

ELYZA-LLM-Diffusionとは、日本語処理に特化した拡散言語モデル(Diffusion LLM)です。自己回帰(AR)モデルとは文章の生成方法が異なり、一部修正や推敲に強みがあります。
本記事では拡散言語モデルの基本から主要パラメータ「steps」の解説、得意・不得意なタスク等を紹介します。デモやデプロイなど、ELYZA-LLM-Diffusionの使い方、料金の考え方についても解説します。
ELYZA-LLM-Diffusionとは|日本語特化の拡散言語モデル

ELYZA-LLM-Diffusionは日本語処理に特化して学習された拡散言語モデル(Diffusion LLM)です。文章の生成・要約などで一般的に使われている自己回帰モデル(ARモデル)とは文章の生成方法が異なり、推論回数を制御しやすい等のメリットがあります。
拡散言語モデルの特徴と自己回帰型モデルとの違いを整理したうえで、ELYZA-LLM-Diffusionの概要や重要な要素であるstepsの考え方について紹介します。
拡散言語モデル(Diffusion LLM)の特徴
拡散言語モデル(Diffusion LLM)は、不完全な文章の修正を繰り返して文章を完成させる文章生成の手法です。文章を左から右へと、逐次的に生成する自己回帰モデルが現在主流となっていますが、自己回帰モデルとは文章の生成方法が根本的に異なります。
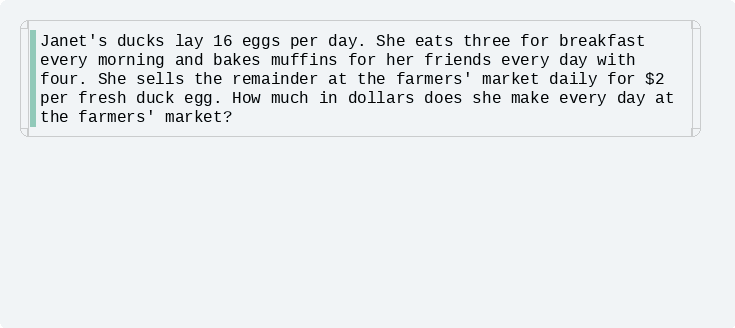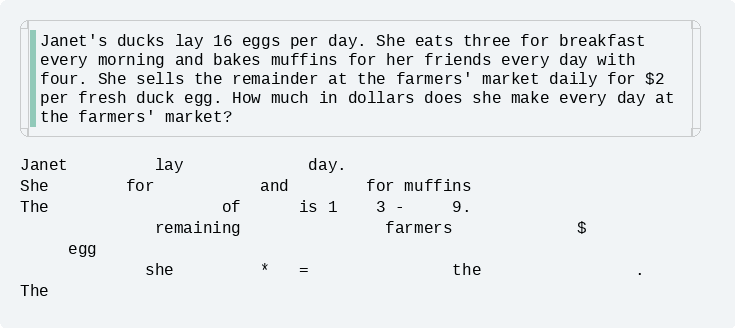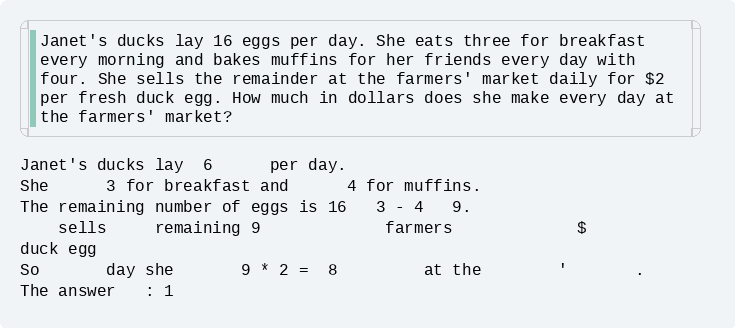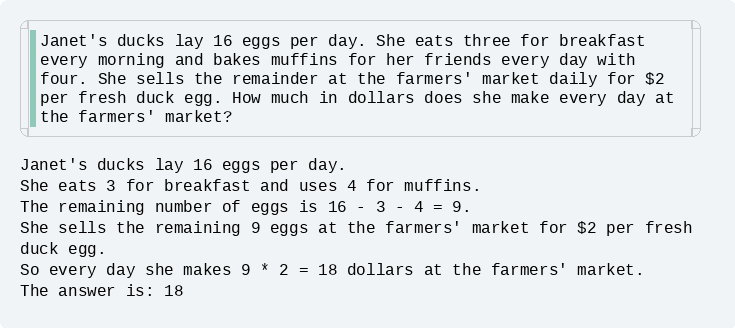
拡散言語モデルは、もともと画像生成で使われていた拡散モデルの考え方を文章に適用した考え方です。拡散言語モデルでは文章が[MASK]で埋まった状態(=仮の文字が配置された状態)からスタートし、その初期の文章を段階的に整形して、ノイズ除去します。
文章全体を徐々に修正していくというプロセスのため、拡散言語モデルでは生成途中でも文章全体が把握しやすいという性質があります。そのため、局所的な表現修正や文体の統一、構文の整合性確保といった編集・推敲などのタスクと相性が良いです。
拡散言語モデルで文章生成の反復回数を「steps」と呼びます。1stepごとにモデルが現在の文章を参照し、複数箇所をまとめて更新します。拡散言語モデルではこのstepsを調整することで、文章生成の速度と品質のバランスを明示的に制御できる点も特徴です。
- 画像生成AIで主流だった「ノイズから絵を浮かび上がらせる」手法を、文章生成に適用
- 文章全体を俯瞰しながら洗練させていく手法のため、文体の一貫性や局所的な修正に強い
- stepsの調整により、生成速度・品質のトレードオフをコントロールしやすい

【比較表】拡散言語モデルと自己回帰モデルの違い
拡散言語モデルと自己回帰モデルでは文章の生成方法が大きく異なるため、得意なタスクや文章の生成速度などにも違いが生じます。違いを以下の通り整理しました。
| 項目 | 拡散言語モデル | 自己回帰モデル |
|---|---|---|
| 文章の生成 | マスクされた状態から文章を更新して完成させる | 逐次的に文章を生成 |
| 代表的なパラメータ | steps 品質・生成制御性と速度・計算コストのバランスをコントロール | 温度(temperature),Top-p,Top-k 等 生成するトークンのランダム性をコントロール |
