
Anthropicは21日、大規模言語モデルであるClaude 3 Sonnetの内部構造の一部を明らかにした研究論文を発表しました。
Claude の内部には、関連するテキストを読んだり、関連する画像を見たりしたときに活性化する何百万もの概念があります。Anthropic研究者は、この活性化の強さを調整し、Claudeの行動を制御できることを発見しました。
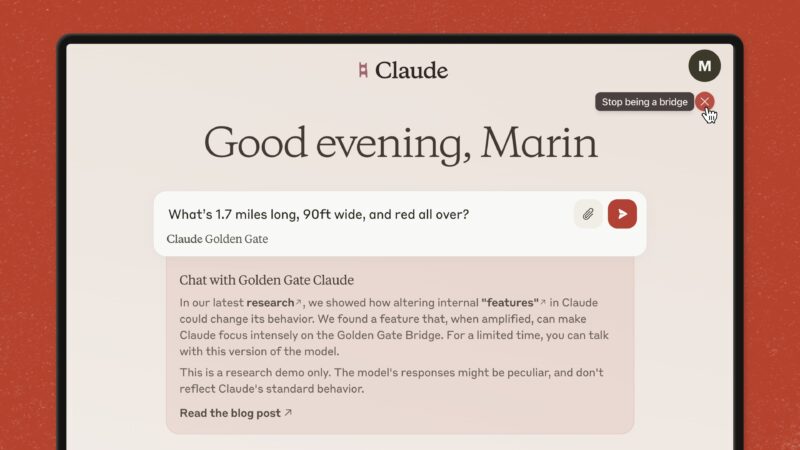
その1つとして、サンフランシスコのランドマークである「Golden Gate Bridge」に関するテキストや画像によって活性化する、特定のニューロンの組み合わせがあります。この機能の強度を上げたところ、関連性のない話題を投げかけてもGolden Gate Bridgeに言及した返答をするようになりました。

これは従来のシステムプロンプトやファインチューニングとは異なる、大規模言語モデルを微調整するための新たな手法で、同技術は生成AIのセキュリティ強化にも活用できるとしています。
Anthropicでは「Golden Gate Bridge」に関する機能を上げたモデルを「Golden Gate Claude」と命名し、期間限定で公開しています。
従来ではAIの判断プロセスや特定の出力の背景は”ブラックボックス”であることが前提でした。今後は特定のタスクにおいて、より効果的にAIの振る舞いや応答を制御できるようになるかもしれません。