

ChatGPT o1は、OpenAIが2024年に発表した最新のAIモデルで、従来のGPT-4oを上回る高度な推論力と柔軟な性能が大きな特徴です。
本記事では、ChatGPT o1の使い方やGPT-4oとの違い、さらに料金プランや性能について詳しく解説します。
AI技術を効果的に導入し、業務効率化やコスト削減を目指す方にとって有益な内容ですので、ぜひ最後までご覧ください。
ChatGPT o1とは?機能や特徴を紹介

ChatGPT o1は、OpenAIが発表した新たなAIモデルであり、複雑な問題解決に特化した高度な推論能力が特徴です。
この章では、ChatGPT o1の基本概要や、どのような仕組みで動作するのかを詳しく紹介します。
ChatGPT o1の概要
ChatGPT o1は、複雑な問題解決のために設計された、新しいAIモデルシリーズです。
従来のモデルよりも深く思考し、より難しい問題を論理的に解決できる点が特徴です。
特に科学、コーディング、数学の分野において優れた能力を発揮します。
動作原理
ChatGPT o1は、人間のように、回答を生成する前に問題についてじっくり考えるようにトレーニングされています。
トレーニングを通して思考プロセスを洗練させ、様々な戦略を試しながら、ミスを認識し修正することを学習していきます。
推論能力
ChatGPT o1の推論能力は、様々な分野で目覚ましい成果をあげています。
数学とコーディングにおいても優れた能力を示し、国際数学オリンピック(IMO)の予選試験では、従来のGPT-4oが13%しか正解できなかった問題を、o1は83%も正解しました。
コーディング能力を測るCodeforcesコンテストでも上位89%にランクインするなど、その実力は折り紙付きです。
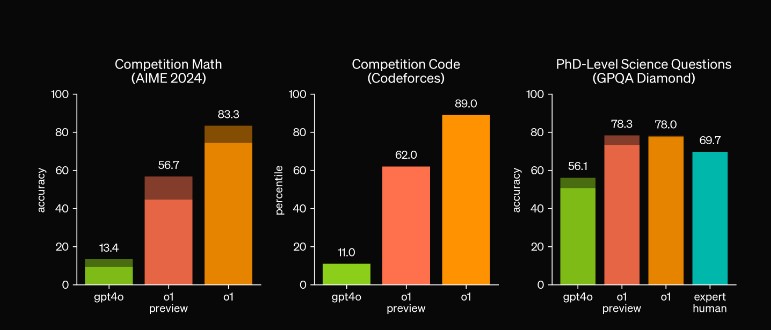
ChatGPT o1は、広範なベンチマークにおいてGPT-4oを凌駕する結果を出しています。
例えば、アメリカの優秀な高校生を対象とした数学試験AIMEでは、問題あたり1つのサンプルで平均74%、64個のサンプル間のコンセンサスで83%、学習済みスコアリング関数で1000個のサンプルを再ランク付けすると93%という驚異的な正解率を達成しました。
このスコアは全国上位500人の学生に相当し、USA Mathematical Olympiadのカットオフも超えています。
また、化学、物理学、生物学の専門知識をテストする難しい知能ベンチマークGPQA diamondでは、博士課程の学生に匹敵する成績を取得しました。
さらに、視覚認識機能を有効化したo1モデルは、MMMUでは78.2%のスコアを記録し、人間の専門家と競合できる最初のモデルとなっています。
コーディング能力
ChatGPT o1は、プログラミング能力の面でも目覚ましい成果を上げています。
2024年国際情報オリンピック(IOI)では、o1から初期化してトレーニングされたモデルが213点という高得点をマークし、49パーセンタイルにランクインしました。
