

Gemini 2.5 Flash‑Liteは、Googleの最新・軽量AIモデルです。
高速な応答と低コストで、PoC(概念実証)・試作・定型業務の自動化に向いています。
さらに「Thinking(推論)機能」のON/OFFを切り替えることで、推論の精度と料金のバランス調整も可能です。
本記事では、Gemini 2.5 Flash‑Liteの特徴や料金体系、さらには導入手順や活用事例までわかりやすく解説します。
GoogleのGeminiとは?

Geminiとは、Googleが開発した生成AIモデル群の名称で、以下のような機能に幅広く対応する次世代AIです。
- テキスト生成
- コードの補完
- マルチモーダル処理(画像や音声との連携)
Geminiシリーズは2023年12月に最初にリリースされ、2025年6月には、最速・低コストな「Gemini 2.5 Flash‑Lite」が追加されています。
大規模な推論をしないシーンや、試験導入などで特に活躍が期待されるものです。
Geminiシリーズの詳細については、別記事「GoogleのGeminiとは?」で全体像を紹介していますので、ぜひそちらもあわせてご覧ください。

Gemini 2.5 Flash-Liteとは?3つの特徴を解説

Gemini 2.5 Flash-Liteは、速度と価格を重視する際に最適な新しいモデルです。
それを実現できる技術的な理由や、他のGeminiモデルとの違いを紹介しつつ、Flash-Liteの価値を解説します。
「最速・最安」を実現できる要因
Gemini 2.5 Flash-Liteの「最速・最安」を実現した要因は、その構造と処理設計です。
このモデルは、従来の高性能モデルよりもパラメータ数を抑えており、メモリ消費やレイテンシ(応答時間)を大幅に削減しています。
