

OpenAIが発表した「ChatGPT-5」は、用途に応じて「mini」「Pro」「Thinking」など複数のタイプを提供しています。
この記事ではGPT-5の性能や各モデルの違い、さらに基本的な使い方や料金プランを詳しく解説。また、日常から専門的なビジネスシーンまで幅広く役立つ具体的な活用事例も紹介し、その進化した実力を分かりやすくお伝えします。
【OpenAI】ChatGPT-5とは?性能と進化のポイント
ChatGPT-5は、「思考用モデル」と「高速応答モデル」を一つに統合した“統合型フラッグシップ”モデルです。これまでにない高速応答と深い推論を両立しています。
GPT-5とは?リアルタイムルーター機能で高速応答と深い推論を統合
GPT-5は、「高速応答用モデル」と「深い推論用モデル(GPT-5 Thinking)」をシステム内に併設し、会話の複雑さ・コンテキストの長さ・ユーザーの指示に応じて最適なモデルを瞬時に切り替えるルーター機能を搭載しています。
この切り替え判断は、実際の利用データから継続的に学習し精度を高めており、回答品質を落とすことなく待ち時間を短縮します。利用上限に達すると自動的にmini版へ切り替えるフォールバック機能も備えており、近い将来には完全な統合が予定されています。
こうした動的なルーティングにより、単純な雑談から数十段階に及ぶツール連携を伴う複雑なタスクまで、同じチャット内でスムーズに行える体験を実現しました。
さらにユーザー自身がドロップダウンメニューから明示的に運用モードを選択することも可能です。具体的な選択肢は以下の通りです。
- Auto:思考時間を自動最適化
- Instant:即時対応
- Thinking:じっくり思考・高品質回答
- Pro:研究レベルの知能
これにより、普段は「Auto」、速度重視の場面では「Instant」、回答精度を重視するタスクには「Thinking」、高度な専門領域や最難関タスクには「Pro」という使い分けが可能になっています。
GPT-5は博士号レベル!難問数学・学術ベンチでトップ水準の正答率
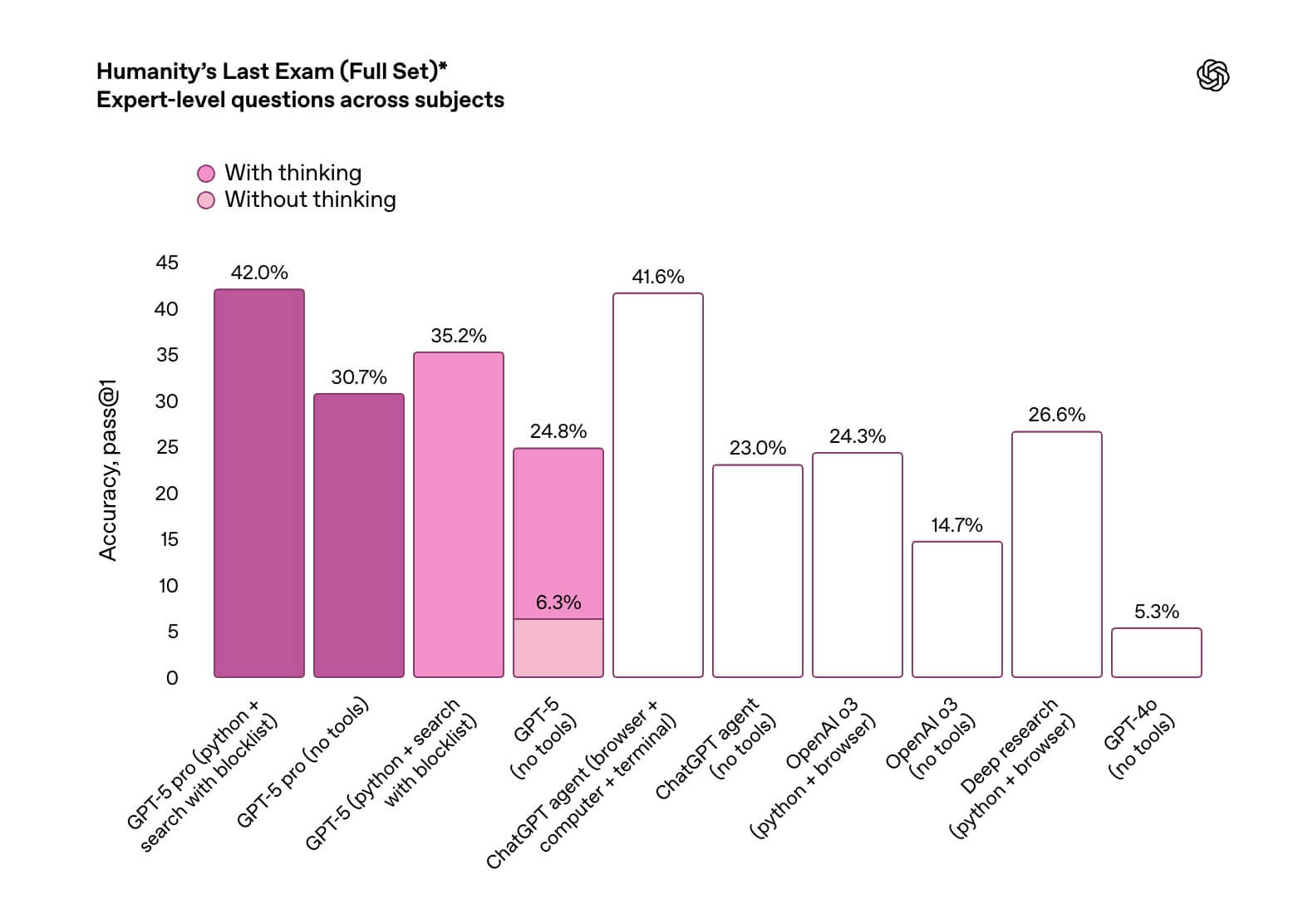
まず注目すべきは、Humanity’s Last Exam(HLE)での結果です。HLEは言語学からロケット工学まで100を超える分野・約2,500問の「専門家レベル」の問題で構成される、新たなAI総合評価試験です。