| 文章の部分修正 | 相性がよい | 一般的にプロンプトの設計次第 専用の学習(fill-in-the-middle)をしているモデルも存在 |
| 制約に従った文章生成 | 制約に従わせやすい | 専用の手法を適用することで制御可能 constrained decoding/grammar-constrained decoding等の実装が必要 |
| 長文の生成 | 一貫性の維持、状態遷移の管理などに課題あり | 一般的に安定した長文生成が可能 |
| 速度特性 | stepsにより調整可能 | 出力する文章の長さ(出力トークン)が大きくなるほど時間がかかる |
| 向いているタスク | 文章の要約・部分修正・テンプレートからの生成等 | 長文、会話の展開、ゼロからの文章生成等 |
自己回帰モデルはこれまで生成したトークン(文章)を踏まえて次のトークンを生成します。生成されるトークンは過去のトークンに依存するため、生成される文章には因果関係があります。そのため、文章の意味的にも因果的な関係を維持したまま長文を生成しやすいです。
一方で生成途中で過去の文章を修正したり、部分的に文章を修正するというタスクは苦手です。
ELYZA-LLM-Diffusionの概要
ELYZA-LLM-DiffusionはDream-v0-Instruct-7Bという拡散言語モデルに対し、日本語データで追加事前学習(further pretraining)と指示追従学習(Instruction Tuning)を実施して日本語対応させたモデルです。
ベースとなるDream-v0-Instruct-7Bは、文章を全て [MASK] で埋めた状態から文章を生成する拡散言語モデルです。ただしDream-v0-Instruct-7Bは英語でトレーニングされているため、そのままでは日本語での生成品質が十分ではありません。
ELYZA-LLM-Diffusionでは、Dream-v0-Instruct-7Bを日本語に適応させるため、追加事前学習と指示追従学習を実施しています。
追加事前学習では大規模な日本語コーパスを用いてトレーニングを行います。追加事前学習により、適切な日本語の語彙や助詞、敬語・文体の頻度等、日本語らしい表現に必要な統計的特徴を獲得させます。これにより、単語の選び方や文のつながり方が日本語として自然になり、生成文の安定性も高まります。
指示追従学習では、入力された指示に対する適切な出力を学習させます。チューニングの効果として、「指定されたフォーマットで回答する」「意図を外さずに要点をまとめる」といった、実運用で重要な振る舞いが強化されます。
- 日本語データによる追加事前学習 … 日本語の言語能力の向上
- 指示追従学習 … 与えられた指示に追従する能力の向上
ELYZA-LLM-Diffusionの性能評価
ELYZA-LLM-Diffusionについては、複数のベンチマークで他のモデルと比較した結果が、以下の通り示されています。
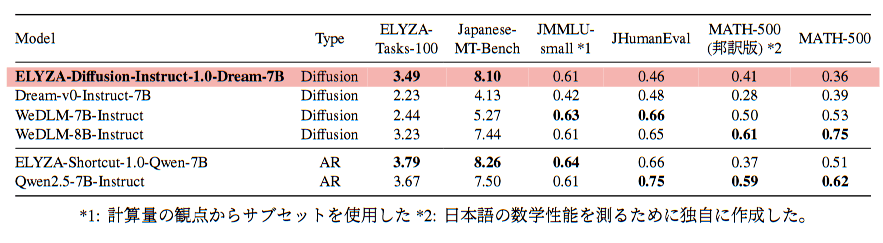
ELYZA-LLM-Diffusionを日本語に適用させる前のDream-v0-Instruct-7B(拡散言語モデル)や、日本語データで指示追従学習を行った自己回帰モデルのELYZA-Shortcut-1.0-Qwen-7B等と比較されています。