これにより、クラウド上での高速処理と低コスト運用が可能になりました。
さらにFlash-Liteでは、計算負荷の高い推論処理(Thinking)をON/OFFできる構造を採用しています。
これによって重要な処理だけを高精度で行い、それ以外は高速・低コストで済ませられるようになりました。
Flash-Liteは、次のようなプロジェクトに適したモデルと言えます。
- コスト重視のプロダクト開発
- AI導入初期の検証段階
Flash-LiteとFlash/Proとの違いを比較
Gemini 2.5シリーズには、「Flash-Lite」「Flash」「Pro」の異なる性質の3種類があり、用途に合わせてモデルを選ぶことが大切です。
以下に、各モデルの違いをわかりやすく比較した表を掲載します。
| モデル名 | 処理速度 | 精度 | Thinking対応 | コスト 1Mトークンあたり | 主な用途例 |
|---|---|---|---|---|---|
| Flash‑Lite (プレビュー) | 非常に速い | 最小限 | ON/OFF可能 | 入力 $0.10 出力 $0.40 ※無料枠あり | 簡易チャット 低負荷テスト運用 |
| Flash | 速い | バランス型 | ON/OFF可能 | 入力 $0.30 出力 $2.50 ※AI Studioのみ無料枠あり | 情報検索 軽めの文章生成 |
| Pro | やや遅い | 非常に高精度 | 常時ONのみ | ■200Kトークン未満 入力 $1.25 出力 $10.00 ■200Kトークン以上 入力 $2.50 出力 $15.00 | 複雑な推論 文脈理解 創作タスク |
- 導入前のPoC(概念実証)/チャットbotの試用:Flash‑Lite(素早く・低コストで検証できる)