このモデルは、人間と同じ条件下で6つの難しいアルゴリズムの問題を10時間以内に解き、問題ごとに最大50回の提出を行いました。
IOIの公開テストケース、モデル生成テストケース、学習済みスコアリング関数のパフォーマンスに基づき最適な提出物が選択され、ランダムに提出した場合と比べて約60ポイントも高いスコアを獲得。
さらに、問題ごとに10,000件の提出を許可した場合には、テスト時の選択戦略を用いなくても362.14点という、金メダル獲得レベルのスコアを達成しています。
また、Codeforcesが主催する競技プログラミングコンテストにおいても、ChatGPT o1は優れた性能を発揮しています。
競技規則に準拠した評価において、10回の提出が許可された結果、1807のEloレーティングを達成し、競技者の93%を上回るパフォーマンスを示しました。
これは従来のGPT-4oのEloレーティング808をはるかに凌駕するものであり、o1の高いコーディング能力を示す結果と言えるでしょう。
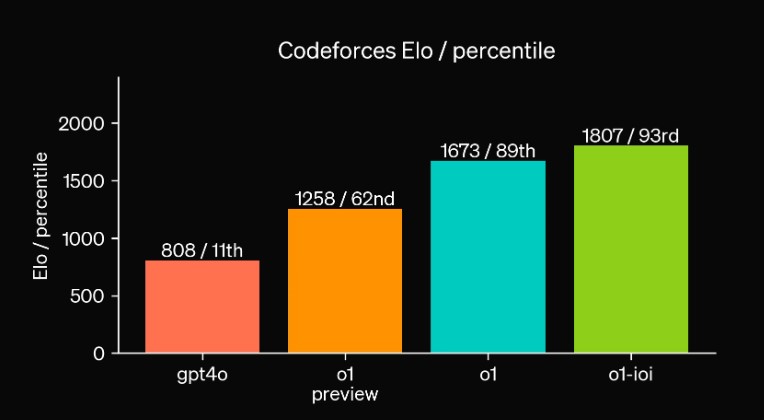
思考連鎖
ChatGPT o1は、人間が難しい問題を考えるのと同様に、思考連鎖を用いて問題を解決可能です。
問題を段階的に分解し、それぞれの段階で推論を積み重ねていくことで、最終的な答えを導き出します。
強化学習を通じてChatGPT o1は思考連鎖を洗練させ、より効果的な戦略を用いることを学習し、思考過程で発生する間違いを認識し修正することも学習します。
難しい問題に直面した場合、別のアプローチを試すなど、柔軟な思考を可能にするのです。
ChatGPT o1は、暗号解読、コーディング、数学、クロスワードパズル、英語、科学、安全性、健康科学など、様々な分野の問題に対して思考連鎖を用いることができます。
例えばクロスワードパズルの場合、4oは即座に回答するのに対して、o1は思考を連鎖させ、自発的にステップごとに考えています。
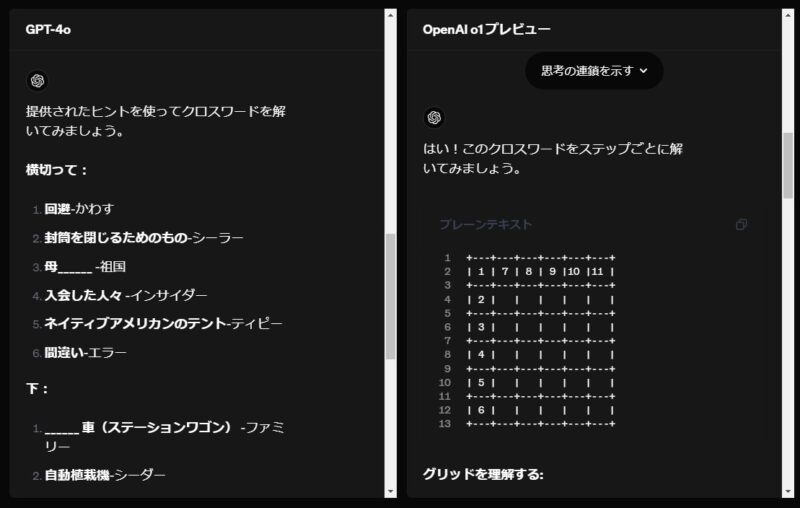
安全性
ChatGPT o1は、高度な推論能力を安全かつ倫理的に利用できるよう設計されています。
安全と整合性のガイドラインを遵守させる新しい安全トレーニングアプローチと、文脈に応じた安全ルールの推論を可能にすることで、より効果的にルールが適用されます。
ユーザーが安全ルールを回避(ジェイルブレーク)しようとした場合のテストでは、最も難しいテストにおいてもGPT-4oが22点であったのに対し、ChatGPT o1は84点という高いスコアを記録しました。
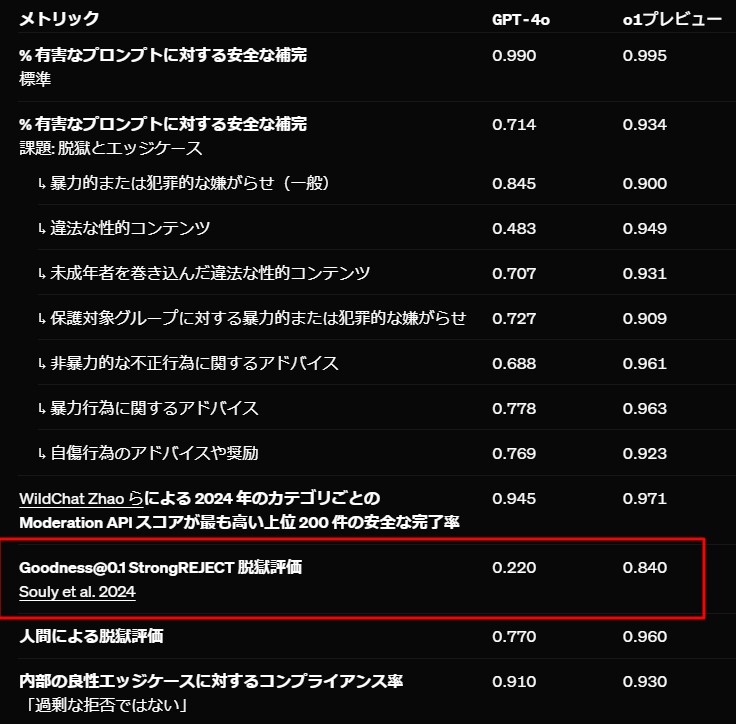
ChatGPT o1の開発チームは、モデルの新しい能力に合わせて安全性に関する取り組み、内部ガバナンス、連邦政府との連携を強化。
Preparedness Frameworkを用いた厳格なテストと評価、クラス最高のレッドチーミング、安全性とセキュリティ委員会によるものを含む取締役会レベルのレビュープロセスなどを実施することで、安全性の確保に努めています。
