

画像生成AI「Stable Diffusion」を使ってみたいけれど、始め方が分からず悩んでいませんか?
本記事では、Stable Diffusion Web UIによるローカル環境での使い方を中心に、導入方法から基本操作、応用例まで丁寧に解説します。
さらに、onlineでの使い方や、Stable Diffusionの利用にかかる料金、そして著作権・商用利用・NSFW設定の注意点についてもご紹介します。
Stable Diffusionとは?最新版SDXL/3.5の特徴

Stable Diffusionは、入力されたテキストをもとに高品質な画像を生成するAIツールです。2022年8月にリリースされ、このAIは潜在拡散モデルを使用して、ユーザーのプロンプトに基づいた多様なスタイルの画像を生成します。
リアルな画像やアートスタイルの画像を短時間で作成できるため、クリエイティブなプロジェクトに最適です。
Stable Diffusionの特徴
Stable Diffusionの特徴として、オープンソースであることが挙げられます。自分のパソコンにインストールして使用する場合、モデルの料金はかかりません。
ただし、クラウドサービスやWebアプリケーションを通じて利用する場合、有料プランが設定されていることがあります。基本的な機能は無料でも、高度な機能や大量の画像生成には料金が必要となるケースが多いです。
一部のケースでは料金が発生しますが、Stable Diffusionは他の商用AIサービスと比べて非常にコスト効率が高いツールです。利用条件や料金プランを確認し、自分のニーズに合った方法を選ぶことが重要です。
- ローカルに環境構築する場合は無料で利用可能
- クラウドサービスやWebアプリケーションを使用する場合、有料のケースもある
また、オープンソースであるため、コミュニティによって継続的に改善されています。開発者が新しい機能やモデルを追加でき、自分自身でカスタマイズしたり、独自の環境で動かしたりすることも可能です。この柔軟性が、Stable Diffusionを多くのプロジェクトで利用される理由の一つです。
最新モデルSDXLと3.5の特徴
最新モデルとして、Stable Diffusion XL(SDXL)と、Stable Diffusion 3.5があります。モデルの違いは、解像度、モデルサイズ(パラメータ数)、推奨VRAMとなっています。
| 項目 | SDXL | SD 3.5 Medium | SD 3.5 Large |
|---|---|---|---|
| 公開年 | 2023年 | 2024年 | 2024年 |
| 解像度 | 1024×1024 | 0.25~2MP (例:768×768〜1440×1440) | ~1MP (例:1024×1024、1280×800) |
| モデルサイズ | Base:3.5B Base+Refiner:6.6B | 2.5B | 8.1B |
| 推奨VRAM | Baseのみ:8GB Refinerあり:16GB | 9.9GB | 24GB |
SDXLはBaseとRefinerの2つのモデルを組み合わせたモデルであり、ベースモデルは単体でも使用可能です。生成できる画像の解像度は1024×1024であり、VRAMはベースモデルのみであれば8GBで動きます。Refinerも組み合わせる場合は16GB以上のVRAMが推奨されます。
一方3.5 Mediumは解像度が0.25~2MP、推奨VRAMは約10GBと比較的軽くなっており、3.5 Largeは解像度が~1MP、推奨VRAMは24GBとかなりのスペックが要求されます。また、3.5にはLargeを蒸留したLarge Turboもあり、Largeよりも大幅に高速な生成が可能です。
まずは3.5 MediumやSDXLのベースモデルを試し、VRAMに余裕があれば3.5 LargeやSDXLも使ってみましょう。
Stable Diffusionを始める3つの方法(ローカル・クラウド・オンライン)

Stable Diffusionを利用するには、ローカル・クラウド・オンラインという主に3つの方法があります。
それぞれの方法には、異なるメリットとデメリットがあるので、自分に合った方法を選ぶことが大切です。
Stable Diffusionをローカル環境に構築して使う
Stable Diffusionをローカル環境で使用する際の最大のメリットは無料で利用できることです。オープンソースとして提供されているため、個人利用であればライセンス料などを気にせずに使用できます。生成する画像の枚数やプロンプトに制限がないため、自分好みにカスタマイズして自由度の高い画像生成が可能です。
一方で、ローカル環境でモデルを動かすには手間がかかります。特に技術的な知識が必要となるため、初心者には少し難しく感じるかもしれません。
また、高性能なPCが必要であり、スペックが低いと動作が遅くなることがあります。具体的には、以下のスペックが推奨されています。
- Windows 10以上のOS
- メモリ16GB以上
- VRAM12GB以上のGPU
Stable Diffusionをローカル環境で利用することで得られる自由度とコストメリットは大きいですが、それに伴う技術的なハードルも考慮する必要があります。
ローカル環境での具体的な構築手順や、より詳細なメリット・デメリットは以下の記事で解説しています。

Stable Diffusionをクラウドサービスに構築して使う
Stable Diffusionをクラウドサービスで利用する方法は、高性能なPCを持っていない方や手軽に始めたい方に最適です。
最も一般的なサービスとしてGoogle Colabがあげられます。Google Colabは、Googleが提供するクラウドベースのJupyterノートブック環境です。GPUを使えるため、Stable Diffusionのような計算量の多いタスクに適しています。

Google Colabは無料でも利用可能です。ただし、GPU利用・実行時間に制限があるため、安定運用のためには有料プランや別環境の利用も検討しましょう。
導入方法は以下の記事で解説しています。

