

Mistral OCRは、画像やPDF内のテキストを抽出するOCRモデルのAPIです。
複雑な構造の文書やマルチモーダルドキュメントにも対応しており、テキストに加え、表や図、数式などを文書の構造を保ったまま抽出できます。
また、抽出された情報はMarkdown形式やJSON形式で出力でき、そのままドキュメント管理システムやナレッジベースに組み込めるため、業務の効率化も可能です。
この記事では、Mistral OCRの使い方、料金、そして日本語の文書に対する精度について詳しく解説します。
ドキュメント理解API「Mistral OCR」とは?

Mistral OCRとは、フランスのAIスタートアップ企業であるMistral AI(ミストラルAI)が開発したドキュメント理解APIです。
従来のOCRよりも精度が高く、複雑な画像やグラフを正確に認識し抽出できることから、高度な研究活動を支える基盤技術となっています。
また、Mistral OCRはMistral AIが提供しているLe Chatでもデフォルトの文字認識システムとして採用されており、今後はクラウドパートナーやオンプレミス(自社環境)での展開も予定されています。
ここからは、Mistral OCRの特長を詳しくご紹介します。
文書の構造を崩さずMarkdown形式で出力可能
Mistral OCRの大きな特長は、画像とテキストが交互に配置された「インターリーブ構造」を保持したまま解析できることです。
インターリーブとは?
インターリーブ(Interleave)とは、データやプロセスを交互に配置する手法で、主に計算機科学や電気通信の分野で用いられます。これにより、性能向上やエラー耐性の強化が図られます。
入力されたPDFや画像内のテキストデータを、表や図との位置関係を維持したまま抽出できます。
