

Googleは4月15日、テキスト読み上げモデル「Gemini 3.1 Flash TTS」を発表しました。表現力や制御性、音声品質を高めた最新モデルで、AIを使った音声アプリケーションの開発基盤として展開します。開発者向けにはGemini APIとGoogle AI Studioでプレビュー提供を始め、企業向けにはVertex AI、Workspaceユーザー向けにはGoogle Vidsを通じて順次提供します。
今回のモデルで大きな特徴となるのが、「audio tags(音声タグ)」の導入です。テキストの中に自然言語で指示を書き込むことで、声質や話す速さ、抑揚、感情の込め方などを細かく調整できます。従来の読み上げモデルよりも演出の自由度が高く、用途に応じた音声表現を作り込みやすくなりました。
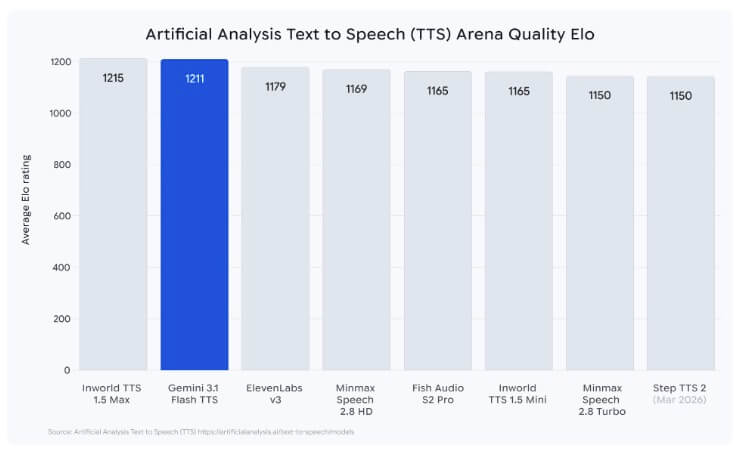
Googleによると、Gemini 3.1 Flash TTSは同社の中で最も自然で表現豊かな音声モデルです。音声品質の評価では、Artificial AnalysisのTTSリーダーボードでEloスコア1211を記録しました。
同社はこのモデルについて、高品質な音声生成と低コストを両立する領域に位置付けています。加えて、70言語超に対応し、複数話者による対話をネイティブで扱える点も特徴です。
Google AI Studioでは、音声タグに加えて、開発者が演出を設計しやすくする機能も用意しました。場面設定や会話指示を与えて登場人物の一貫性を保つ「Scene direction」、話者ごとに話速や口調、アクセントを調整する「Speaker-level specificity」、設定内容をGemini APIのコードとして書き出せる「Seamless export」などに対応します。これにより、単なる読み上げにとどまらず、キャラクター性を持つ対話や没入感のある音声体験の構築がしやすくなるでしょう。
Googleは、初期の開発者や企業テスターから、制御性と表現力の高さに関する評価が寄せられていると説明しています。音声AIの活用が広がる中で、Gemini 3.1 Flash TTSは自然言語による細かな音声演出を可能にするモデルとして、音声UIや多言語対応サービスの開発を後押ししそうです。