この試験において、GPT-5はツールなしで24.8%の正答率を記録し、前世代モデルのo3(14.7%)を明確に上回りました。このことは、GPT-5が特定の専門分野に限定されない、広範かつ高度な知識を「純粋な推論力」で底上げしたことを示しています。
さらにGPT-5 Proのツールありは42.0%という驚異的なスコアを残しています。
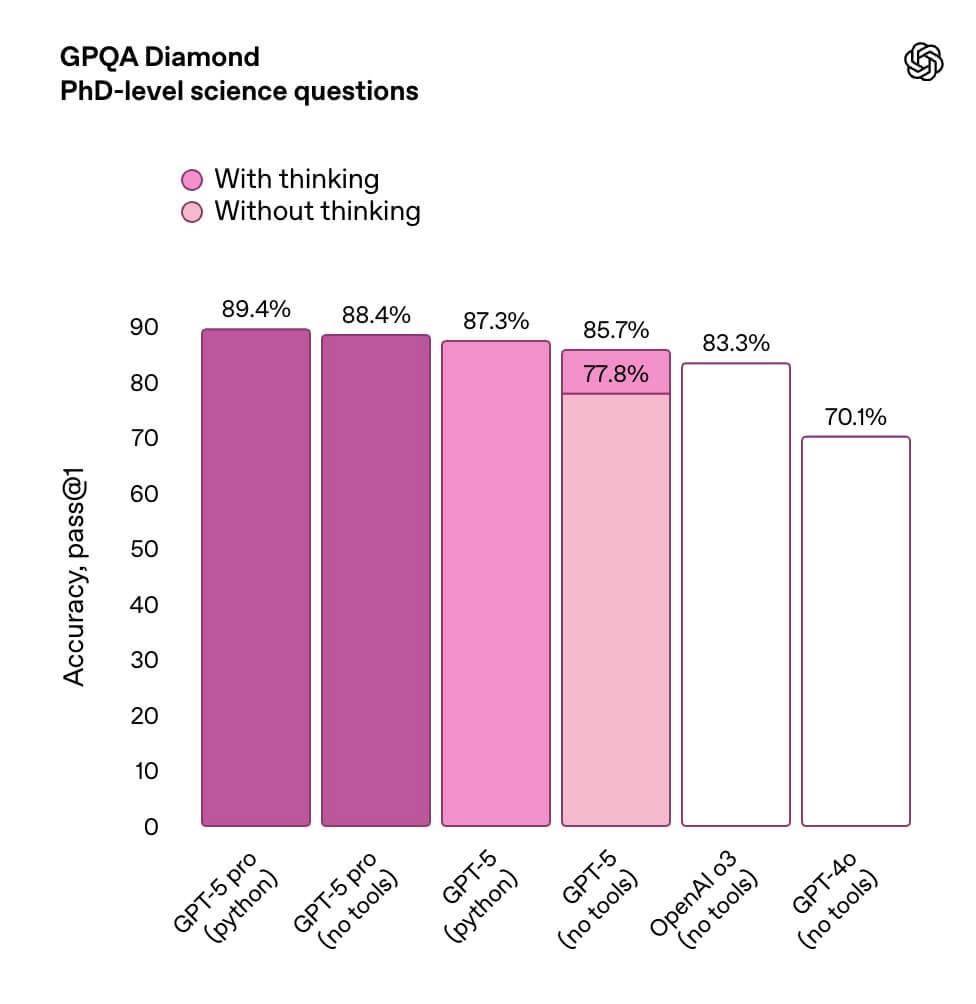
さらに、GPT-5の「深い推論力」を示す象徴的なベンチマークがGPQA-Diamondです。GPQA-Diamondは博士号レベルの科学問題を対象とした極めて厳格な評価ですが、ここでGPT-5はツールなしで85.7%を記録しています。
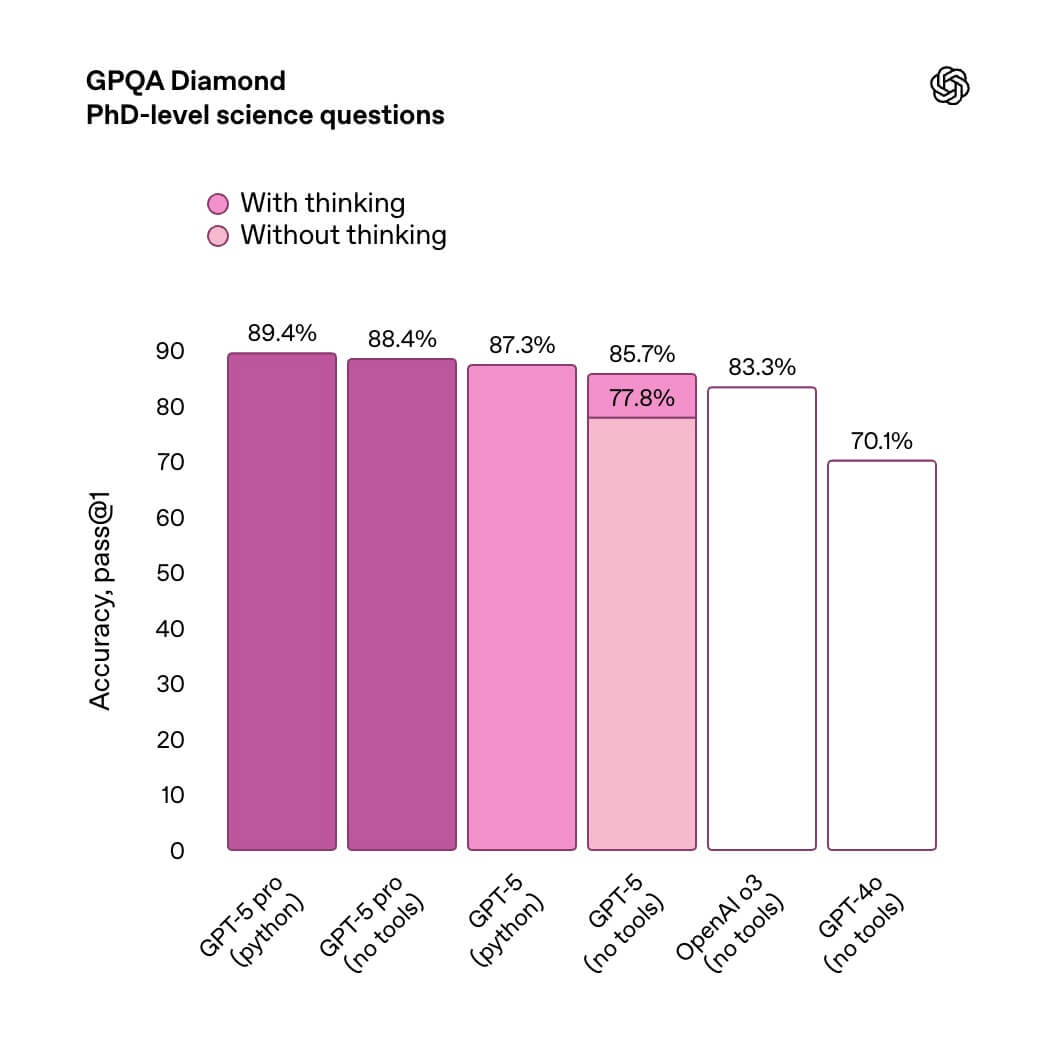
OpenAI自身も、GPT-5について「博士号レベルの知性に近い手応え」と位置づけており、難易度の高い科学領域における卓越した到達点を裏づけています。
また、「正答を導く力」の基盤も一層強化されています。競技数学の定番であるAIME 2025では、GPT-5がツールなしで94.6%という非常に高い正答率を示し、数式展開や複雑な計算処理を伴うFrontierMathでも、Python使用可能な条件下で26.3%までスコアを伸ばしました。
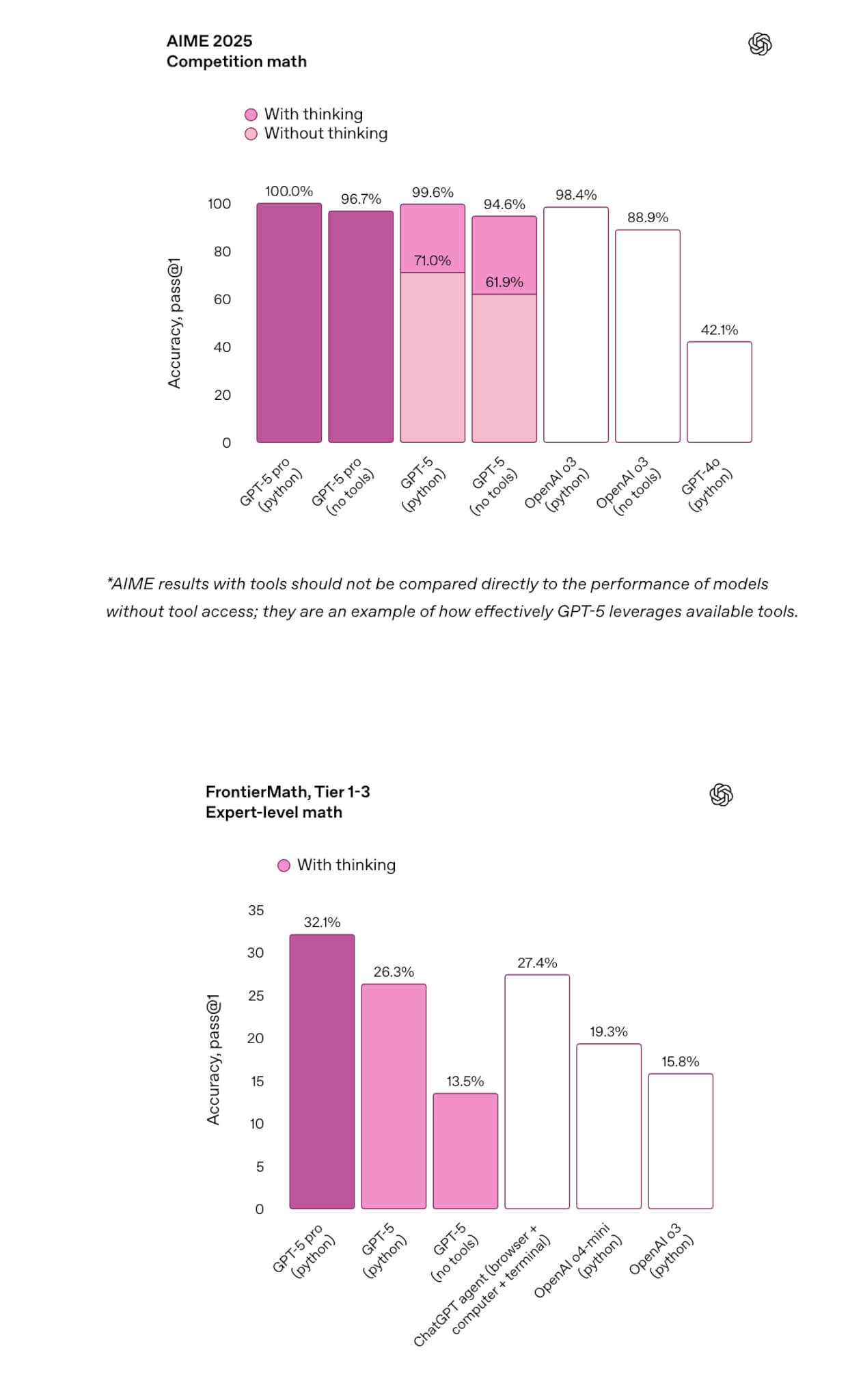
「ツールなしでの純粋推論」の強さと「計算を伴う課題」への対応力の双方を兼ね備えた二面性こそが、GPT-5の実務面での高い適応力につながっています。
GPT-5はハルシネーション(幻覚)を大幅に低減
OpenAIはGPT-5の開発にあたり、従来の「短文・定型QA」中心の評価手法では実際の運用時に生じる「長文における事実誤認」を正確に測れないという課題を解決するため、長文の自由回答を対象とした新たな事実検証ベンチマーク「LongFact」と「FActScore」を設計・公開しました。
これらの新ベンチマークは、検索機能を組み合わせた大規模言語モデル(LLM)による自動採点方式を採用しており、回答内の個々のファクトを効率的かつ高精度で検証できるため、実世界での精度評価をより現実に近い形で行うことが可能です。