LaTeXフォーマットなどの複雑な構造の文書であっても、図、表、テキスト、式などの各要素を正確に認識し、順序を保持したまま抽出することが可能です。
文書の構造を維持したままMarkdown形式で出力することもでき、見出しや表などの情報を自動的に付与して、元のドキュメントを反映します。
また、読み取ったデータをJSON形式で構造化して出力できるため、OCR処理で抽出した内容をそのままドキュメント管理システムやナレッジベースに取り入れられます。
マルチモーダルドキュメントに対応
Mistral OCRは、マルチモーダルドキュメントの入力に対応しています。
そのため、テキスト以外に図や表、複雑な数式などが書かれたスライド資料や科学論文などのPDFを入力として受け取ることが可能です。
マルチモーダルドキュメントを入力として受け取るRAGシステムを組み合わせて使用するのに最適なOCRモデルといえるでしょう。
他モデルとの比較
Mistral OCRは、OCR性能を評価するベンチマークにおいて、GoogleやOpenAI、Microsoftが提供しているOCRモデルを超えるスコアを記録しています。
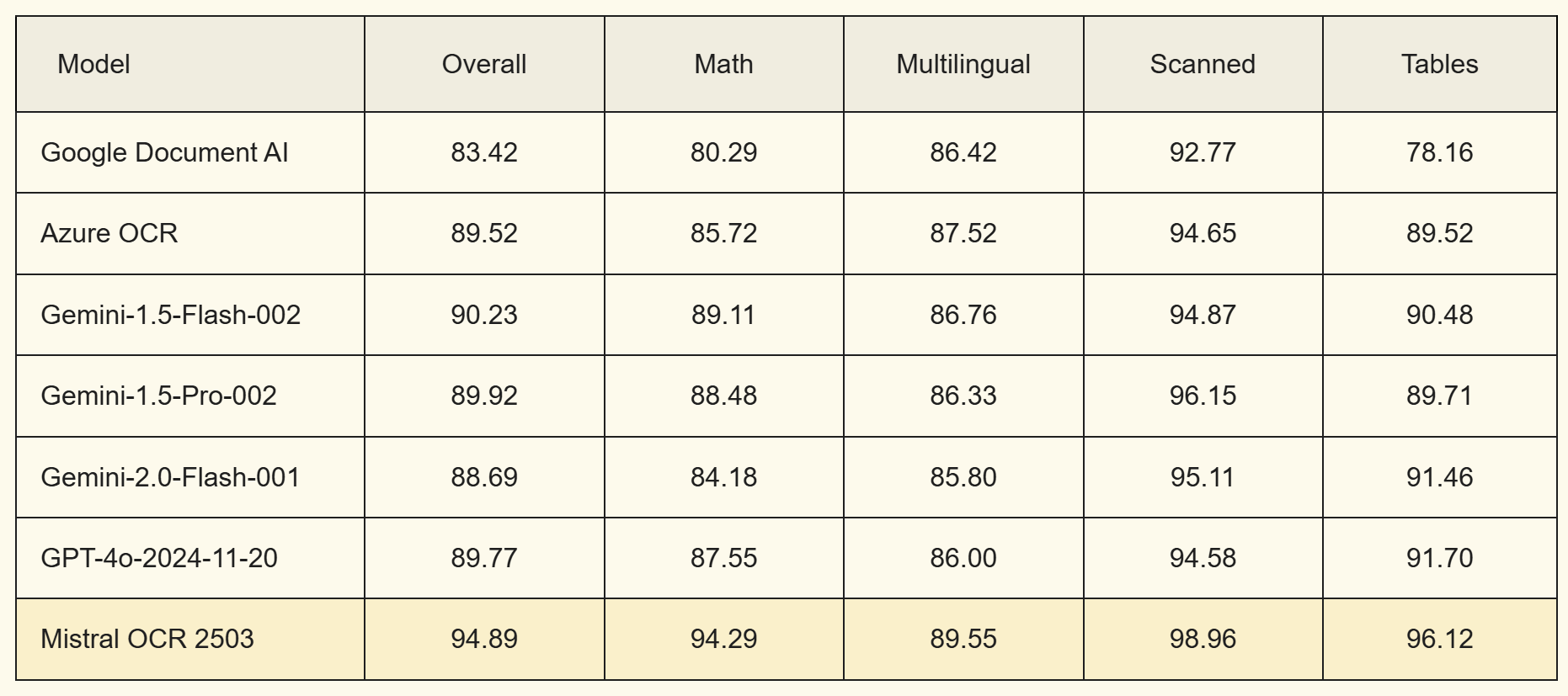
全体的な性能だけではなく、数学的表現、多言語文書、スキャン文書、表形式データのすべてのカテゴリで最も良い精度となっています。
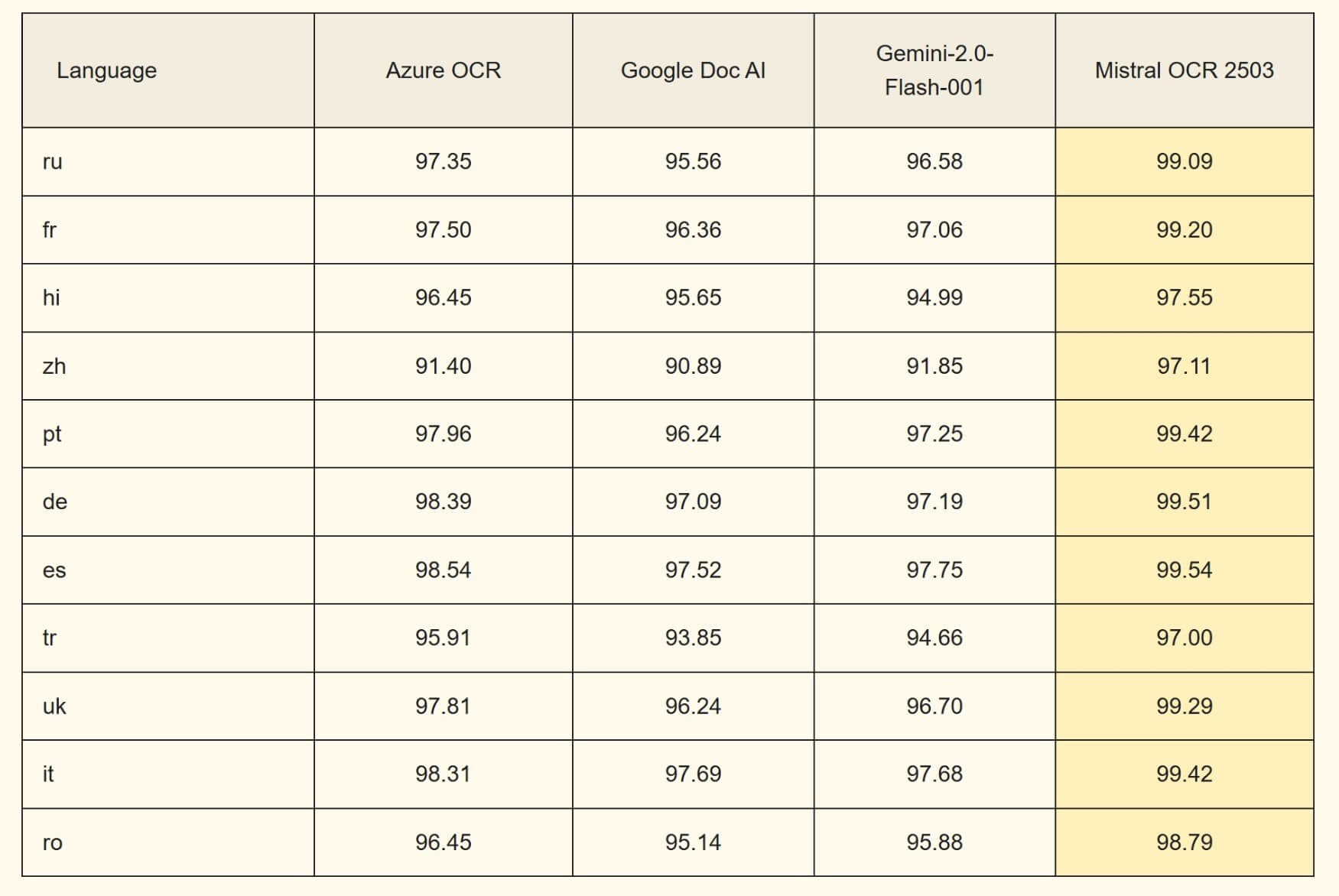
多言語文書においては、特にロシア語やフランス語、ポルトガル語、ドイツ語、イタリア語などの英語以外の言語も高い精度で認識できる点が特長です。
処理速度もほかのモデルと比べて高速であり、1分間あたり最大2,000ページを処理できます。
そのため、大量の文書を処理する企業や研究機関に適しているでしょう。
Mistral OCRの料金

