
米Meta(旧Facebook)が最新AIモデル「Llama 4(ラマ・フォー)」を公開しました。このモデルは最大で業界トップとなる1000万トークン(約本100冊分)の情報を一度に処理できる性能を備えており、競合するGPTやGeminiなどの最新モデルを精度面で上回っています。
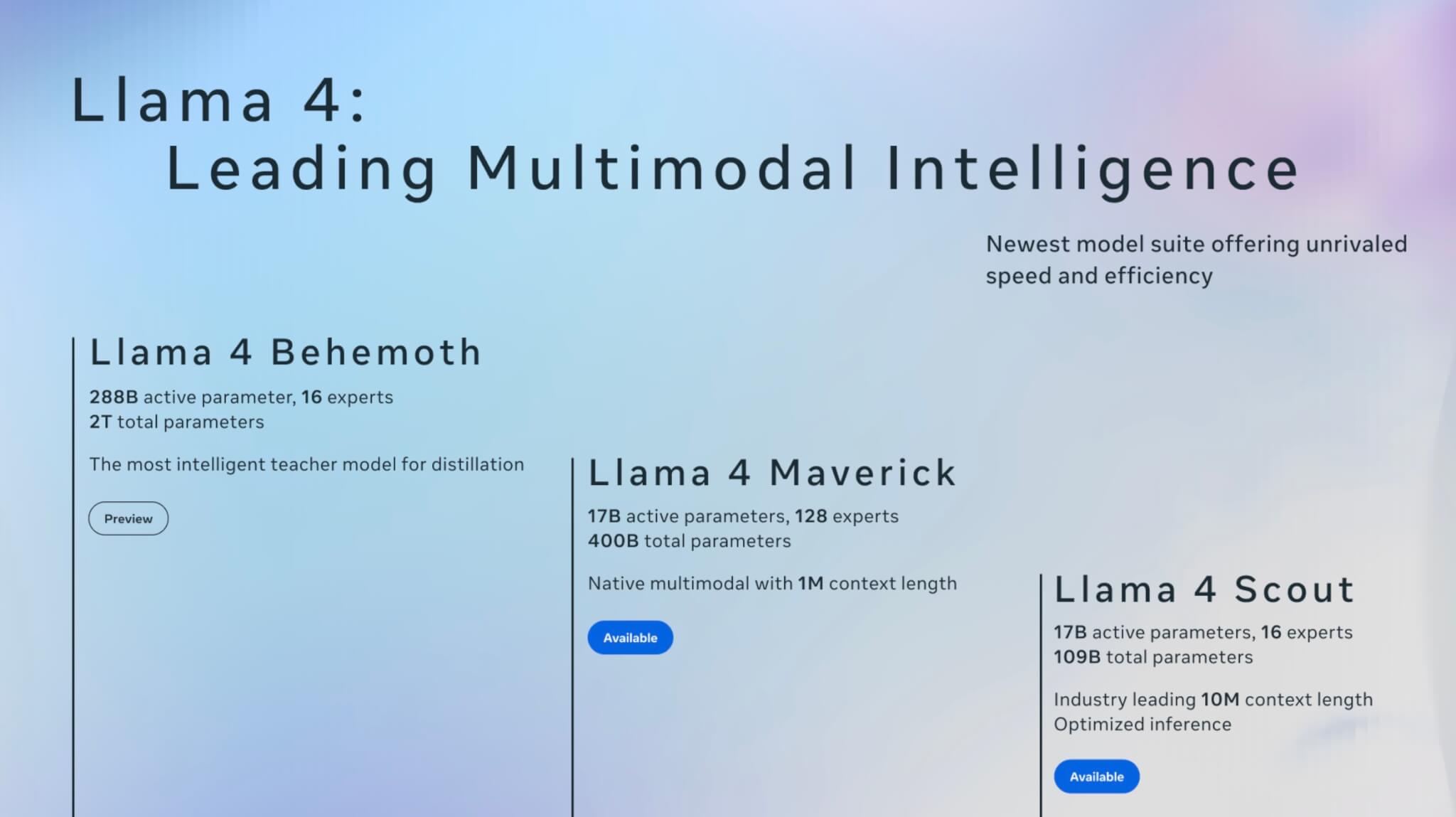
Metaが発表した「Llama 4」は、性能やサイズごとにゲームなどでも馴染み深い名称が与えられており、「Scout(スカウト=斥候)」「Maverick(マーベリック=一匹狼)」「Behemoth(ベヒーモス=巨獣)」の3モデルで構成されています。
- Llama 4 Scout
-
「Scout」は17B(170億)パラメータと小型ながら、業界初となる1000万トークンの情報処理に対応したモデルです。これは本約100冊分に相当する情報量を一括で扱える性能で、単一のNVIDIA H100 GPUでの稼働が可能なほど軽量でありながら、Gemma 3やGemini 2.0 Flash-Liteを超える精度を実現しています。
- Llama 4 Maverick
-
「Maverick」はScoutと同じ17Bパラメータを持つ中型モデルですが、専門知識を持つ128個のユニットを搭載し、特に複雑な処理やマルチモーダル(画像とテキストの同時処理)に優れています。GPT-4oやGemini 2.0 Flashといった代表的な競合モデルを幅広いベンチマークテストで凌駕する性能を誇ります。
- Llama 4 Behemoth