公開されている結果では、ELYZA-LLM-Diffusionは、性能評価での指標として対話の質を測る「Japanese-MT-Bench」で非常に高いスコア(8.10)を示しており、日本語の対話・指示への対応に強みがあることが分かります。これは自己回帰モデル(Qwen2.5-7B-Instruct 等)よりも上回っており、拡散言語モデルの中ではトップクラスです。
指示への忠実さを問う「ELYZA-Tasks-100」のスコア(3.49)も拡散言語モデルの中では高い水準ですが、自己回帰モデルよりはやや低く、汎用的な有用性・安定回答では自己回帰モデルに強みがある傾向が見えます。
知識・推論系では、日本語の知識理解や文脈把握の程度を測定する「JMMLU-small」のスコア(0.61)は拡散言語モデルの中では標準的で、自己回帰モデルと大きな差はありません。
日本語でのコード生成能力を測る「JHumanEval」のスコア(0.46)や日本語における数学的な推論力を評価する「MATH-500」のスコア(0.36)では、自己回帰モデルの方が一部高いことが確認できます。
このことから、プログラミングや数学的推論といった厳密性が要求されるタスクにおいて自己回帰モデルの方が得意な傾向にあると判断できます。
- 拡散言語モデルの特性どおり、対話品質や生成制御に強み
- 数理的・アルゴリズム的な正確性が要求されるタスクは自己回帰モデルよりもスコアが低い傾向
ELYZA-LLM-Diffusionが得意なタスクと苦手なタスク
ELYZA-LLM-Diffusionは、目的や形式がある程度決まっているテキスト処理に向いています。
具体的には、業務文書の下書き、要約、言い換え、トーン統一、定型フォーマットへの書き換え等が挙げられます。これらは拡散言語モデルの「反復的に更新しながら文章を完成させる」特性と相性がよいタスクです。
一方でゼロから長編を組み立てる創作や、伏線回収・因果関係の積み上げのように文章の整合性が求められるケースでは活用が難しい傾向にあります。文章全体を同時に更新するプロセスのため、ストーリー展開や論旨の一貫性を保つためには、追加のアプローチ(アウトライン固定、段落ごとの生成、再編集ループなど)も検討すると良いでしょう。
| タスクの種類 | タスクの性質 | タスクの例 |
|---|---|---|
| 向いているタスク | 目的・フォーマットが明確 既存の文章の編集 ルールに従った文章(長さ・トーン・文体等) | 要約、言い換え、トーン統一、議事録への整形、メール文の整形、テンプレートからの生成等 |
| 向いていないタスク | 長期的な整合性が重要 展開を積み上げる 厳密な論理性が求められる | 長編小説、複雑なプロット生成、数学証明、コード生成等 |
ELYZA-LLM-Diffusionの使い方|デモから公開モデルのデプロイまで

ELYZA-LLM-Diffusionを使うためには、文章生成を簡単に試せるデモ環境を利用するか、自分で用意した実行環境に公開モデルをデプロイする方法があります。
これらの方法について、実際の操作画面を交えた具体的な利用手順を紹介します。
stepsの設計方針|生成品質・速度・生成制御性の関係性
stepsは拡散言語モデルにおける生成の反復回数を示すパラメータで、文章生成の品質・速度・制御性に影響します。
stepsを少なく設定すれば文章を修正する回数が減るため、高速に文章を生成できます。
一方で文章の品質が下がったり、指定した条件からの逸脱が起きやすくなります。stepsを増やすと文体の統一や条件の遵守性は向上しやすいですが、生成には時間がかかります。
| 項目 | stepsが少ない | stepsが多い |