Mistral OCRは、APIプラットフォーム「la Plateforme」を通じて1,000ページあたり1ドルで利用できます。
バッチ推論の場合は、1ドルで約2,000ページの処理が可能です。
なお、Mistral AIが提供しているLe Chatでは、Mistral OCRを無料で使えます。
Mistral OCRの基本性能を試したい方は、まずはLe Chatで使ってみると良いでしょう。
以下で、Le ChatでMistral OCRを使う方法を解説します。
Le Chatを利用したMistral OCRの使い方
Le ChatはMistral OCRを無料で使えるほか、APIに関する知識が不要であるため、簡単に使い始めることができます。
ここからは、Le Chatを利用したMistral OCRの使い方をご説明します。
以下のステップに従って進めることで、すぐに利用を開始できます。
Le Chatは、ログインしていない状態ではファイルのアップロードができないため、Mistral OCRを使うにはアカウントを作成する必要があります。
サイトの右上にある「Sign up」をクリックします。

メールアドレスを使った登録のほか、GoogleやApple、Microsoftのアカウントを使ってログインすることも可能です。
ここではメールアドレスを使ったアカウント作成について説明します。
メールアドレスとパスワードを入力して「Sign up」を押すと、入力したメールアドレス宛に認証番号が送られてきます。
送られてきた番号を入力して「Continue」をクリックしてください。
以下のような画面が表示されたらアカウント作成完了です。
今回は、BERTの論文から以下の1ページ分のスクリーンショット画像を入力してみました。