- 情報検索/メール作成/ドキュメント作成 : Flash(文脈処理と速度のバランスが取れている)
- 創作/分析/複雑な判断 : Pro(高度な推論力がある)
上記の選び方例に目的が当てはまれば、まずはそのモデルを試してみましょう。
Gemini 2.5 Flash-Liteの料金|Thinking機能の活用法

料金プランを理解せずにGemini 2.5 Flash-Liteを使うと、思わぬコストアップになる可能性があります。
深い推論を行う「Thinking(推論)機能」のON/OFFによる料金の違いや、コストを抑えるための設定方法もあわせて解説しましょう。
無料枠とプレビュー料金のしくみ
Gemini 2.5 Flash-Liteには、「無料枠」と「プレビュー料金」という2つの料金体系があります。
プレビュー料金は、入力トークンが1Mあたり$0.10、出力トークンは$0.40となっており、運用前の検証を低コストで行えるため、導入時のハードルを下げることができます。
無料枠は、負荷が少ない処理であれば十分運用可能で、小規模なプロトタイプや初期段階の検証にも適しています。AI Studioではクレジットカード登録なしで利用できるという利点もあります。
ただし、トークン数に上限があるため、商用や長期的な利用には不向きです。特にThinkingがONになるような負荷の高い処理では、すぐに枠を超過してしまう可能性があります。また、提供条件が変更されることがあるため、常に最新の仕様確認が必要です。
一方のプレビュー版は、正式リリース前の割安価格で高性能なモデルを利用できます。ThinkingのON/OFF切り替えによってコストと精度を柔軟に調整でき、商用利用や実運用に近い検証が可能になります。
