

OpenAIは、新たな画像生成手法「sCM(simplified Continuous-time consistency Model)」を発表しました。
この手法は、従来のDiffusionモデル(拡散モデル)と比較して約50倍の高速化を実現し、わずか2ステップで高品質な画像を生成できる点が特徴です。
Diffusionモデルはこれまで、リアルな画像や3Dモデル、オーディオ、ビデオの生成で非常に高い成果を上げてきましたが、その一方で、サンプリングには多くのステップを要し、処理速度が課題となっていました。
従来の手法では数十から数百のステップを必要とし、その分だけ計算コストや実行時間がかかっていたのです。
今回発表されたsCMは、Continuous-time consistencyモデル(連続時間一貫性モデル)の理論的な枠組みを簡略化し、トレーニングの安定性とスケーラビリティを大幅に向上させています。
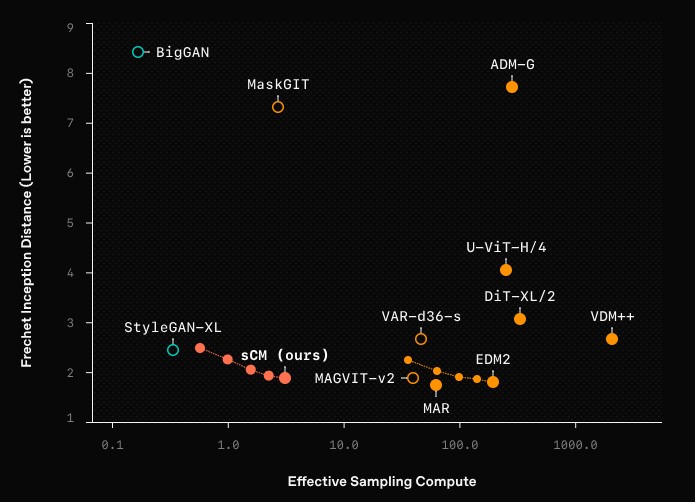
具体的には、1.5億パラメータのモデルをImageNetの512×512解像度のデータセットでトレーニングし、サンプリングを2ステップで行うことで、わずか0.11秒で高品質な画像を生成します。
これにより、リアルタイムでの画像生成が現実のものとなり、様々な分野での応用が期待されます。
バッチ サイズ = 1 の単一の A100 GPU で測定されたサンプリング時間。
バッチ サイズ = 1 で単一の A100 GPU で測定されたサンプリング時間。
さらに、このsCMは、従来のDiffusionモデルに匹敵する品質のサンプルを生成できる点も注目されています。
品質の評価にはFréchet Inception Distance(FID)という指標が用いられており、sCMはDiffusionモデルと比較して10%未満の差異しかないことが確認されました。
これにより、sCMは高品質な生成を維持しながら、計算コストを大幅に削減することができます。
sCMの高速化の秘密は、ノイズを直接クリーンなサンプルに変換するために必要なステップ数が少ないことにあります。
従来のDiffusionモデルは、ノイズを段階的に取り除くことで徐々に画像を生成していましたが、sCMでは一度のステップでノイズからクリアなサンプルを作り出します。
この手法は、Consistency TrainingやConsistency Distillationといった技術を活用し、トレーニングの効率をさらに高めています。
ただし、sCMは依然としてDiffusionモデルをベースにしているため、サンプル品質にはわずかな差異が残ることがあります。
また、FIDスコアは万能ではなく、特定の用途においては別の評価基準を用いる必要があるかもしれません。
今後、OpenAIはさらなるモデルの改良に取り組むとし、より高速かつ高品質な生成技術の発展を目指しています。
これにより、リアルタイムでの高品質な生成が、画像やオーディオ、ビデオといったさまざまな分野での応用を加速させることが期待されます。
出典:Simplifying, stabilizing, and scaling continuous-time consistency models | OpenAI