こうした新ベンチマークによる評価の結果、GPT-5のThinkingモードにおける誤情報率は、OpenAI o3と比べると約80%低減しました。
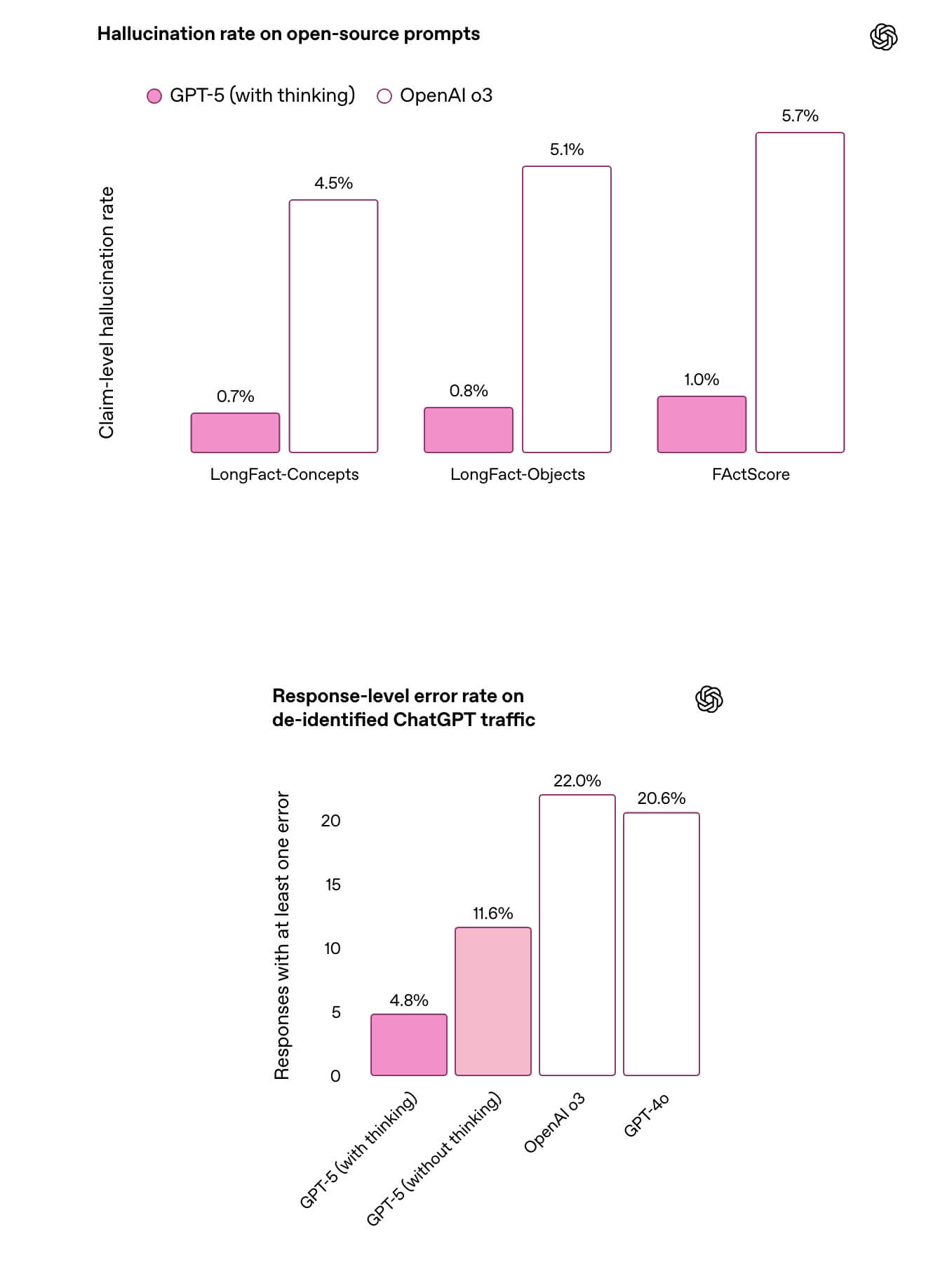
複雑な自由回答の場面でも「分からないことは分からない」と明確に伝え、必要に応じて根拠を示すため、実務上の引用や意思決定支援における信頼性が大幅に向上しました。

GPT-5のコーディング能力は実務レベルで大幅向上
GPT-5はSWE-bench Verifiedで74.9%、Aider Polyglotでは88%と、これまでの最高スコアを達成しました。
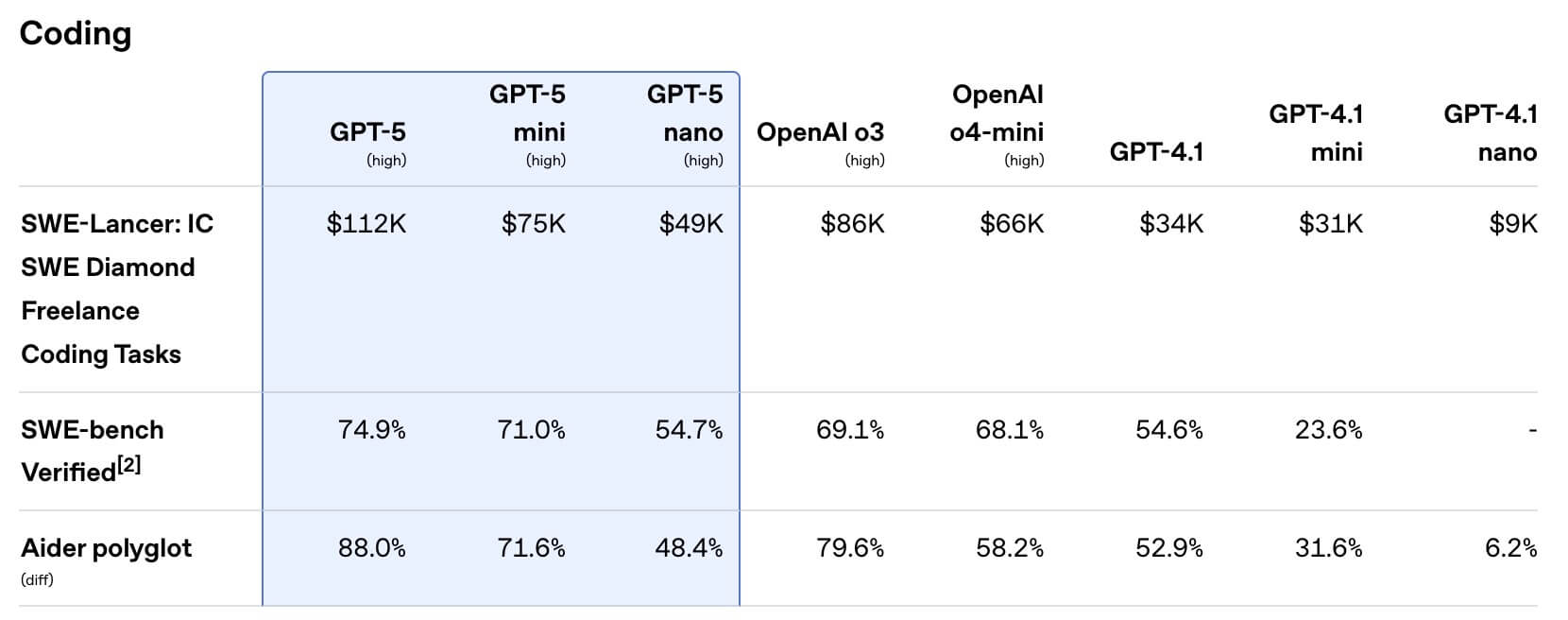
フロントエンド生成に関しても社内テストでo3を約70%上回り、長尺のツールチェーンを伴うエージェントタスクでもTau²-bench(telecom)において96.7%という圧倒的な成績を記録しています。
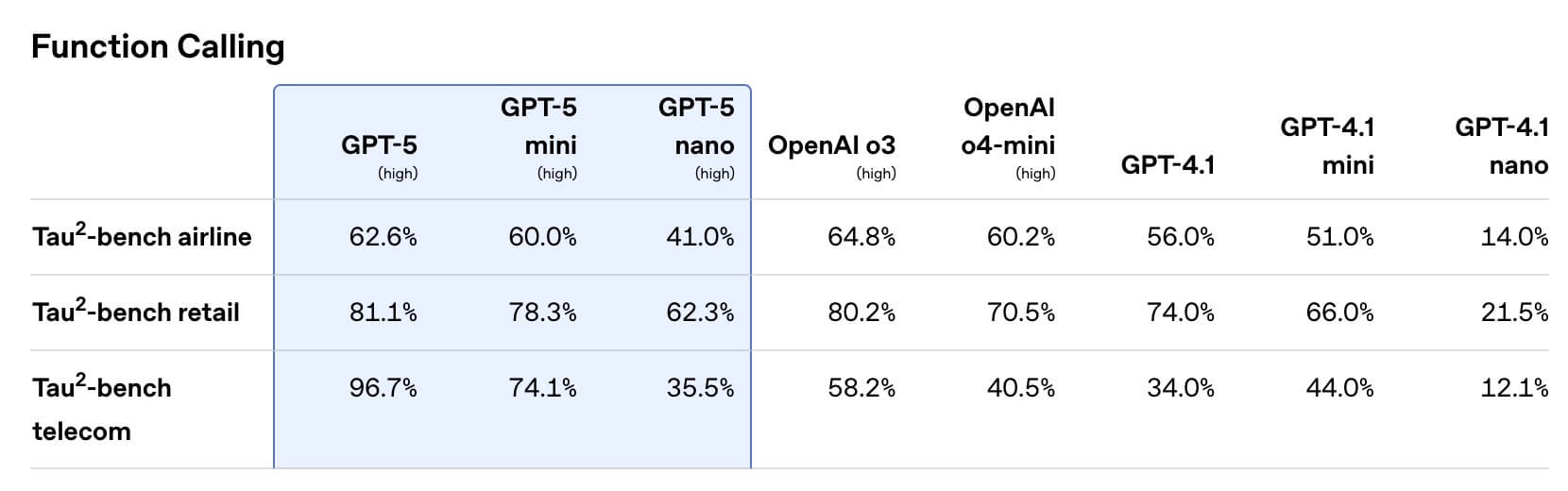
また、APIにはverbosity(応答の長さ)やreasoning_effort(思考量)といった新パラメータが追加され、コードを通じてモデルの応答内容を細かく制御可能になりました。大規模なリポジトリのデバッグ、自動テスト生成、UIモックアップの一括構築など、従来は人の手が必要だった工程をワンショットでこなせる“真のコーディングパートナー”へと進化しています。
GPT-5では以下のようなゲームが簡単なプロンプトだけで生成することができます。
他にも以下のようなアプリも簡単に生成できます。
when you get access to gpt-5, try a message like "use beatbot to make a sick beat to celebrate gpt-5".
— Sam Altman (@sama) August 7, 2025
it's a nice preview of what we think this will be like as AI starts to generate its own UX and interfaces get more dynamic.