Google Colabの他にも、Paperspace GradientやVast.aiなどのクラウドサービスがあります。Paperspace Gradientは使いやすいインターフェースと無料プランがあり、初心者にも適しています。一方、Vast.aiは多種多様なGPUから選べ、自分の予算やニーズに柔軟に合わせられます。
これらのクラウドサービスを利用することで、高性能なPCがなくてもStable Diffusionを活用できます。
Stable DiffusionをオンラインのWebサービスで使う
Stable Diffusionを利用する最も簡単な方法の一つは、企業が提供するWebサービスを活用することです。無料または定額制で始められるため、初心者の方に特におすすめです。
無料で利用できるWebサービスとして、Stable Diffusion Online・Dream Studio・Mage.space・Hugging Faceがあります。有料プランのみの提供ですが、ConoHa AI Canvasというサービスもあります。
| サービス | 無料プラン | 有料プラン |
|---|---|---|
| Stable Diffusion Online | 10クレジット/日 | Pro:10ドル/月(年払い) ※約1,550円 Max:20ドル/月(年払い) ※約3,100円 |
| Dream Studio | サインアップ時に1,000クレジット付与 | Basic:12ドル/月 ※約1,860円 |
| Mage.space | サインアップ時に300Gems付与 | Basic:10ドル/月 ※約1,550円 |
| Hugging Face | 2 vCPU16GBが利用可能 | Nvidia T4 small(GPU):0.40ドル/時 ※約62円 |
| ConoHa AI Canvas | – | エントリー:1,100円 |
ConoHa AI CanvasはGMOが提供するサービスで、国内のデータセンターを使用しているため、安全性と通信速度に優れています。月額1,100円から利用可能で、高性能なNVIDIA GPUをクラウド上で使用することにより、高品質な画像生成を手軽に始められます。有料サービスとしては月額1,100円からとリーズナブルに利用できる点が魅力です。
導入方法は以下の記事で詳しく解説しています。

\ MiraLab AIの読者限定で500円割引適用中 /
まずはオンライン版で画像生成を試して感触を掴み、問題がなければローカル環境でSDXLのベースモデルを動かしてみましょう。本格的な画像生成を行う場合は、ConoHa AI CanvasでクラウドGPUを使って高速化することをおすすめします。
【初心者向け】Web版のStable Diffusionでまずは最初の1枚を作ってみよう

