

米AI開発企業のOpenAIは、「GPT-4o」の画像生成機能をアップデートしたことを発表しました。このアップデートにより、ユーザーが求めるテキストをより正確に画像化できるようになり、文脈を踏まえた自然な画像生成が可能になっています。
GPT-4oは従来のモデルと比較して、テキストと画像の関係だけでなく、複数の画像間の関連性まで深く理解できるよう設計されました。
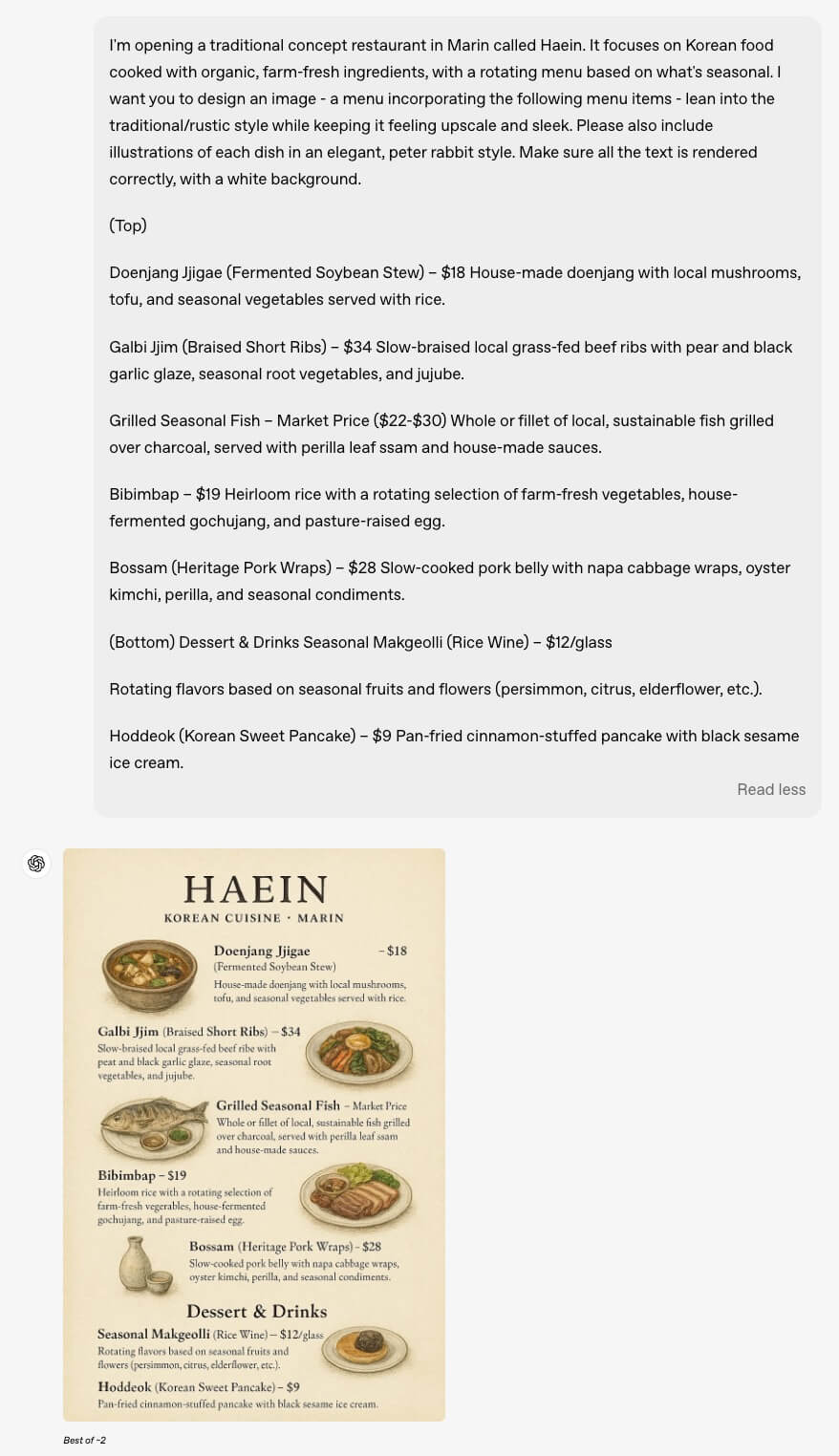
特に今回のアップデートでは、画像内に含まれるテキストを正確かつ自然に描写することが可能になりました。これにより、看板やポスター、メニューといった文字情報が重要な画像生成にも対応し、視覚的な情報伝達やコミュニケーションの実用性を高めています。
その他の特徴としては、会話の流れに沿って画像を生成する「マルチターン生成」が挙げられます。これにより、ユーザーは自然な対話の中でイメージを細かく調整・改善することができます。

また、アップロードした画像を参考に新しい画像を生成したり、既存の画像にインスピレーションを得て画像を描画したりすることも可能です。

OpenAIのCEOであるサム・アルトマン氏は、今回の発表で「GPT-4oの設計思想として、ユーザーが望まない限り攻撃的なコンテンツは生成しないことを重視している」と述べました。
we are launching a new thing today—images in chatgpt!
— Sam Altman (@sama) March 25, 2025
two things to say about it:
1. it's an incredible technology/product. i remember seeing some of the first images come out of this model and having a hard time they were really made by AI. we think people will love it, and we…
これは、AI技術が社会に広がる中で特に懸念される安全性と倫理面への配慮を明確にしたもので、ユーザーの創造性を最大限尊重しながら安全性を維持する方針を示しています。
一方で同社は、現時点でのモデルにはいくつかの課題が残っていることも認めています。具体的には、画像が意図せずトリミングされてしまう問題や、存在しない情報を画像化してしまう「幻覚」問題、多数の要素を含む複雑な画像を正確に生成する際の限界などです。
OpenAIはこれらの課題に対し、今後継続的な改善を行っていく方針を示しています。
今回のアップデートは、ChatGPTのPlus、Pro、Team、そしてFreeユーザーを対象に順次提供が開始されます。また企業向けおよび教育機関向けにも近く提供される予定で、さらに開発者向けに画像生成APIの提供も近日中に始まります。