しかし、プレビュー期間中は価格体系が予告なく変更されるリスクがあり、期間終了後には料金が上昇する可能性もあります。さらに、サービス仕様自体が安定していないケースもあり、業務用途では注意が必要です。
まず無料枠で試し、その後、検証やPoC段階でプレビュー料金に移行するという段階的な利用方法が現実的でしょう。
Thinking(推論)ON/OFFによる価格や性能の違い
Gemini 2.5 Flash-Liteでは、「Thinking(推論)」という機能をONとOFFで切り替えられます。
この設定を変えるだけで、応答の速さ・答えの正確さ・料金が大きく変わるのが特徴です。
| OFF | ON | |
|---|---|---|
| 特徴 | 軽く・速く・安く使える | より深く考えた答えが返ってくる |
| 精度 | やや低め | とても高い |
| 速度 | とても速い | 少し遅い |
| 料金(1 Mトークンあたり) | 少し高い | |
| 向いている使い方 | 簡単な質問や定型文の返答など | 複雑な質問、創作、判断が必要な場面など |
以下のように、使い分けられます。
- 「早く・安く」で済ませたいとき:OFF
- しっかり考えた答えがほしいとき:ON
目的に合わせて切り替えて、費用と性能のバランスを上手にとりましょう。
Gemini 2.5 Flash-Liteの操作手順ガイド

「Gemini 2.5 Flash-Liteを試してみたいけど、どこから始めればいいの?」という方向けの導入ガイドです。
Vertex AIとGoogle AI Studio、それぞれのプラットフォームでFlash-Liteを使う方法を、丁寧に紹介します。
Vertex AIでの利用方法