Web上でStable Diffusionを動かし、画像を1枚生成する方法を紹介します。
各Webサービスについて、それぞれの始め方や特徴、設定できる項目の違いが分かります。
Hugging FaceでStable Diffusionを使用する
Hugging FaceはAIモデルやデータセットを共有できるプラットフォームです。
Hugging FaceではAIモデルを構築するための「Hugging Face Spaces」という機能を提供しており、Hugging Face Spaces上でStable Diffusionを動かすこともできます。
画像生成のためには専用のソースコードを用意する必要があるため、詳細なカスタマイズを行いたい開発者向けの利用方法となります。
Hugging FaceでStable Diffusionを使用する方法は以下の通りです。
右上のプロファイルアイコンをクリックし、「Create new Space」をクリックしてSpaceを作成しましょう。
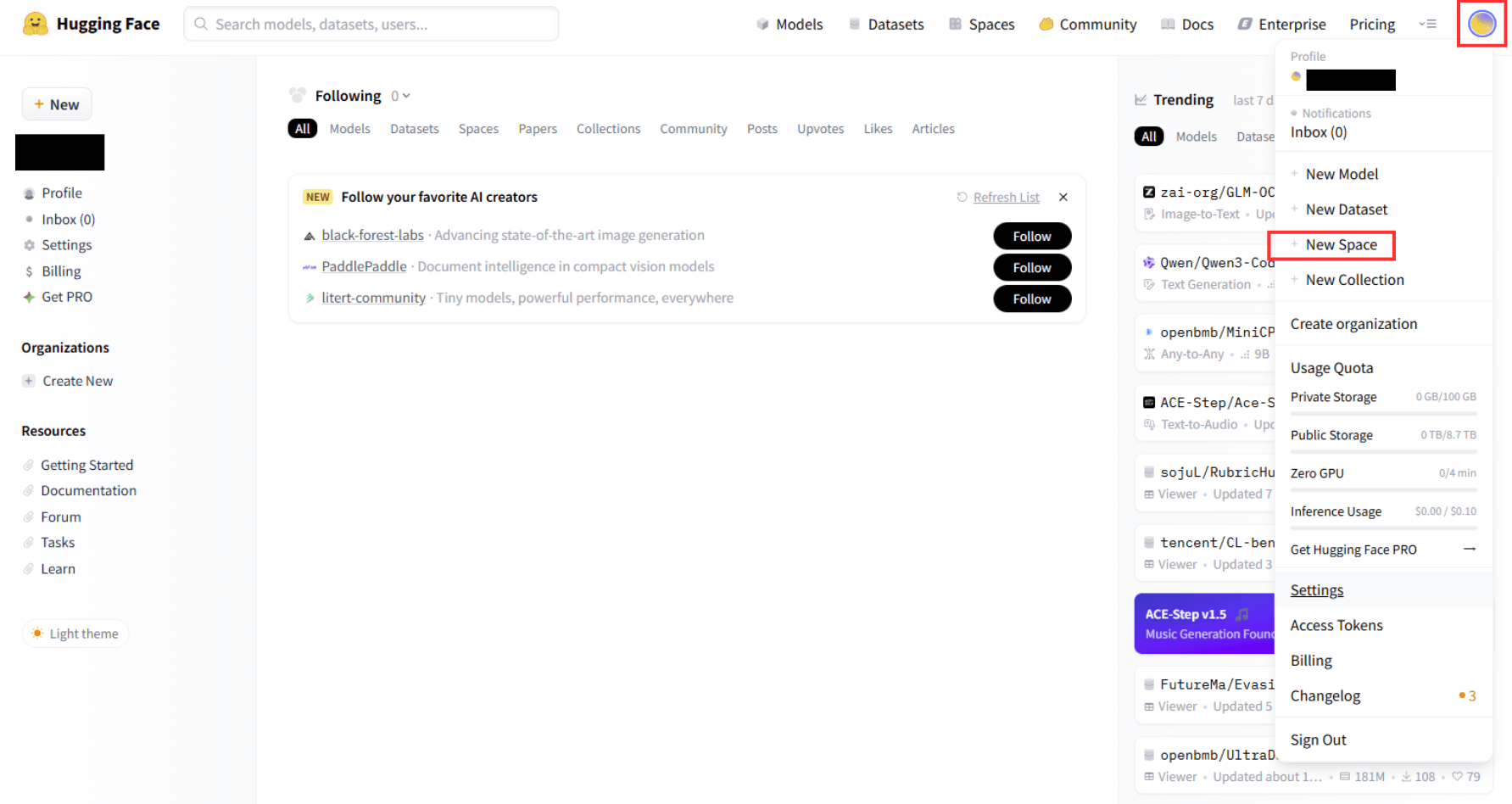
Stable Diffusionを動かすために必要な以下の2つのファイルをローカル環境で作成します。
- requirements.txt
-
diffusers transformers accelerate torch gradio invisible-watermark>=0.2.0 sentencepiece safetensors - app.py
-
import os import torch import gradio as gr from diffusers import StableDiffusionXLPipeline MODEL_ID = "stabilityai/stable-diffusion-xl-base-1.0" device = "cuda" if torch.cuda.is_available() else "cpu" dtype = torch.float16 if device == "cuda" else torch.float32 pipe = StableDiffusionXLPipeline.from_pretrained( MODEL_ID, torch_dtype=dtype, variant="fp16" if device == "cuda" else None, use_safetensors=True, ) pipe = pipe.to(device) def generate_image( prompt, negative_prompt="", steps=30, guidance_scale=7.0, width=1024, height=1024 ): image = pipe( prompt=prompt, negative_prompt=negative_prompt if negative_prompt else None, num_inference_steps=steps, guidance_scale=guidance_scale, width=width, height=height ).images[0] return image demo = gr.Interface( fn=generate_image, inputs=[ gr.Textbox(label="Prompt", lines=3, value="Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"), gr.Textbox(label="Negative Prompt", lines=2, value=""), gr.Slider(10, 50, value=30, step=1, label="Steps"), gr.Slider(1.0, 15.0, value=7.0, step=0.5, label="Guidance Scale"), gr.Slider(512, 1024, value=1024, step=64, label="Width"), gr.Slider(512, 1024, value=1024, step=64, label="Height"), ], outputs=gr.Image(label="Generated Image"), title="SDXL on Hugging Face Spaces", description="Stable Diffusion XL Base 1.0 demo running on Hugging Face Spaces" ) if __name__ == "__main__": demo.launch()
今回はSDXLのベースモデルを使用しており、ソースコードは以下のドキュメントを参考にしています。
作成したSpaceの画面右上の「Files」タブをクリックし、ファイルをアップロードします。
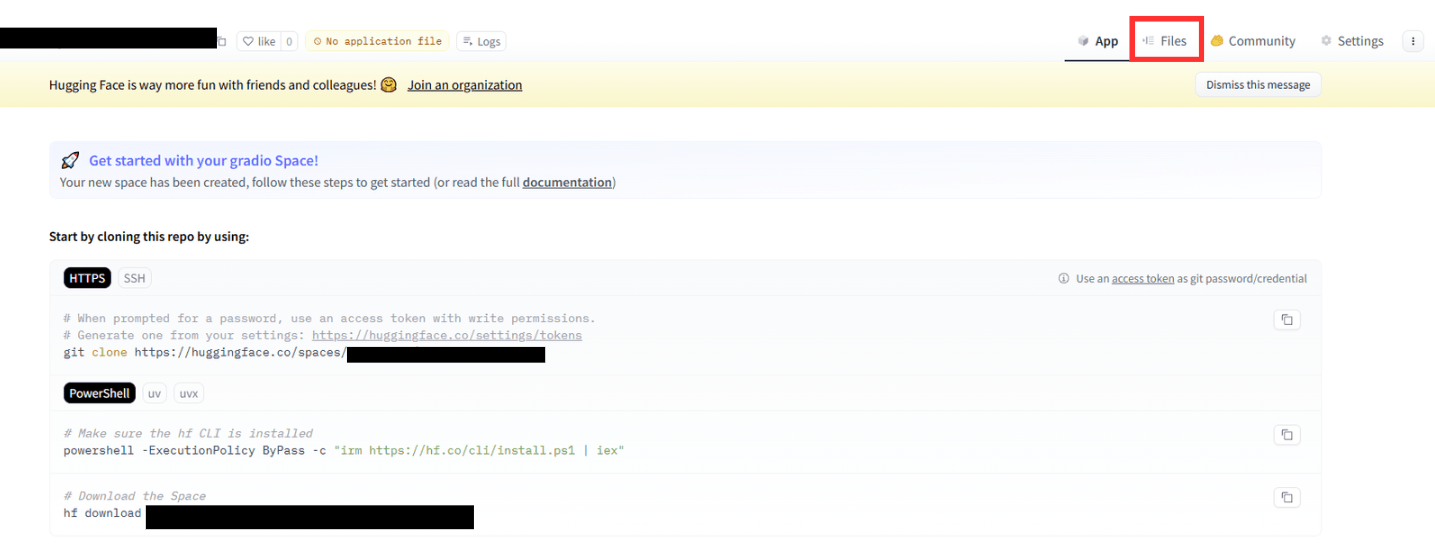
ファイルをアップロードすると、自動で環境構築が開始されます。
左上に表示されるステータスが「Building」から「Running」に変わったら「App」タブをクリックしてください。
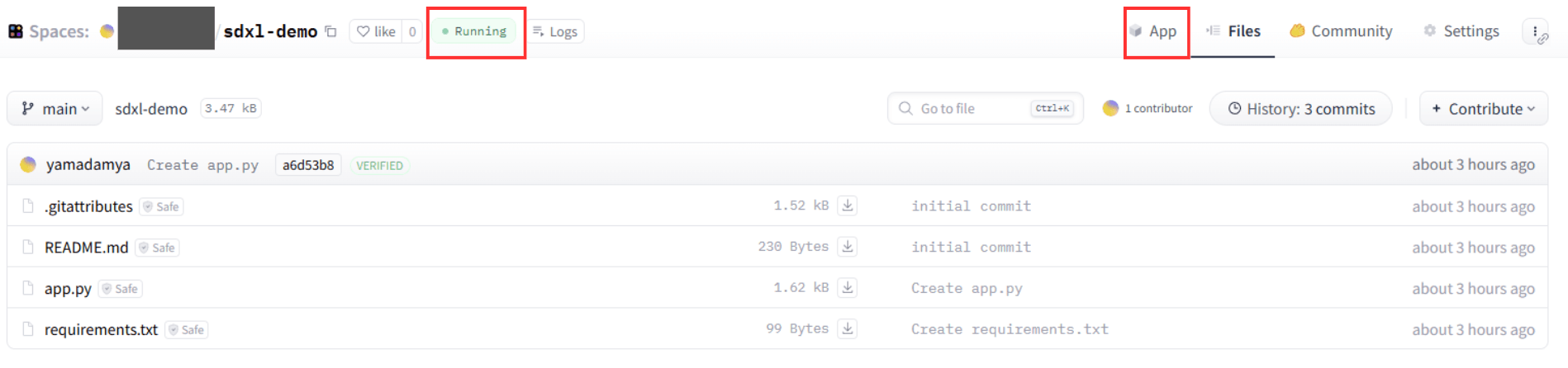
以下のようにSDXLを操作するWeb UIが表示されます。
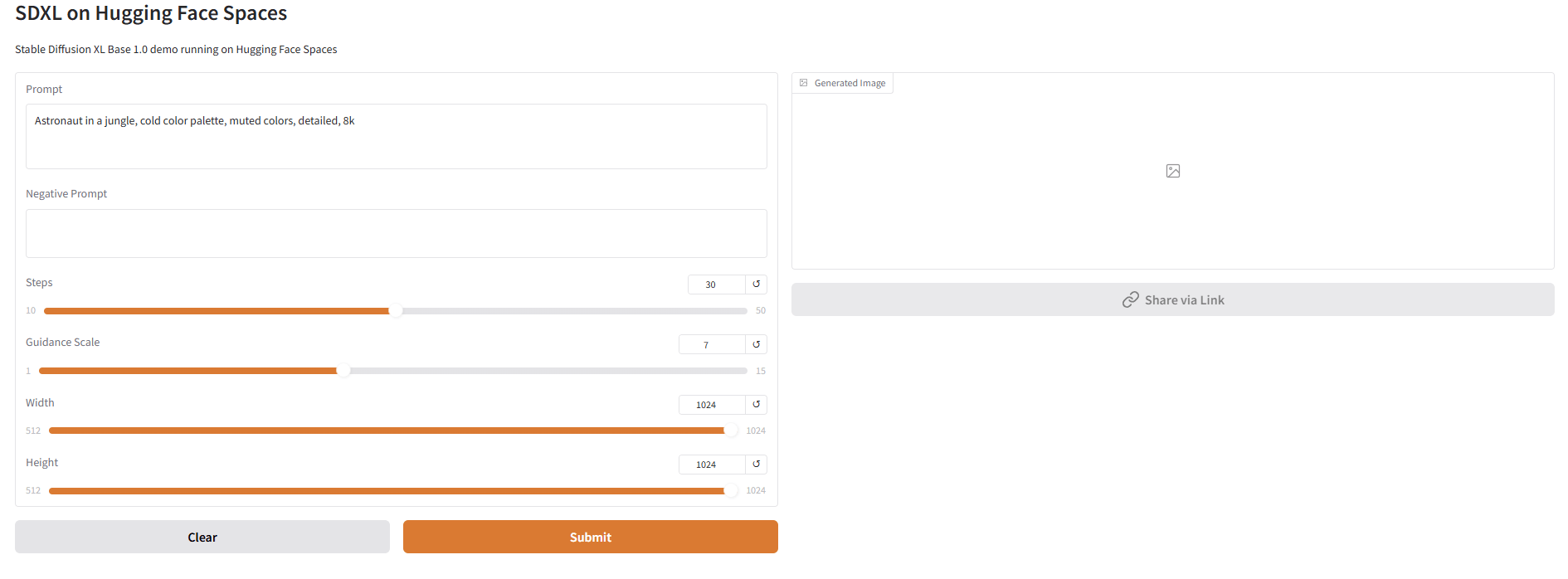
表示されたWeb UIから画像生成が可能です。
今回はPromptに「神秘的な宇宙の画像」と入力し、以下の画像を生成しました。

