

米OpenAIは、次世代の音声AIモデル3種類を発表しました。
今回公開されたのは、2種類の音声認識モデル「gpt-4o-transcribe」「gpt-4o-mini-transcribe」と、1種類の音声合成モデル「gpt-4o-mini-tts」です。
これらはすでにAPI経由で全世界の開発者に提供されています。
音声認識モデルは、従来の「Whisper」シリーズを大きく上回る精度を実現しています。
OpenAIによると、新モデルは多言語ベンチマーク「FLEURS」において、従来モデルよりも低い単語誤り率(WER)を記録し、雑音の多い環境や多様な話速、アクセントのある発話に対しても高い認識精度を維持するとのことです。
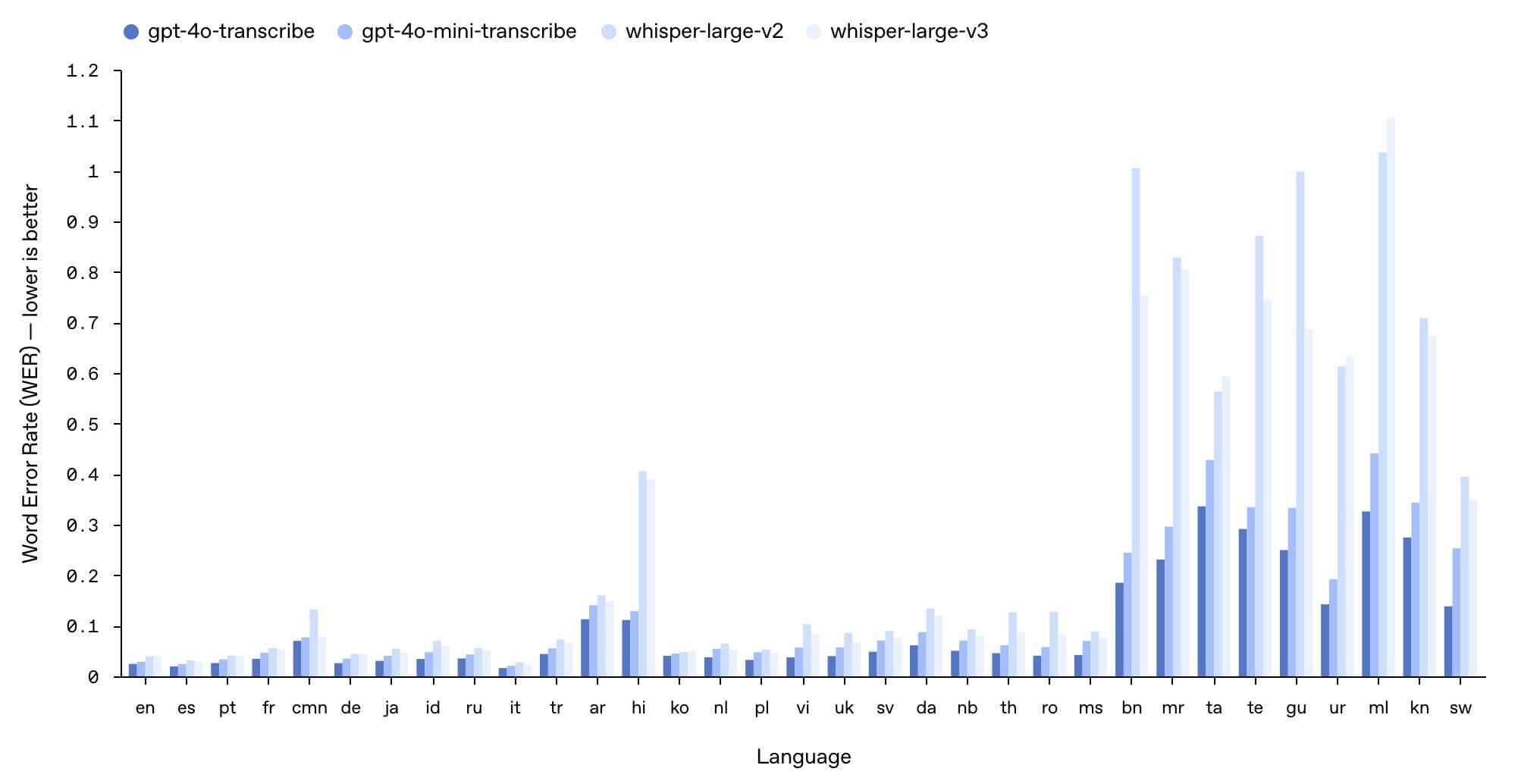
これにより、カスタマーサポートや会議の文字起こしなど、実用的なユースケースでの活用が期待されます。
一方、音声合成モデル「gpt-4o-mini-tts」は、テキストに加えて「どのように話すか」まで指示可能な点が特長です。
例えば「共感的なカスタマーサービス担当者のように話す」といった表現指示が可能で、従来の単調な音声合成とは異なる、より人間らしい音声出力が実現されます。
感情や文脈に応じた音声生成ができることで、ストーリーテリングや教育用途など、多彩な活用が見込まれます。
これらのモデルは、GPT-4oおよびGPT-4o-miniのアーキテクチャをベースに、音声データに特化した事前学習を受けており、強化学習や高度な蒸留技術も取り入れられています。