-
「Behemoth」は現在もMetaが開発を継続中の最大モデルで、288B(2880億)のパラメータを持ち、STEM(科学、技術、工学、数学)分野に特化した性能が特徴です。GPT-4.5やClaude Sonnet 3.7などの高度な競合モデルを多数のテストで上回っており、今後のさらなる進化が期待されています。また、小型モデルの教師モデルとしても利用され、性能向上に貢献しています。
Metaが開発を進める最新AIモデル「Llama 4 Behemoth(ベヒーモス)」は、複数の主要ベンチマークにおいて、競合する最新のAIモデルを大きく上回る精度を記録しています。
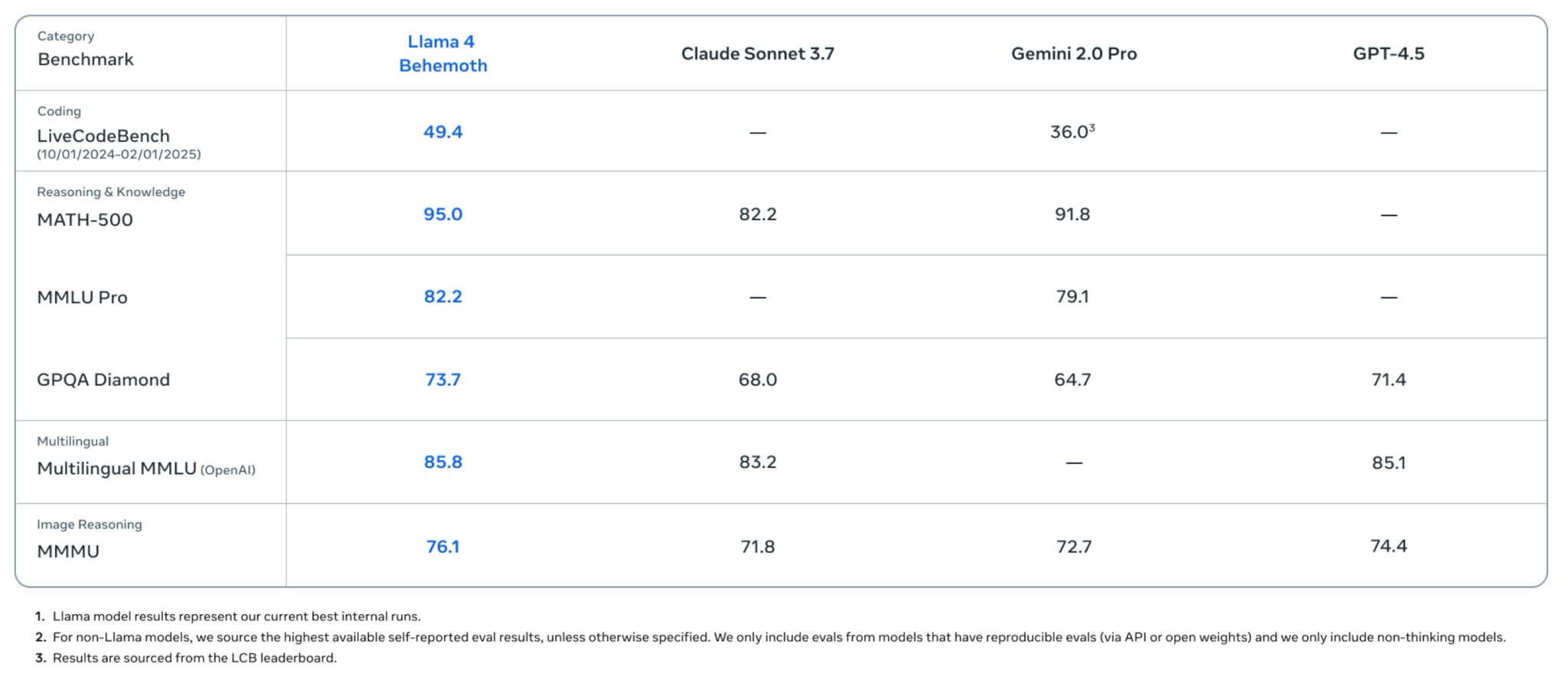
具体的な評価結果を見ると、プログラミング能力を評価する「LiveCodeBench」では49.4のスコアを記録しており、Gemini 2.0 Proの36.0を大幅に上回りました。また、数学的な問題解決力を測る「MATH-500」では95.0という高得点を記録。Claude Sonnet 3.7の82.2やGemini 2.0 Proの91.8を超えています。
さらに知識や推論力を測定する「MMLU Pro」でも82.2という高スコアを獲得し、Gemini 2.0 Proの79.1を上回っています。一般的な質問応答能力を評価する「GPQA Diamond」でも73.7を記録し、Claude Sonnet 3.7の68.0、Gemini 2.0 Proの64.7、GPT-4.5の71.4をすべて上回る結果となりました。