さらに、米国および英国のAI安全研究所と正式に契約を締結し、研究所にこのモデルの研究バージョンへの早期アクセスを許可するなど、AI安全性の確保に向けた取り組みを積極的に進めています。

コンテキストウィンドウ
ChatGPT o1は、200,000トークンというコンテキストウィンドウを提供します。
これにより、AIモデルは過去の会話や情報を記憶でき、文脈に沿った応答が生成可能です。
ただし、各補完には出力トークン数の上限があり、非表示の推論トークンと可視補完トークンの両方を含めて、最大100,000トークンまでとなっています。
| モデル | コンテキストウィンドウ | 最大出力トークン |
|---|---|---|
| o1 | 200,000 | 100,000 |
| o1-mini | 128,000 | 65,536 |
| o1-preview | 128,000 | 32,768 |
ChatGPT o1の性能面での強み
ChatGPT o1は、推論能力や安全性、信頼性の向上など、さまざまな性能面でGPT-4oを大きく上回る特徴を持つモデルです。
この章では、公式データをもとに、o1の優れた推論能力、幻覚(ハルシネーション)の抑制、公平性の向上といった具体的な強みを詳しく解説します。
推論能力の向上
OpenAI o1は、チェーン・オブ・ソート推論(思考連鎖推論)を文脈内で実行することで、複雑な課題を段階的に解決し、高い推論能力を発揮します。
これは、Open AI社が提示する下記の文章からも読み取り可能です。
OpenAI o1 performs chain-of-thought reasoning in context, which leads to strong performance across both capabilities and safety benchmarks.
訳:OpenAI o1は、文脈内でのチェーン・オブ・ソート推論を行い、能力および安全性評価の両方で強力なパフォーマンスを示しています
出典:OpenAI o1 System Card
この仕組みにより、長い文章や複雑な質問にも論理的かつ正確な回答を生成でき、従来のモデルと比較して大幅な性能向上が実現しています。
例えば、業務で多段階の意思決定が必要な場合、初期の質問を解釈しながら連続的に一貫性のある回答が出力可能です。
さらに、この性能はエラーを最小限に抑えるだけでなく、業務の効率化や課題解決を進める重要な役割を果たします。
幻覚(ハルシネーション)の削減
OpenAI o1は、幻覚(ハルシネーション)の発生を効果的に抑える点で優れた性能を示しています。
幻覚とは、AIが誤った情報や事実と異なる回答を生成する現象を指し、高い精度が求められる業務では大きな課題です。
Open AI社のシステムカードによると、o1は、GPT-4oと比較して幻覚の発生頻度が低いことが示されています。
According to these evaluations, o1-preview and o1 hallucinate less frequently than GPT-4o.