|---|---|---|
| 生成品質 | ||
| 生成速度 | ||
| 生成制御性 | ||
| 計算コスト | ||
| 使い分け | 下書きの作成、検証等 | 最終稿の作成、厳密な編集等 |
注意点として、stepsを増やせば無限に品質が向上するわけではありません。ある段階からは品質の向上幅が頭打ちになり、推論の計算コストだけが増えるケースもあります。業務などで活用する場合には低stepsで下書きを生成、中〜高stepsで最終稿の生成・制約の厳しい文章を生成する等の段階的な運用が考えられます。
stepsの指定によって事前に品質と生成速度・コストを見積もりやすい点は、拡散言語モデルならではの利点です。
【無料で今すぐ試す】ELYZA-LLM-Diffusion公式デモ
環境構築なしでELYZA-LLM-Diffusionを試すための公式のデモが用意されています。デモの利用手順は以下の通りです。
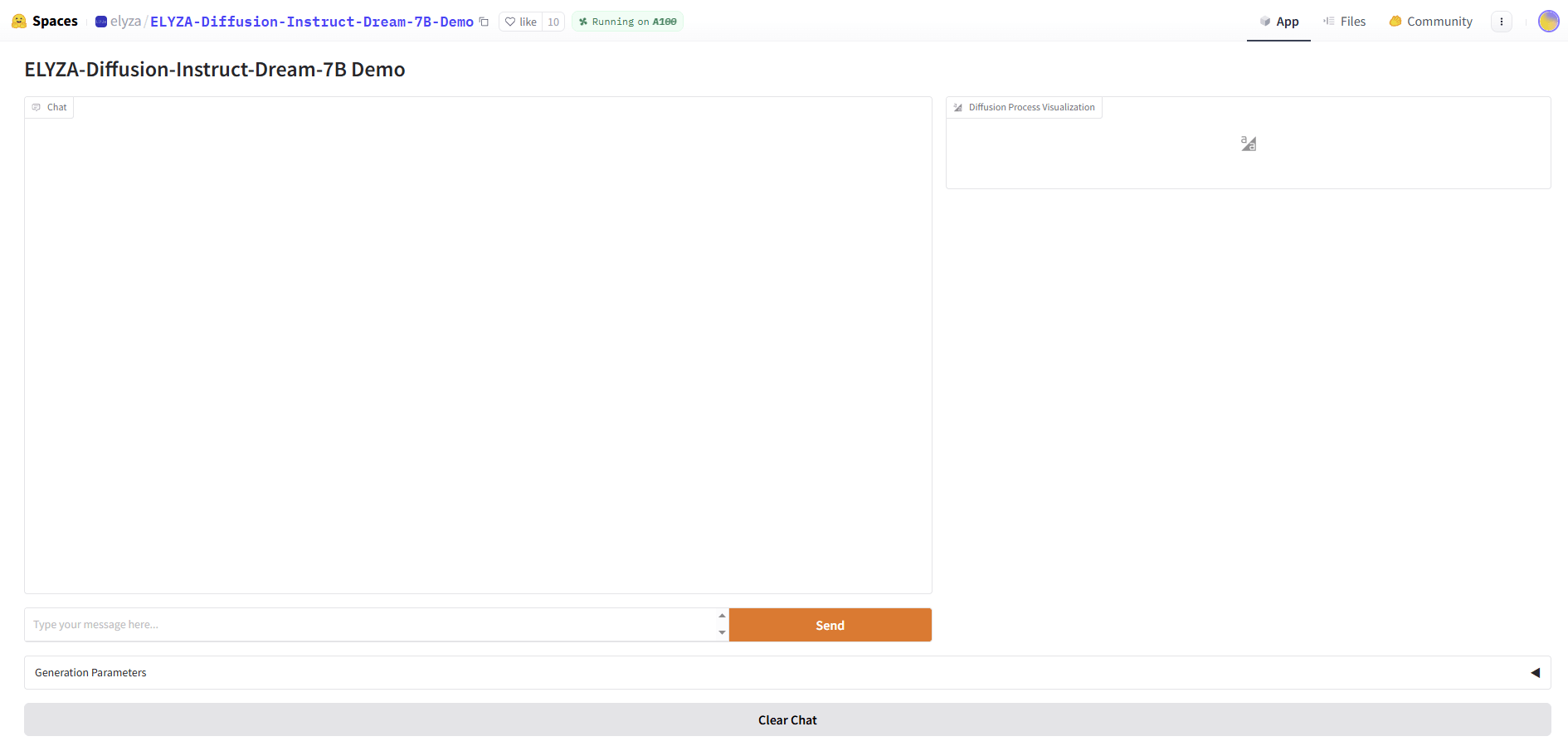
「Generation Parameters」をクリックするとパラメータ設定画面が表示されるので、必要に応じて各パラメータを設定します。詳細については「ELYZA-LLM-Diffusionデモのパラメータ解説」を参照してください。
今回はデフォルトの設定のまま使用しました。
チャット欄にプロンプトを入力し、「Send」ボタンをクリックすると文章生成が開始されます。
今回は「拡散言語モデルについて教えて」というプロンプトを入力しました。
文章の生成過程は画面右側でリアルタイムに表示されます。最終的に生成された文章は画面左側のチャット欄に表示されます。
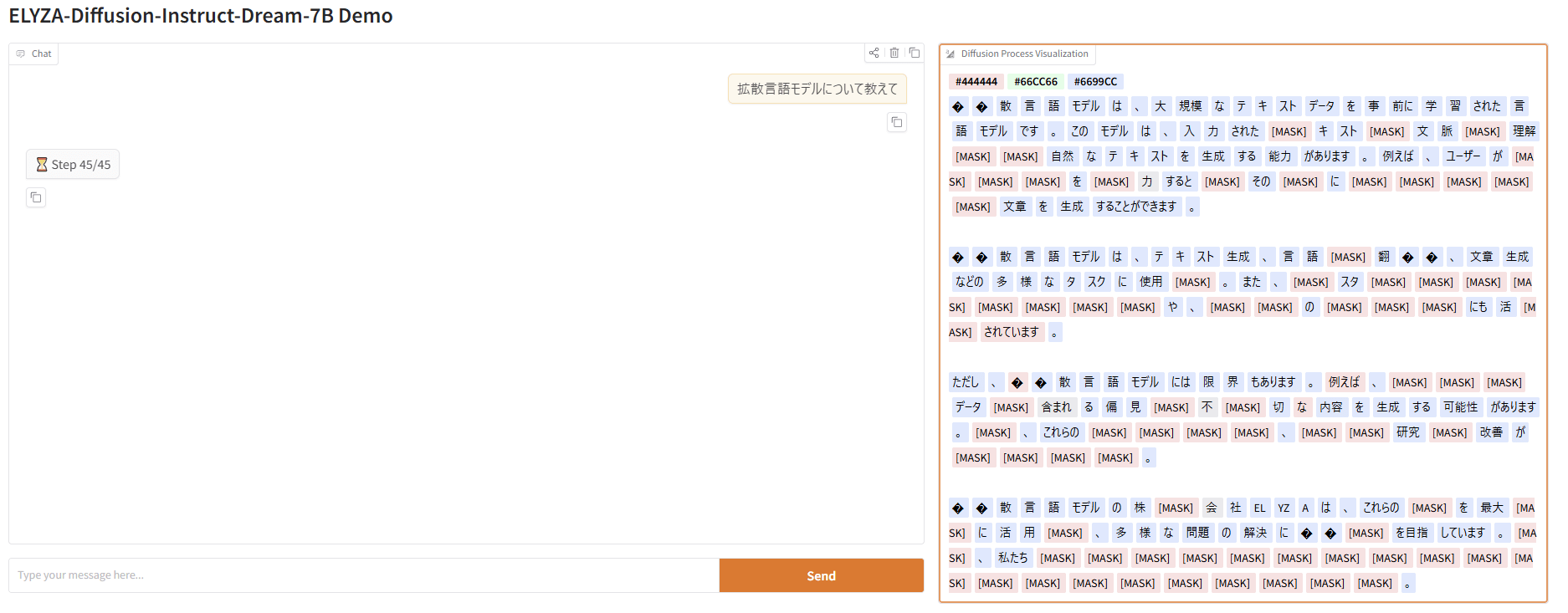
生成過程の表示では一部文字化けしていますが、最終的な出力はチャット欄で適切に表示されます。
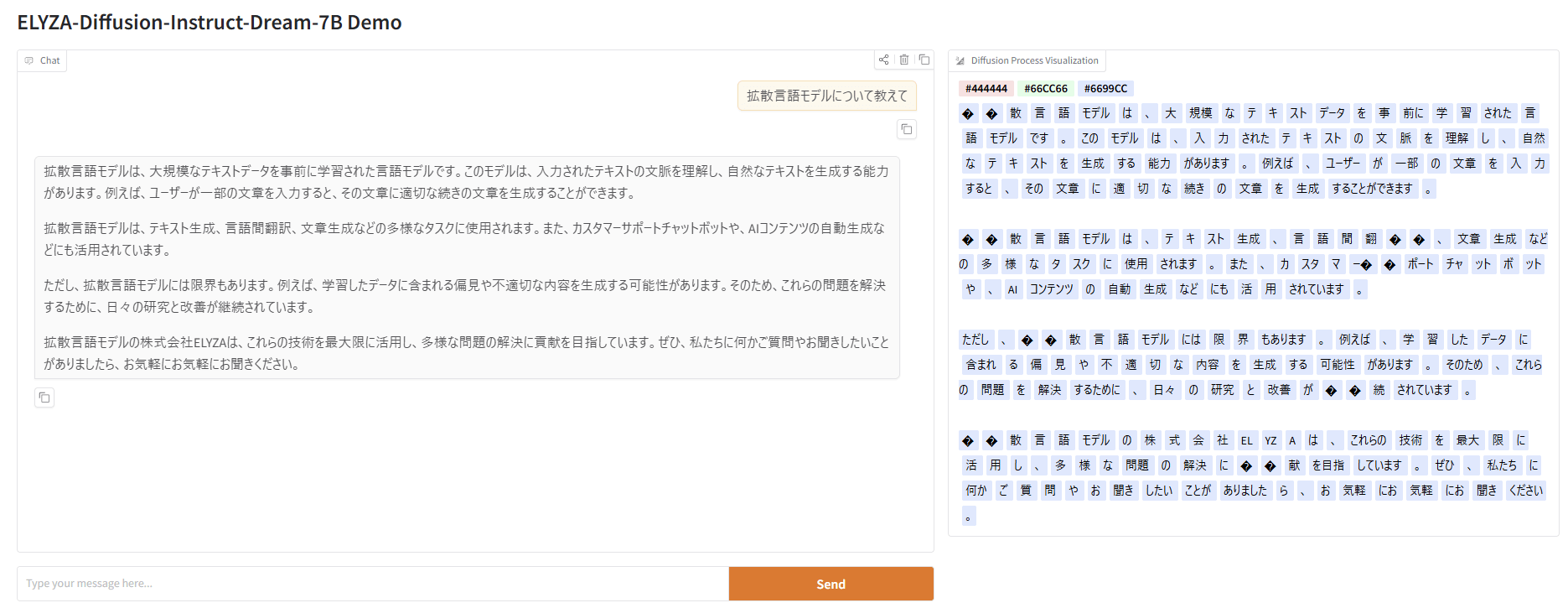
以上の手順で、プロンプトを入力するだけで簡単に拡散言語モデルによる文章生成の検証が可能です。
ELYZA-LLM-Diffusionデモのパラメータ解説
公式デモでは、拡散言語モデルの主要なパラメータを変更可能です。各パラメータの概要と考慮事項は以下の通りです。
| パラメータ | 設定値 | 概要 | 考慮事項 |
|---|---|---|---|
| Max New Tokens | 16~512 | 生成される文章の最大トークン数 | 長くすると長文を生成できるが、計算量が増加 |
| Diffusion Steps | 8~512 | 文章を反復的に修正する回数 | 低いほど高速だが品質は下がりやすい 高いほど品質は向上しやすいが時間や計算コストがかかる |
| Temperature | 0~1 | トークン選択のランダム性 | 低いほど生成されるトークンが安定し、高いほど多様なトークンが選択される 業務用途では低〜中が扱いやすい |
| Top-p | 0~1 | トークン候補の制限 | Temperatureと併用 高すぎると表現が不安定、低すぎると表現が単調になる |
| Top-k | 0~100 | 候補トークン数の固定制限 | 低すぎると表現が単調、高すぎると表現の逸脱やブレが増える Top-pと似たパラメータのため、Top-p利用時は0 (無効)とするケースもある |
| Visualization Delay (sec) | 0~0.5 | 文章生成の可視化速度(表示用) | 文章の生成には影響なし |