今回のソースコードでは、プロンプトの他に以下を指定できるようにしています。
- Negative Prompt
- Steps
- Guidance Scale
- Width
- Height
「Negative Prompt」には、反映したくない要素を文章で入力できます。
「Guidance Scale」では、出力される画像がどれくらいプロンプトに従うかを調整します。値を高くすることでプロンプトにより忠実な画像が出力されますが、品質が下がる場合もあるため注意してください。
以下の記事でも同様に、Hugging Face Spaceを使ってオープンソースのモデルを使用しています。詳細な手順はこちらの記事もご確認ください。

開発元のStability AIもHugging Face Spaceを使ったデモを公開しています。しかし、2026年3月時点では公開が一時停止されていました。
Hugging Face上でより簡単にStable Diffusionを試したい場合は、以下のデモが再開されていないか確認してみてください。
https://huggingface.co/spaces/stabilityai/stable-diffusion-3.5-medium
Stable Diffusion Onlineで今すぐ画像生成
Stable Diffusion OnlineはGoogleアカウントがあれば、登録不要ですぐに画像生成を始められます。最初の1枚をすぐに作りたい人向けのサービスです。
入力欄にプロンプトを入力しましょう。「描く」ボタンをクリックすると、画像生成が開始されます。
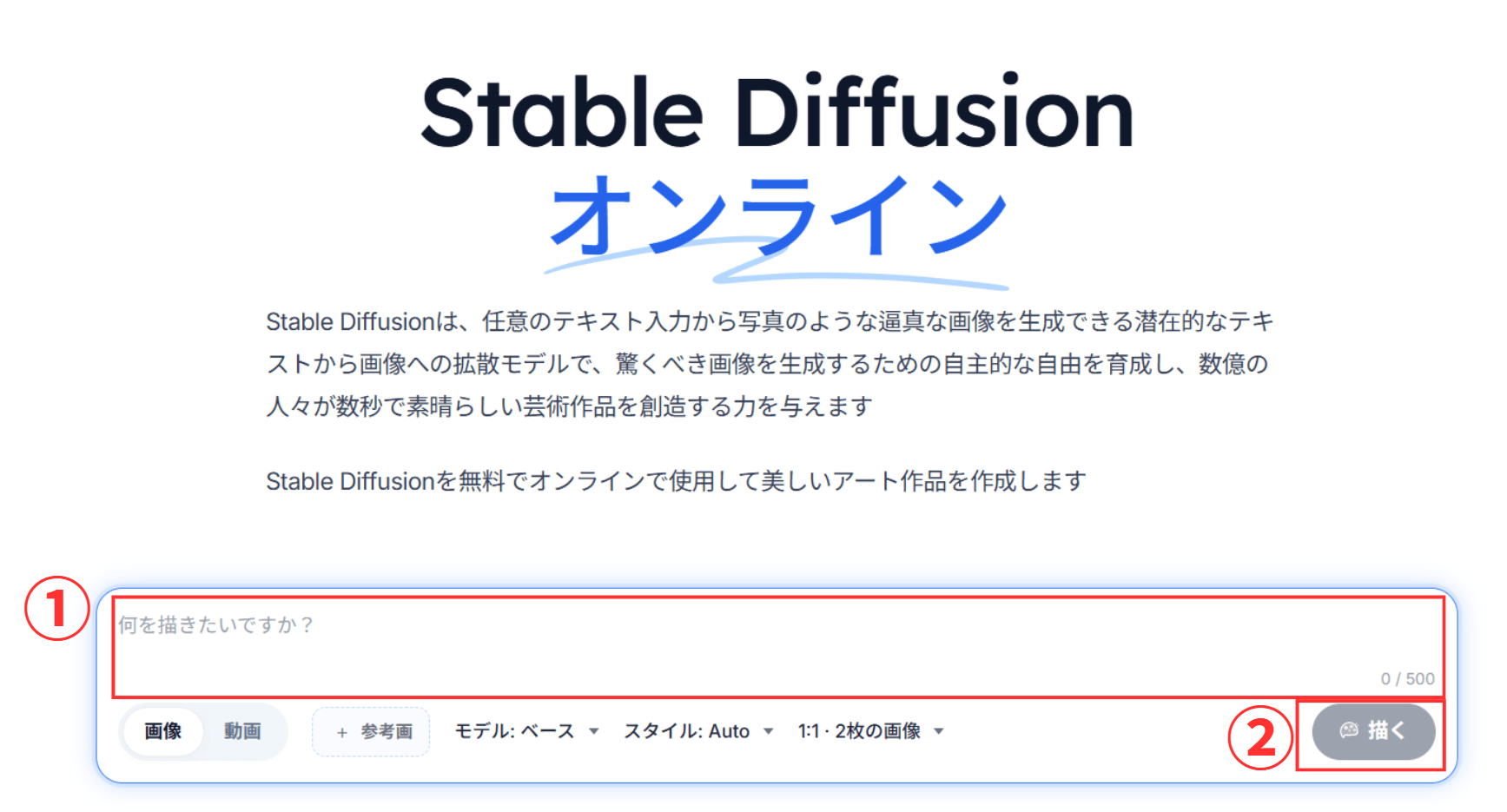
今回「神秘的な宇宙の画像」というプロンプトを入力すると、以下の画像が生成されました。

