽にAI画像生成を試せる
- 注意点:無料利用時間が10時間と限られているため、頻繁に画像生成を行う方にはコストが上がる可能性がある
特に、少ない利用頻度でもAI画像生成を楽しみたい方や、初めての利用者にとって最適な選択肢です。
スタンダードプラン
スタンダードプランは、定期的にAI画像生成を行いたいクリエイター向けのプランです。
100GBのストレージと50時間のWebUI無料利用時間が含まれており、エントリープランに比べて利用時間やストレージ容量が大幅に増えます。
これにより、クリエイティブなプロジェクトに継続的に取り組む方にとって、コストパフォーマンスの高い選択肢となっています。
- おすすめユーザー:定期的にAI画像生成を行うクリエイターやデザイナー
- メリット:プロジェクトに合わせて、柔軟に利用できる。十分なストレージと利用時間を提供
- 注意点:短期間に大量の画像生成をする場合は、上位のアドバンスプランを検討
中規模なクリエイティブプロジェクトを進めるための安定した環境を提供し、画像生成の頻度が高いユーザーにとって理想的です。
アドバンスプラン
アドバンスプランは、プロフェッショナル向けのプランで500GBのストレージと100時間のWebUI無料利用時間が含まれています。
大量の画像生成を必要とするクリエイティブ業界や企業向けの選択肢であり、長時間にわたるプロジェクトや、継続的に高品質な画像を生成する場合に最適です。
- おすすめユーザー:大規模なプロジェクトを進める企業やプロフェッショナル
- メリット:大量の画像生成や長時間の利用が可能、業務やプロジェクトの要件にしっかり応える
- 注意点:初心者や個人でのライトな使用にはややオーバースペック
特にクリエイティブエージェンシーやゲーム開発、広告業界など、プロジェクトの規模が大きくなる業務に最適です。
豊富なストレージと無料利用時間により、効率的にAI画像生成を進めることができます。
無料WebUI時間と従量課金(6.6円/分)の仕組み
ConoHa AI Canvasでは、各プランに応じて無料のWebUI利用時間が提供されています。無料時間を超過すると、従量課金が適用され、1分あたり6.6円の料金が発生します。

この仕組みにより、利用者は自分の利用状況に応じて柔軟にプランを選択・変更を検討することが可能です。
読者限定割引実施中
現在、MiraLab AIの読者限定で500円割引が適用される特別キャンペーンを実施しております。
エントリープランであれば通常は初月1,100円(税込)のところ、半額の550円(税込)でご利用いただけます。
以下のリンクからお申し込みいただくと自動的に割引が適用されますので、この機会にぜひご活用ください。
\ MiraLab AIの読者限定で500円割引適用中 /
ConoHa AI CanvasでのStable Diffusionの始め方と使い方

ConoHa AI Canvasは、複雑な操作が必要なく、クラウド上で簡単に画像が作れるサービスです。