| Algorithm | origin/ar | 文章生成のアルゴリズム | origin:各stepで現在の[MASK]を修正し、確率に基づいてトークンを更新 ar:自己回帰モデル風にトークンを左から右へ生成する |
| Algorithm Temperature | 0~1 | 拡散アルゴリズム内部のランダム性 | 高すぎると推敲が不安定となる |
拡散言語モデルの生成品質に大きな影響を与えるパラメータは「Diffusion Steps」ですが、stepsを大きくしても期待する品質が得られない場合は「Temperature」や「Top-p」、「Top-k」等の他のパラメータも調整してみましょう。
公開モデルをHugging Face Spacesにデプロイする
ELYZA-LLM-DiffusionはHugging Faceで公開されているため、任意の実行環境にデプロイ可能です。
今回はチャットUIを使ってELYZA-LLM-Diffusionによる推論を行うアプリケーションをHugging Face Spacesに無料でデプロイする手順を紹介します。Hugging Face Spacesはローカル環境を用意せずに、Web上でモデルのデモや簡易アプリを公開・実行できるサービスです。
Hugging Face Spacesにアプリケーションをデプロイするために、以下の3ファイルが必要です。あらかじめローカル環境でファイルを作成してください。
- README.md
-
Spaceの基本設定ファイルです。デプロイするアプリケーションについて、Pythonバージョン、ソースコードファイル名 (
app.py)、Spaceのタイトルや表示情報等を定義します。--- title: ELYZA Diffusion LLM CPU Demo emoji: 🧠 colorFrom: gray colorTo: blue sdk: gradio python_version: "3.10" app_file: app.py pinned: false --- # ELYZA Diffusion LLM (CPU) CPU-only Space demo for ELYZA Diffusion LLM. - requirements.txt
-
Python依存関係を定義します。
gradio transformers accelerate torch bitsandbytes - app.py
-
アプリケーションのソースコードです。GradioでUIを定義し、ELYZA Diffusion LLMのロード・文章生成のリクエスト等を実装しています。今回は無料枠の計算資源で実行するため、計算負荷を下げる目的で
BitsAndBytesConfig()によってモデルの量子化を行っています。import os import torch import gradio as gr from transformers import AutoModel, AutoTokenizer, BitsAndBytesConfig #ロードするモデルの指定 MODEL_ID = os.getenv("MODEL_ID", "elyza/ELYZA-Diffusion-Instruct-1.0-Dream-7B") DEVICE = "cpu" #4bitで量子化 bnb_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16, bnb_4bit_quant_type="nf4", bnb_4bit_use_double_quant=True, ) print(f"Starting