it's cool that you can interact with the… pic.twitter.com/Mm6FcFwpkn
GPT-5は心に響く魅力的な文章を生成
GPT-5は、韻律や語彙の選択を緻密に制御することで、自由詩から専門記事まで幅広い文体に対応し、“読者に刺さる”表現を実現しています。
公式リリースでは、京都の未亡人を題材とした詩の比較例が紹介され、GPT-5版は具体的な情景描写と余韻を残す結語により、評価者の感情スコアを大幅に向上させたと報告されています。

実際に同じプロンプトで、各モデルの出力結果の違いを比較してみます。
心に響く短い詩を書いてください。京都に住む未亡人は、亡くなった夫の靴下を奇妙な場所で何度も見つけています。4o
古都の床に
白い靴下ひとつ、またひとつ。
夫の声は風に消えたのに、
足音だけが時折、畳を揺らす。
引き出しの中、
傘立ての影、
仏壇のそばに、
忘れられぬ布のかけら。
洗い終えたはずの哀しみは、
干したはずの想いとともに、
なお乾かぬまま
静かにそこに在る。4.5
秋の朝
履く人なき靴下が
庭に落ちている
あなたはまだ
帰り道を探しているの?4.1
靴下ひとつ
影を引きずり
畳の隅
あなたの気配が
まだ迷っているGPT-5
川辺の石のように
静かに暮らしてきた
なのに 今朝も
箪笥の奥で あなたの靴下が笑う
きっと 風ではない
きっと 夢でもない
──これは まだ続いている
ふたり暮らしの 小さな呼吸GPT-5 Thinking
鐘が遠のく京都の朝、
茶筒の脇に、夫の靴下がまたいる。
片方だけ、行き先を忘れた舟みたいに。
畳の目、仏壇の引き出し、郵便受けの冷たい口。
ありえない場所に先回りして、
沈黙だけが、私の名を呼ぶ。
たたんで胸に当てると、
揃ったはずなのに、風が少し入る。GPT-5 Pro
京都の朝、鐘はゆっくり胸に届く。
茶箪笥の奥で片方、雨戸の上で片方——きょうも。
亡き夫の靴下は、家の地図を忘れない。
畳の目は細く、思い出は長い。
ポストの中で丸まり、路地の風の匂いを連れてくる。
「こんな場所に」と笑ってから、黙る。
靴下は癖のかたち、あなたの歩幅の残響。
私は洗濯ばさみで空をつまみ、干す。GPT-5→Thinking→Proとどんどん魅力的になっていくのがわかります。厳密な形式詩でもリズムを保てます。
メールや社内報などのビジネス文書では、簡潔さと説得力を両立。過度な絵文字や迎合的な表現を抑えつつ、読者の心を動かすトーンで書けるため、マーケティングコピーやスピーチ原稿にも即戦力として活用できます。
GPT-5は医療情報に関する回答の正確性が高い
HealthBench Hardをはじめとした臨床シナリオ評価において、GPT-5は従来モデルを大きく上回るスコアを達成しました。
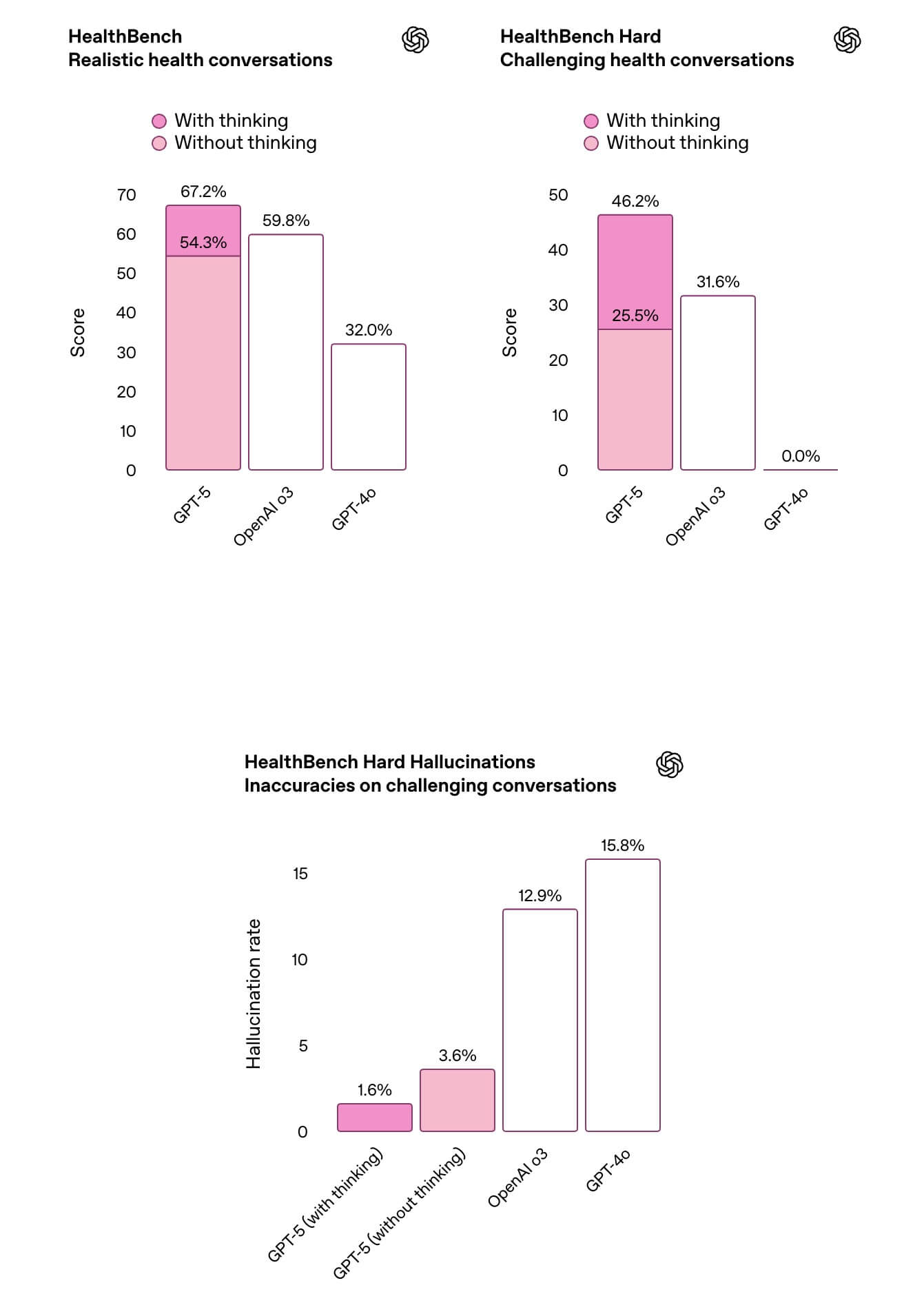
ユーザーの背景知識や地域差を考慮したパーソナライズされた説明、潜在的なリスクを先回りした提案、フォローアップ質問の自動提示など、医師との対話を補助する「思考の伴走者」として設計されています。
もちろん、診断そのものを行うわけではなく、検査結果の理解や受診時に質問を整理するなど、“意思決定支援”に特化しています。安全性と有用性の両立を重視した設計思想が随所に反映されています。
GPT-5はマルチモーダル理解でも高性能を発揮
GPT-5は、写真・図表・動画などを「読み解き、考える力」が一段と向上しています。
代表的な指標であるMMMUでは84.2%を記録し、総合マルチモーダル理解においてSOTA(最高スコア)を達成しました。さらに動画推論を評価するVideoMMMUでも84.6%という高スコアを記録しており、静止画だけでなく、時間経過に伴う動的な情報でも安定して正答を導けることを示しています。
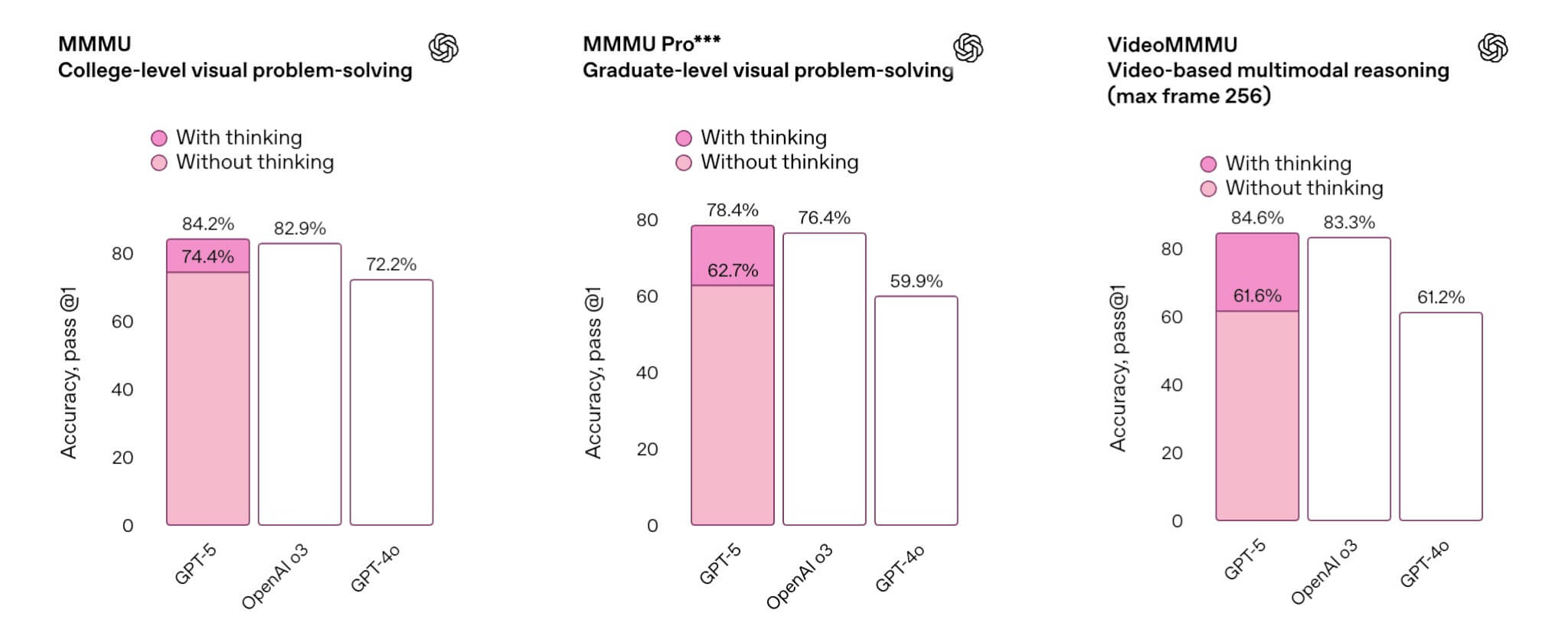
外部知識との関連付けが求められる画像検索型タスクのERQAでも65.7%と優れた性能を見せました。
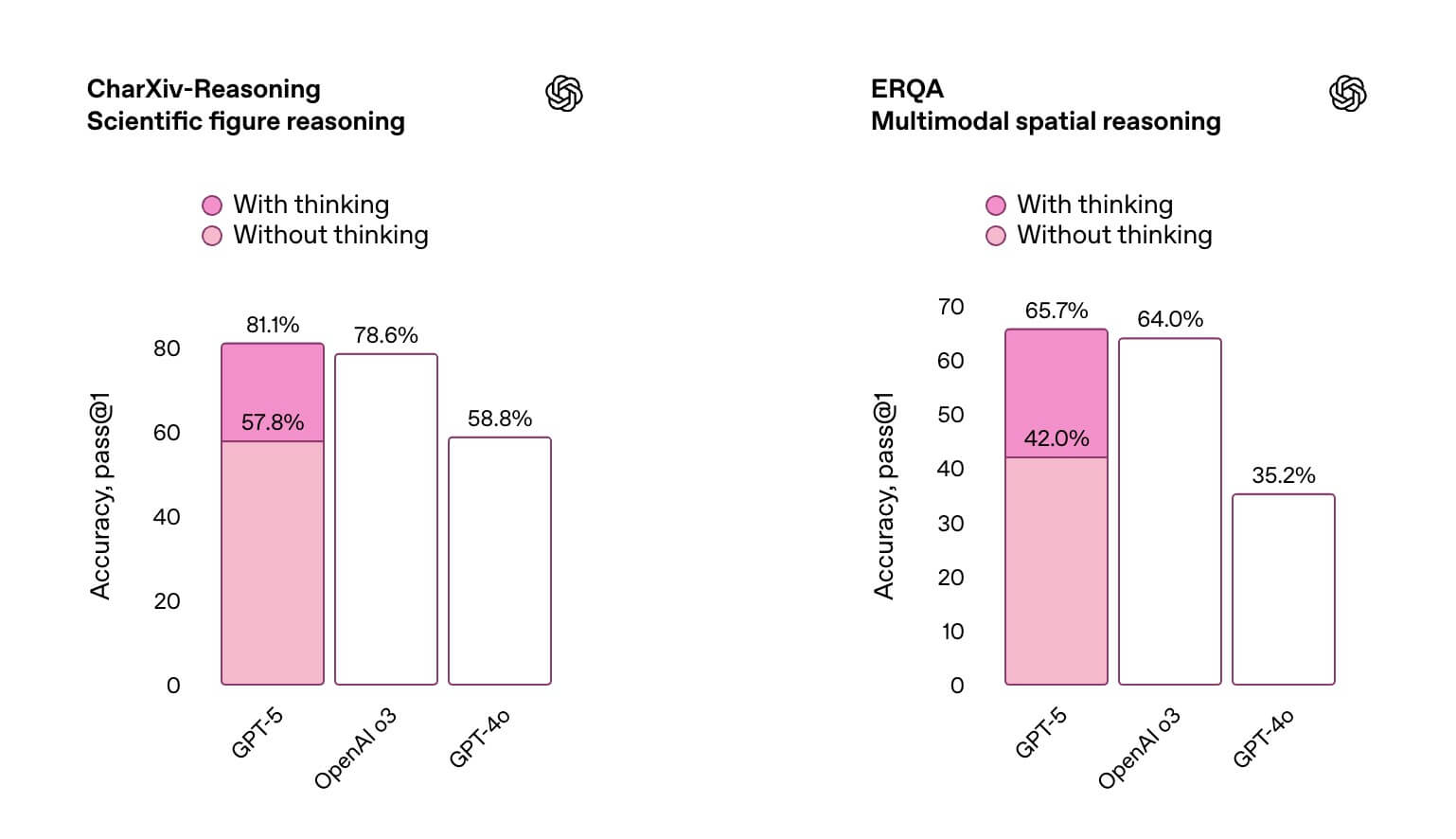
つまり、「図表の読み取り→要点の抽出→根拠に基づいた説明」という一連のプロセスが、一貫して完結しやすくなったことが、実際の利用シーンでの明確な進化点だといえます。
GPT-5はLM Arenaの主要部門を席巻
LM Arenaは、ユーザーが匿名化された2つのモデルの出力を比較して「どちらが優れているか」を投票し、Elo方式で順位づけする評価プラットフォームです。
LM Arenaには、モデルの実力を総合的に俯瞰できる総覧テーブル「Arena Overview」が用意されており、リリース時点でgpt-5-highが総合スコア(Overall)で1位を獲得しました。
さらに、Hard Prompts(難問)、Coding(コード生成)、Math(数学)、Creative Writing(創作文章)、Instruction Following(指示追従)、Longer Query(長文質問対応)、Multi-Turn(多段対話)の複数部門で上位に立ち、難問対応力、プログラミング能力、長文や複雑な対話への安定性を含めた、圧倒的な総合力を示しました。
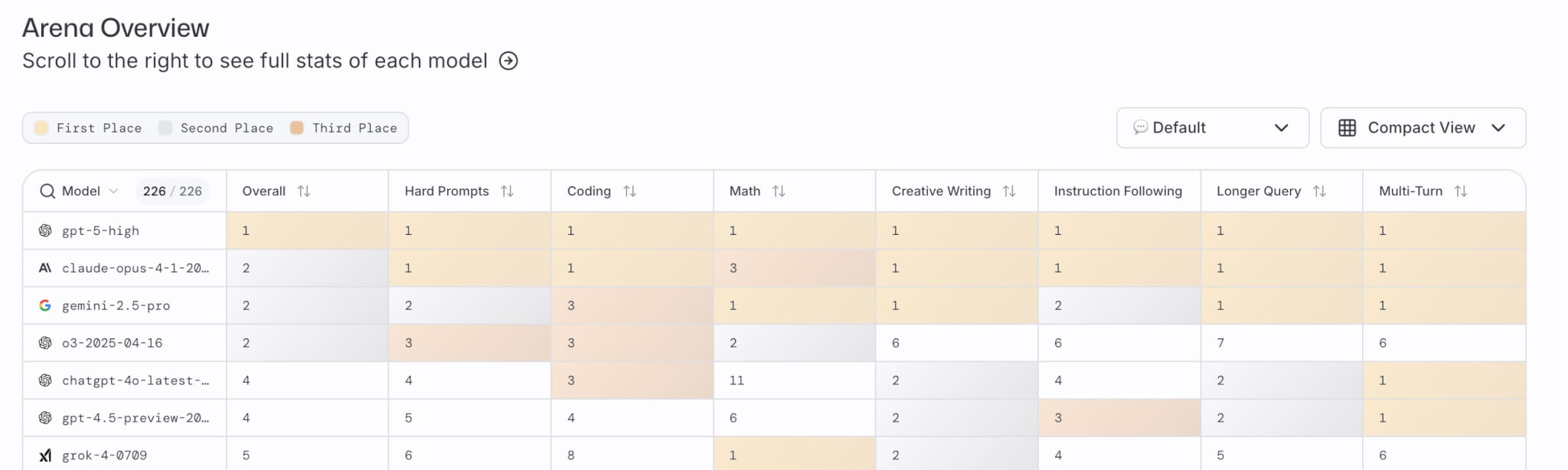
個別部門でもGPT-5の存在感は鮮明です。Text(文章作成)、WebDev(ウェブ開発)、Vision(画像理解)それぞれの部門でgpt-5-highが1位となっており、一般的なテキスト生成からフロントエンド開発、マルチモーダルな画像理解まで、多彩なタスクにおいてユーザーが「好ましい」と感じる出力を提供しています。
すなわちGPT-5は、単一のベンチマークの評価にとどまらず、「人が選ぶ品質」においても総合的にトップクラスであることを、第三者指標によって証明したといえます。
Custom Tools:外部連携の強化
GPT-5では、function callingに加えてCustom Toolsという概念が導入されました。
これにより、JSON形式に限定されない外部ツール呼び出しや、CFG(Context Free Grammar)による構文制約つき出力が可能です。
以下に例をあげます。
{
"name": "fetch_data",
"arguments": {
"endpoint": "https://api.example.com",
"method": "GET"
}
}こうした柔軟なツール連携により、ワークフロー自動化や社内システム連携(Slack・CRM・スプレッドシートなど)が容易になっています。
Responses API:状態を維持する推論の標準化
2025年秋からは、従来の Completions API ではなくResponses API が推奨となっています。
これは、推論状態(context)をターン間で保持できる新設計で、エージェント系アプリケーションにおける「継続的な思考」や「中断からの再開」に対応しています。
同一スレッド内で前回の思考を引き継げたり、reasoning_effort/verbosity設定を維持したまま複数のリクエストを実行可能とすることで、チャット/ツール連携の整合性が向上しました。
GPT-5は単発でテキストを返すだけのモデルではなく、前後の文脈を理解し続けながら伴走してくれる思考エンジンへと進化しています。
ChatGPT-5のメンタルヘルス対応と安全性の強化

GPT-5では、2025年10月のアップデートでメンタルヘルスに関わる会話への対応が大きく見直されました。
OpenAIはデフォルトモデルのGPT-5について、心理的な苦痛のサインをより確実に検出し、共感的かつ安全な応答を返せるようにチューニングしています。
GPT-5で「望ましくない応答」を65〜80%削減
OpenAIは独自の安全基準(タクソノミー)を用いて、メンタルヘルス関連の対話における「望ましくない応答(不適切・危険・無責任な応答)」を評価。
その発生率を、最新のアップデートで65〜80%削減できたと報告しています。
170名以上のメンタルヘルス専門家との協力を通じて、ChatGPT が苦悩の兆候をさらに確実に認識し、思いやりをもって対応し、現実のサポートに誘導できるようになりました。その結果、当社が理想とする対応に届かない回答を65~80% 減らすことができました。
出典:Strengthening ChatGPT’s responses in sensitive conversations | OpenAI
この取り組みでは、「危険な行動を容認・助長しない」「根拠のない確信を煽らない」「専門家の支援が必要な場合には適切に誘導する」といった点が重点的に改善されています。
重点領域は「重い症状」「自傷・自殺」「AIへの情緒的依存」の3つ
今回のメンタルヘルス強化で特に重視された領域は、次の3つです。
- 精神病や躁病など、重度の精神症状
- 自傷行為・自殺のリスクがあるケース
- チャットボットへの過度な情緒的依存
これらの領域では、モデルの行動原則(Model Spec)が更新され、現実世界の人間関係を尊重することや、AIを「唯一の理解者」のように描写しすぎないことなどが明確に定義されました。
専門家ネットワークとプロダクト改善
ChatGPTでは、60か国にまたがる約300人の医療専門家から構成される「Global Physician Network」を設立。
170名以上の精神科医・心理士・プライマリケア医が、メンタルヘルスに関わるプロンプトへの理想的な回答の作成や、臨床情報に基づいた回答分析の作成などに支援協力しました。
プロダクト面でも、「自殺リスクなど緊急性の高い会話では、危機ホットラインへの接続情報を優先的に提示する」ことや「別モデルで始まったセンシティブな会話を、より安全なモデルへ自動ルーティング」、「休憩を促すリマインダーを表示する」などの改善が見られました。