ここでは、実際にアカウントを作成し、画像を作り始めるまでのステップを紹介します。
新規アカウント作成(サインアップ)
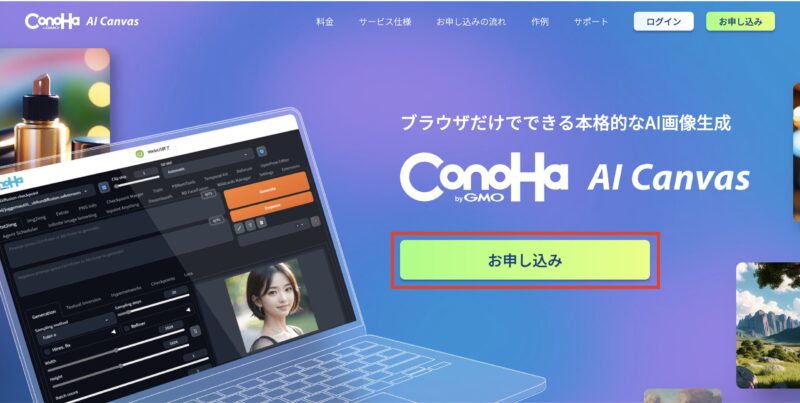
メールアドレスとパスワードを入力しましょう。
プラン選択とWebUIの起動
エントリー、スタンダード、アドバンスの中から自分に合ったプランを選び、「次へ」をクリックします。
お客様情報を入力しましょう。
電話認証またはSMS認証を行います。
お支払い方法を入力し「お申し込みを確定」をクリックします。

プランを選んだら「WebUI起動」ボタンをクリックして、画像生成の準備を整えます。
「ユーザーネーム」と「パスワード」を設定しましょう。
設定した「ユーザーネーム」と「パスワード」でログインします。
日本語UIの設定・確認
ConoHa AI CanvasのAUTOMATIC1111は、現在は初期状態から日本語UIが有効になっています。そのため、新規契約者は特別な設定をしなくても日本語表記で利用できます。
もしUIが英語のまま表示される場合は、2025年7月31日以前に契約した環境である可能性があります。その場合は以下の手順で日本語化を行ってください。
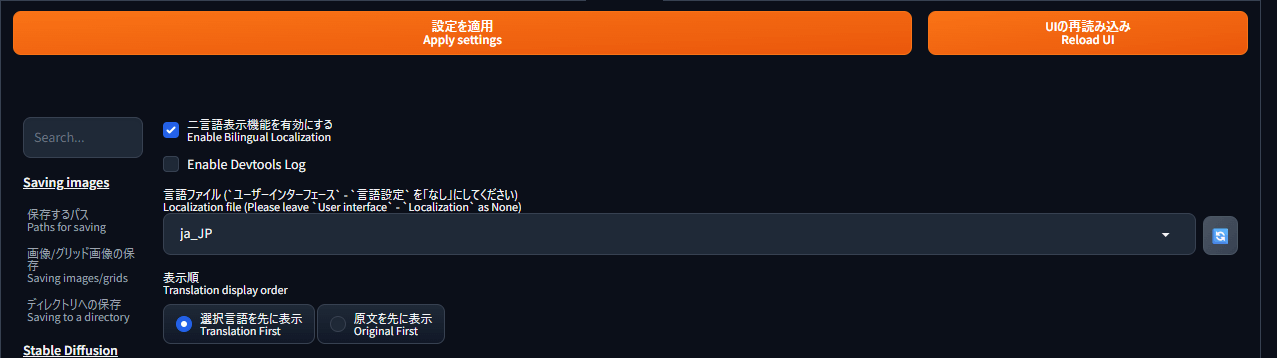
WebUIの右上にある「Settings(設定)」をクリックします。
二言語表示(日本語+英語)を有効にすることで、英語表記と突き合わせて調べられるようになり操作を理解しやすくなります。
設定→「ユーザーインターフェース」→「Localization」から「ja_JP」を選択肢、「None」を選びます。もしくは、設定画面の下の方にある「Bilingual Localization」で二言語表示を有効にチェックをして、言語ファイルは「ja_JP」を選びましょう。

「設定を適用(Apply settings)」をクリックし「UIの再読み込み(Reload UI)」をクリックすると、ログイン画面が表示されます。
ログインすると日本語と英語両方が表示されるように変更されています。
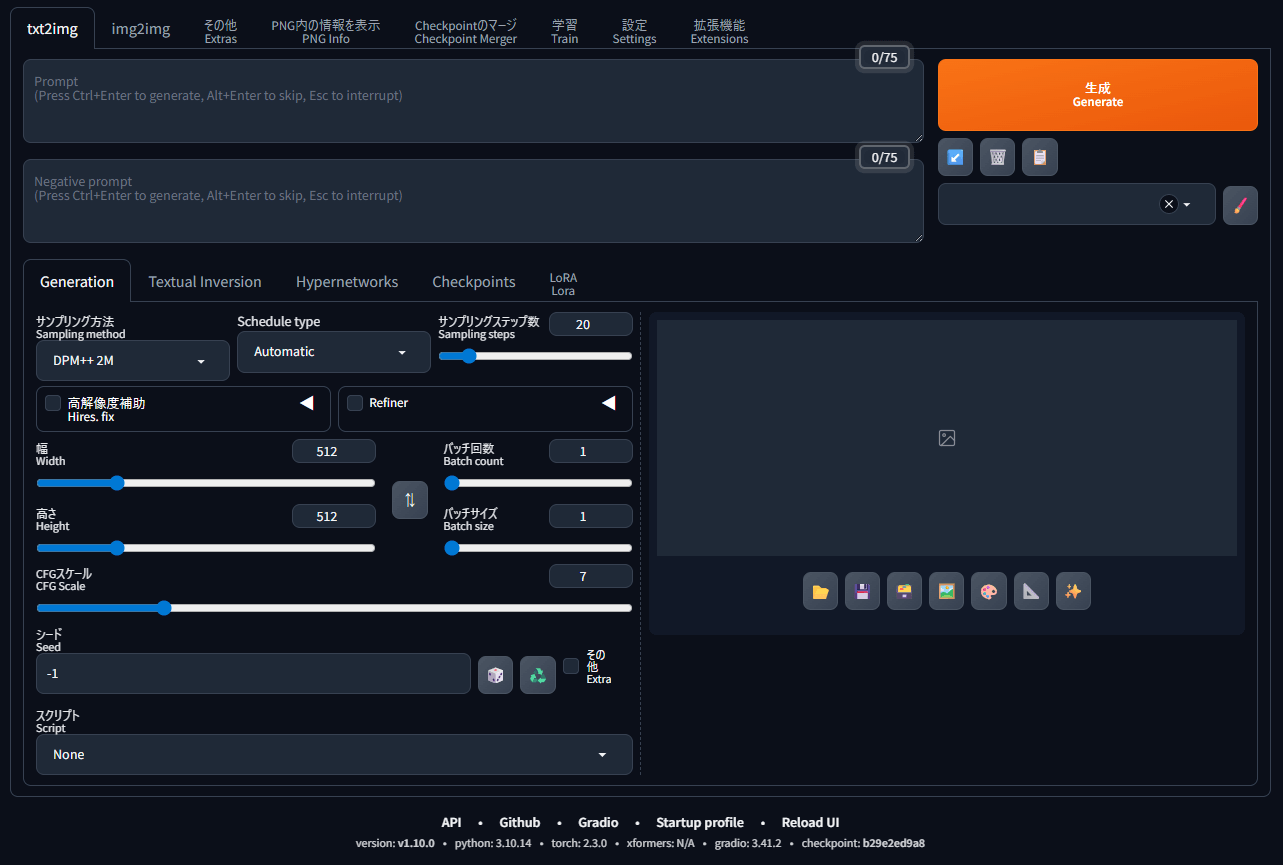
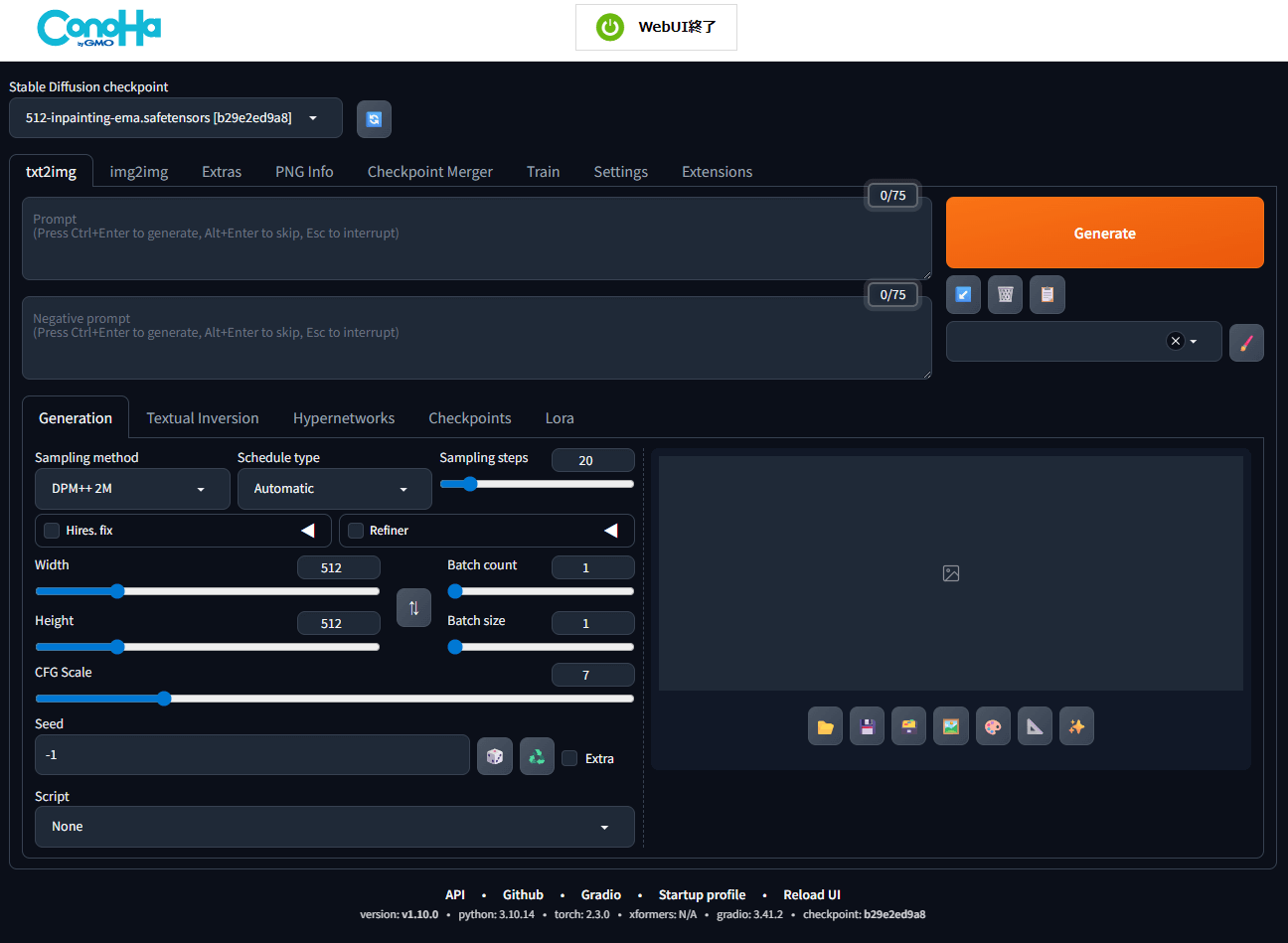
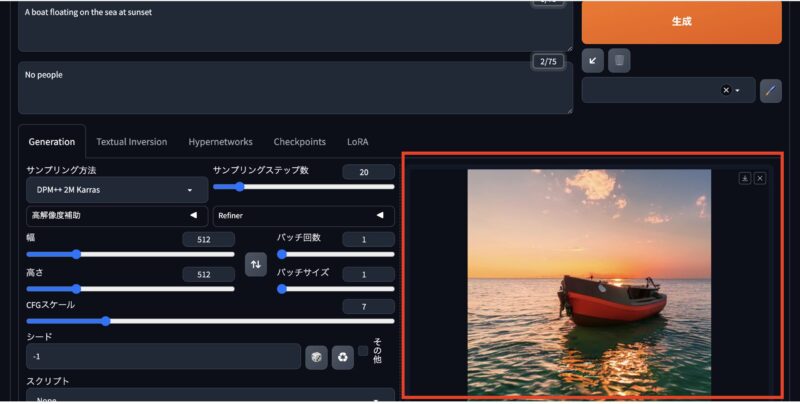
画像生成の方法(AUTOMATIC1111)
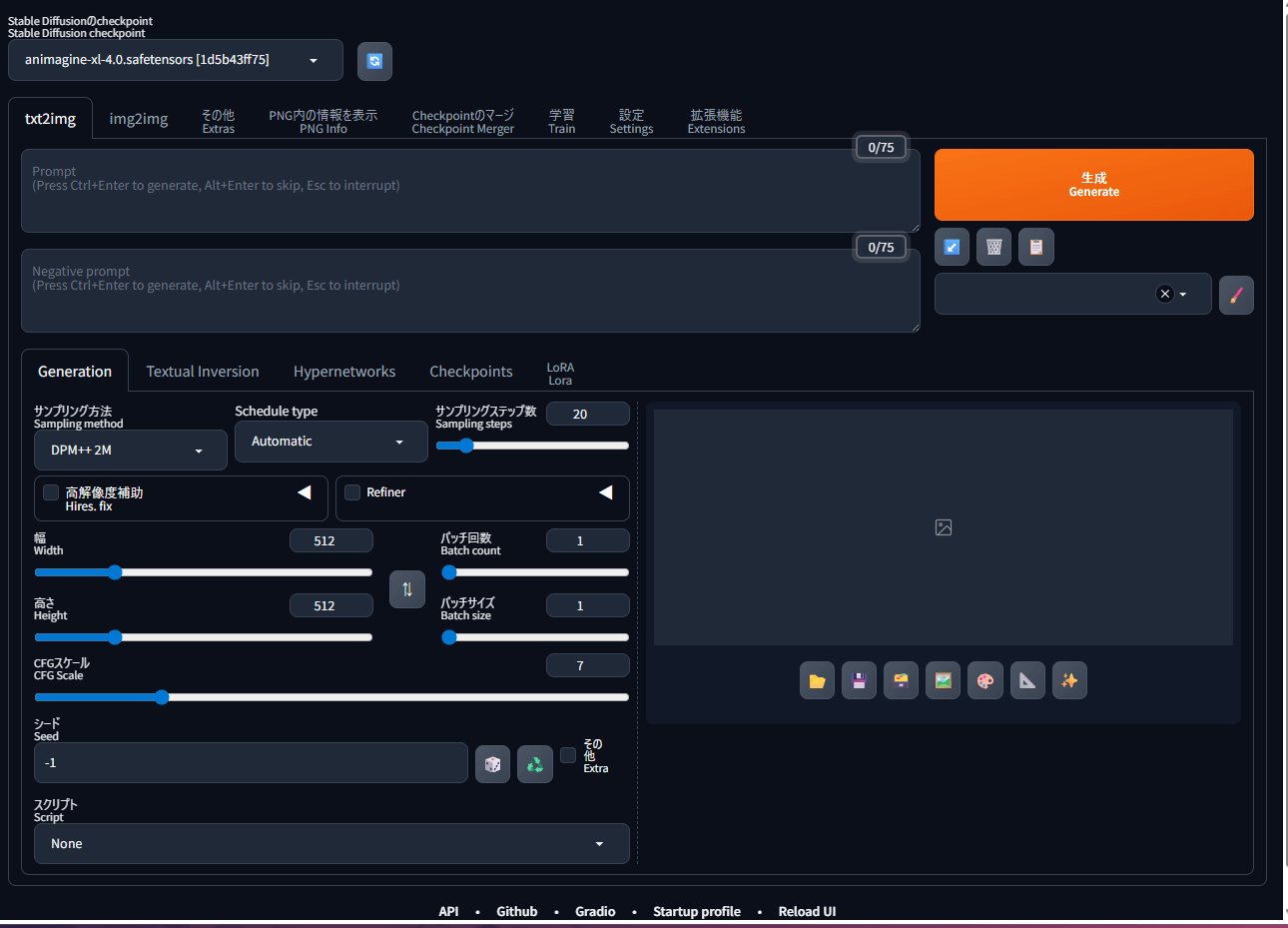
現在利用しているCheckpointが表示されているか確認しましょう。切り替え時に便利です。
設定→「ユーザーインターフェース」からクイック設定を選び、sd_model_checkpointを追加しましょう。

これを追加すると、上部に現在利用しているCheckpointが表示されます。
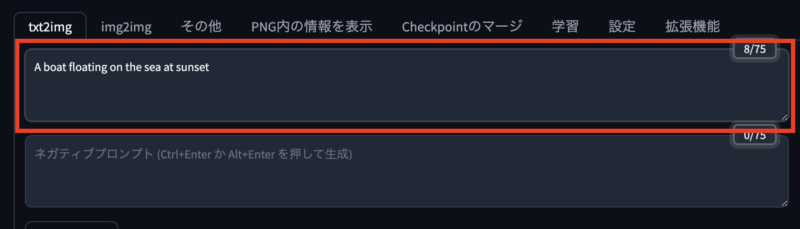
作りたい画像を説明する文章を入力します。