CPU quant Space: DEVICE={DEVICE}, MODEL_ID={MODEL_ID}") model = AutoModel.from_pretrained( MODEL_ID, quantization_config=bnb_config, device_map={"": DEVICE}, trust_remote_code=True, ).eval() tokenizer = AutoTokenizer.from_pretrained(MODEL_ID, trust_remote_code=True) @torch.no_grad() def generate(prompt, steps, max_new_tokens, temperature, top_p, alg_temp): prompt = (prompt or "").strip() if not prompt: return "プロンプトを入力してください。" steps = int(max(4, min(int(steps), 64))) max_new_tokens = int(max(16, min(int(max_new_tokens), 128))) messages = [{"role": "user", "content": prompt}] inputs = tokenizer.apply_chat_template( messages, return_tensors="pt", return_dict=True, add_generation_prompt=True, ) input_ids = inputs.input_ids.to(DEVICE) attention_mask = inputs.attention_mask.to(DEVICE) out = model.diffusion_generate( input_ids, attention_mask=attention_mask, steps=steps, max_new_tokens=max_new_tokens, temperature=float(temperature), top_p=float(top_p), alg="entropy", alg_temp=float(alg_temp), ) return tokenizer.decode(out.sequences[0][input_ids.size(1):], skip_special_tokens=True) with gr.Blocks() as demo: gr.Markdown("## ELYZA Diffusion LLM (CPU 4bit quant)") prompt = gr.Textbox(label="Prompt", lines=6, value="拡散言語モデルについて教えて") with gr.Row(): steps = gr.Slider(4, 64, value=16, step=1, label="steps") max_new_tokens = gr.Slider(16, 128, value=96, step=1, label="max_new_tokens") with gr.Row(): temperature = gr.Slider(0.1, 1.5, value=0.8, step=0.05, label="temperature") top_p = gr.Slider(0.1, 1.0, value=0.95, step=0.01, label="top_p") alg_temp = gr.Slider(0.1, 1.5, value=0.8, step=0.05, label="alg_temp") run = gr.Button("Generate") out = gr.Textbox(label="Output", lines=14) run.click(generate, [prompt, steps, max_new_tokens, temperature, top_p, alg_temp], out) demo.queue(max_size=8) if __name__ == "__main__": demo.launch()
必要なファイルを用意したら、以下の手順でHugging Face Spacesにアプリケーションをデプロイします。
画面右上の「Spaces」をクリックし、「+New Space」ボタンをクリックします。
以下に任意の値を入力します。「Select the Space SDK」は「Gradio」を選択してください。
- Space name
- Short description
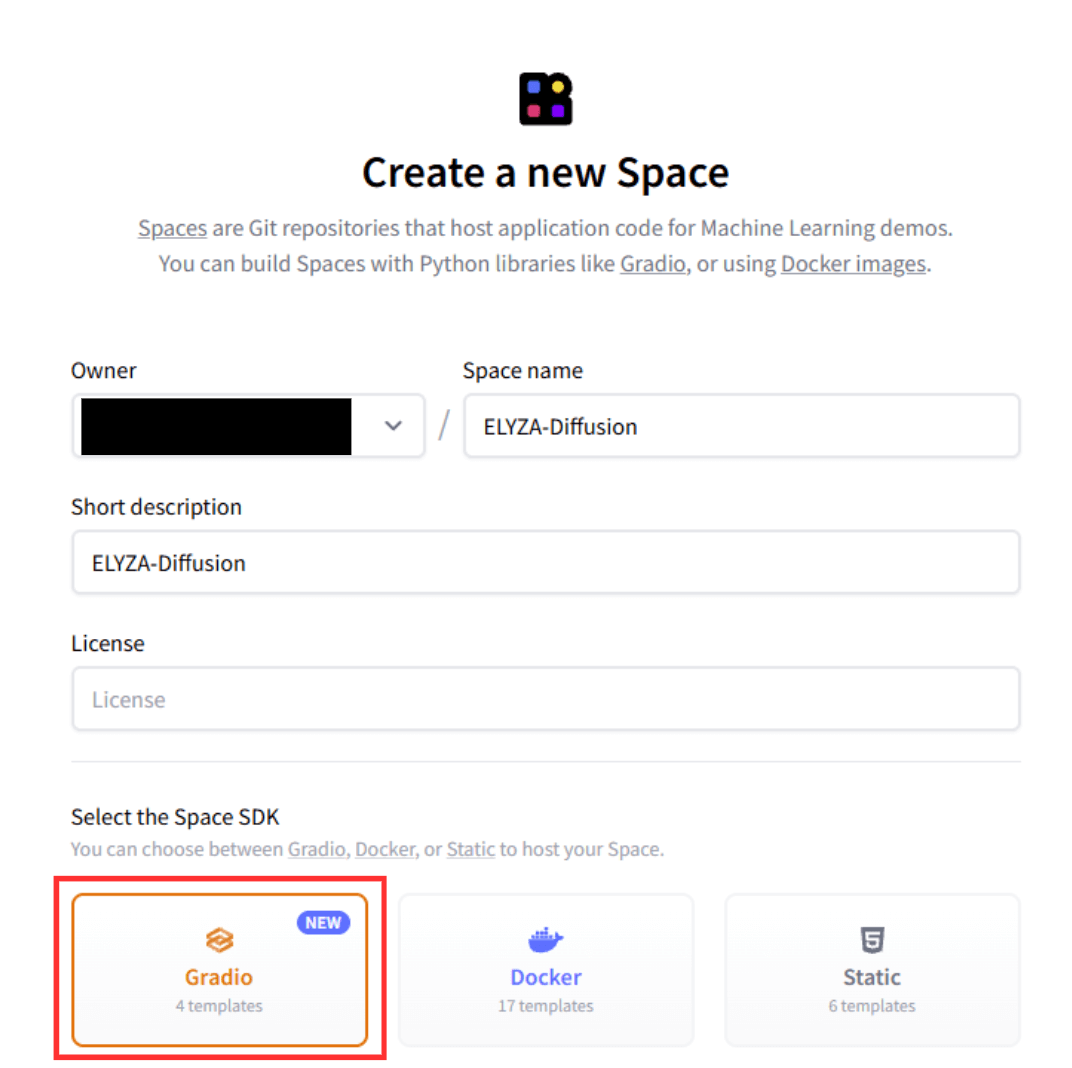
デプロイ方法が以下になっていることを確認し、「Create Space」ボタンをクリックします。
- Space hardware:CPU Basic または ZeroGPU
- Space Dev Mode:Public
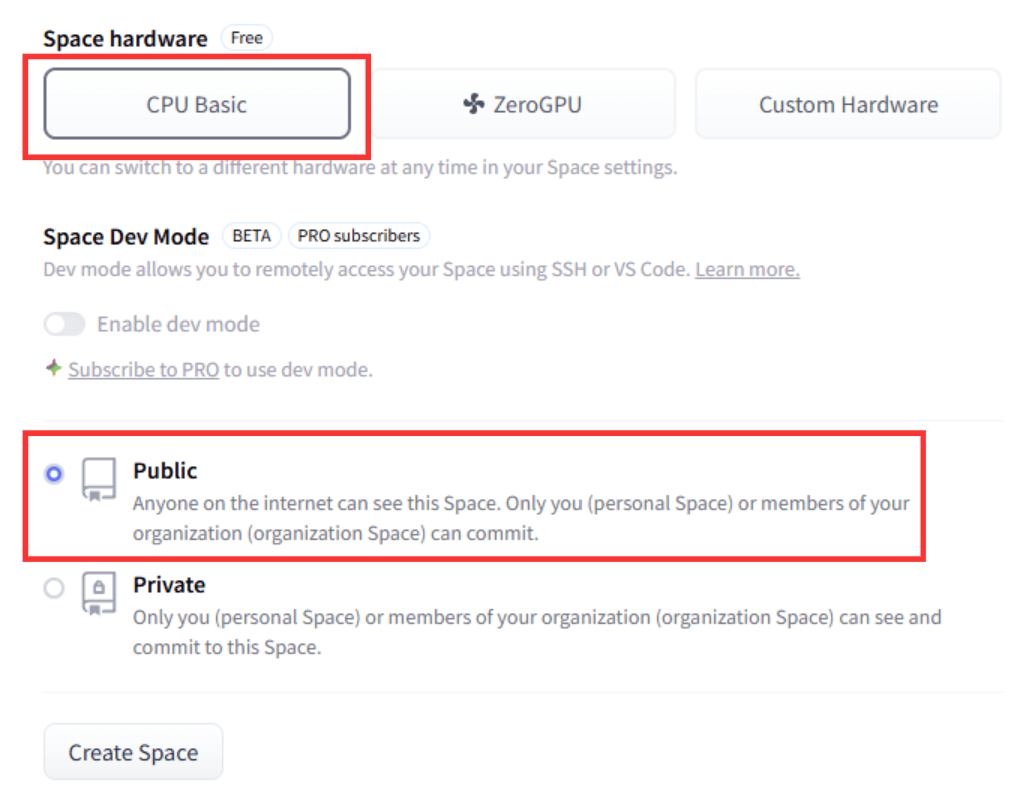
有料プランを購入されている場合はGPUの利用をおすすめします。
Spaceが作成されると以下の画面が表示されるので、画面右上の「Files」をクリックしてファイルのアップロード画面に移動します。
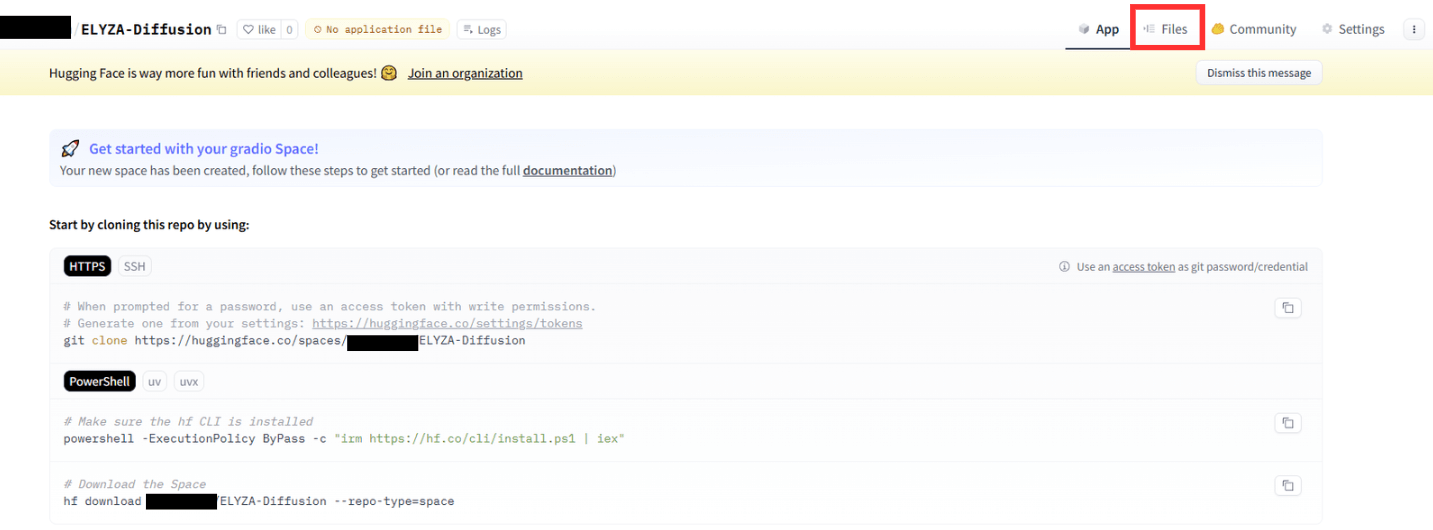
Files画面では、初期からデフォルトで配置されているファイルが2つ表示されます。右上の「+Contribute」ボタンをクリックし、「Upload files」をクリックします。

ドラッグアンドドロップで、事前に作成した3ファイル(app.py, README.md, requirements.txt)をアップロードします。
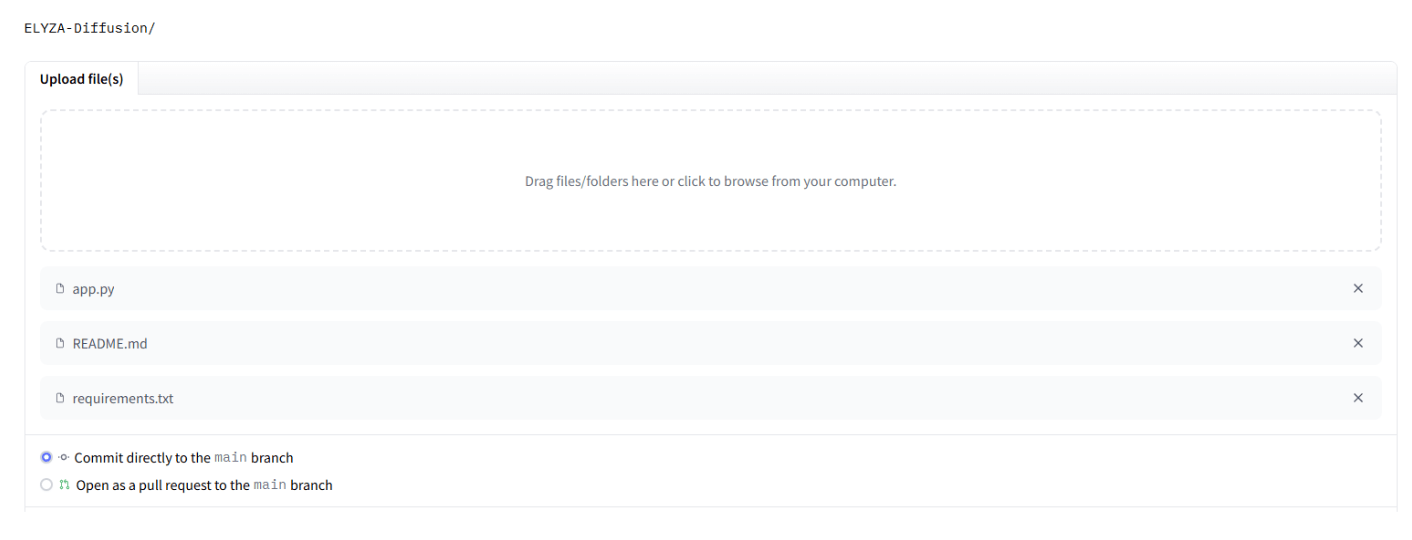
アップロードが完了すると、Spacesのステータスが以下の通り「Building」になります。

デプロイが完了すると「Running」になるため、ステータスが変更されるまで待機します。10~20分ほどで完了します。

ステータスが「Running」になったら、画面右上の「App」をクリックしてください。チャット形式のWebアプリケーションが表示されていればデプロイ成功です。
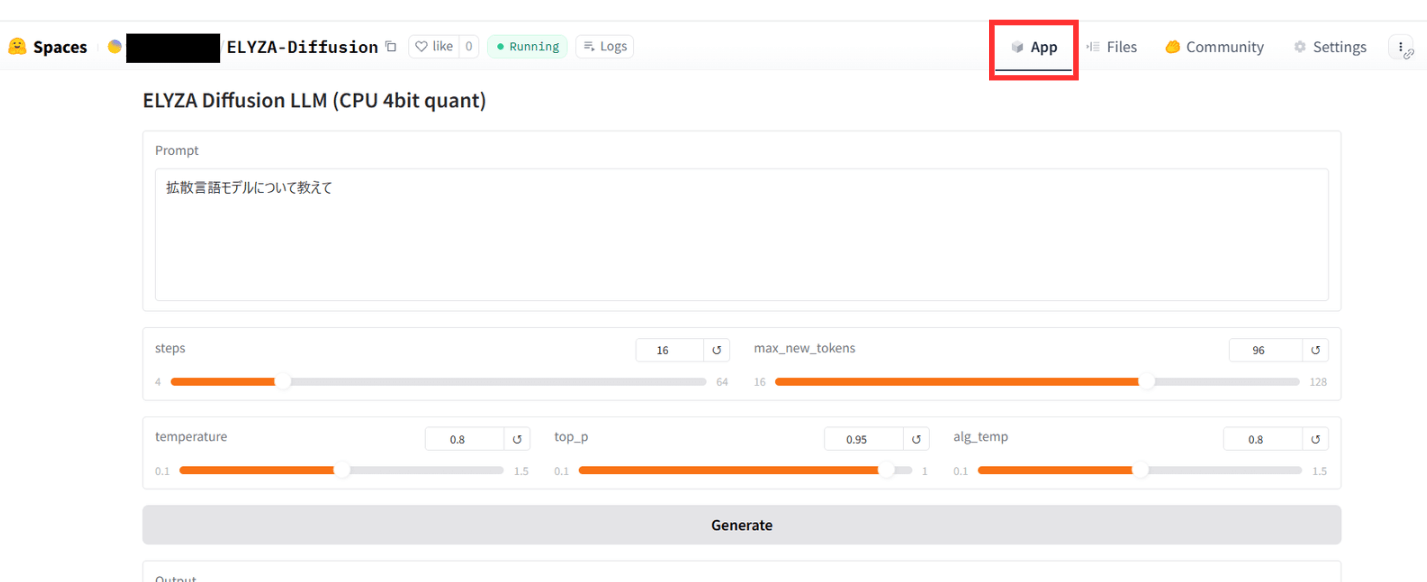
以上の手順で、ELYZA-LLM-Diffusionによる文章生成が可能なWebアプリケーションをデプロイできました。ソースコードを変更することでUIを変更したり、既存のサービスやシステムにELYZA-LLM-Diffusionによる文章生成の機能を組み込むことができます。
今回は無料枠でデプロイするためにCPUを利用していますが、ELYZA-LLM-DiffusionはGPUでの起動が想定されています。自社のリソースやクラウドサービス等、GPUが利用可能な場合はGPUの利用をおすすめします。