ここからは、Vertex AIでFlash-Liteを使う方法をステップで紹介しましょう。
Google Cloud Consoleからライブラリにアクセス
まずGoogle Cloud Console(https://console.cloud.google.com/)に接続し、「APIとサービス」タブ→「ライブラリ」を選択します。
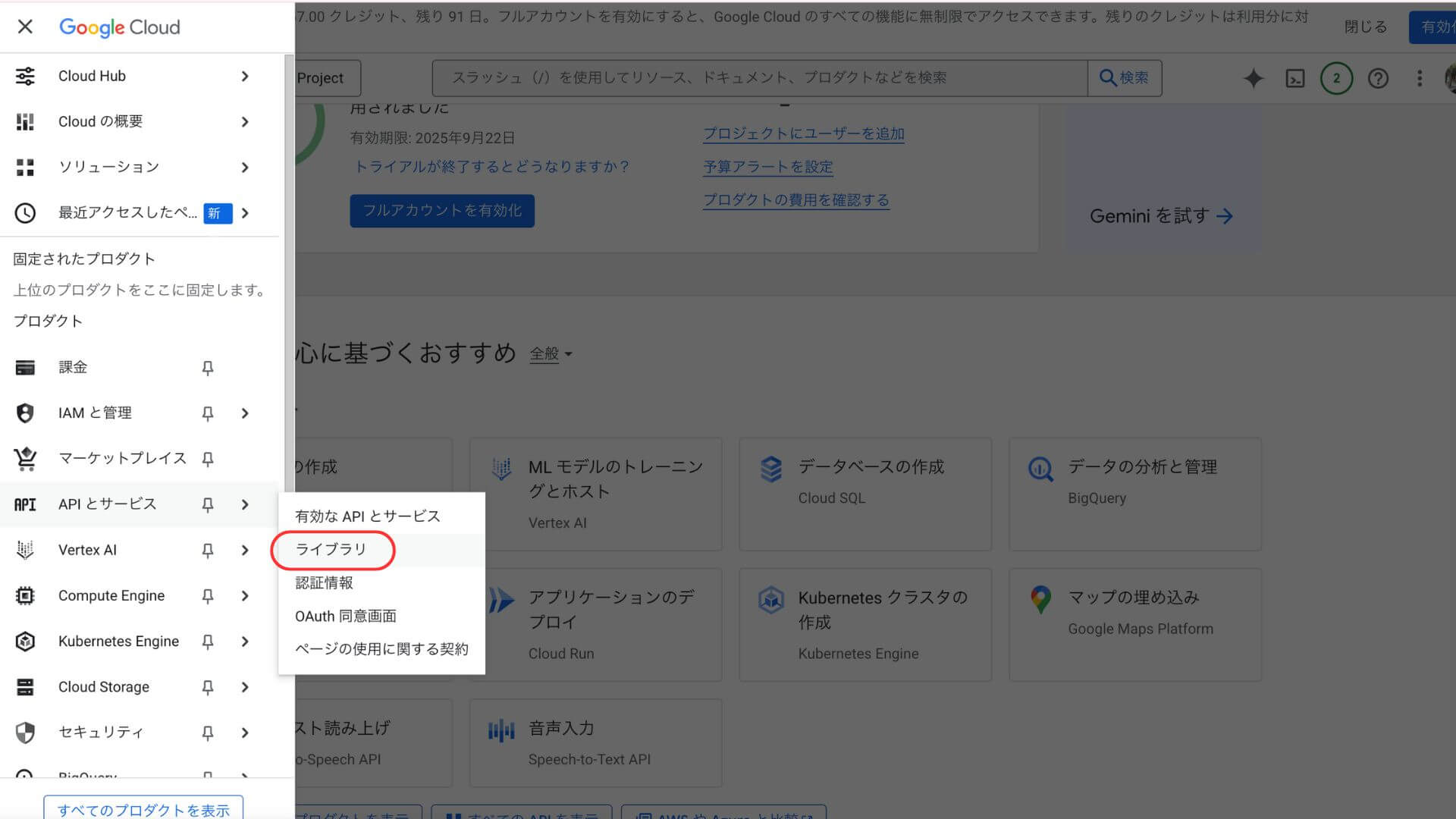
「VERTEX AI API」と検索窓に入力し、検索する
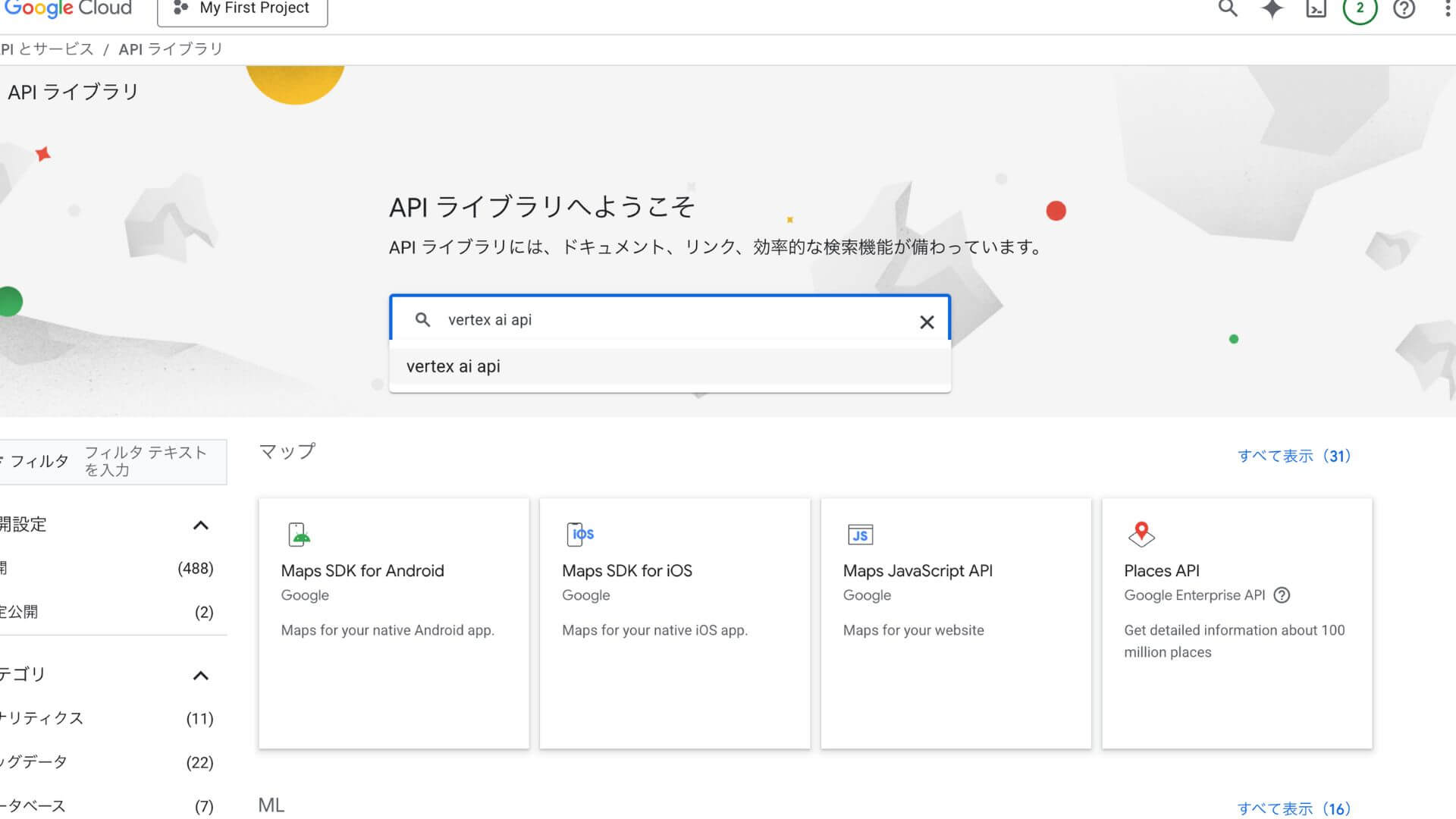
表示された検索結果から「Vertex AI API」をクリック
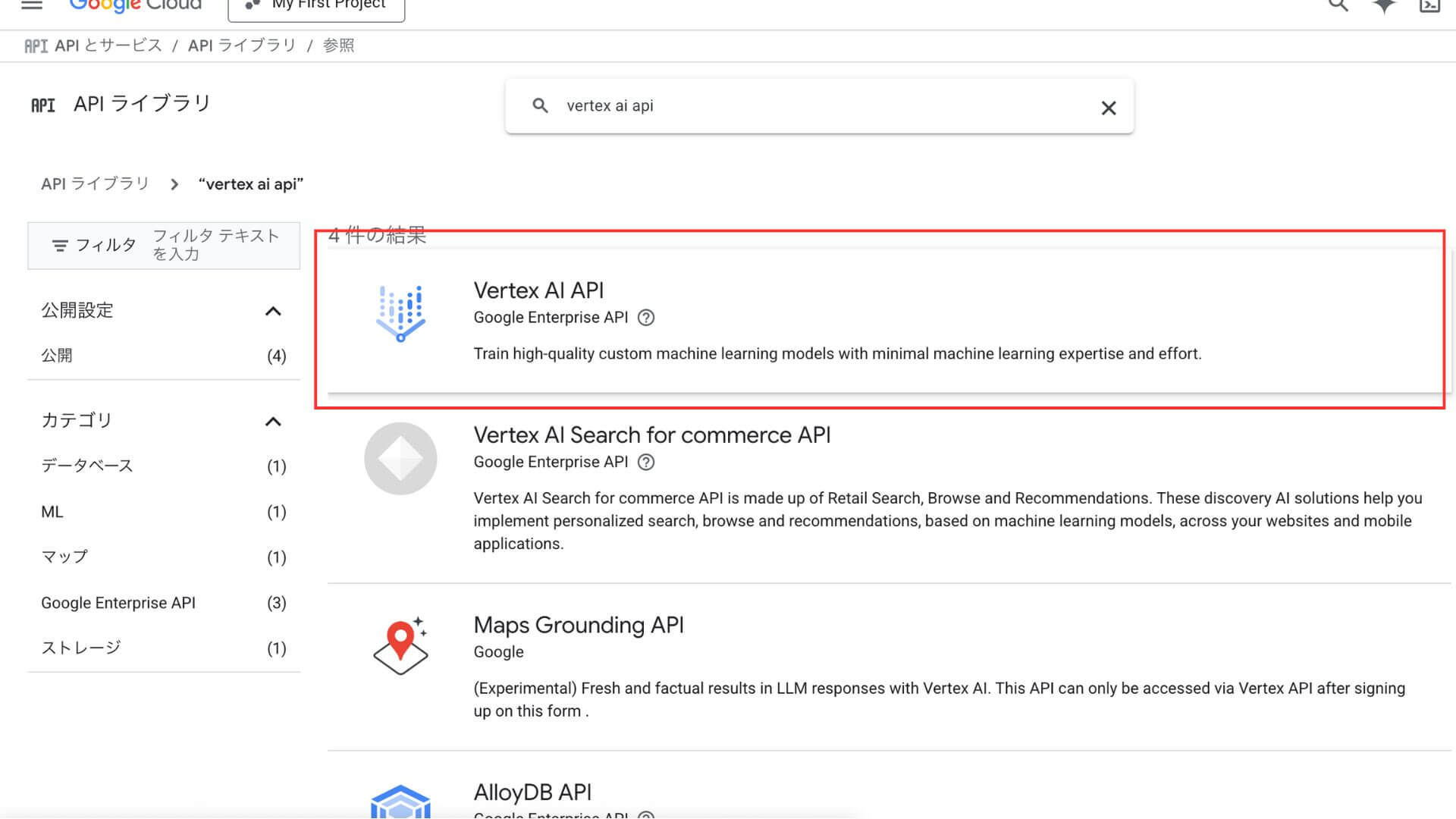
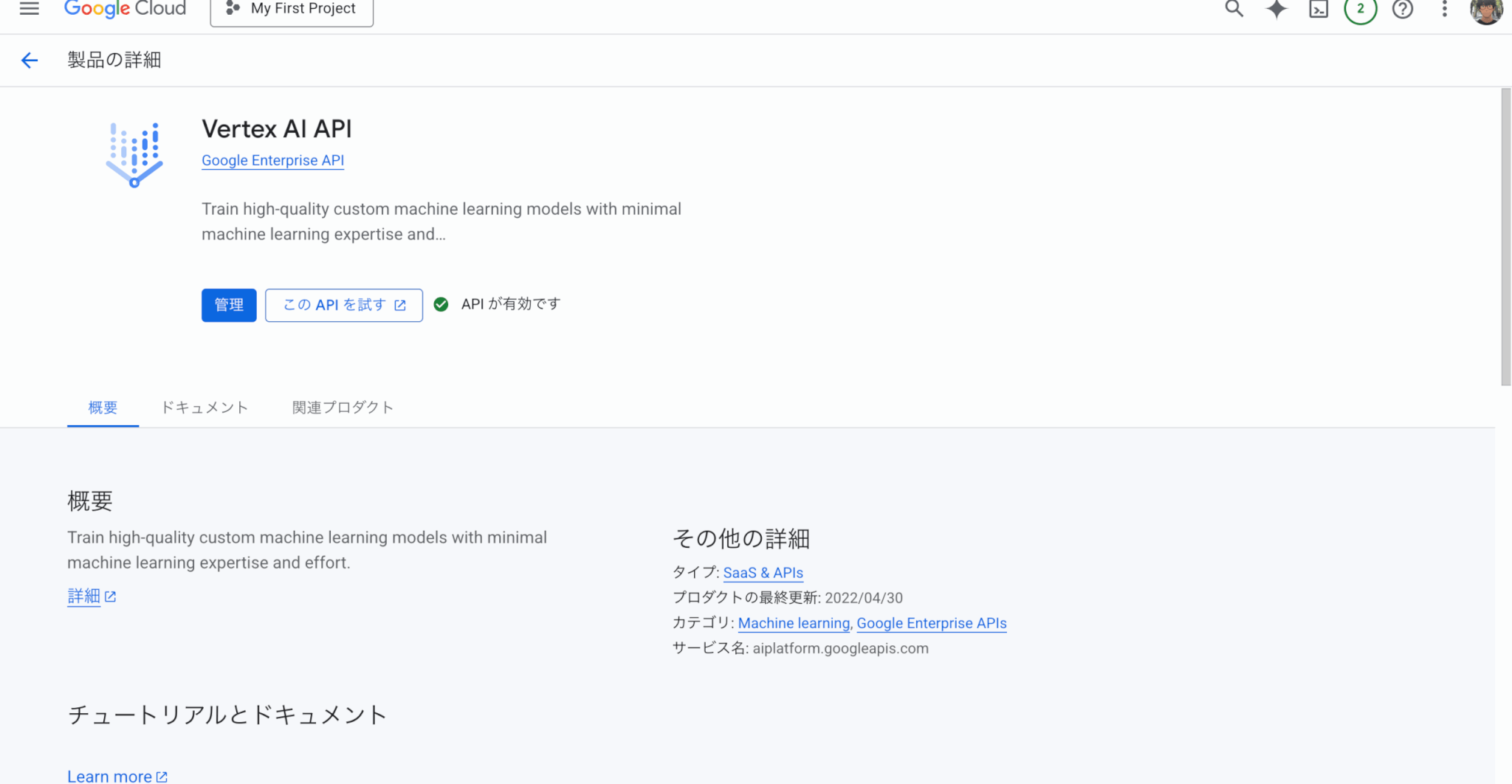
「管理」から「Vertex AI API」を有効にする。「APIが有効です」と表示されればOK
メニューから「APIとサービス」タブ→「認証情報」を選ぶ
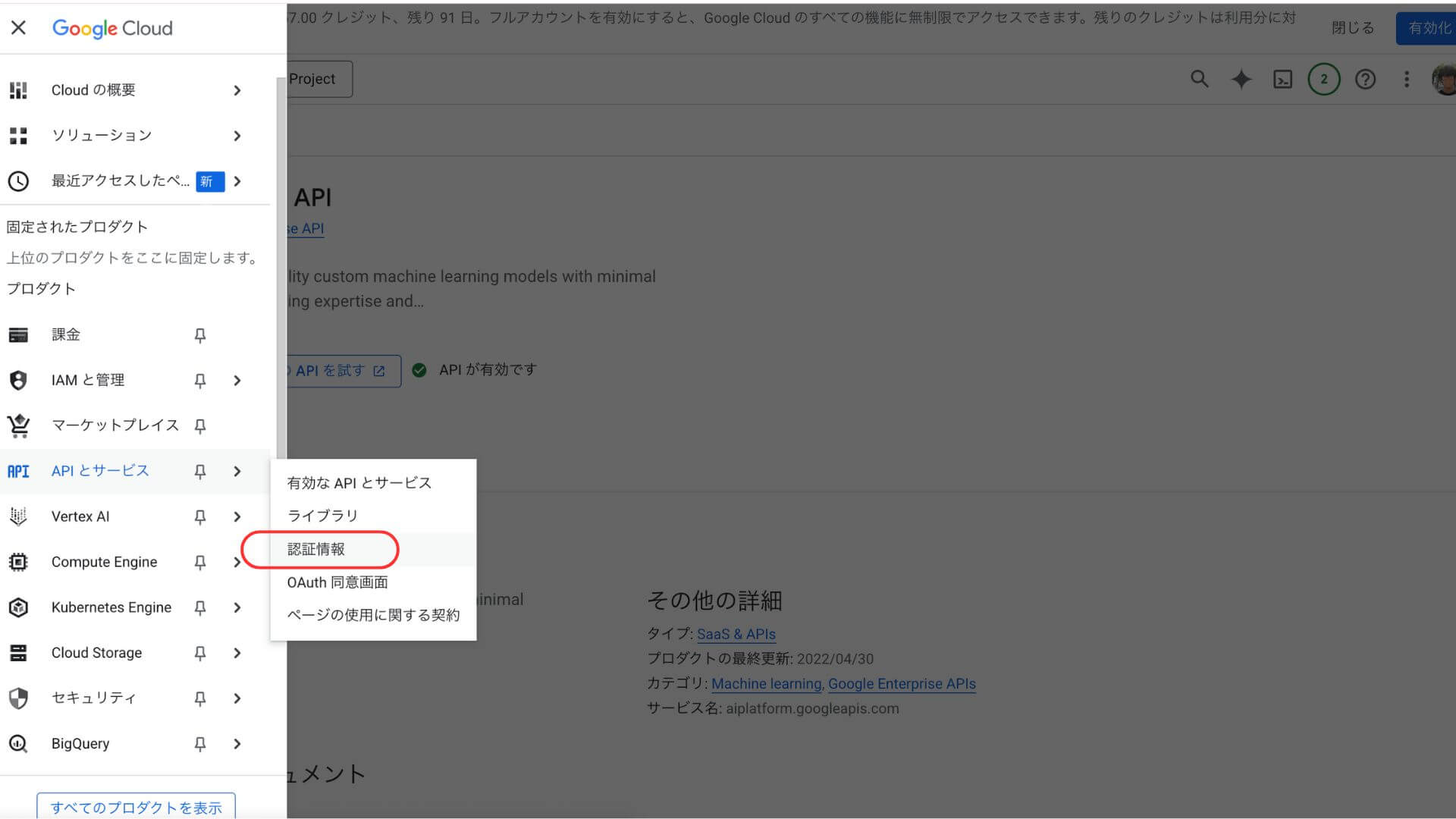
「+認証情報を作成」からAPIキーを作成し、コピーする
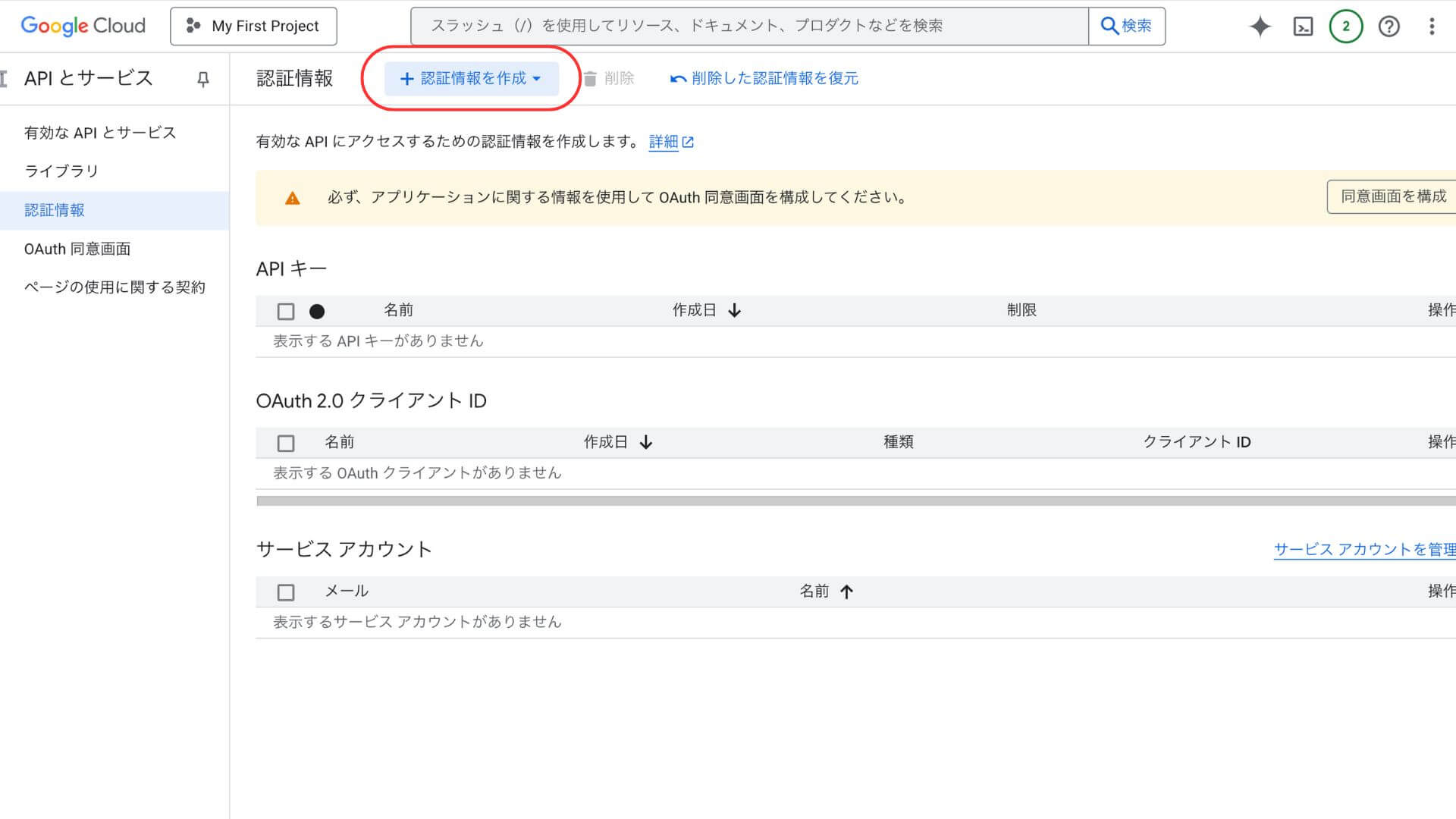
メニューから「Vertex AI」タブ→「Model Garden」を選択
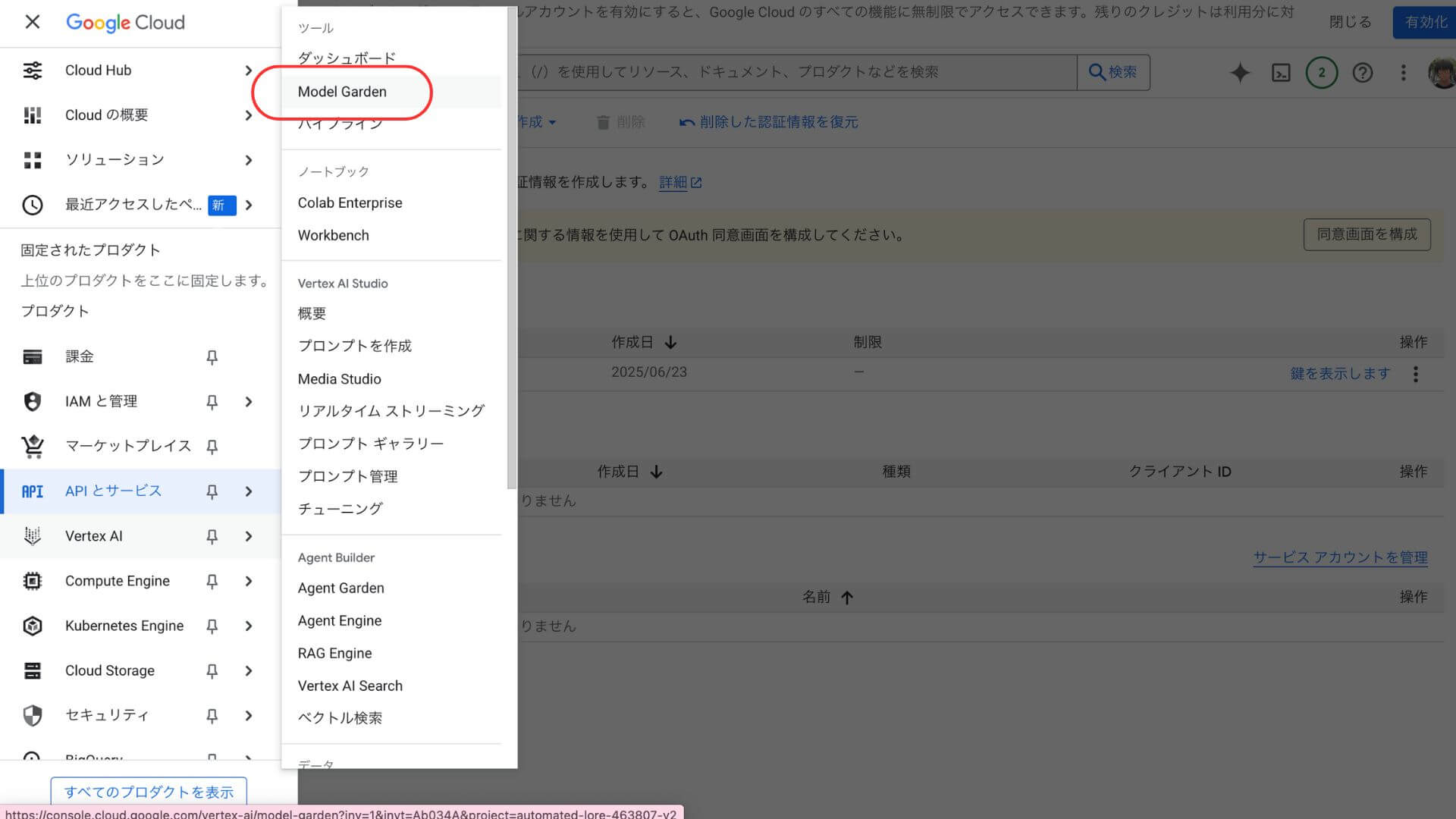
基盤モデルで「Gemini 2 5 Flash-Lite」を選択
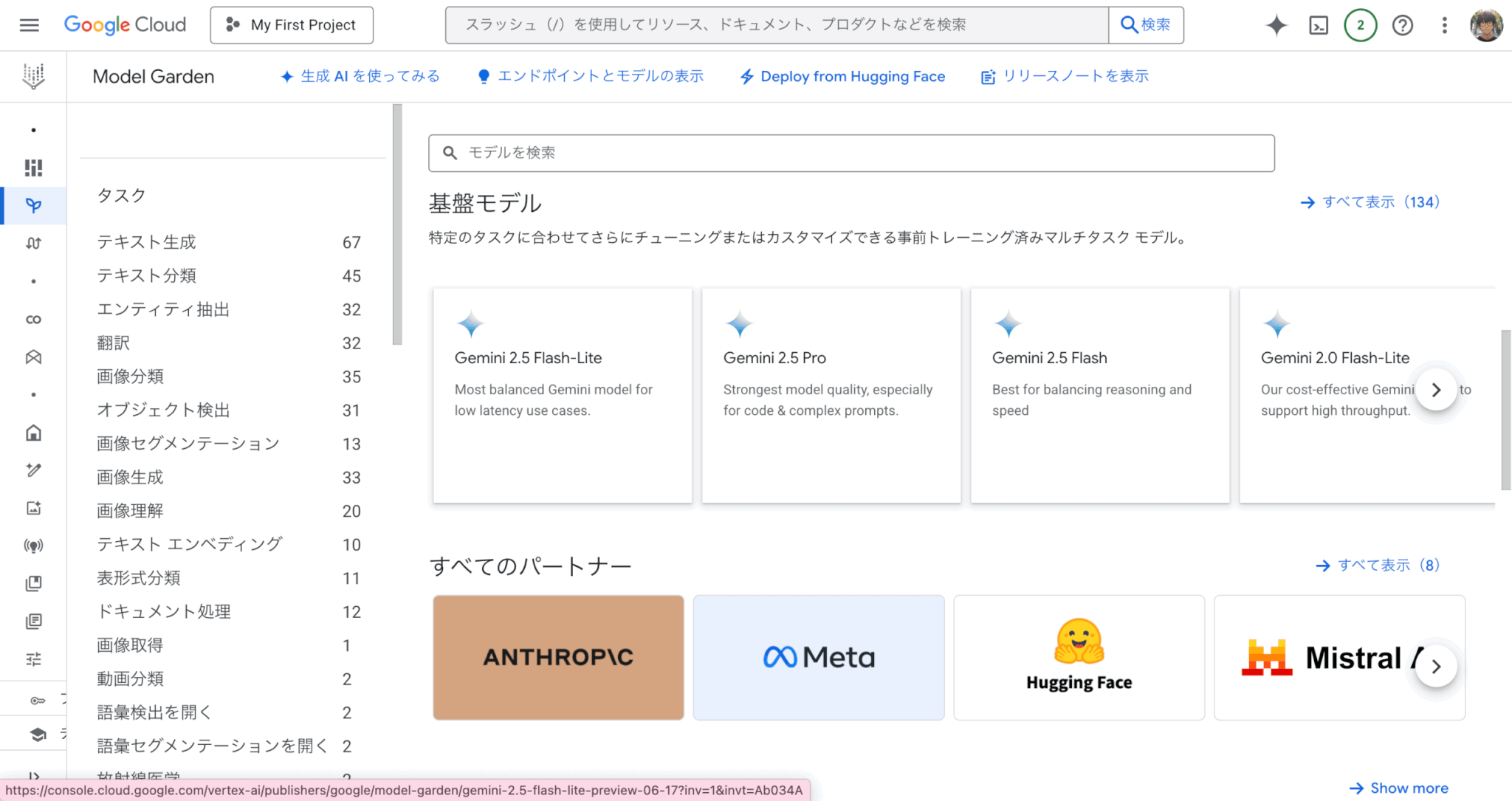
遷移したページの真ん中あたりの「Open Vertex Al Studio」をクリック