たとえば「A boat floating on the sea at sunset(夕焼けの海に浮かぶボート)」など。
作りたくない要素があればここに入力します(例:「ボートなし」「人なし」など)。
設定が完了したら「生成」ボタンを押して、AIに画像を作ってもらいます。
「生成」ボタンの下に画像が生成されます。
ComfyUIの基本
ComfyUIは、ノードベースでワークフローを組み立てていくタイプのWebUIです。一見すると煩雑そうに見えますが、その分、画像生成の工程を細かく制御できる柔軟性があります。
たとえば、プロンプトやサンプラーの設定に加えて、LoRAやVAE、アップスケーラーなどを自由に組み合わせることが可能です。通常のAUTOMATIC1111では難しい複雑な処理も、ComfyUIならノードをつなげるだけで実現できます。「もっと細かい調整をしたい」「独自のワークフローを作ってみたい」という上級者に特におすすめできるUIです。
ComfyUIでも画像生成の仕組みそのものは大きく変わらず、普段AUTOMATIC1111を使っている人なら同じ感覚で扱うことができます。違いは、設定が「ノード」という形で独立しているため、他の工程(アップスケーラーやLoRAの適用など)と柔軟に組み合わせやすい点です。
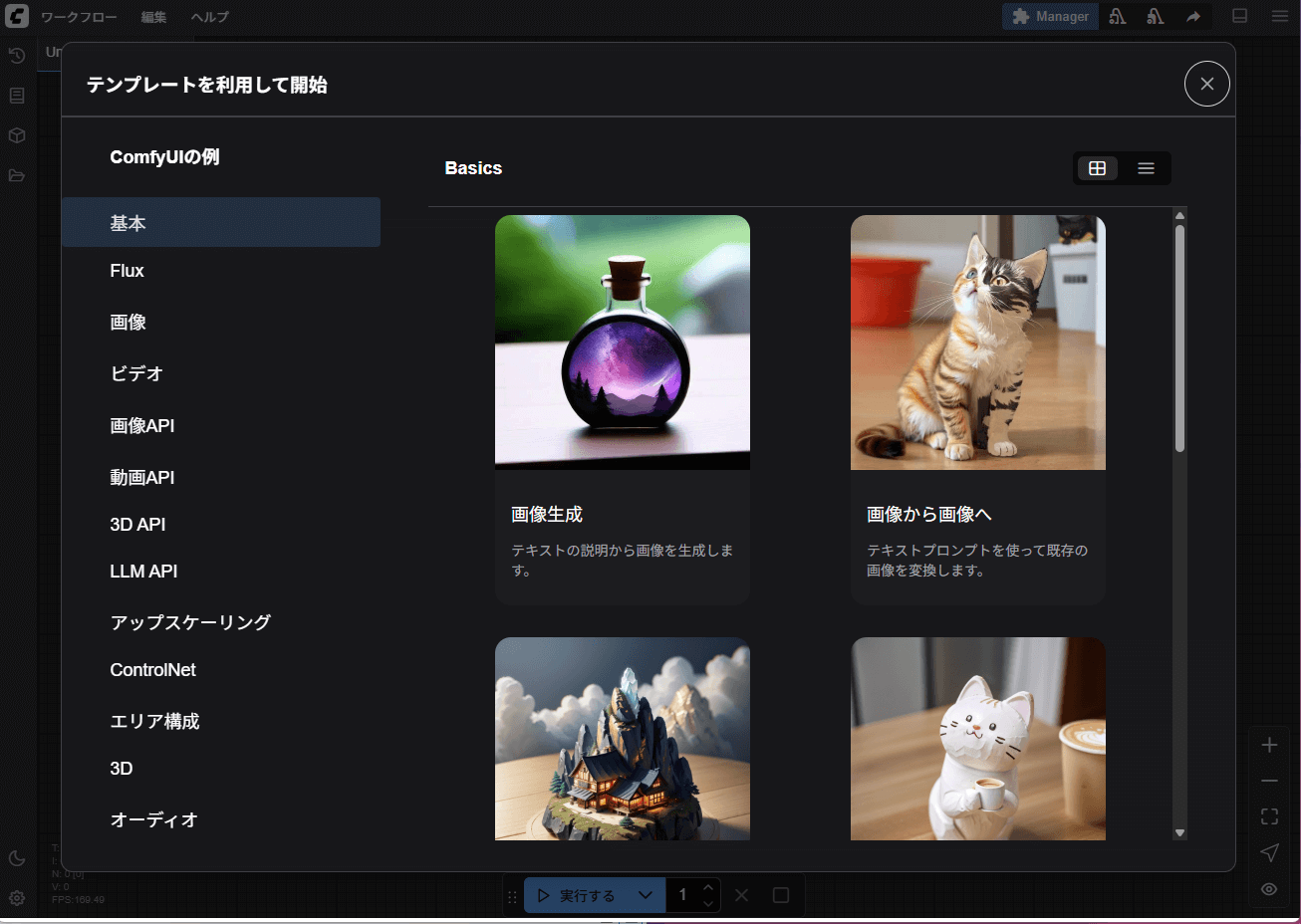
ComfyUIには、あらかじめいくつかのワークフローが用意されており、初心者でも基本的な流れをすぐに体験できるようになっています。チュートリアルとして用意されている「画像生成」のワークフローを使って、ComfyUIの基本的な仕組みを見ていきましょう。
ComfyUIの初期画面から「テンプレートを利用して開始」を選択して生成を開始します。
今回は画像生成(テキスト→画像)のワークフローを選んでみましょう。
2回目以降の起動で何処にあるか分からなくなったら左上の「ワークフロー」→「テンプレートを参照」から同じ画面を開くことが出来ます。
画面に並んでいる四角いブロックは「ノード」と呼ばれ、画像生成の工程を表しています。
ノード同士は線でつながっており、同じ色の線は役割が共通しています。
画像生成(テキスト→画像)のワークフローでは、「チェックポイントを選ぶ」→「プロンプトを入力する」→「生成した画像を保存する」という流れがノードとして組まれており、処理が順番に引き継がれていきます。
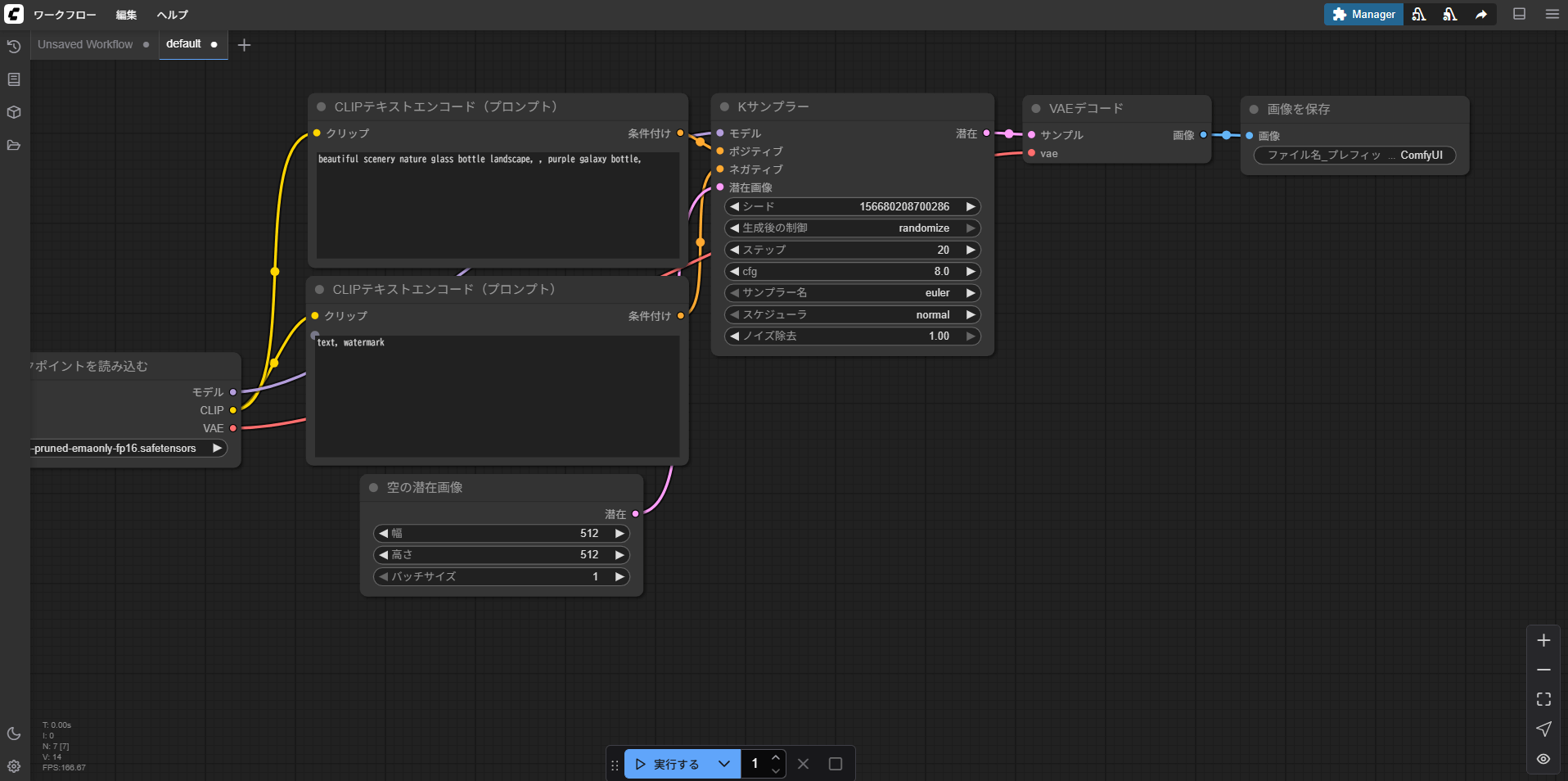
画像の部分で「チェックポイント」を選択します。今回はデフォルトでプリインストールされているチェックポイントを用います。
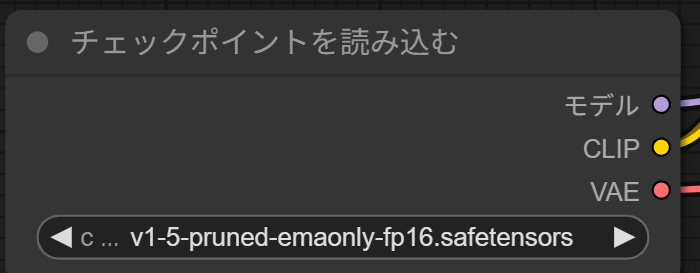
読み込んだテンプレートにはプロンプト入力欄が2段存在します。上にポジティブプロンプト、下にネガティブプロンプトを入力します。
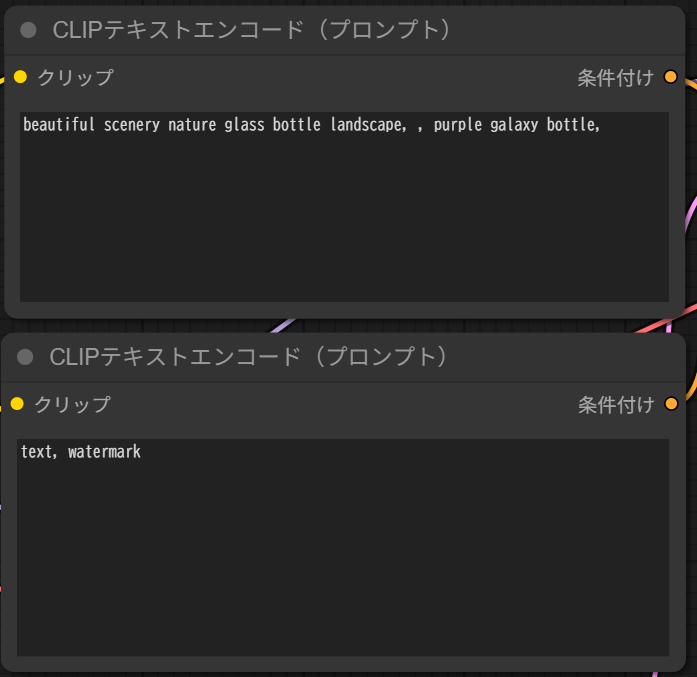