画像の通り、無料プランではstablediffusionweb.comのすかしが入ります。
Stable Diffusion Onlineの無料プランでは、プロンプトの他に以下の要素を指定できます。
- モデル(ベース or 強化)
- スタイル(自動、リアルスタイル、アニメーションなど)
- アスペクト比
- 出力数量(1 or 2)
- Guidance Scale(ガイダンス強度)
- 固定されたシードの使用(有効 or 無効)
「Guidance Scale(ガイダンス強度)」は、プロンプトを考慮する強さを示します。Stable Diffusion Onlineでは1~30の整数でGuidance Scaleを設定できます。
Stable Diffusionでは、シード値を固定することで画像生成のランダム性を抑えます。「固定されたシードの使用」を有効にすることで、同じプロンプトから非常に近い画像を生成できるようになります。
Dream StudioでStable Diffusionを使う
Dream Studioは、Stable Diffusionを開発・提供するStability AIが運営するサービスです。プロンプトの補完機能を活用して、手軽にStable Diffusionの性能を引き出したい人に向いています。
画像の入力欄にプロンプトを入力し、「Create」ボタンをクリックすると画像が生成されます。
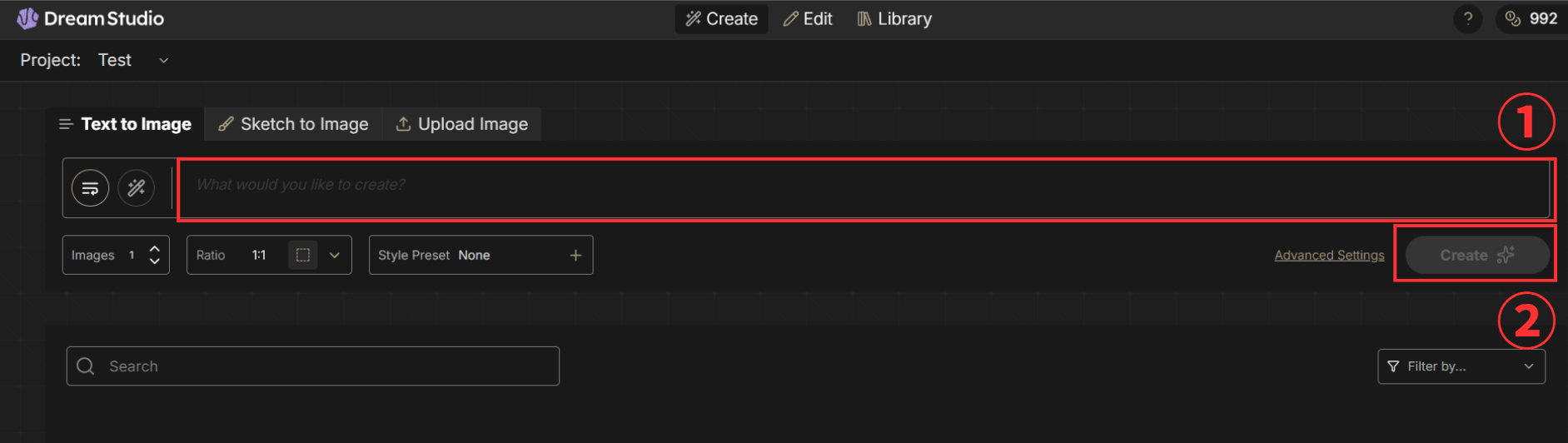
Dream Studioで「神秘的な宇宙の画像」というプロンプトを送信すると、以下のような画像が生成されました。

Dream Studioの無料プランでは、プロンプトの他に以下の要素を指定できます。
- Images(1~4)
- Ratio
- Style Preset(3D Model、Analog Film、Animeなど)
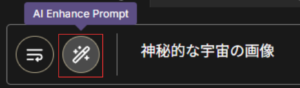
Dream Studioでは、「AI Enhance Prompt」も利用可能です。この機能を使うと、Stable Diffusionに適した形式(Danbooru形式)にプロンプトを変換できます。
入力欄にプロンプトをプロンプトを入力し右隣のボタンをクリックすると、AIによって英語の短文で表現されたプロンプトに変換されます。