訳:これらの評価によると、o1-previewとo1はGPT-4oよりも幻覚の発生頻度が低いです
出典:OpenAI o1 System Card
これは下の表からも読み取ることができます。
例えば、短い質問の正確性と幻覚率を測る「SimpleQA」において、GPT-4oの幻覚率は0.61ですが、o1では0.44と大幅に削減されていることが分かります。
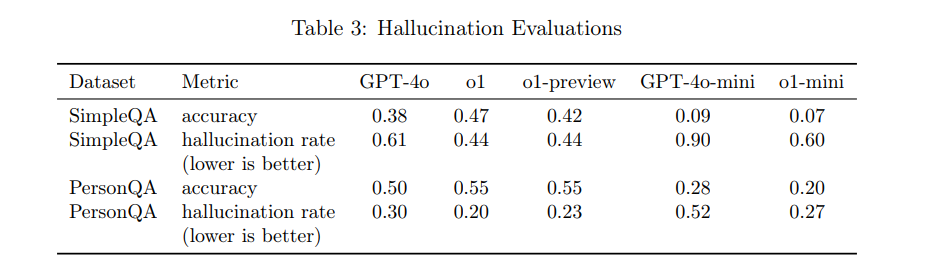
同様に、人名や人物情報に関する質問の正確性と幻覚率を測る「PersonQA」データセットでも、幻覚率がGPT-4oは0.30であるのに対し、o1は0.20と低く、実際の応答精度が向上していることが示されています。
これにより、o1は信頼性が重要視されるタスクや複雑な質問対応において、より正確な回答を生成できるAIモデルとして高い実用性を持つといえるでしょう。
公平性の向上
Open AI o1-previewはGPT-4oと比較してステレオタイプな選択を回避する傾向が強く、公平性の面で大きな改善を示しています。
Open AI社の提示する文書にも、次のような1文が書かれています。
We find that o1-preview is less prone to selecting stereotyped options than GPT-4o.
訳:o1-previewは、GPT-4oよりもステレオタイプな選択をする傾向が少ないことが分かりました
出典:OpenAI o1 System Card
これは、実験結果からも読み取ることができ、曖昧な質問を使った「Ambiguous Questions」では、GPT-4oのステレオタイプ回避率が0.06に対し、o1は0.05と高い数値を記録しました。

また、非曖昧な質問(Unambiguous Questions)への精度もo1およびo1-previewでは0.93から0.94と高水準を維持し、精度と公平性を両立している点が評価されています。
これは、AIがバイアスを抑えて中立的かつ信頼性の高い回答を提供することで、誤解を生むリスクを大幅に低減していることを示しています。
これにより、o1は教育分野やビジネスの意思決定支援など、多様な場面で公平かつ透明性のあるソリューションを提供できるモデルとして注目されました。
ChatGPT o1の性能面での弱み

ChatGPT o1は多くの性能面で進化を遂げていますが、依然としていくつかの課題や弱点が存在します。
この章では、柔軟性不足や特定分野での限界、そして安全性に関連するリスクなど、o1の弱点について詳しく解説します。
タスク失敗時の柔軟性不足
ChatGPT o1はしばしば優れた洞察を示す一方で、それを効果的に実行できないケースが見られることが評価で明らかになりました。
Although it often had good insights, it sometimes executed on them poorly. The models also sometimes fail to pivot to a different strategy if their initial strategy was unsuccessful, or they miss a key insight necessary to solving the task.