画像のサイズを設定します。ここでバッチサイズもあるため、複数枚生成したい場合はこの値を増やしましょう。
画像生成の中心となるのが「Kサンプラー」ノードです。cfgやステップなどの基本的なパラメータを調整することで生成結果が変化します。
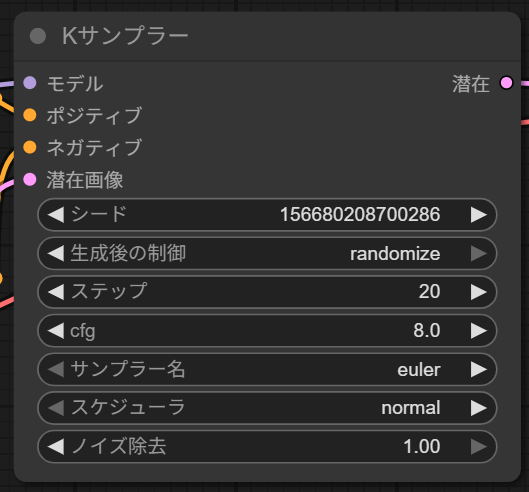
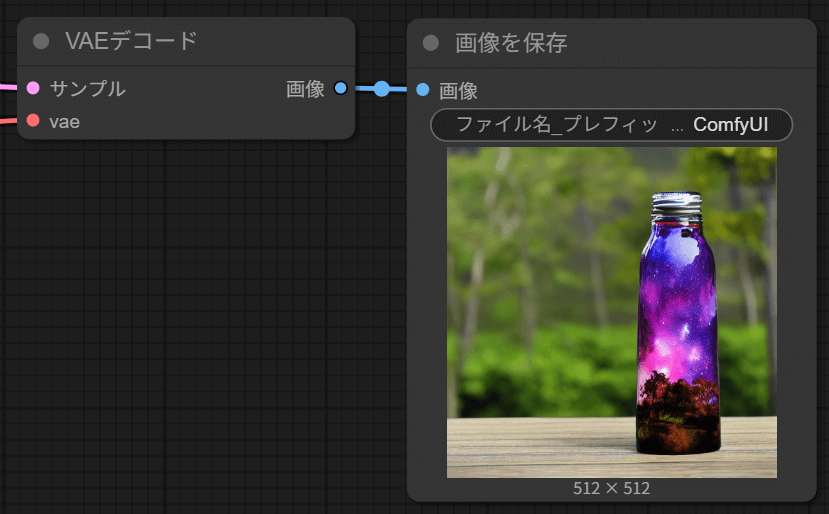
Kサンプラーノードが出力するのは、人間の目で直接見ることはできない形のデータです。これをVAEデコードノードで変換します。
今回はpurple galaxy bottleという指定だったため、このように紫色の宇宙が入った瓶が生成されました。
ComfyUIでの動画生成
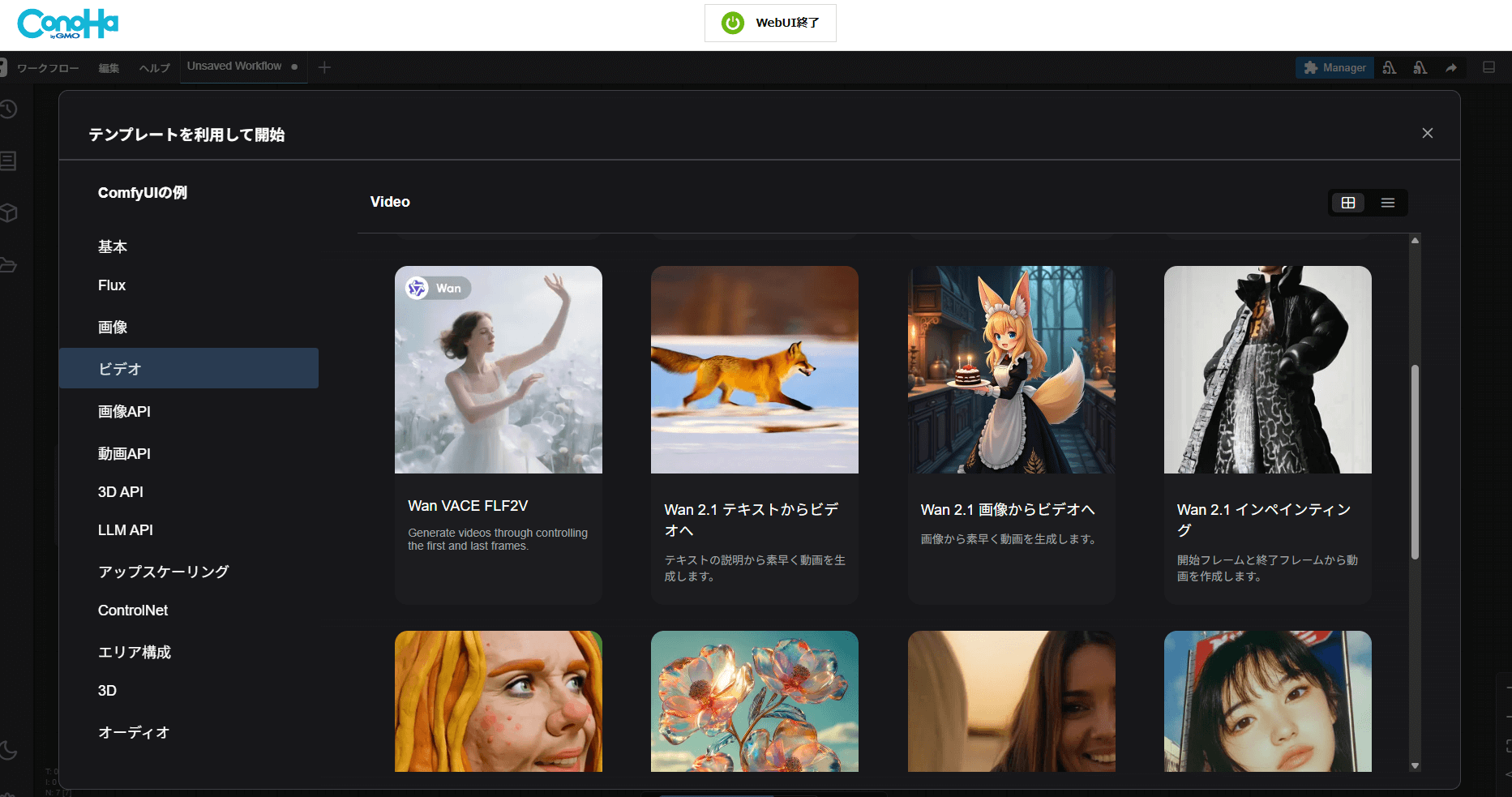
ComfyUIには、静止画だけでなく動画を生成できるワークフローも最初から用意されています。
そのひとつが「Wan2.1」というテンプレートです。特別な設定を自分で組む必要はなく、テンプレートを選んで実行するだけで、簡単にAIによる動画生成を体験できます。ここでは、実際に「Wan2.1」を使って動画を作成する手順を見ていきましょう。
なお、動画生成は静止画に比べて処理時間が長くなるため、ConoHa AI Canvasの無料WebUI時間や従量課金の消費に注意が必要です。
先程は基本のテンプレート内の画像生成を選びましたが、今回はビデオテンプレート内にあるWan2.1のものを選びます。今回はテキストからビデオへを選びます。
今回も画像同様にノードが与えられたワークフローがあります。これを用いて作成します。
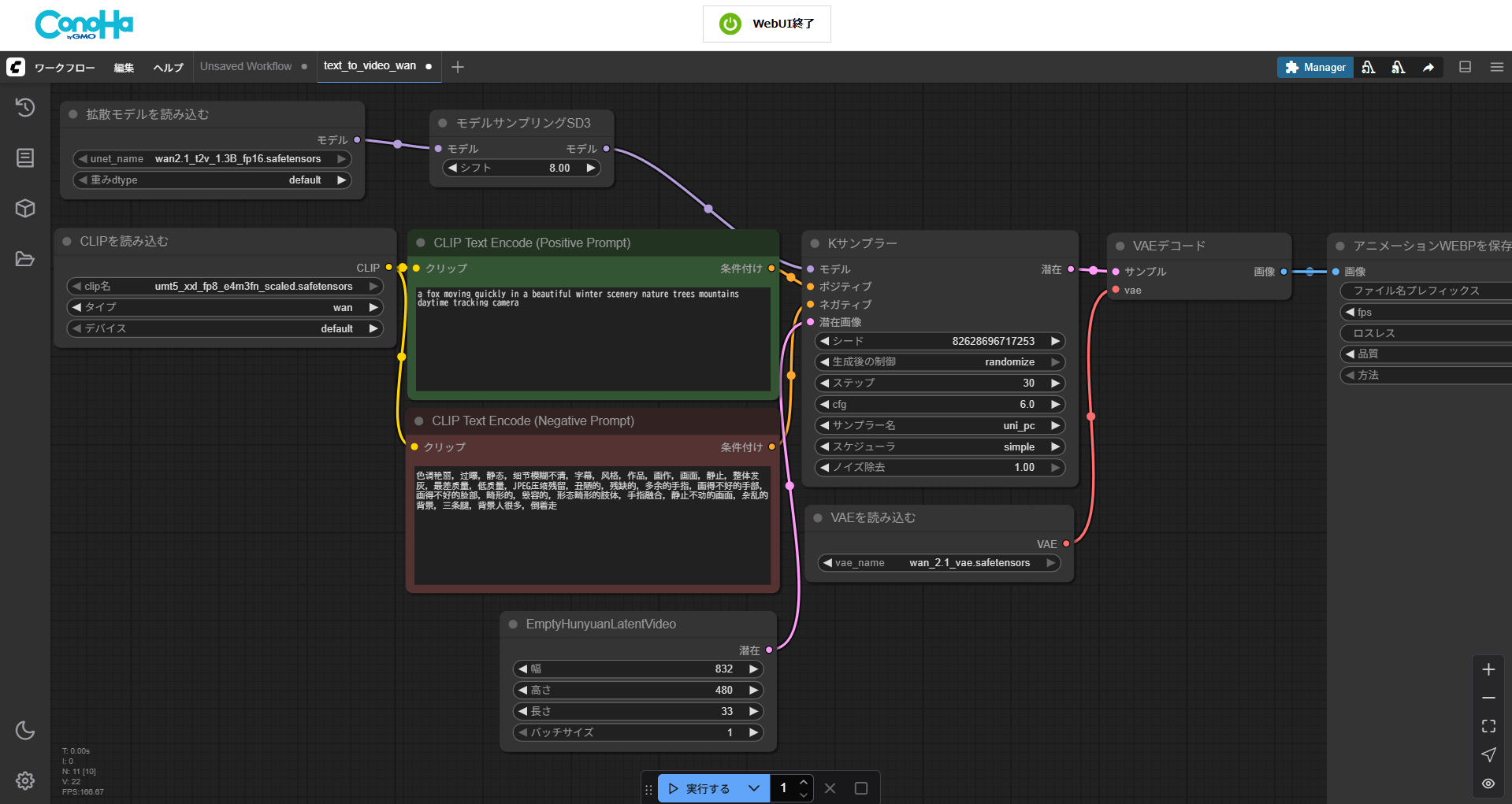
CheckpointとクリップはWan2.1のものとなっています。これは動画を作るためのCheckpointなので、そのまま利用します。
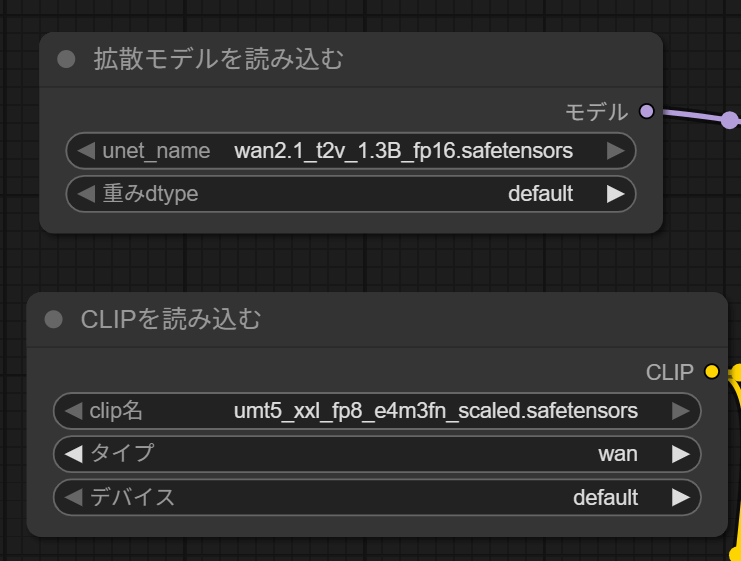
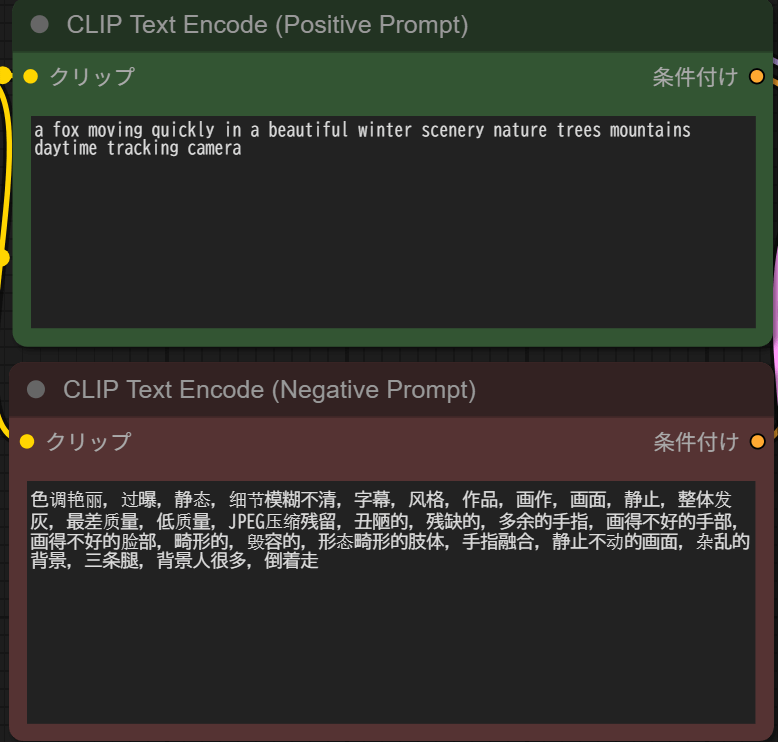
今回読み込んだワークフローでは、ネガティブプロンプトが中国語になっています。内容としては、色彩や画品質、ディテールの崩れ、不自然な構図や物体、背景の雑多さなどが指定されています。
このままでも動作しますが、実際に自分で動画を作成する際は英語で作ったほうが安定するため、必要に応じてネガティブプロンプトも英語に書き換えて利用すると、より意図に沿った結果を得やすくなります。
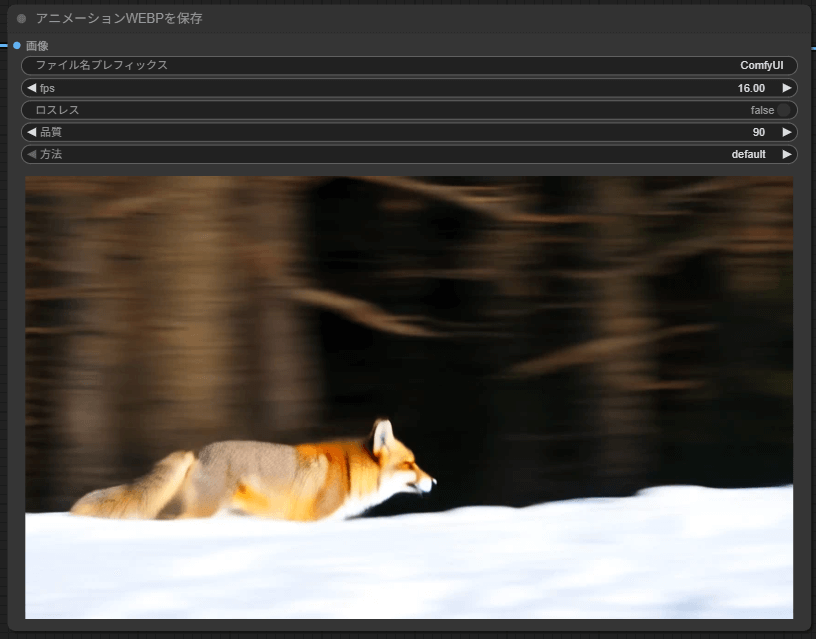
今回のワークフローでは、150秒ほど待つことでプロンプトで指示した動画が作成されました。このように動画を作成する場合は画像より時間がかかるため、注意して利用する必要があります。
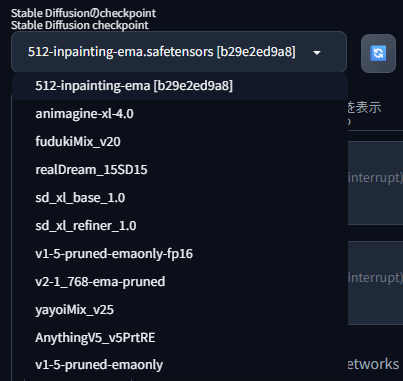
プリインストールCheckpointの使い方