変換後のプロンプトを使うと以下の画像が生成されました。手という余分な要素は排除され、最初の画像よりもプロンプトに忠実であることが確認できます。

Mage.spaceでStable Diffusionを試す
Mage.spaceは様々なモデルを使って画像を生成できるサービスです。Stable Diffusion以外のモデルも使いたい人にはMage.spaceの使用が向いています。
画面中央下部に表示される入力欄の設定を行います。
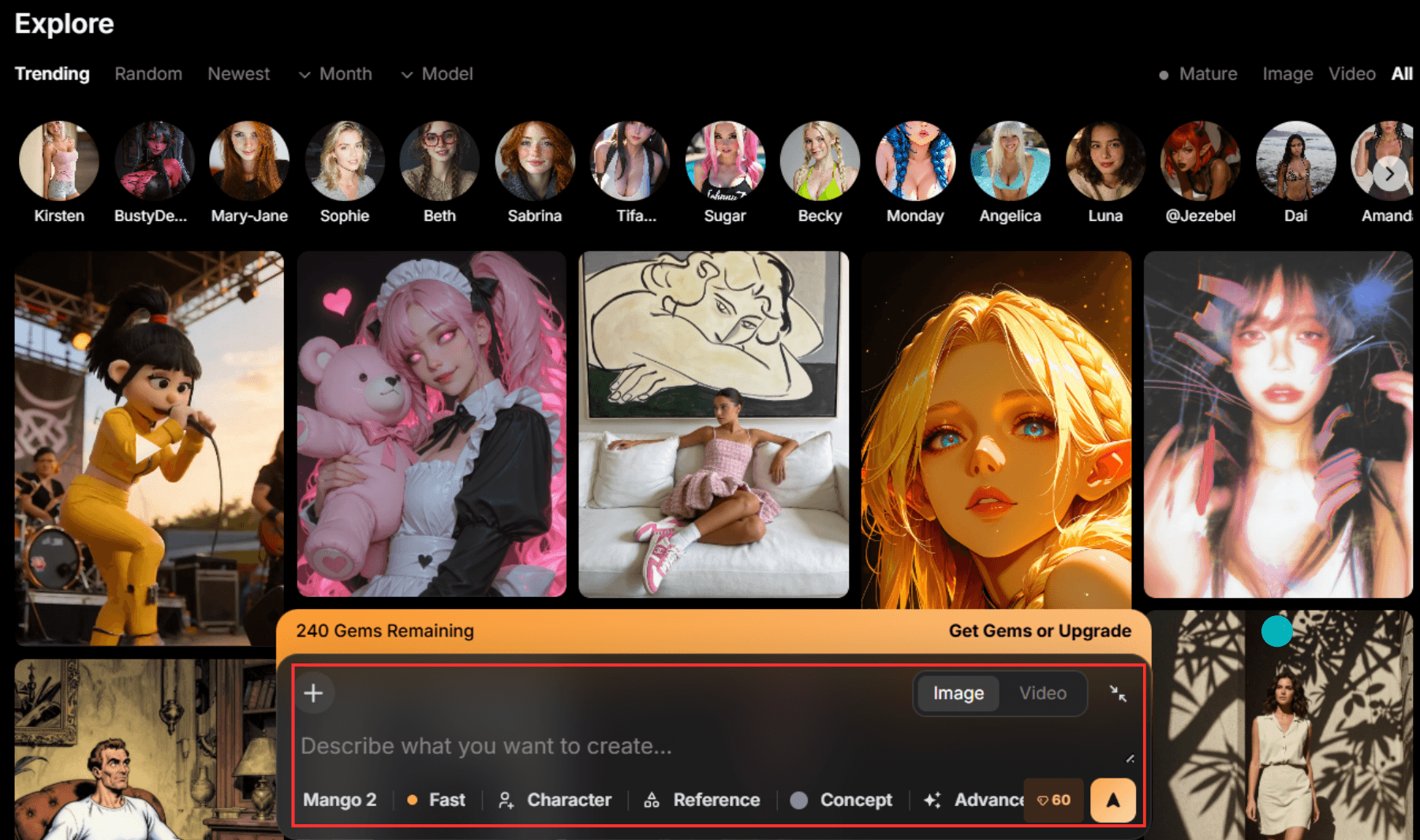
まずは左下のモデル名をクリックし、検索欄に「stable diffusion」や「sdxl」と入力して使用したいモデルを検索してください。
モデルが表示されるので、使用したいモデルをクリックします。
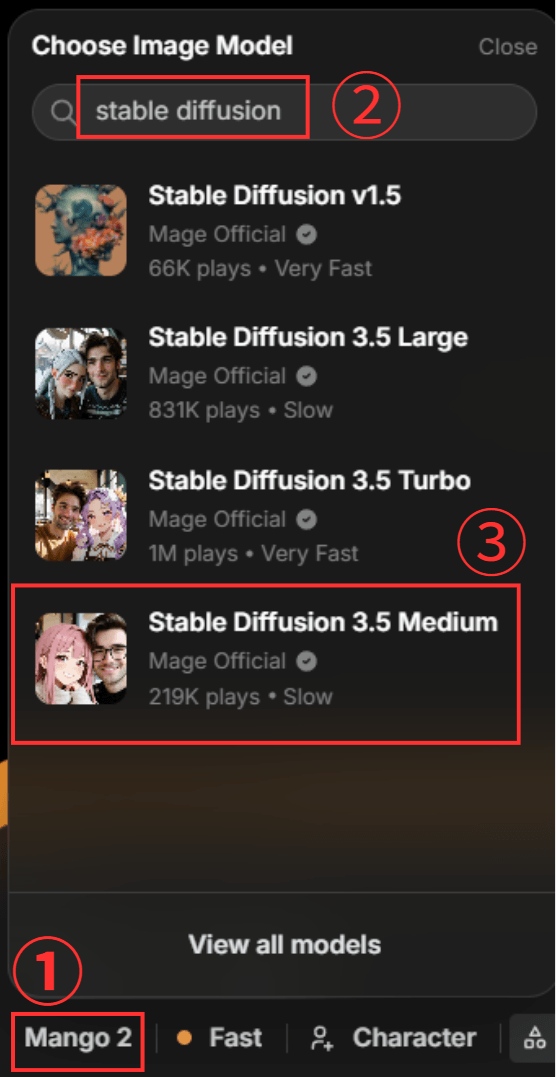
今回は「Stable Diffusion 3.5 Medium」を選択しました。
モデル選択後にプロンプトを入力し、開始ボタンをクリックします。
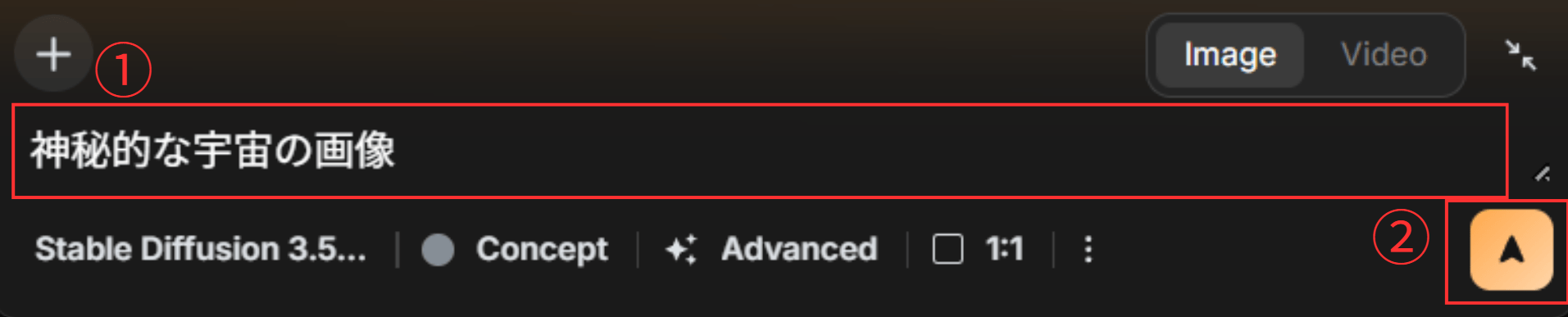
「神秘的な宇宙の画像」というプロンプトを送信すると、以下の画像が生成されました。