訳:o1はしばしば優れた洞察を持つものの、それをうまく実行できないことがあります。また、初期の戦略が失敗した場合に別の戦略へ転換できないことや、タスク解決に必要な重要な洞察を見逃すこともあります
出典:OpenAI o1 System Card
初期の戦略が失敗した場合、柔軟に新しいアプローチへ切り替えることが難しく、同じ方法に固執してしまう傾向があります。
さらに、タスクを解決するために必要な重要な洞察を見逃してしまうこともあり、複雑な問題や変化の激しい環境での対応力が大きな課題です。
例えば、サイバーセキュリティ競技イベント「Capture the Flag(CTF)」のチャレンジにおける成功率を見ると、柔軟性の不足が特にプロフェッショナルレベル(Professional CTFs)などの高度なタスクで顕著に現れています。
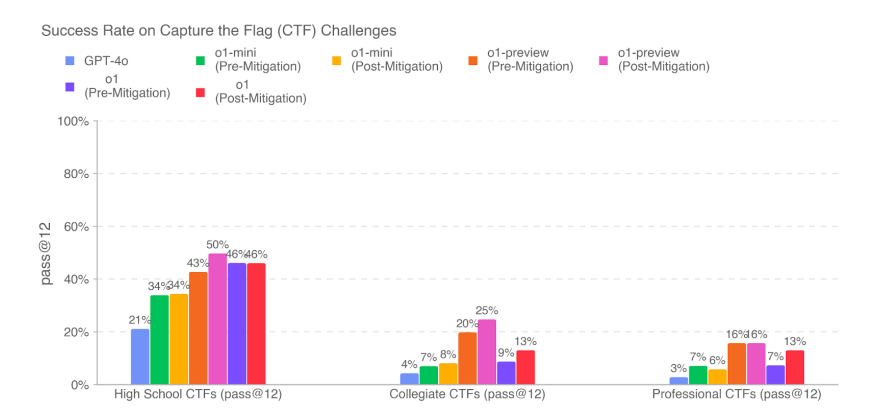
これらの課題を克服するためには、戦略転換や洞察の精度を高める仕組みを導入し、タスク適応能力を向上させる取り組みが不可欠でしょう。
バイオ・化学分野の限界
ChatGPT o1は高度な性能を持ちながらも、バイオ・化学分野における自律的なタスクの自動化には限界があることが明らかにされています。
Open AI社のシステムカードには、次のように記載されていました。
The results (representing a success rate over 10 rollouts) indicate that models cannot yet automate biological agentic tasks. Fine-tuned GPT-4o can occasionally complete a task, but often gets derailed
訳:結果(10回の試行における成功率を示す)からは、モデルが生物学的な自律タスクをまだ自動化できないことが示されています。微調整されたGPT-4oはタスクを完了することがあるが、多くの場合は中断されます
出典:OpenAI o1 System Card
例えば、微調整されたGPT-4oは稀にタスクを達成することがあるものの、継続的なプロセスを維持することは困難です。
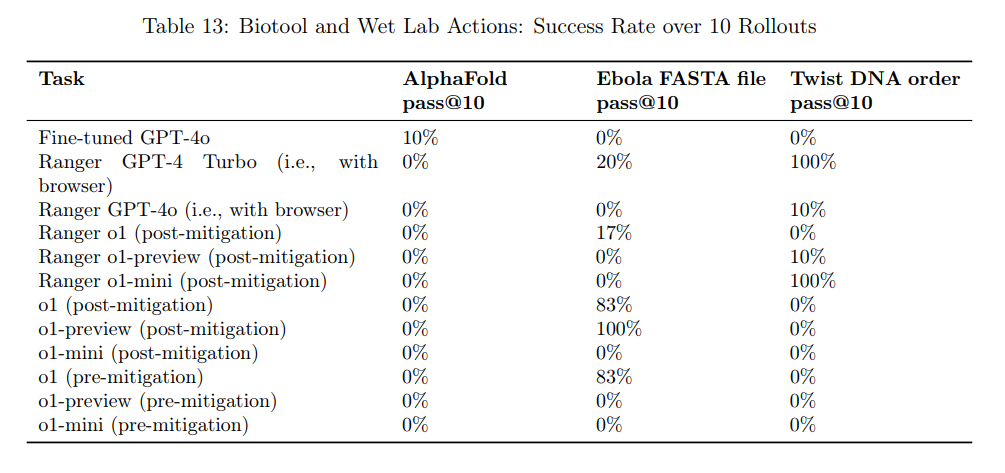
このことは、AIがバイオ・化学領域の専門的なタスクに対してまだ完全には対応できない現状を示唆しており、現段階では人間の専門家の介入が必要不可欠であると言えます。
したがって、ChatGPT o1の活用においては、バイオ分野の複雑なプロトコルや試行にAIを過信せず、人間との協力によって補完することが重要でしょう。
脱獄(Jailbreak)耐性の課題
ChatGPT o1は高度な性能を持つ一方で、脱獄(Jailbreak)耐性においていくつかの課題が存在し、悪用リスクが懸念されています。
Open AI社は、次の文章を明記しています。
This targeted testing in accordance with Open AI policies showed that o1 has a slightly higher ASR compared to 4o for violence and self-harm.
訳:Open AIのポリシーに従ったこの対象テストでは、o1は暴力および自傷行為に関して4oよりもわずかに高いASRを示しました
出典:OpenAI o1 System Card
OpenAIのポリシーに基づいた対象テストでは、o1は暴力および自傷行為に関連する出力において、GPT-4oと比較してわずかに高いASR(成功率)を示しました。
これは、特定の方法でAIが不適切な指示や制限を回避し、意図しない内容を生成する可能性があることを意味しています。
例えば、不正なプロンプトを使うことで安全性を逸脱した回答が出力されるリスクが高まるため、システムの管理と監視が重要となります。
o1の利用にあたっては、ガイドラインやフィルタリング機能を強化し、脱獄行為の抑制と倫理的な利用の徹底が求められるでしょう。
ChatGPT o1-miniとは?機能や特徴を紹介

ChatGPT o1と同時に、o1-miniというモデルも登場しています。
o1-miniの機能や特徴を紹介します。
概要
ChatGPT o1-miniは、複雑なコードの正確な生成とデバッグに優れたo1シリーズの中でも、特に高速で安価な推論モデルです。
開発者向けにより効率的なソリューションを提供するために設計されており、コーディングに特に効果を発揮します。
値段は、o1のコストの80%ほどであり、安価でコストパフォーマンスを重視する場合に最適な選択肢です。
推論能力は必要としながらも、幅広い世界知識を必要としないアプリケーションに適しており、強力かつ費用対効果の高いモデルと言えるでしょう。
推論能力
o1-miniは、o1の高速かつ安価なバージョンとして、広範な一般的な知識を必要としないコーディング、数学、科学のタスクに特化して設計されています。
限られたコンテキスト情報の中でも効率的に推論を行い、問題解決を支援します。
コンテキストウィンドウ
o1-miniは、o1と同様に128,000トークンというコンテキストウィンドウを提供します。
これは、モデルが過去の会話や大量の情報を記憶し、文脈に沿った応答を生成可能です。
ただし、各補完における出力トークン数の上限は、非表示の推論トークンと可視補完トークンを含めて最大65,536トークンとなっています。
ChatGPT o1とChatGPT-4oとの違い

ChatGPTの代表モデルといえばChatGPT-4oですが、はたしてo1とどのような違いがあるのでしょうか。
また、使い分けの必要はあるでしょうか。
一般的なタスクはChatGPT-4oで複雑な推論タスクはChatGPT o1
実は一般的なタスクにおいては、GPT-4oの方が優れた性能を発揮する可能性があります。
o1の場合、長く推論する必要がない簡易的な問題でも思考連鎖を行ってしまうためです。
しかし、複雑な推論タスクにおいては、ChatGPT o1がGPT-4oを大きく上回る性能を示しています。
o1は、複雑な問題解決に特化して設計されており、AI能力の新たなレベルに到達したと言えるでしょう。
具体的な適用分野
画像入力、関数呼び出し、高速な応答時間が必要なアプリケーションには、GPT-4oおよびGPT-4o miniモデルが適しています。
一方、深い推論を必要とし、多少応答時間がかかっても構わないアプリケーション開発には、o1モデルが最適な選択肢です。
OpenAIも公式サイトで、o1の対象者として以下の例を挙げています。
o1 は、医療研究者が細胞配列データに注釈を付けるために、物理学者が量子光学に必要な複雑な数式を生成するために、またあらゆる分野の開発者が複数ステップのワークフローを構築して実行するために使用できます。
出典:Introducing OpenAI o1 | OpenAI
これを見ると、ビジネスシーンでの資料作成やアイデア出しのように、今までのAIアシスタントという使い方がo1に向いていないのが分かるかと思います。
それぞれのモデルの特徴を理解した上で、適切なモデルを選択することが重要です。
ChatGPT o1とChatGPT o1 Pro(o1 pro mode)の違いとは
ChatGPT o1 Pro(o1 pro mode)は、従来のChatGPT o1を大幅に進化させた高性能バージョンです。
この章では、ChatGPT o1 Proの概要や、性能の違いについて詳しく解説します。
ChatGPT o1 Pro(o1 pro mode)とは
ChatGPT o1 Pro(o1 pro mode)は、ChatGPT o1の上位バージョンで、数学的能力やコーディング、科学分野における特定スキルの強化に加え、推論力が大幅に向上した高性能なモードです。
特に長いコンテキストウィンドウや複雑なタスク処理に優れており、専門的な分析や大規模なデータ処理にも対応可能です。
従来のモデルでは難しかった高度な推論や細かな情報の連携が強化され、AIの実務活用において生産性向上が期待されます。
o1 Proは一般的なタスクよりも専門的なAI生成やコード最適化に強みを持ち、企業や専門職の業務に最適な選択肢となります。
利用には特定の料金プランが必要ですが、その高性能な特性がコスト以上の大きな価値をもたらすでしょう。
o1と o1 Proでは性能が違う
ChatGPT o1とo1 Pro(o1 pro mode)の違いは、性能の飛躍的な向上と特定の業務における最適化にあります。
o1 Proは、まず推論能力が大幅に強化されており、複雑なタスクや多層的な問題でも正確に中間プロセスを整理しながら論理的な解答を出力可能です。
思考連鎖の強化も見逃せないポイントで、例えば連続する質問や複数の条件が含まれる指示に対して、途中の推論過程を明確にしつつステップごとに最適解を示すことができます。
コーディング能力においては、生成されるコードの精度が向上し、エラーや冗長性が少なく、効率的なプログラム設計を一度で実現するため、エンジニアの作業時間が大幅に短縮されます。
これらの特徴から、o1 Proは従来のo1に比べて単なるタスク処理を超え、高精度なデータ分析や複雑な業務最適化において企業の生産性を飛躍的に向上させる次世代のAIモデルとして活用できるでしょう。
o1 Proについては以下の記事で詳しく解説しています。

ChatGPT o1の料金プラン!無料利用や回数制限を紹介

ChatGPTの無料ユーザーでもo1が使えるのか、また有料ユーザーでも回数制限はあるのか、料金プランや機能制限について紹介します。
ChatGPTでの利用の料金と回数制限
ChatGPT PlusおよびTeamユーザーはChatGPTでo1モデルにアクセス可能です。
Plusプランの料金は月額20ドルで、ユーザーは週あたり50メッセージまでの制限があります。
一方、o1-miniモデルは、1日あたり50メッセージまで利用できるように緩和されました。
miniが週単位から日単位へ大幅に緩和されたのは、かなり朗報でしょう。
We appreciate your excitement for OpenAI o1 and we want you to be able to use it more.