多言語理解力を評価する「Multilingual MMLU」では85.8をマークし、Claude Sonnet 3.7の83.2、GPT-4.5の85.1を抑えてトップに立っています。また画像を使った推論能力を評価する「MMMU」でも76.1を記録し、競合モデルをリードしています。
これらのベンチマーク結果からも、「Llama 4 Behemoth」が幅広い分野で卓越した性能を示し、現時点で業界を代表する最も先進的なAIモデルの一つであることが明確となりました。
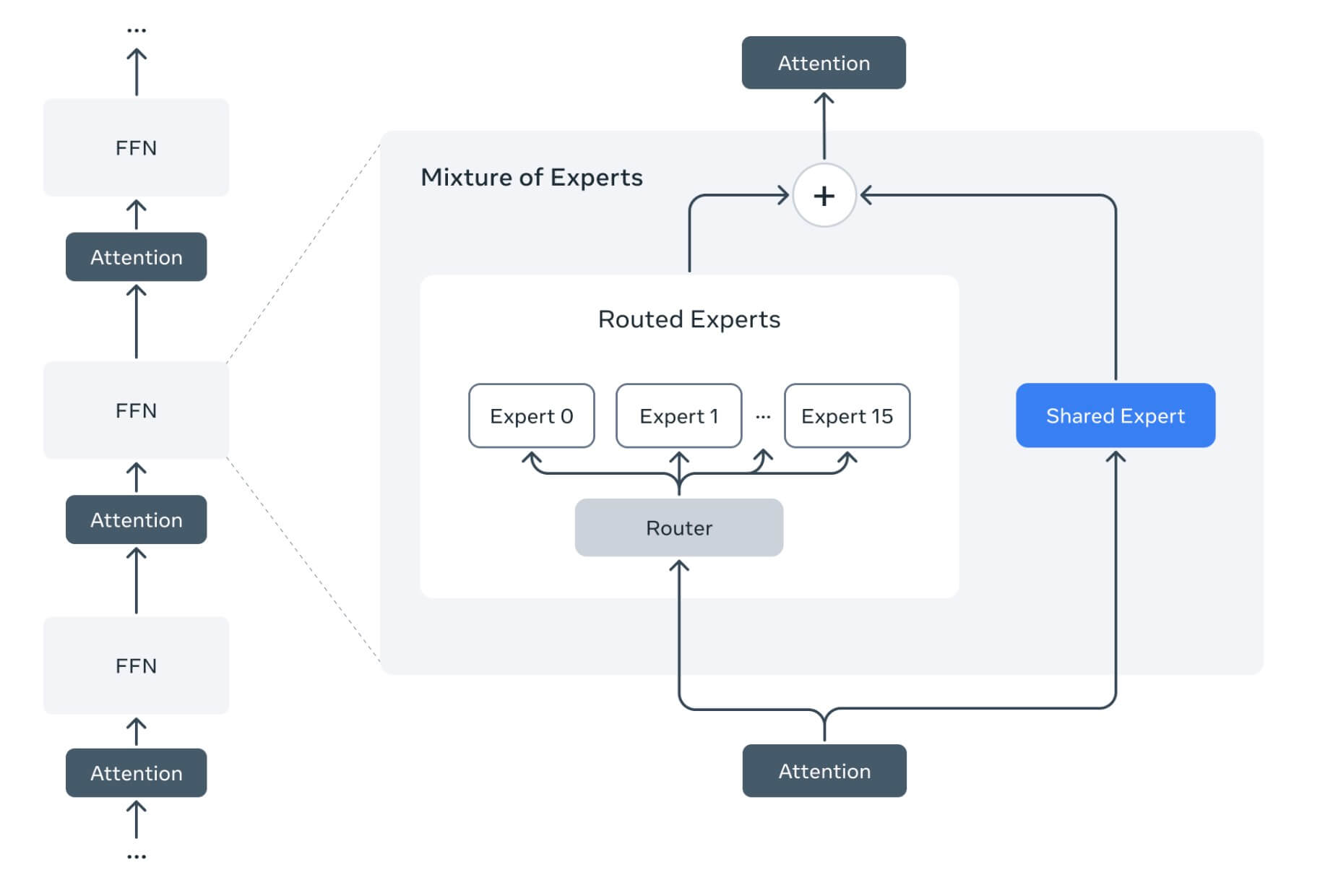
今回Metaは新たに、処理効率を高めるために「Mixture-of-Experts(MoE)」と呼ばれる技術を初めて導入しました。これは情報に応じてモデルの一部だけを動かす仕組みで、計算負荷を大幅に削減しています。
また、画像や動画、テキストを一つのモデルで同時処理するマルチモーダル技術にも力を入れ、視覚的な理解能力を飛躍的に高めました。
Metaは、これら最新AIモデルをオープンソースとしてllama.comやHugging Faceなどで公開し、誰でも自由に活用できるようにしています。WhatsAppやMessengerなどMeta傘下のプラットフォームにも導入されることから、「Llama 4」が今後のAI業界の勢力図を大きく塗り替える可能性が注目されています。
出典:The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation