

近年のAI技術の進歩により、ChatGPTは人間のように自然な文章を生成できるようになりました。
しかし、時に「ハルシネーション」と呼ばれる現象が発生します。ハルシネーションとはChatGPTが「嘘をつく現象」のことです。
ChatGPTをビジネスや情報源として活用するには、嘘をつかせないことが重要です。
この記事では、ハルシネーション対策として有効なプロンプトの使い方やファクトチェックの重要性など、具体的な方法を紹介します。
ChatGPTの嘘をつく現象(ハルシネーション)とは

ChatGPTなどの生成AIは、人間が書いたような自然な文章を作り出すことができます。
しかし、時には事実とは異なる情報や、存在しない情報を生成してしまうことがあり、これを「ハルシネーション」と呼びます。日本語で「幻覚」という意味です。
例としてノーベル賞受賞者の研究について質問しました。
ノーベル賞を受賞したピエール・アゴスティーニとDavid R.Klelinmanの研究はどのように異なりますか?

ピエール・アゴスティーニ氏は実際に2023年ノーベル物理学賞を受賞していますが、David R. Kleinmanは架空の人物であり、ChatGPTが回答したような研究事実はありません。
あたかもDavid R. Kleinman氏の研究が実在するかのような回答が生成されたとおり、実在しない書籍や論文をでっち上げてしまったり、歴史的な事実をねじ曲げてしまったりするケースなどが報告されています。
特に文章や画像生成において顕著で、根拠がない情報を創造する点がハルシネーションの厄介な点です。
以下の画像は、ChatGPT-o3proとChatGPT-4oを比較する際にChatGPTの間違いを指摘したものになります。
「ChatGPT-4o(通称o4)」といったように誤った解釈のまま回答が生成されました。
生成されたデータが現実と異なることで、情報としての正確さや信頼性が損なわれてしまいます。

ChatGPTでなぜ嘘をつく現象が起きる?ハルシネーションの原因

ChatGPTがハルシネーションを起こす原因は、ChatGPTが回答を生成する仕組みそのものにあります。
主な3つの原因を正しく知りましょう。
ハルシネーションの原因①:正しい回答をする仕組みではない
ChatGPTは、Google検索のように事実を探して回答するシステムではありません。膨大なデータの中から、質問に対して確率的に最も適切と思われる単語を繋ぎ合わせて文章を生成しています。
そのため、文脈上最もらしく見えれば、事実の検証をすることなく回答してしまいます。

ハルシネーションの原因②:学習データの鮮度と質
ChatGPTの回答は、過去の膨大な学習データに基づいて生成されます。
しかし、学習データは24時間更新されているわけではなく、また偏った情報が含れている場合もあり、最新の正しい情報とは異なる回答が生成される場合があります。
GPT-4oは2024年6月までのデータを元に学習しており、それ以降の出来事は基本的に知らない前提です。
例えば、2024年7月に開幕したパリ五輪の競技結果について質問してみました。
2024年パリオリンピックのBMXブレイクダンス優勝者を教えてください。

学習データ以降のニュースであるため、未確定であることと注目選手の回答にとどまりました。
また、特定の人物に関する情報が学習データに不足している場合にも、不正確な回答が生成される可能性が高くなります。
2024年7月7日に東京都知事選がありましたが、その立候補者の1人である三輪陽一さんについて質問してみました。

三輪氏は経済学者ではありませんし、同姓同名の経済学者がいるわけでもありません。学習データが少ないため、間違った回答をしています。
ChatGPT-4oで精度が上がり、データがないことに関しても不明確な回答がでる確率は少なくなりましたが、学習データの内容や質によって回答の精度は大きく左右されるのです。
ハルシネーションの原因③:得意分野と苦手分野がある
ChatGPTは文章の読解や生成を得意とする一方、計算などの分野は苦手としています。複雑な計算処理を行うには、より高度な言語モデルが必要となるためです。
例えば、4桁×4桁の計算をさせるとかなりの確率で間違えます。
9850×7250の計算式ですが、電卓で計算すると答えは「71,412,500」となりますが、ChatGPT-3.5だと「71,487,500」と回答してきます。

ただし、GPT-4以降は計算能力が向上しており、同じ計算をさせても正しい回答が生成されました。

より複雑な計算の場合は、計算式や途中経過を明確に提示することで、正確な答えを導き出せる場合があります。
なお、Googleが開発した生成AIのGeminiは、開発段階で計算に関するプログラムが組み込まれているため、計算問題に強いのが特徴です。

ChatGPTのハルシネーション対策

ChatGPTの嘘(ハルシネーション)への対処法について解説していきます。
ChatGPTをビジネスシーンなど信頼性を求められる場面でも効果的に活用できるようにしましょう。
ハルシネーション対策①:ファクトチェックの実施
ChatGPTが生成した情報は鵜呑みにせず、必ずファクトチェック(事実確認)を行うようにしましょう。
特に、ニュース記事、学術研究、公共の情報提供など、正確性が求められる分野においては、ファクトチェックは非常に重要です。
ChatGPT-4oは2024年6月までのデータで学習しているため、より新しい情報や専門性の高い情報については、信頼できる情報源を用いて、裏付けを取るように心がけましょう。
ハルシネーション対策②:RAGの利用
ChatGPTに不足している学習データを補うためには、RAG(Retrieval Augmented Generation:検索拡張生成)を利用しましょう。
RAGとは、ChatGPTにトレーニングデータ以外の信頼できる外部データを与え、その情報を元に回答を生成させる技術のことです。
ハルシネーション(もっともらしい嘘)のリスクを軽減し、より正確で専門的な回答を提供することが期待されています。
たとえば、社内のナレッジベースやFAQ、商品カタログなどのデータとChatGPTを連携させることで、「社内専用のAIサポートデスク」や「営業支援ボット」のような使い方が可能です。
ビジネスシーンでRAGを取り入れることで、単なる一般情報の生成にとどまらず、自社固有の情報を活かした精度の高い応答を実現できます。
信頼性と一貫性を求める業務では、特に有効な手段といえるでしょう。
ハルシネーション対策③:WEBブラウジング機能の活用
ChatGPTではすべてのユーザーに向けてWebブラウジング機能が開放されました。
Webブラウジング機能を活用すると、キーワード検索、ウェブページの閲覧、最新ニュースや天気予報などのリアルタイム情報を取得し、より正確で最新の情報を反映した回答を生成できるようになります。
| モデル | Webブラウジング機能 |
|---|---|
| ChatGPT-4o | |
| ChatGPT-o3 | |
| ChatGPT-o3-pro |
2024年7月7日に行われた東京都知事選の開票結果をChatGPT-4oに聞くと、自発的にWEBブラウジングし最新情報を取得して回答してくれました。
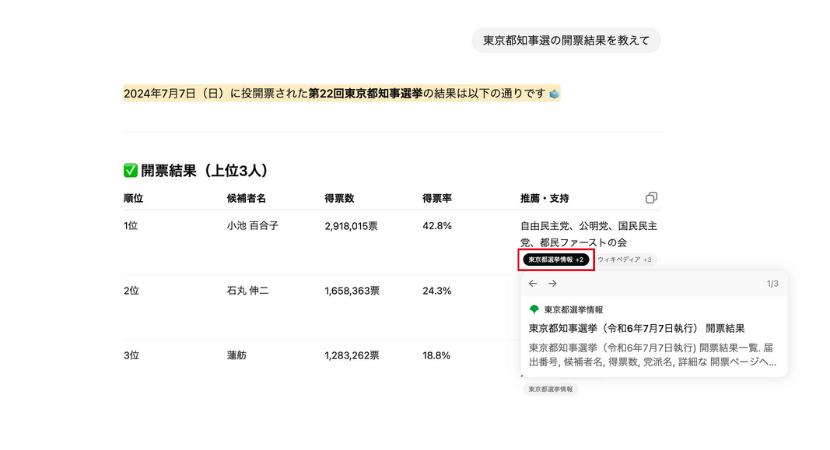
以下、NHKの選挙特設ページと比較しても情報が正しいことが確認できます。
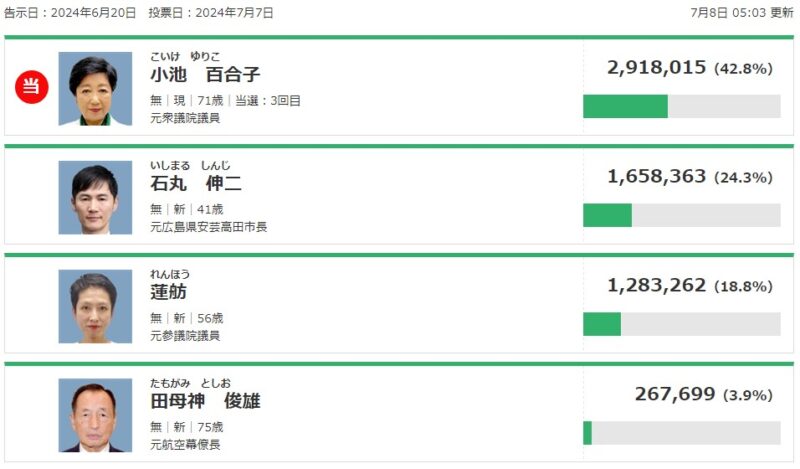
Webブラウジング機能を活用することで、ChatGPTの回答の精度を大幅に向上させることができます。

【ハルシネーション対策】ChatGPTに嘘をつかせないプロンプト

LLM(大規模言語モデル)は、プロンプト(質問文や指示)に基づいて回答を生成することから、プロンプトの質によってLLMの回答精度は大きく変化します。
ChatGPTを使う上で、ハルシネーションを防ぐための具体的なプロンプトを紹介します。
回答を制限したり情報源を開示させたり具体的に指示する
ChatGPTのパフォーマンスを最大限に引き出すためのプロンプト構築技術は「プロンプトエンジニアリング」とも呼ばれ、ハルシネーション(嘘をつく現象)の抑制にも一定の効果を発揮します。
一番有効なのは、ChatGPTに事実に基づいた回答を求めていることを明確にプロンプトに示すことです。
ChatGPT-4oの機能について、事実のみを箇条書きで教えてください。

引用元が記載され回答の根拠が明確になり、情報の信頼性を判断しやすくなります。
ほかにも、特定の分野に関する誤情報を頻繁に生成してしまう場合には、誤っている箇所や禁止事項を具体的に明示すると軌道修正させることができます。
- 〇〇についての情報は提示しないでください
- 〇〇は誤った認識です。正しくは▲▲です。
ファクトチェックを前提に情報元を明記させたり、すでに知っている正しい情報を先に提示したりすることで、無駄な工程を省き正しい情報を得ることができます。

ChatGPTに深呼吸をさせる
Google DeepMindの研究では、「深呼吸をして、この問題に一歩ずつ取り組もう」という言葉をプロンプトに加えるだけで、LLMの数学の問題における正答率が34%から80%にまで向上したという結果が出ています。
興味深いことに、この最新の研究で、DeepMind の研究者は、Google の PaLM 2 言語モデルで使用した場合、「深呼吸して、この問題に段階的に取り組んでください」が最も効果的なプロンプトであることを発見しました。このフレーズは、小学校の算数の文章題のデータセットであるGSM8Kに対するテストで 80.2 パーセントという最高の精度スコアを達成しました。比較すると、特別なプロンプトなしの PaLM 2 は、GSM8K で 34 パーセントの精度しか獲得できず、従来の「段階的に考えてみましょう」というプロンプトは 71.8 パーセントの精度を獲得しました。
出典:Ars Technica
まとめ
近年のAI技術の進歩により、ChatGPTは人間のように自然な文章を生成できるようになりましたが、時には「ハルシネーション」と呼ばれる嘘をつく現象が見られます。
ChatGPTが膨大なデータから質問への回答を優先し、内容の真偽を判断していないことが原因となります。
ハルシネーション対策としては、ファクトチェックの実施、情報源を明記させるプロンプトの利用、WEBブラウジング機能の活用などが有効です。
ChatGPTの情報を鵜呑みにするだけではなく、一次情報や専門家の意見も参考にすることでビジネスシーンなど幅広い業務に活用させましょう。