プリインストールCheckpointは、公式では「v1-5-pruned-emaonly」のみですが、実際にはSD1.5やSDXL、ComfyUI側にはFluxモデルなど、様々なモデルが選択できました(2025年8月時点)。おおむね高精細な画像が作れるモデルが多いため、作りたい画像にあったモデルを選択しましょう。
AUTOMATIC1111ではCheckpointを選ぶプルダウンから、ComfyUIでは「チェックポイントを読み込む」の欄から変更できます。(画像にはプリインストール以外のCheckpointも含まれています)
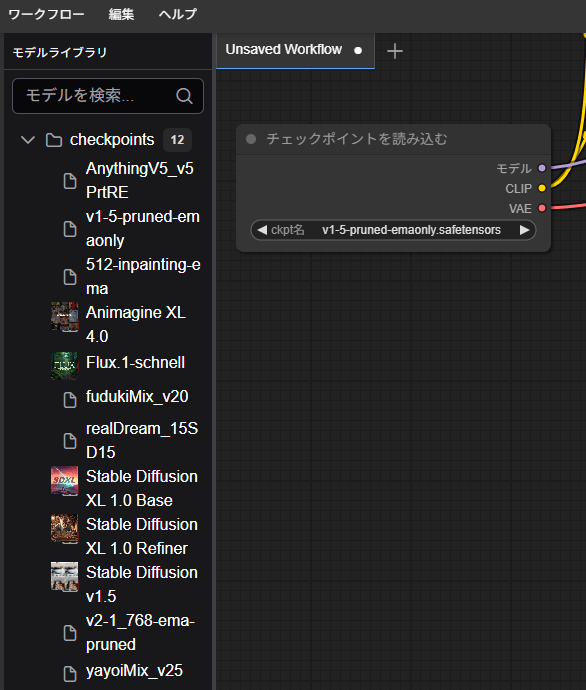
ファイルの追加方法
CheckpointやLoRAなどに、プリインストールされていないファイルを使用する場合は、ファイルマネージャーからアップロードできます。Checkpointは home/data/models/Stable-diffusion に、LoRAは home/data/models/Lora にアップロードしてください。
契約容量の範囲内であれば、ファイルマネージャー上で該当フォルダにファイルをドラッグ&ドロップするだけで、一括アップロードも可能です。詳しくはLoRAの導入手順をご覧ください。
\ MiraLab AIの読者限定で500円割引適用中 /
ConoHa AI CanvasではStable DiffusionのLoRAは使えるのか

LoRA(Low-Rank Adaptation)は、既存のStable Diffusionモデルに後から学習したスタイルやキャラクター特性を追加できる仕組みです。
Checkpoint本体を大きく差し替える必要がなく、軽量なファイルを読み込むだけで表現の幅を広げられるのが特徴です。

ConoHa AI Canvasでは、AUTOMATIC1111とComfyUIの両方で利用可能です。
クラウド上で動作するため、ローカル環境のような複雑な導入作業は不要で、アップロードすればすぐにLoRAを組み込んだ生成が行え、キャラクター表現や画風調整など、生成画像の幅を大きく広げることができます。
LoRAの対応状況(AUTOMATIC1111/ComfyUI)
ConoHa AI Canvasでは、AUTOMATIC1111とComfyUIの両方でLoRAを利用することができます。基本的な扱いはローカル環境と同じで、LoRAファイルを所定のフォルダに配置すればUI上から読み込めるようになります。特別な設定や追加インストールは不要で、標準機能として利用できるのが大きな利点です。
AUTOMATIC1111ではプロンプトにLoRAを指定して使えるほか、ComfyUIではLoRAノードを組み合わせてワークフロー内に組み込むことが可能です。どちらのUIでも一般的なLoRAは問題なく動作し、キャラクター再現やスタイル変更など幅広い用途に活用できます。
LoRAの導入手順