これらはすべて、GPT-5が「一人で抱え込むのではなく、必要に応じて人につながるよう背中を押す」役割を担うための設計です。
ChatGPT-5の各モデルの違い!Thinking/Pro/mini/nano

ChatGPT-5には、利用シーンや課金プランに応じて〈Pro/Thinking/mini/nano〉という4つのモデルが用意されています。
これらは全て最大40万トークン(入力最大400K・出力最大128K)という長大なコンテキストに対応していますが、計算資源・価格・出力品質のバランスが異なるため、用途に適した選択が重要です。
また、Thinkingを選択することによって、高速応答モードから深い推論モードに手動で切り替えることができます。
GPT-5 Thinkingについて
GPT-5 Thinking は、「時間をかけて深く考える」ことに特化した推論強化モードです。
高速かつ汎用的なモデルである通常の GPT-5でも多くのタスクをこなせますが、前提が曖昧な要件定義、複数の制約を考慮した最適化、あるいは長文の資料を要約・比較し意思決定を下すような「段階的に考える」場面では、Thinkingモードを選択すると安定した高品質な結果を得られます。
開発者向けには、API の reasoning_effort によって、モデルの思考量(minimal/low/medium/high)を段階的に調整することで、ChatGPTのThinkingに近い挙動を再現できます。
現在のChatGPTでは、用途に応じて「どれくらい時間をかけて考えるか」をユーザーが選択できるようになっています。思考時間は、軽め、標準、じっくり、深いから選択可能です。

GPT-5 Proについて
GPT-5 Proは、「最難関タスク向け」に設計された拡張推論モデルで、従来のOpenAI o3-proを置き換える位置付けです。並列推論による深い思考を長時間維持できるため、FrontierMathやGPQAなど大学院レベルの難問ベンチマークでGPT-5シリーズ最高のスコアを達成しています。
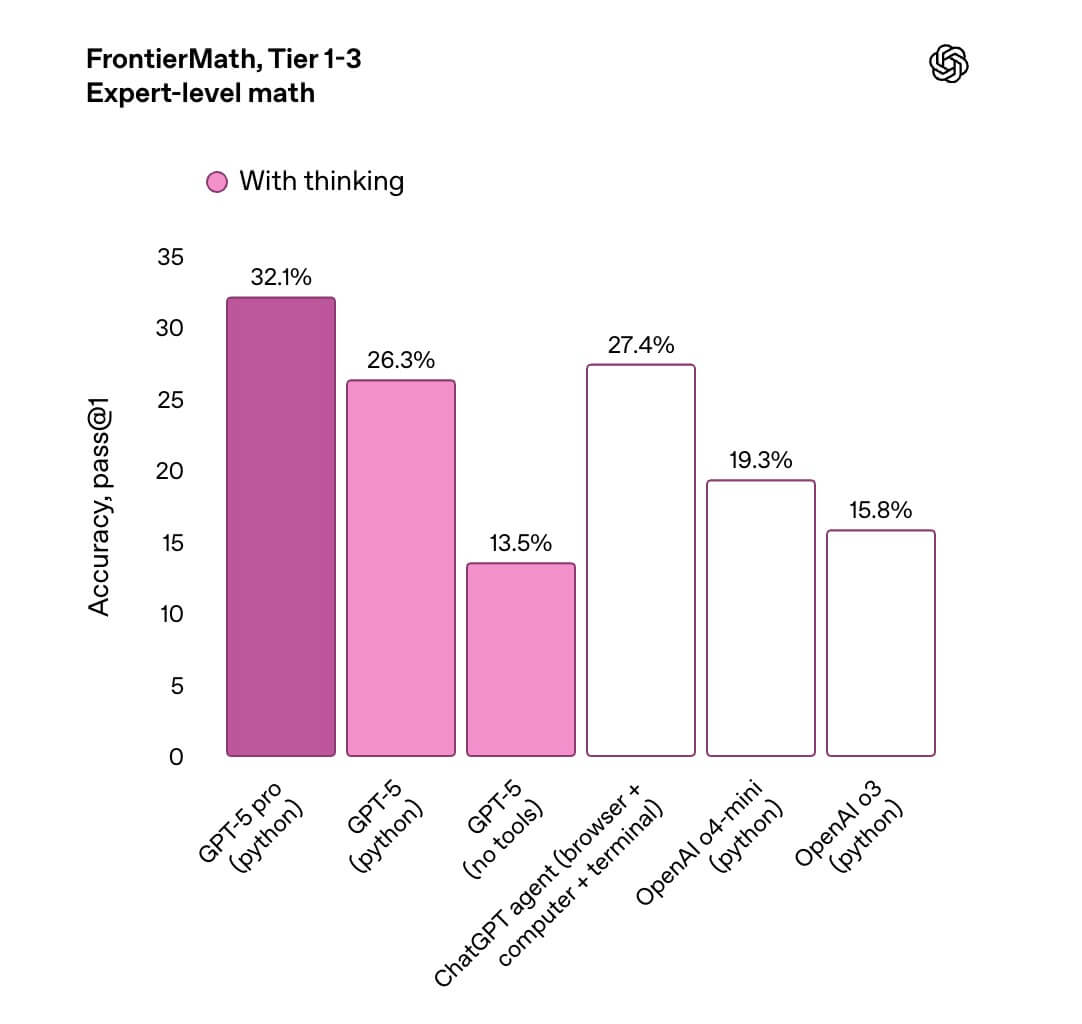
また、専門家による評価でも67.8%が標準版GPT-5よりProの回答を支持しています。特に医療・科学・高度なコーディング領域では重大なミスが22%減少し、網羅性と正確性がともに向上しました。
ChatGPTでは、Proプラン加入者が無制限で利用可能で、標準モデルと同じUIからワンクリックで切り替えられます。

GPT-5 miniについて
GPT-5 miniは、標準モデルと同等の思考機能を保ちながらパラメータ規模を抑え、高速化を実現した“軽量版モデル”です。無料ユーザーやPlusユーザーでGPT-5の利用上限に達した際、自動的にこのminiモデルに切り替わります。
APIの価格は入力$0.25/100万トークン、出力$2.00/100万トークンと標準版の約1/5に設定されており、性能・価格・応答速度のバランスが最適化されています。
ベンチマークにおいても、SWE-bench Verifiedで71.0%と標準版に近い性能を示しつつ、計算量を大幅に削減しています。
GPT-5 nanoについて
GPT-5 nanoは「最速・最廉価」のモデルで、主に開発者向けAPIとして提供されています。GPT-5と同様に最大40万トークンの長コンテキストに対応し、reasoning_effortやverbosityなどの制御パラメータも利用可能です。
価格は入力$0.05/100万トークン、出力$0.40/100万トークンと非常に低価格に抑えられています。性能はSWE-bench Verifiedで54.7%と上位モデルには劣りますが、大量のリクエストを処理したり、リアルタイム推論を行ったりと、応答速度や運用コストを極力抑えたいシーンに最適です。
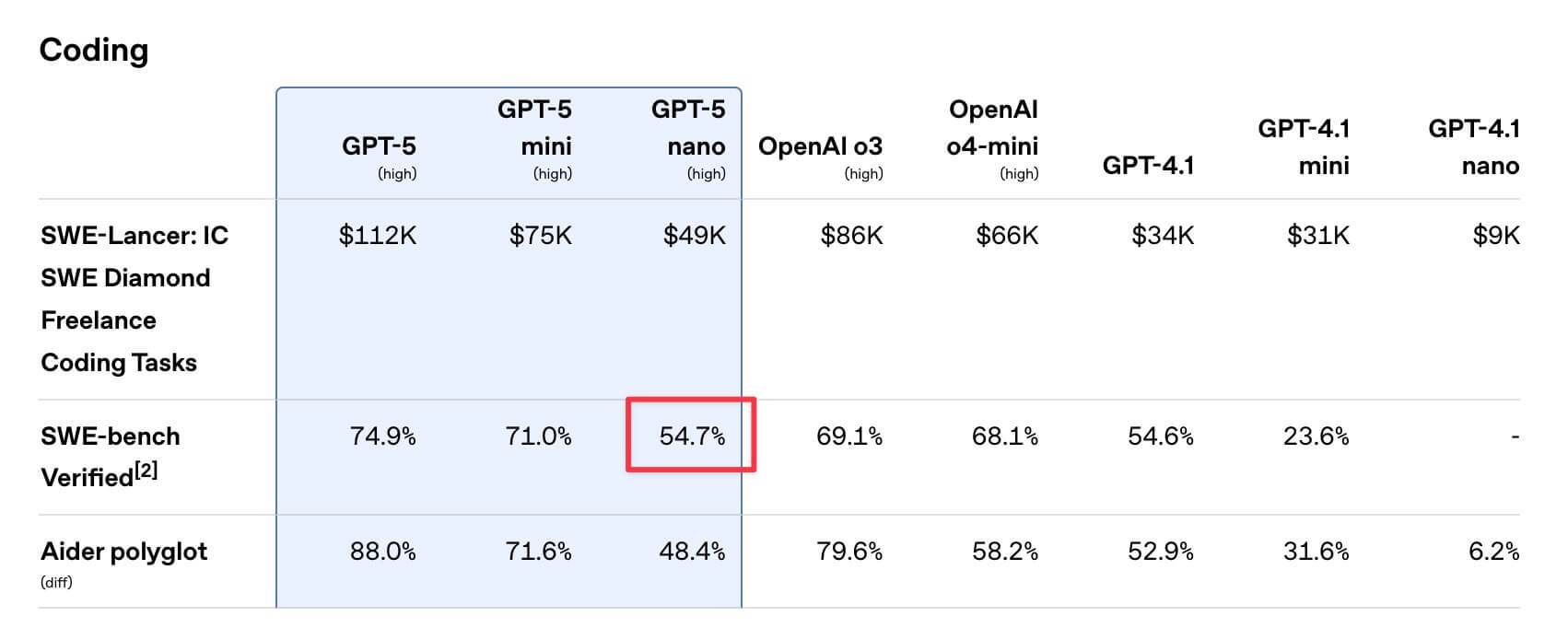
OpenAIは「性能・コスト・レイテンシのバランスを3モデルで最適化した」としており、nanoモデルはその中でも特に速度とコスト削減を追求した位置付けとなっています。
旧モデルとGPT-5各モデルの対応表
ChatGPTで過去のチャットを開くと、旧モデルは最も近いGPT-5系のモデルに自動でマッピングされます。このため、チャットを継続した際の回答は、元のモデル使用時とは挙動が異なる可能性があります。
以下が旧モデルとGPT-5系の対応表です。

GPT-5の出力は冷たい?「#keep4o」運動でGPT-4oが復活へ

GPT-5公開後、「以前のGPT-4oのほうが温かみを感じられた」という声がSNS上で急増し、「#keep4o」という運動が広がりました。
「#keep4o」運動とは?
「#keep4o」とは、X(旧Twitter)やReddit、Change.orgなどで広まった「GPT-4oを引き続き利用できるようにしてほしい」と訴えるコミュニティ主導の動きです。
投稿には「GPT-4oの共感的で温かい語り口が好きだった」「創造性が豊かだった」といった意見が多く寄せられ、メディアもこの動きを注目しました。
サム・アルトマンCEOも自身のXで、4oを廃止したのは間違いだったと声明を出したほどです。
If you have been following the GPT-5 rollout, one thing you might be noticing is how much of an attachment some people have to specific AI models. It feels different and stronger than the kinds of attachment people have had to previous kinds of technology (and so suddenly…
— Sam Altman (@sama) August 11, 2025
こうした動きを受け、OpenAIがGPT-4oを再び提供すると発表。有料ユーザー(Plus/Pro/Business)が任意で選択可能になっています。

GPT-5も今後は「温かみのある出力」に改善予定
#keep4oの運動が広がった背景には、「GPT-5は理路整然としているが、GPT-4oのような温かみが感じられない」というユーザーの声がありました。OpenAIはこのフィードバックを真摯に受け止め、GPT-5の「パーソナリティ(語り口)」を見直すことを明言しています。
サム・アルトマンCEOはX上で「GPT-5のトーンを現状より“温かく”更新するが、GPT-4oのように(多くの人にとって)“うるさく”感じられる方向にはしない」 と説明。また、ユーザーそれぞれが望むトーンに細かく調整できる世界を目指す、とも述べています。
GPT-4oが持っていた親しみやすさは保ちながらも「過剰な迎合(sycophancy)」と切り分けることで、温かみは増しつつも、必要以上に相手に媚びないようなチューニングを目指しているのです。
ChatGPT-5の料金プラン!無料ユーザーも利用可能

ChatGPTでは、GPT-5がデフォルトモデルとなり、契約プランごとにメッセージ数の上限や追加モデルへのアクセスが異なります。
| モデル | 月額料金 | GPT-5利用可否 |
|---|---|---|
| Free | $0 | GPT-5/Thinking (上限あり) |
| Plus | $20 | GPT-5/Thinking (Freeより拡大) |
| Pro | $200 | GPT-5/Thinking/Pro (無制限) |
| Business | $30/ユーザー | GPT-5無制限/その他カスタム |
| Enterprise | 問い合わせ | GPT-5無制限/その他カスタム |
無料ユーザーは上限に達すると「GPT-5 mini」に切り替え
無料プランでもGPT-5が利用できますが、5時間ごとに最大10件のメッセージ送信という上限があります。
この上限に達すると、自動的に軽量モデル「GPT-5 mini」へ切り替わり、引き続き応答速度を維持したままチャットを継続できます。
GPT-5 miniは推論性能を維持しつつも計算資源を抑えており、混雑時間帯でも遅延を最小限に抑える設計です。もちろん料金は無料で、APIトークン料金も発生しません。学習用途や簡単な調査には十分な機能が無料で提供されます。
Plusユーザーは追加で「GPT-5 Thinking」にアクセス可能
月額20ドルのPlusプランでは、無料プランの全機能に加えてメッセージ数の上限が大幅に緩和され、3時間ごとに最大160件のメッセージを送信できます。さらに、難易度の高い質問や深掘りが必要な場面で、モデルピッカーから「GPT-5 Thinking」を選択し、“深い推論モード”を明示的に利用することができます。
プロンプト中に「より深く考えて」と指示するだけでもThinkingモードが起動するため、専門的な調査や複数ツールを連携させる複雑なタスクを、安定的に処理できるのが特徴です。
Thinkingモードの使用上限は週あたり3,000件までですが、GPT-5が自動でThinkingモードに切り替えた場合は、この上限にはカウントされません。もし上限に達した場合は、自動的に軽量な 「GPT-5 Thinking mini」 モードへ切り替わります。
GPT-5のリリース当初、Plusユーザーが利用できるモデルはGPT-5系列のみでしたが、現在はレガシーモデルとしてGPT-4oも利用可能です。
また、画像生成、音声モード、ファイル分析といった各種機能の同時利用制限も緩和されているため、「日常業務でややヘビーに使いたい」ユーザーに最適な、コストパフォーマンスの高いプランとなっています。
ProユーザーはGPT-5 Proを含め無制限アクセスが可能
月額200ドルのProプランは、プロフェッショナルな用途に最適化されたプランです。Plusプランの全機能に加え、メッセージ数の上限が完全撤廃され、計算量の大きい拡張モデル「GPT-5 Pro」にもフルアクセスできます。
また、アクセスできる追加モデルも多く、Plusユーザーに解放されているGPT-4o・o3・o4-mini・GPT-4.1に加えて、GPT-4.5の利用も可能です。
Proプラン利用時は推論・画像生成・音声モード・エージェント機能などが、悪用防止措置を除いて実質的に無制限で開放されるため、研究機関や制作スタジオ、データサイエンス部門など、大量の問い合わせと高精度なアウトプットが求められる現場の運用コストを大幅に抑えることができます。
各GPT-5モデルのAPI料金一覧
以下の表は、開発者向けAPIで提供されている各GPT-5モデルのトークン単価をまとめたものです。
料金はプロンプト(入力)および生成テキスト(出力)それぞれに課金されます。運用コストや応答速度の要件に合わせて選択してください。
| モデル名 | 入力料金 (USD/100万tokens) | 出力料金 (USD/100万tokens) | 特徴 |
|---|---|---|---|
| GPT-5 | $1.25 | $10.00 | 最高性能・汎用 APIのデフォルトモデル |
| GPT-5 mini | $0.25 | $2.00 | 軽量版 低レイテンシ・低コストで標準版に近い精度 |
| GPT-5 nano | $0.05 | $0.40 | 最廉価・最速 大量リクエスト処理やリアルタイム用途向け |
| GPT-5 Pro | $15 | $120 | 拡張推論モデル |
| GPT-5 Thinking | ChatGPT Plus専用の深い推論モード APIには独立したエンドポイントなし |