Le Chatは文字認識のデフォルトモデルとしてMistral OCRを採用しているため、アップロードした画像をMarkdown形式で出力するように指示を出すだけでMistral OCRを使った抽出ができます。
プロンプトについては、画像の通りではなくても問題ありません。
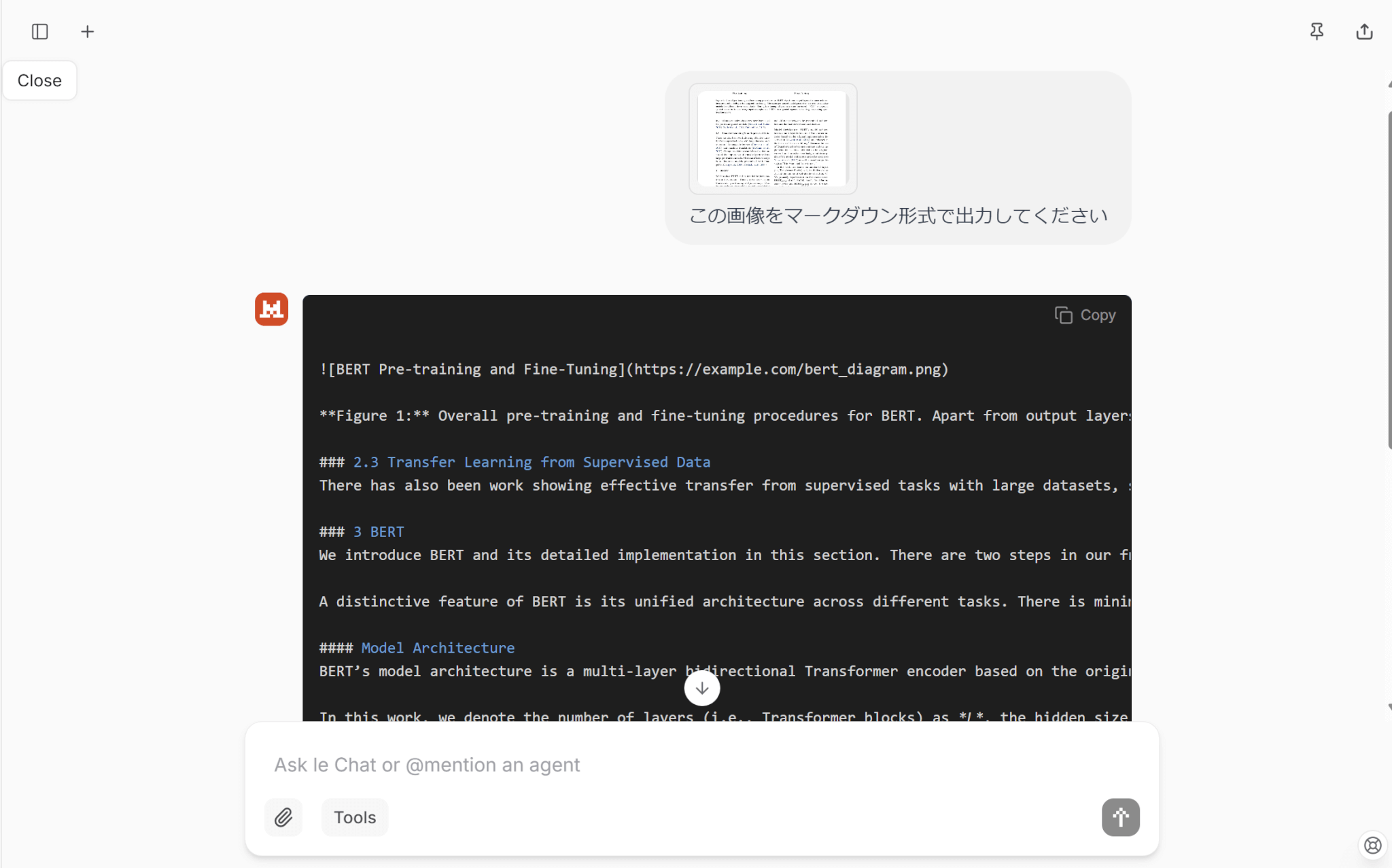
画像のようにMarkdown形式でテキストを出力してくれます。
プレビュー結果は以下のとおりです。

二段組みの文書でも、順序を保ってテキストを抽出できていることがわかります。
なお、Le Chatの性質上画像の表示には対応していないため、画像内にある図は抽出できていません。
Mistral OCRの日本語に対する精度

先述したとおり、Mistral OCRは多言語に対応しており、さまざまな言語でほかのモデルと比べて高い精度を誇ります。
しかし、日本語に対する認識精度については公式の情報はありません。
そこで、実際に日本語で書かれた文書を入力し、どれほどの精度でテキストを抽出できるのかを確かめてみました。
入力した画像は以下の日本語で書かれた論文1ページ分です。

Markdown形式で出力させた結果のプレビューは以下のとおりです。

結果を見ると、表や見出しなどの構造は維持できているものの、ところどころ文字の間違いが目立ちます。
特に表の内容は、文章が全く異っています。
このことから、Mistral OCRの日本語に対する精度にはまだ課題があるといえるでしょう。
当然ではありますが、文字認識の精度は入力された画像の解像度にも影響されるため、高解像度の画像を用いることで、精度が高まる可能性もあります。
しかし、実際にXでは、Mistral OCRの日本語に対する精度に関して以下のように報告されています。
mistral OCR 日本語苦手そうだなー。。 pic.twitter.com/yPmw6nzwg2
— やきとり (@yakitori_eng) March 7, 2025
試してみたけど日本語のベンチマークスコアが出てないように、日本語はまだgeminiの方がよさそう。
— 鈴木淳巳 (@suzukiAdIre) March 10, 2025
手元の100項目のOCRテストでgemini-pro100/100、flash99/100の画像で、mistralは96/100だった。
今後の日本語対応に期待 https://t.co/aVEhNKjzf6
このため、日本語で書かれた文書については、ほかのOCRモデルを利用したほうが賢明かもしれません。
特に手書きの日本語文書に関しては、従来のOCRモデルが優位であるといえるでしょう。
まとめ
Mistral OCRは、従来のOCRモデルの比べて高い精度を誇るドキュメント理解APIです。
マルチモーダルドキュメントに対応しており、テキストに加えて図や表、数式など複雑な構造を持つ文書やスライド資料に対し、高度な構造解析を実現しています。
読み取った文書はMarkdown形式やJSON形式で出力でき、抽出した内容をそのまま管理システムやナレッジベースなどに組み込むことも可能です。
APIは低コストで利用できるほか、Le Chatを用いて無料で使うこともできます。
日本語に対する精度には課題が残りますが、英語やフランス語、ロシア語などほかの言語の文書を処理するには最適なOCRモデルであるといえるでしょう。