LoRAファイルは、ファイルマネージャーを開いて、home/data/models/Loraに配置します。その後WebUIを再読み込みすることで、LoRAがUI上に反映されます。
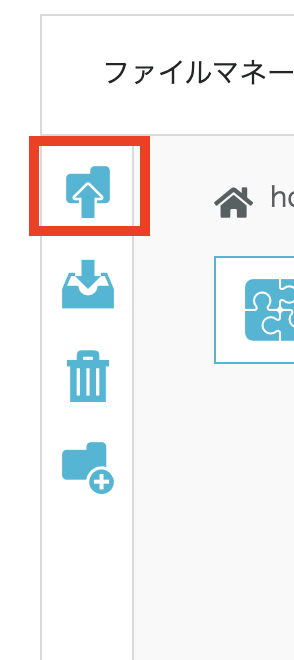
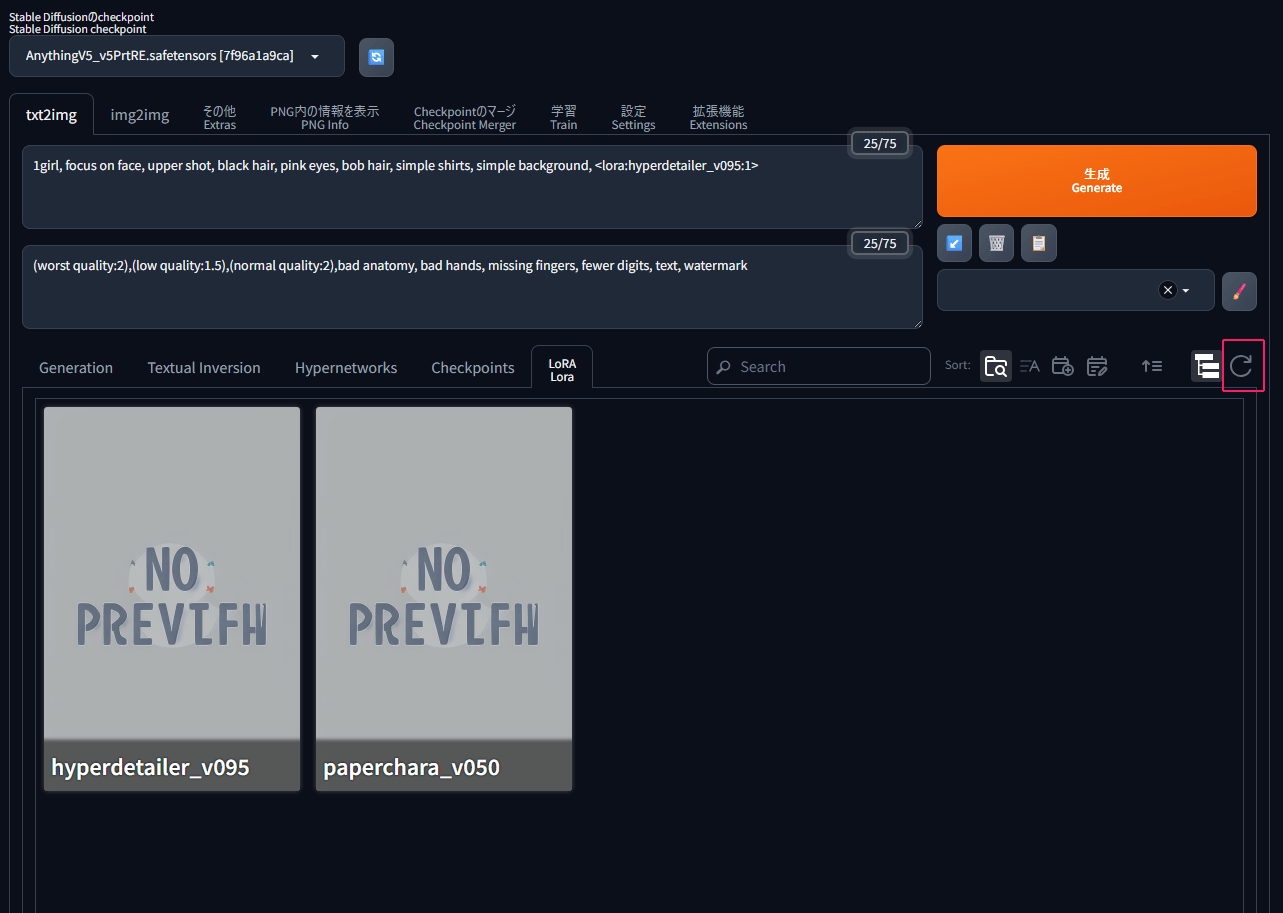
data>models>Loraの順番に進み、画像の赤枠のマークをクリックするとファイルをアップロードできます。
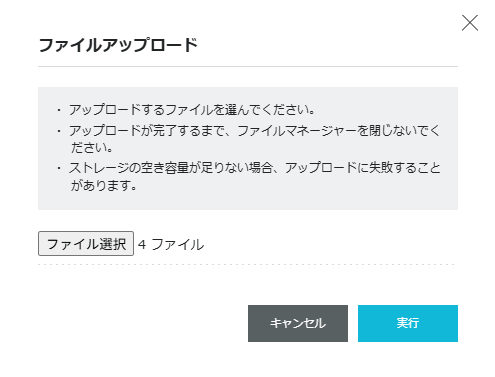
また、アップロードしたいファイルをドラッグアンドドロップすることでもアップロードできます。この際複数ファイルを選択すると、画像のように一括アップロードが出来ます。
LoRAの読み込み方法(AUTOMATIC1111/ComfyUI)
AUTOMATIC1111の場合、現在選択されているCheckpointで使えるLoRAのみ表示される仕組みになっています。
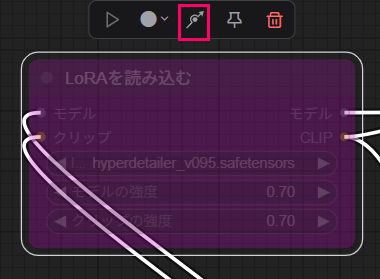
Checkpointを選んだあと、以下の画像のLoRAタブの右端にある赤枠でくくったリロードボタンを押すことで、そのCheckpointで使えるLoRAのみが表示されます。
使用するLoRAをクリックすると、プロンプト内にLoRAが表示され使えるようになります。
LoRAを適用した画像と適用していない画像を比較してみましょう。
ディティールをアップするLoRAを「重み0.7」で適用しました。特に髪のディティールが上がっていることが分かります。

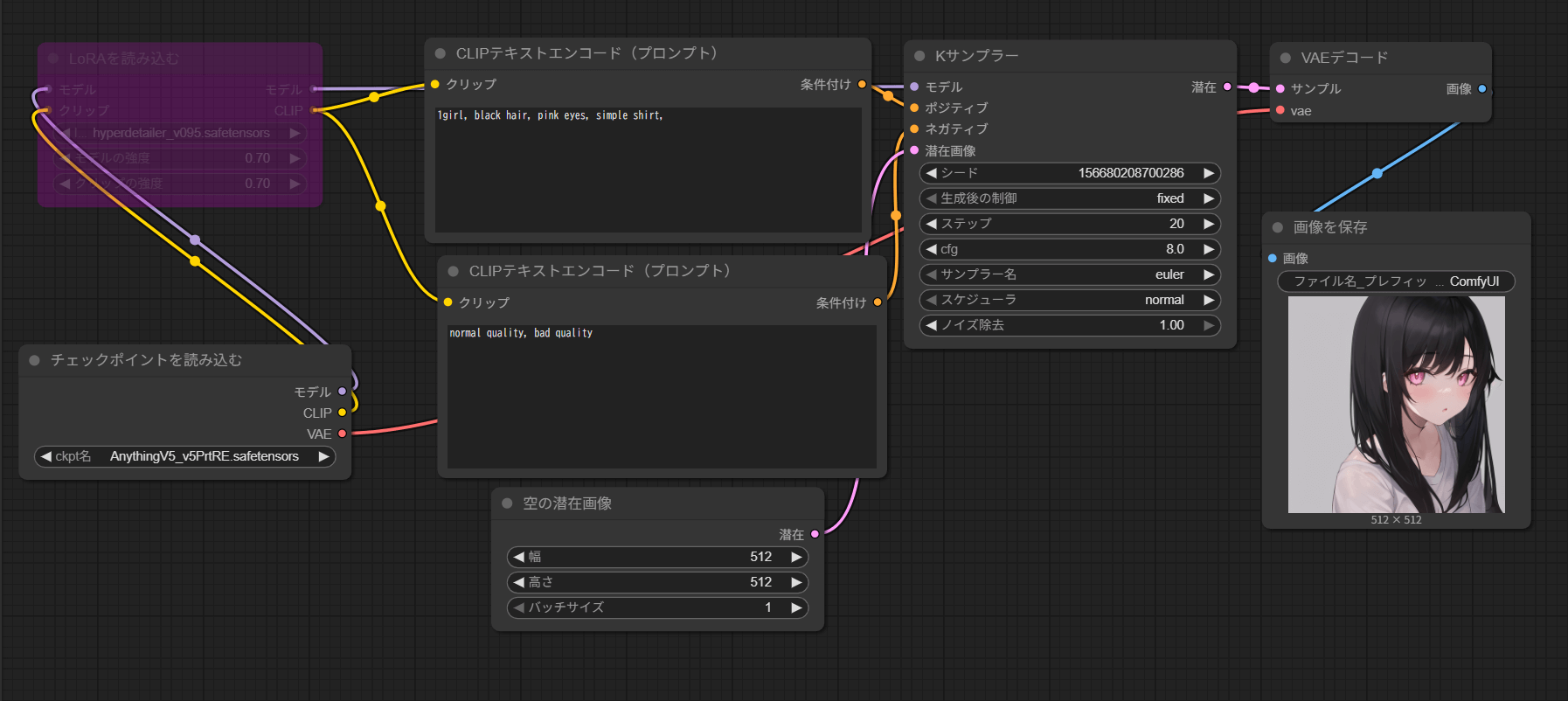
ComfyUIでLoRAをチェックポイントに適用する場合、ノードの接続順に注意する必要があります。
チェックポイントを読み込むノードからLoRAノードを経由させ、その出力をプロンプトノードとKサンプラーノードの両方に接続します。プロンプトノードに繋ぐことでプロンプトに反映され、Kサンプラーノードに繋ぐことでモデル側に反映されるため、この2箇所に正しくLoRAを渡すことが重要です。
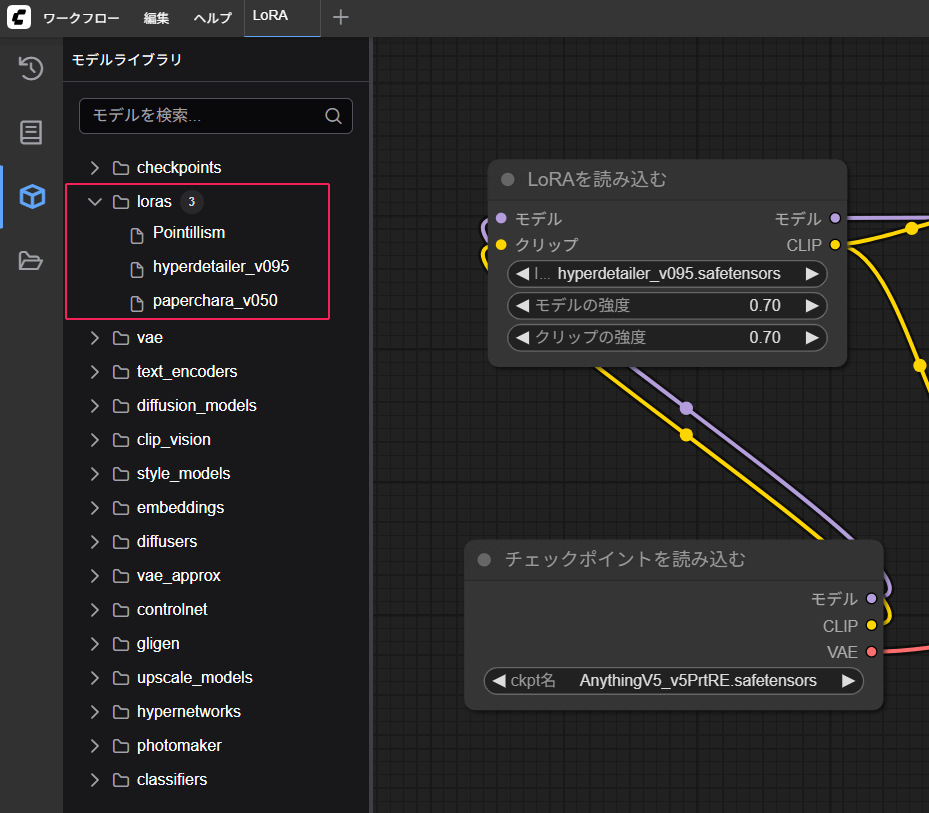
LoRAは左端の箱のようなボタン(水色)を押すとモデルライブラリが出てくるので、その中のlorasフォルダに入っています。AUTOMATIC1111とは違い、すべてのLoRAが表示されます。
これをドラッグアンドドロップで右側のワークフローに置くと、LoRAを読み込むノードが出来ます。AUTOMATIC1111のプロンプト内で設定していたLoRAの強度は、モデルの強度、クリップの強度で設定します。
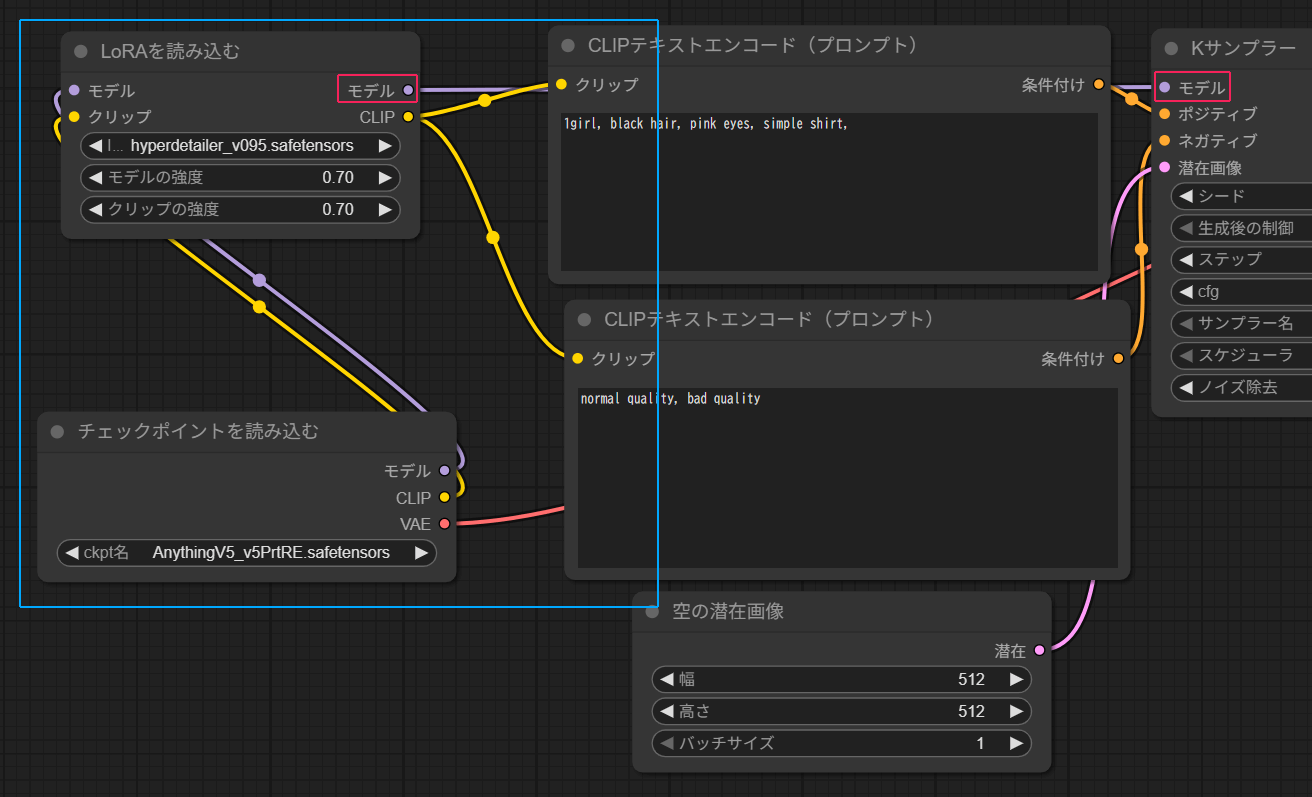
LoRAノードを適用するために、モデルとクリップをつなぎます。
これは「Checkpointとその他のノードの間にLoRAのノードを挟む」と考えると分かりやすいです。