これでFlash-Liteを使えるようになりました。
Google AI Studioでの利用方法
次に、Google AI Studioで利用する方法です。
Google AI Studio(https://aistudio.google.com/prompts/new_chat)に接続し、ログインをしてください。
右上のプルダウンから「Gemini 2.5 Flash-Lite Preview 06-17」を選択します。
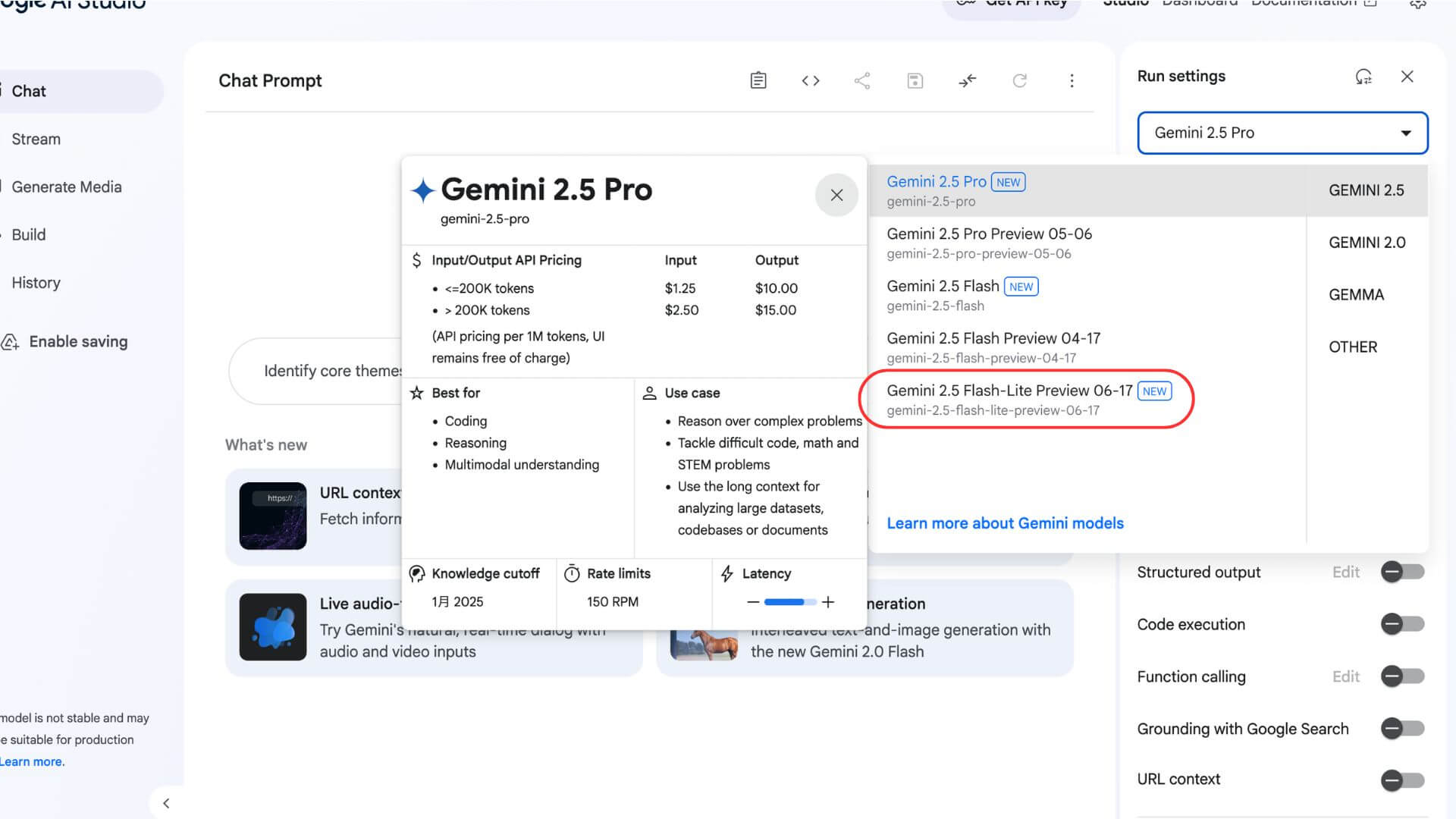
これで完了です。
Thinking設定の切り替え手順とベストプラクティス
Thinking設定のON/OFF切替は、トグルボタンひとつで可能です。
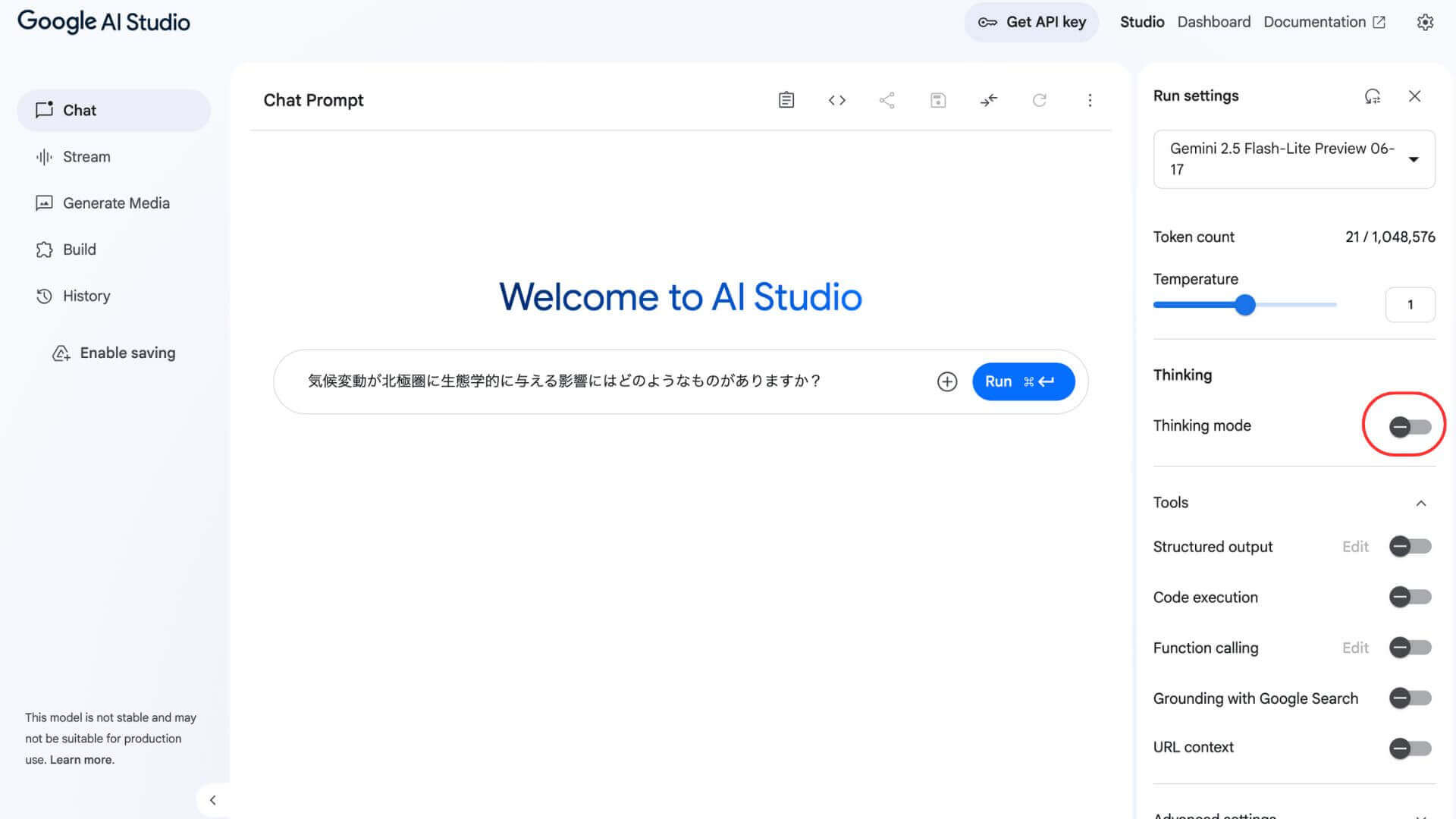
Thinking設定のON/OFFは、場面によって使い分ける必要があります。
ベストプラクティス(適切な使い分け)の例一覧です。
- 簡単なやり取りはOFF
-
FAQや定型応答など、精度が不要な場面ではOFFにして費用を節約する
- 重要な分析や創作はON
-
複雑なリクエスト、創造性が必要なケースではON。より深い推論ができるようにする
- A/Bテストで比較
-
実際にON/OFFで出力や費用がどれだけ変わるか試し、場面によってベストバランスを見つける
- 定期的に見直す
-
リクエスト傾向や費用に合わせて、月1回など定期的に振り返る
これらにより、ムダな消費を抑え、成果につながる使い方が可能になります。
必ずON/OFFによる出力・速度・料金を比較し、納得できる運用ルールを作りましょう。
まずはAI Studioから無料で試してみよう
Gemini 2.5 Flash‑Liteは、Google AI Studioから無料枠を使ってすぐに試せます。