ELYZA-LLM-Diffusionの料金|コストはどこで発生する?

ELYZA-LLM-Diffusionのような公開モデルを利用する場合、モデルの利用料金とモデルの実行環境の利用料金が発生します。また、実行環境については各種クラウドサービス等、複数の選択肢があります。
ELYZA-LLM-Diffusionは現在、主に研究用途および検証用途を想定しオープンソースライセンスであるApache License 2.0のもと公開されています。モデル自体の利用料金は発生せず、商用利用も可能です。
ただし、モデルを実行するためにはコンピューティング環境が必要となり、この実行環境の使用には料金が必要なケースがあります。
- モデルの利用 … オープンライセンスのため料金は不要
- モデルの実行環境 … 計算リソースの使用に料金が発生するケースがある
本記事の「公開モデルをHugging Face Spacesで動かす」ではCPUを使ってモデルを動かしていますが、ELYZA-LLM-DiffusionはGPUでの実行が想定されています。
GPUが利用できるサービスとして、Hugging Face Spacesの有料プラン、AWS、Azureについて調査しました。
| サービス | GPU提供機能(代表例) | ハードウェアスペック | 料金 | 備考 |
|---|---|---|---|---|
| Hugging Face Spaces | Nvidia T4 – small | 4vCPU メモリ15GB ディスク50GB | $0.40/時間 (62円/時間) | GPU環境でPythonアプリケーションをデプロイ可能 |
| Amazon EC2 (仮想マシンサービス) | g4dn.xlarge | 4vCPU メモリ16GB ディスク125GB | $0.71/時間 (110円/時間) | g4dn.xlargeは機械学習モデルデプロイ用のNVIDIA GPUを搭載した仮想マシン 価格はリージョン・OS・購入方法(スポット/オンデマンド/事前購入)により変動 |
| Azure VM (仮想マシンサービス) | NV6adsv5 | 6vCPU メモリ55GB ディスク180GB | $0.6580/時間 (102円/時間) | NVIDIA A10 GPUを搭載した仮想マシン 価格はリージョン/OS/購入方(スポット/オンデマンド/事前購入)等で変動 |
実行環境を選択する際には必要なGPUやメモリサイズを踏まえて判断する必要がありますが、GPU利用は高額になりがちです。まずは低コストな構成で検証し、要件に応じて段階的にGPU性能を引き上げる進め方が現実的です。
まとめ
ELYZA-LLM-Diffusionは「不完全な状態の文章を段階的に修正して完成させる」ことで文章を生成する拡散言語モデルです。生成途中でも文章全体を把握しやすいため、要約・言い換え・トーン統一・定型フォーマットへの整形いったタスクでを得意とします。
また主要パラメータである「steps」により、生成する文章の品質・生成制御性と速度・計算コストのバランスを制御できる点が特徴です。
本記事では実践的なノウハウとして、ELYZA-LLM-Diffusionを使った文章生成アプリケーションをWeb上にデプロイする手順や料金の考え方も紹介しています。まずは簡単にELYZA-LLM-Diffusionを検証できる公式デモを利用して、拡散言語モデルによる文章生成を体験してみてはいかがでしょうか。