モデルは、チェックポイントを読み込む→LoRAを読み込む→Kサンプラー(最後は見づらいですが赤から赤)とつなぎます。クリップも同様に、チェックポイントを読み込む→LoRAを読み込む→CLIPテキストエンコード(プロンプト)とつなぎます。変更箇所はこの赤部分と水色部分となります。
複数個のLoRAを使いたい場合は、チェックポイントを読み込む→LoRAを読み込む→LoRAを読み込む→それぞれのノード、というように間に挟むことで適用することが可能です。
このワークフローを実行すると、LoRAが適用された画像が生成されます。
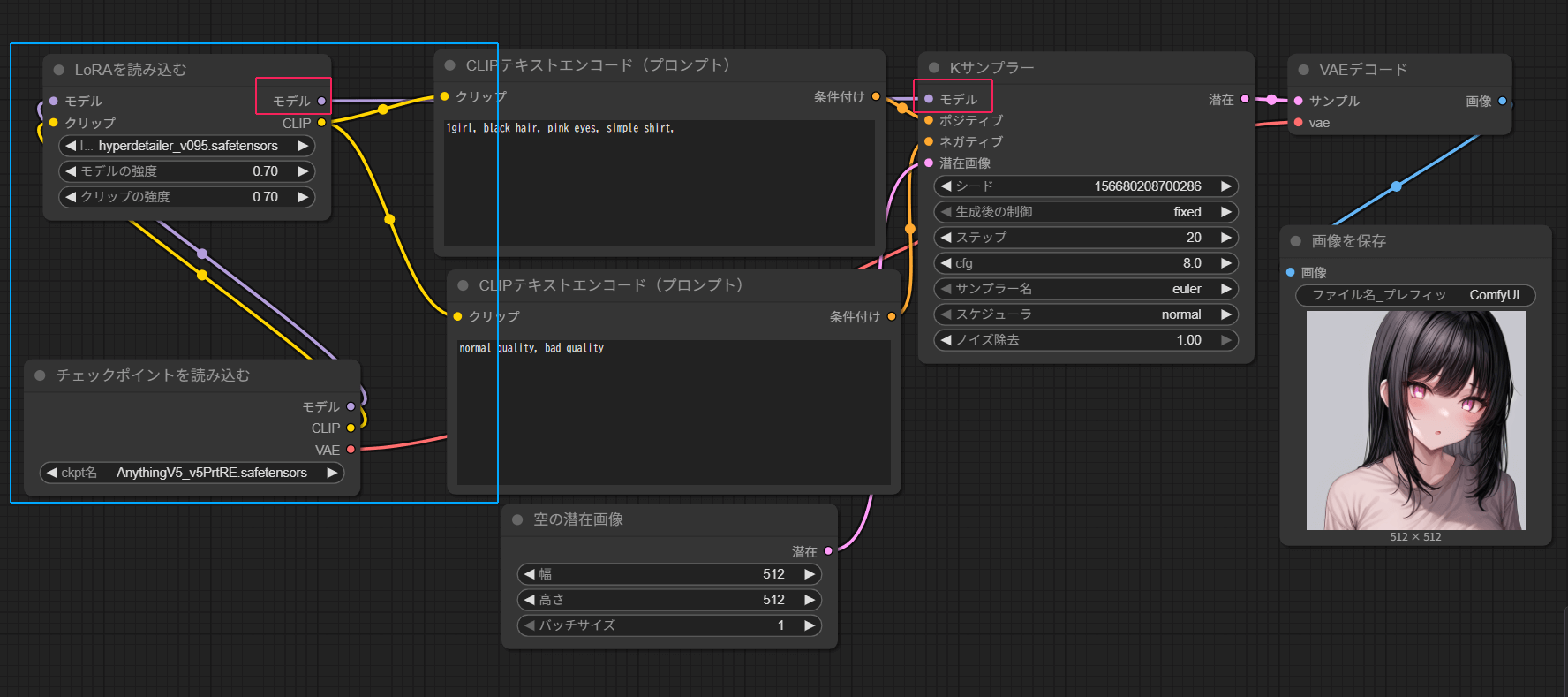
また、ComfyUIでは、LoRAノードをつないだ際でも、LoRAを適用しない画像と比較することが出来ます。
LoRAを読み込むノードの上の矢印ボタン(赤枠)を押して、このように影が掛かった状態でもう一度実行すると、LoRAを適用せずに画像が生成できます。
適用前後の画像を比較します。
ディティールをあげるLoRAを使用したため、ディティールは上がっていますが、少し角度が変わっています。
同じ条件下で生成するためには、プロンプトで細かく指定し揺らぎを少なくしましょう。

LoRA運用のコツ
LoRAを効果的に使うためには、いくつかのポイントを押さえておくと便利です。
AUTOMATIC1111では自動で使えるLoRAは検出されますが、ComfyUIの場合はすべてのLoRAが見えるため、SD15やSDXLなどのファイルの下にLoRAをアップロードすることで、適用バージョンを示しながらLoRAを整理することが出来ます。これらのバージョン違いのLoRAは互換性がないため、ComfyUIを使う際は特に注意しましょう。
重み(Weight) は 0.6~0.8 程度を目安に調整すると安定しやすく、複数のLoRAを組み合わせる際は数値を下げてバランスを取るのがコツです。LoRAの配布サイトに推奨Weightが書いてあることが多いので、それも参考にして画像を生成しながら調整するとうまく使えます。
また、適用した際にエラーや想定外の画像になる場合は、Weightの数字が大きすぎる(小さすぎる場合も絵にほとんど反映されない)、LoRAが競合している、使っているLoRAが適していないなどが考えられます。たとえばSD1.5のLoRAとSDXLのLoRAには互換性がないため、ComfyUIのようにすべてのLoRAが出てきてしまう場合は注意が必要です。
Checkpointとの組み合わせと注意点
LoRAはベースとなるCheckpointとの相性が大きく影響します。ConoHa AI CanvasにプリインストールされていCheckpointには、SDXL系の高精細モデル や 1.5系の安定した実写系モデル が含まれています。そのため、アニメ系LoRAを実写系Checkpointに組み合わせると、効果がうまく反映されず違和感のある画像になってしまうことがあります。
今回はアニメ系LoRAを使ったので、アニメ系Checkpointを入れることで対応しています。
用途に応じて、アニメ調のLoRAを使う場合はアニメ系Checkpointを、リアル調のLoRAを使う場合は実写系Checkpointを選ぶようにすると、より自然な結果が得られます。
\ MiraLab AIの読者限定で500円割引適用中 /
ConoHa AI Canvasのレビュー
実際にエントリープランを契約して利用してみた体験をもとに、使用感をレビューします。
まず操作性については、ブラウザからアクセスするだけで利用でき、UIは日本語に対応しています。AUTOMATIC1111に慣れている人でも違和感なく操作でき、LoRAやCheckpointの追加もファイルマネージャーから簡単に行えるため、導入ハードルは低いと感じます。
生成品質については、標準で用意されているCheckpointだけでも十分に高品質な画像が得られました。ただし、全体的にやや実写寄りの傾向があり、アニメ調の表現を求める人には少し物足りないかもしれません。その場合は、自分でアニメ系のCheckpointを追加することで選択肢を広げ、より好みのテイストに近づけることができます。
料金面では、ConoHa AI Canvasはサブスクリプション契約が前提で、契約時間内で利用できます。短時間やスポット的な利用であればライトユーザーでも無理なく始められます。長時間利用する場合は従量課金で費用が増えることもありますが、利用状況に応じて上位プランに変更すれば効率的にコストを抑えられます。
全体を通して、安定した環境で手軽にStable Diffusionを利用できる点が魅力的です。特にComfyUIに対応したことでCheckpointの選択肢が広がり、ローカル環境では重くなりがちな動画生成までクラウド上で実行できるようになった点は大きな強みだと感じました。初心者から中級者まではもちろん、LoRAやCheckpointを組み合わせれば上級者でも工夫次第で使いこなせるため、幅広い層におすすめできるサービスです。
\ MiraLab AIの読者限定で500円割引適用中 /
まとめ
ConoHa AI Canvasは、ブラウザから手軽にStable Diffusionを利用できるクラウド型AI画像生成サービスです。高性能PCがなくても操作でき、日本語UIやクラウド管理など便利な機能が揃っています。
WebUIはAUTOMATIC1111とComfyUIから選択可能で、用途やスキルに合わせて使い分けられます。特にComfyUIでは動画生成機能もサポートしており、静止画だけでなくアニメーション作成にも挑戦できます。料金はサブスクリプション契約が前提ですが、エントリープランでもライトユーザーには十分な利用時間があり、気軽に試すことができます。
さらにLoRAを使えば、独自スタイルの画像生成を簡単に試すことが可能です。初心者から上級者まで、手軽にカスタマイズや動画制作を楽しめる内容で、AI画像生成を始める入門としてもおすすめです。
\ MiraLab AIの読者限定で500円割引適用中 /