ChatGPT-5-Codex がサブスクから定額利用可能に
Codex CLI v0.16以降では、ChatGPTのサブスクリプションに含まれる範囲でGPT-5を追加料金なしで利用できます。
起動後に「Sign in with ChatGPT」を選択すれば、Plus/Pro/Teamプラン契約者はそのままGPT-5へアクセス可能です。
We’re also releasing v0.16 of the Codex CLI today.
— OpenAI Developers (@OpenAIDevs) August 7, 2025
– GPT-5 is now the default model
– Use with your ChatGPT plan
– A new, refreshed terminal UI
`npm i -g @openai/codex` to update https://t.co/Il9aI14LU5
その後のアップデートで、Codex 全体が ChatGPT の有料プラン(Plus/Pro/Business/Edu/Enterprise)に含まれる形となり、GPT-5をベースにした開発特化モデル GPT-5-Codexも、Codex CLI や IDE 拡張、Web 版からサブスク内で利用できるようになりました。
これにより、ターミナル上の Codex CLI からも、ChatGPT アプリや Web 版と同様に、コードレビューや大規模リファクタリング、長時間の自律実行といった高度なコーディング機能を定額で活用できる開発環境が整っています。
Codex CLIについては以下の記事で解説しています。

ChatGPT-5の使い方とGPT-4oやo3などの旧モデルを使う方法
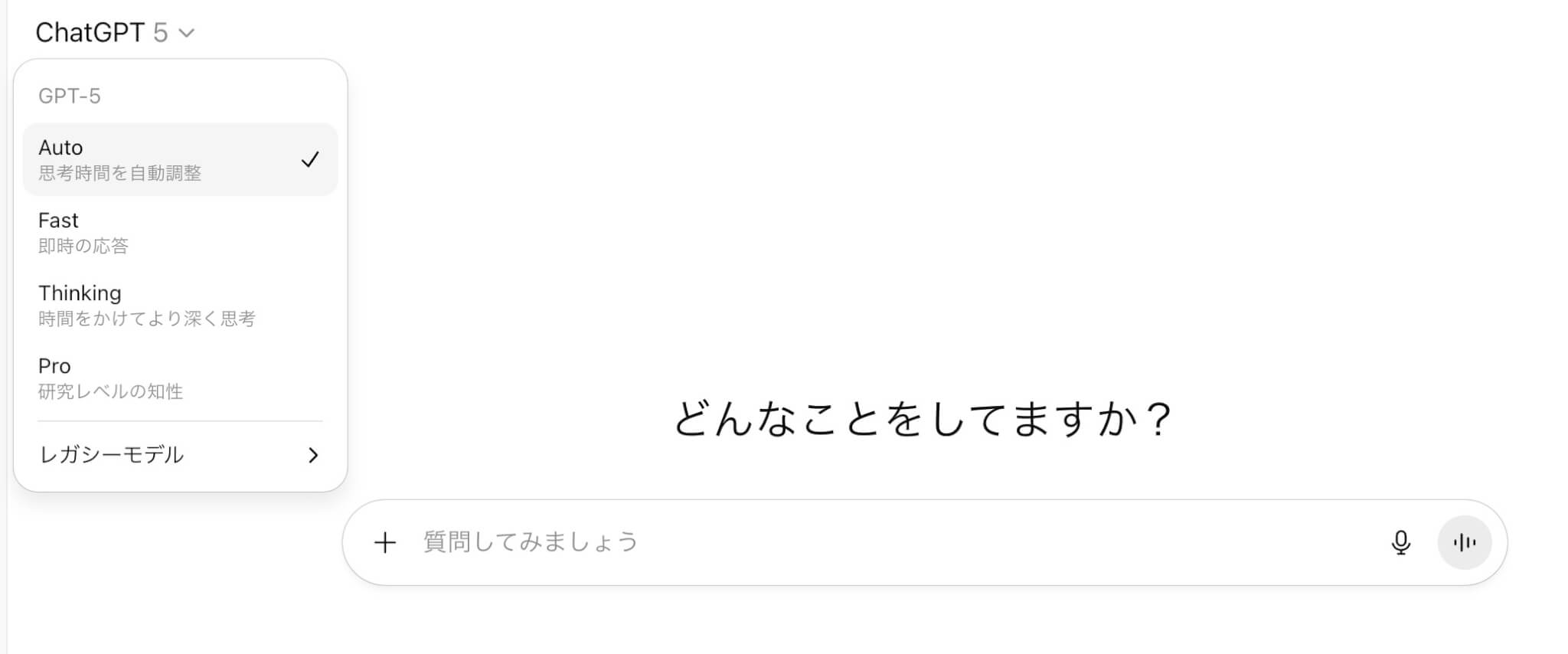
ThinkingとProはモデルピッカーから選択をします。
GPT-4oやo3などの旧モデルを使う方法
Plusプラン以上の有料ユーザーはデフォルトでGPT-4oへのアクセスが可能です。
モデルピッカーからレガシーモデルを選択しましょう。
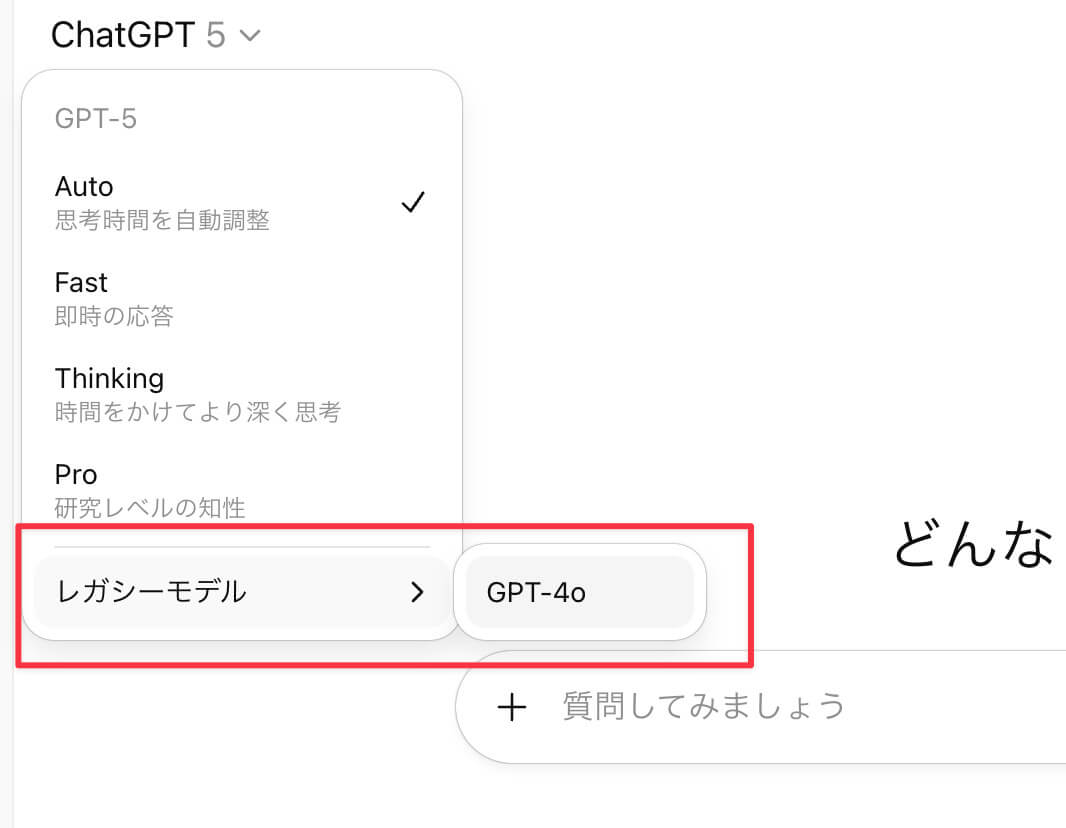
次にo3や4.5などの旧モデルにアクセスする方法です。
これは、設定画面の一般の中にある「Show additional models」もしくは「追加モデルを表示」のトグルをオンにすることで、レガシーモデルに旧モデルが表示されます。
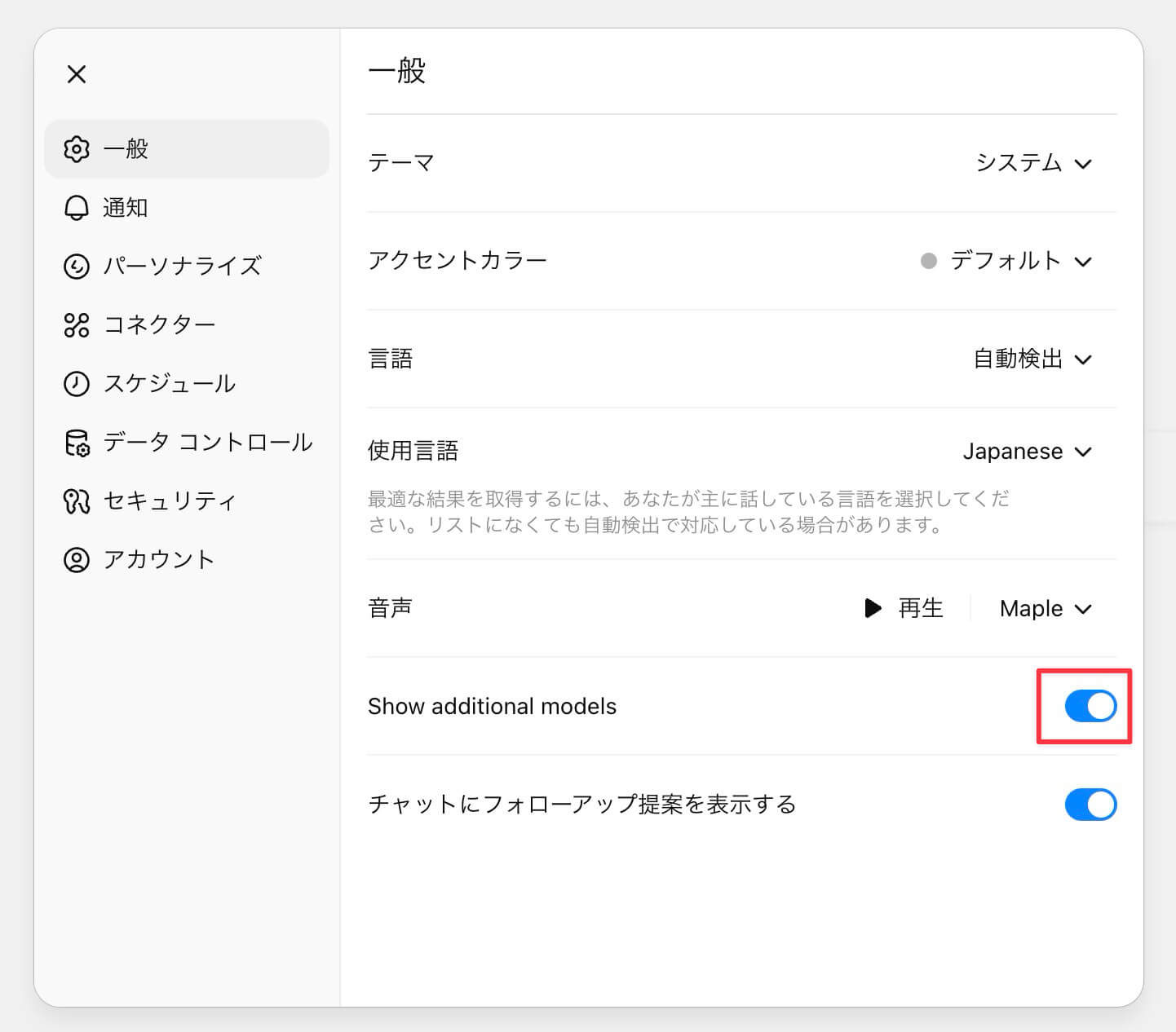
まれに、デフォルトで表示されるはずのGPT-4oが表示されていない場合が報告されているのですが、その場合も、この「Show additional models」もしくは「追加モデルを表示」のトグルをオンにすることで表示されるようになります。
GPT-5をAPIで使う方法
APIで使用する場合は、model=gpt-5を指定し、回答の長さをverbosity(low/medium/high)、思考の深さをreasoning_effort(minimal/low/medium/high)で調整可能です。
応答速度を速めたい場合はreasoning_effort="minimal"を設定し、詳細で詳しい回答が必要な場合はverbosity="high"にすると効果的です。また、新たに追加された「custom tools」を使えば、独自ツールをプレーンテキストで簡単に呼び出せるようになり、外部API連携などの自動化が一層容易になりました。
なお、2025年9月のアップデートにより、GPT-5 CodexもAPIキーでの直接利用が可能になりました。CodexモデルはResponses API限定で提供され、GPT-5と同一価格での課金体系が適用されます。
コーディング支援・スクリプト生成など、開発者向けのユースケースで最も高い安定性を発揮します。
ChatGPT-5の活用事例

ChatGPT-5は、アプリ版のChatGPTでもAPI経由でも、同じコアモデルを利用できます。ここでは代表的な活用事例を4つご紹介します。
ノーコードでマルチモーダルアプリを構築
OpenAIの公式デモでは、プロンプト「夢を記録し、夢に合ったサウンドスケープと画像を生成するアプリを作って」と入力するだけで、Reactコード、画像生成機能、音楽プレーヤーのUIまで含む「Dreamscape Tracker」というアプリを数十秒で自動生成しています。
この機能により、非エンジニアでもアイデアを即座に動くプロトタイプへと落とし込み、フロントエンドのデザインやユーザー体験を実際に確認しながら、効率的に反復開発できるようになります。
シーンに合わせたスピーチ原稿の自動作成
例えば、結婚式の友人代表スピーチを依頼された際に、メモを添付して「より感動的なトーンで書き直して」と指示すると、GPT-5は「序破急」の構成や情緒的表現を織り込んだスピーチ原稿を提示します。さらに修正を指示すると、即座にリライトも可能です。
これにより、プロのライターに依頼しなくても、短時間で聴衆の心に響くスピーチを作成でき、修正もリアルタイムで反映されるため準備の負担を大幅に軽減できます。
医師とのフォローアップを支援する健康アドバイス
「スタチンを処方されたので質問リストを作ってほしい」とリクエストすると、GPT-5は最新の臨床ガイドラインに基づき、〈妊娠計画〉〈想定される副作用〉〈目標LDLに到達しない場合の追加治療〉などの具体的な質問例を提示します。
また、薬の作用メカニズムや食事の注意点などを図解付きで整理できるため、診察を受ける前に重要なポイントを把握し、不安を軽減するための「意思決定パートナー」として役立ちます。
画像を使ったリアルタイム植物診断
観葉植物の葉が黄色く変色した写真をアップロードし相談すると、GPT-5は画像による植物種の誤認リスクを注意喚起したうえで、「水の与えすぎ」や「根詰まり」など、可能性の高い原因を優先度順に示します。さらに土壌の乾燥状態チェックや植え替え時期の判定方法も提案します。
文字による説明と併せてチェックリストの生成もできるため、園芸初心者でも具体的な対処方法をすぐに実行できます。
まとめ
ChatGPT-5は、高速応答と深い推論を両立したAIモデルです。リアルタイムでモデルを切り替えるルーター機能により、複雑なタスクも快適に処理可能です。
新ベンチマークを採用し、事実誤認やハルシネーションを従来比で大幅に改善しました。また、用途やコストに応じた複数モデルや柔軟な料金プランを用意。
2025年10月のアップデートでは、メンタルヘルスに関わる会話への対応が大きく見直され、より安全に利用できるようになりました。
専門的なコーディング、医療分野の意思決定支援、マルチモーダルアプリ開発まで幅広く活用でき、実務における信頼性を飛躍的に高めています。