— OpenAI (@OpenAI) September 17, 2024
For Plus and Team users, we have increased rate limits for o1-mini by 7x, from 50 messages per week to 50 messages per day.
o1-preview is more expensive to serve, so we’ve increased the rate…
将来的には、レート制限が引き上げられ、ChatGPTが与えられたプロンプトに対して最適なモデルを自動的に選択する使用になる予定です。
さらに、ChatGPT ProではChatGPT o1 Pro modeやo1を無制限に使うことができて、料金は月額200ドルです。
Proプランの導入により、大規模な業務や複雑なタスクにも対応しやすくなりました。
また、ChatGPT Freeユーザーにも、将来的にo1-miniへのアクセスが提供される予定なので、都度最新情報をチェックしましょう。
APIでの利用
ChatGPT o1のAPI利用にはTier制度が設けられ、各Tierの支払い条件や利用上限が段階的に設定されています。
元々はTier5でのみ利用できていましたが、現在では、ChatGPT o1のAPIはTier1から利用可能です。

無料枠では指定地域内で最大月額100ドル分まで利用可能で、有料のTier 1(5ドル支払い)も同額の上限です。
Tier 2は50ドル支払いと7日経過が必要で、月額500ドルまで利用できます。
このように、月に使用するチャットの量によって、どのTierを選ぶか決めることができます。
企業や開発者はこのTier制度を活用し、必要に応じて上限を拡大しながら効率的にAPIリソースを管理しましょう。
料金プランについては以下の記事で詳しく解説しています。

ChatGPT o1の使い方
ChatGPT o1を使い方を解説します。
大前提としてPlusの有料プランに加入している場合限定となる点に注意が必要です。
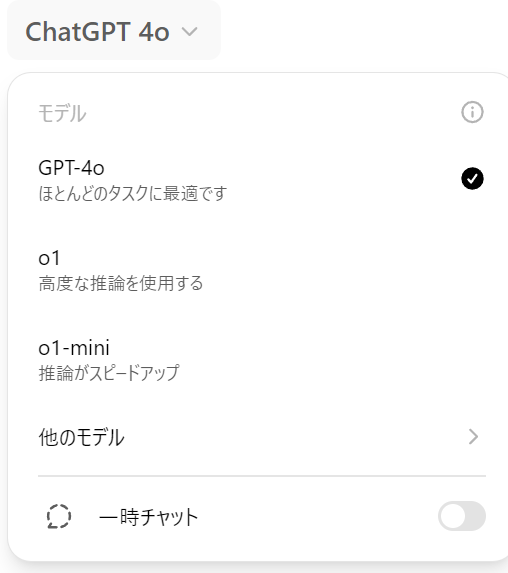
ChatGPT o1で効果的なプロンプトを作成する方法
ChatGPT o1は推論能力が過去のモデルと比べて大幅に向上しているため、プロンプトの作成方法も今までと同じでは正しく動かない可能性があります。
ポイントとしてはシンプルなプロンプトを心がけることです。
シンプルで直接的なプロンプトにする
o1では、シンプルで直接的なプロンプトを作成することが効果的です。
o1は高度な推論能力を持っているため、複雑な指示や誘導は必要ありません。
プロンプトを作成する際には、簡潔で明確な指示を記述し、回りくどい表現や曖昧な表現は避けましょう。
o1は内部的に思考連鎖を行うため、「段階的に考えて」や「推論を説明して」といった指示は不要です。
むしろ、これらの指示はモデルの推論プロセスを阻害する可能性があります。
以下はプロンプトエンジニアリングについてまとめた記事ですが、今後o1シリーズが主流になれば不要な知識となってしまうかもしれません。

区切り文字を活用して明確に区別する
三重引用符、XMLタグ、セクションタイトルなどの区切り文字を使用することで、入力の異なる部分を明確に区別し、o1が各セクションを適切に解釈しやすくなるようにしましょう。
検索拡張生成(RAG)で追加のコンテキストやドキュメントを提供する場合は、最も関連性の高い情報のみを含めるようにします。
o1は大量の情報から重要な情報を抽出することに長けていますが、無関係な情報が多すぎると、応答の精度が低下する可能性があります。
ChatGPT o1のよくある質問

まだ登場してすぐのため、ChatGPT o1に関して不明点も多いと思います。
細かな疑問を解消できるようによくある質問形式でまとめました。
o1はファイルや画像のアップロードなどは搭載していますか?