特に蒸留工程では、自己対話型の学習方法を通じて、人間との自然な会話に近い応答品質を実現しているということです。
また、OpenAIは「OpenAI.fm」というウェブサイトも公開しました。
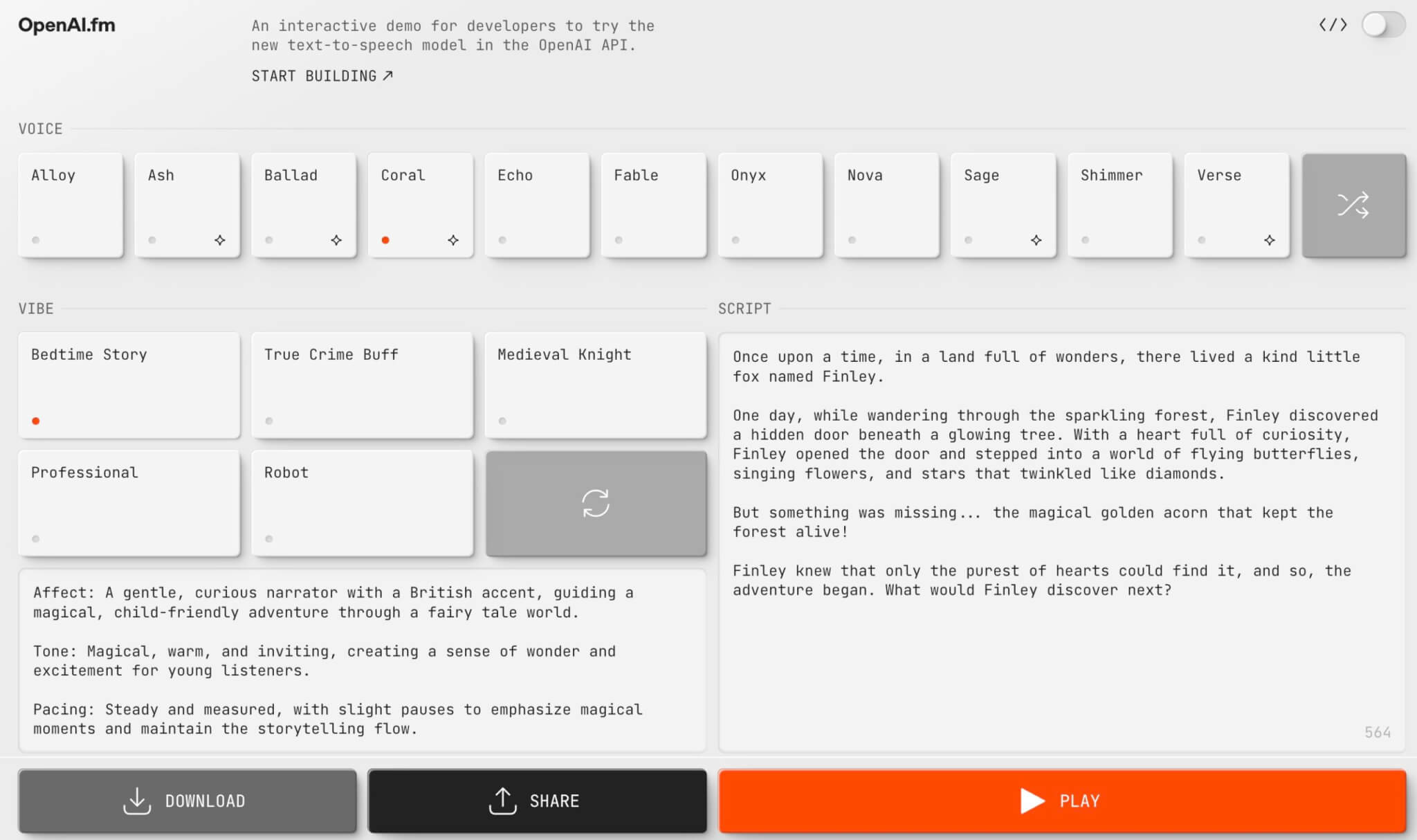
これは、新しいテキスト読み上げモデルを試せるプラットフォームで、ユーザーが入力したテキストをさまざまな声や話し方で再生できます。
特定のプロンプト(例:「狂った科学者」)を選択したり、独自のスタイルを指定したりすることも可能です。
さらに、Python、JavaScript、curl でコードスニペットを生成するオプションが用意されており、開発者が自身のプロジェクトに統合しやすくなっています。
APIでは、OpenAIのAgents SDKとも統合されており、開発者はテキストベースのエージェントに音声機能を簡単に追加することができます。
さらに、将来的には開発者が独自のカスタム音声を使ってよりパーソナライズされた体験を提供できるようにすることも検討されています。
OpenAIは、今後も音声モデルの精度や表現力の向上に注力するとともに、動画など他のマルチモーダル技術への拡張も見据えて開発を進めるとしています。
出典:Introducing next-generation audio models in the API | OpenAI
出典:Audio Models in the API – YouTube