Thinking(推論)機能のON/OFF切り替えもワンクリックのため、応答速度や精度がどのくらい変わるのか、簡単に比較可能です。
導入前に気になるユースケースでテストしておけば、コストをかけずにベストな使い方を見つけやすくなります。
気軽に触って感触を確かめたい方は、まずAI Studioから試してみるとよいでしょう。

Gemini 2.5 Flash-Liteの使い方は?ケース別の使用例とモデル選定表
業務の内容や求める精度によって、選ぶべきモデルは異なるものです。
ここでは、代表的なユースケースごとに最適なモデルの選び方を紹介し、Flash-Liteの活用シーンを示します。
社内PoC・チャットボット・プロトタイプなどの活用例
Gemini 2.5 Flash-Liteは軽量・低価格なため、実用導入の前段階であるPoC(概念実証)や、開発初期のプロトタイプ用途に向いています。
たとえば「社内の業務フローを自動化するチャットボット」を試作したい場合、Flash-LiteならThinkingをOFFにすれば、ほぼ無料でやり取りの動作確認が可能です。
また、音声や画像と組み合わせるようなマルチモーダル系のPoCにも、まずは軽いテキストベースの出力で挙動を確認するために、Flash-Liteが選ばれることもあります。
実際の本番運用ではより高精度なFlashやProに移行するとしても、初期段階の仮説検証には十分です。
このような「少ないリスクとコストで早く動かしてみたい場面」に、Flash-Liteは非常に向いています。
Thinking(推論)の使い分けによるコスト最適化パターン
Thinking(推論)のON/OFF使い分けをすれば、Gemini 2.5 Flash-Liteの高精度の出力を得ながら、全体費用を抑えられます。
定型的な挨拶や簡単な回答ではThinking(推論)はOFFで稼働させることがおすすめです。
- チャットボットの「こんにちは」「わかりました」などの定型的な挨拶・返答
- よくある質問への単純な回答(例:「営業時間は?」)
- メニューの選択肢表示やリンク誘導など、決まった情報の出力
一方で、Thinking(推論)をONにすることで、より複雑な回答を求める場合に精度が向上します。
- 複雑な内容を含む手続き案内
- 自由記述入力への自然な応答/要約
- 文脈をまたいだ質問への対応(過去発言の参照など)
このように、処理内容によってThinkingのON/OFFを切り替えることで、ムダな演算コストを抑え、品質と効率の両立が可能です。
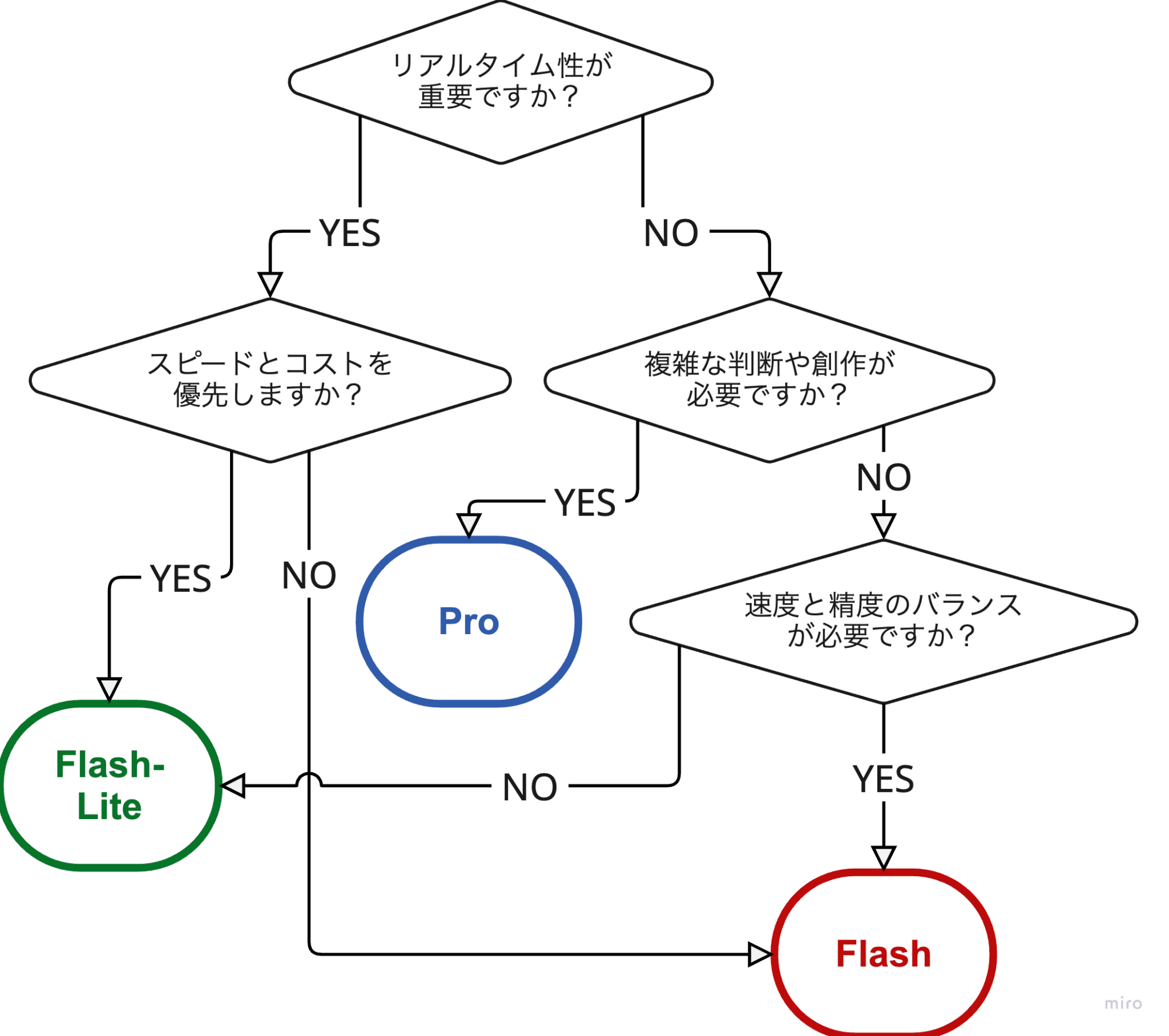
目的別|Pro・Flash・Flash-Liteの選定フローチャート
使い方や目的に合わせた、おすすめモデルを簡単に選べるフローチャートを用意しました。
自分のケースに合ったモデルを見つけてみましょう。
まとめ
Gemini 2.5 Flash‑Liteは、高速かつ経済的に使える「新世代の生成AIモデル」です。
試作や簡単なチャットボットにはThinking OFF、本格的な分析や応答にはThinking ONと、用途に合わせて運用できます。
無料枠があるので導入リスクも低く、料金は1Mトークンあたり$0.50からとリーズナブルです。
「まずは手軽に試したい」「ムダなコストをかけたくない」という方は、AI Studioから触ってみましょう。
Gemini 2.5 Flash‑Liteを活用して、業務とサービスの可能性をさらに広げてみてください。