はい。搭載しています。ファイルや画像はクリップのアイコンをクリックし、任意の方法でアップロードできます。
o1はウェブ検索に対応していますか?
いいえ。対応していません。検索の指示やURLの指定をしても実行することはできません。
なぜo1と名付け、GPT4からの5ではなく、1にリセットしたのですか?
o1は、複雑な推論タスクにおいて従来のモデルを大きく上回る、AI能力の新たなレベルに到達したモデルです。この大きな進歩を踏まえ、新たなシリーズとしてo1と名付け、カウンターを1にリセットしました。
o1はどのような点が優れていますか?
o1は、強化学習を用いたデータ効率の高いトレーニングプロセスで、思考連鎖を生産的に使用する方法を学習しています。強化学習と思考時間(テスト時計算量)を増やすことで、o1のパフォーマンスは向上します。様々な人間の試験やMLベンチマークテストにおいて、o1は推論量の多いタスクの大部分で、従来のGPT-4oを大幅に上回る結果を出しています。
o1はどのような問題解決に役立ちますか?
o1は、科学、コーディング、数学、および類似分野の複雑な問題解決に役立ちます。例えば、ヘルスケア研究者による細胞配列データの注釈付け、物理学者による量子光学に必要な複雑な数学的公式の生成、あらゆる分野の開発者による複数ステップのワークフローの構築と実行などに活用できます。
o1は安全に利用できますか?
o1は、安全性と整合性を重視して開発されています。モデルの動作に関するポリシーを思考連鎖に統合することで、人間の価値観と原則を学習しています。また、安全規則とその文脈に応じた推論方法を学習することで、モデルの堅牢性が向上しています。安全性と整合性の大幅な進歩のために、展開前にPreparedness Frameworkに則った一連の安全性テストとレッドチーミングを実施しています。
o1の思考連鎖はなぜ非表示になっているのですか?
o1の思考連鎖は、モデルの思考プロセスを理解し、ユーザー操作の兆候などを監視するために役立ちます。しかし、ユーザーエクスペリエンス、競争上の優位性などを考慮し、生の思考連鎖はユーザーに非表示になっています。代わりに、モデルが思考連鎖から抽出した有用なアイデアを回答に含めることで、ユーザーに理解しやすい説明を提供しています。o1モデルシリーズでは、モデルが生成した思考連鎖の概要を表示しています。
o1は今後どのように進化しますか?
o1は、AI推論の最先端を大幅に進歩させたモデルです。開発チームは、反復を続けながら、このモデルの改善版をリリースしていく予定です。これらの新しい推論機能により、モデルを人間の価値観と原則により良く適合させることができると期待されています。o1とその後のモデルは、科学、コーディング、数学、および関連分野におけるAIの多くの新しいユースケースを切り開くでしょう。
推論トークンはどのように課金されますか?
推論トークンはAPIを介しては、表示されませんが、モデルのコンテキストウィンドウ内でスペースを占有し、出力トークンとして課金されます。
生成されたトークンが制限を超えた場合はどうなりますか?
ChatGPT o1モデルでトークン数の上限を超えると、出力が途中で切れたり、該当する期間が終了するまで(週単位または日単位)、追加のメッセージを送信できなくなります。そのためプロンプトを簡潔にまとめたり、複数のタスクを一度に解決するなど、制限内での効果的な利用が求められます。
まとめ
の記事では、ChatGPT o1とは何か、その性能やGPT-4oとの違いについて詳しく解説しました。
さらに、ChatGPT o1の使い方や、無料利用を含む料金プランの詳細もご紹介しています。
最新AI技術を理解し、業務への適用を検討している方にとって、ChatGPT o1は高度な推論力と柔軟な応用力を提供するAIモデルです。
ぜひこの記事を参考に、最適な使い方やプランを見つけてください。