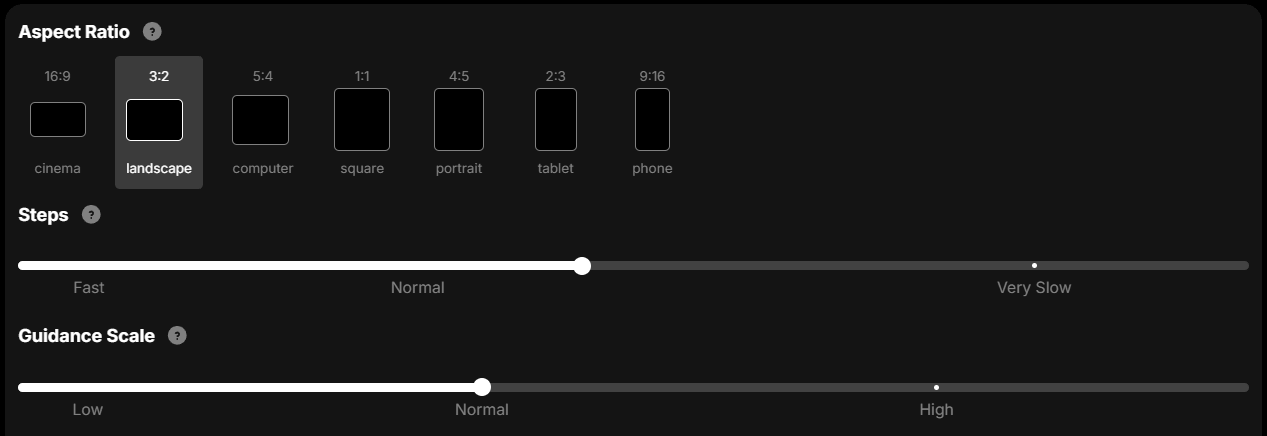
Mage.spaceでStable Diffusionを使用する場合、「Advanced」ボタンから以下の内容を指定できます。
- Aspect Ratio
- Steps
- Guidance Scale
Stable Diffusionを使用できる他のサービスについては、以下の記事もご確認ください。

導入前に確認すべきPCスペックと費用

Stable Diffusionを導入する前に、導入するPCのスペックや利用にかかる費用を確認しておくようにしましょう。
Stable Diffusionに必要なPCスペック
Stable Diffusionをローカルで動かす場合は、ある程度のPCスペックが必要になります。
必要スペックはモデルによって異なりますが、一般にIntel Core i5以上のCPUやVRAM12GB以上のGPU、16GB以上のメモリがあると快適に使えるでしょう。

ただし、3.5 Largeなどの大きなモデルを利用する場合は、24GB以上のVRAMや32GB以上のメモリが必要となります。
軽めのモデルやLoRAを活用する場合はVRAM6GBでも動くでしょう。また、OSはWindowsが推奨されています。
Currently most functionality in the web UI works correctly on macOS, with the most notable exceptions being CLIP interrogator and training. Although training does seem to work, it is incredibly slow and consumes an excessive amount of memory. CLIP interrogator can be used but it doesn’t work correctly with the GPU acceleration macOS uses so the default configuration will run it entirely via CPU (which is slow).
和訳:現在、Web UI の機能のほとんどは macOS 上で正常に動作していますが、CLIP インタロゲーターとトレーニング機能は顕著な例外となっています。トレーニング機能は一応動作するようですが、処理速度が極めて遅く、過剰なメモリを消費します。CLIP インタロゲーターは使用可能ですが、macOS が使用する GPU アクセラレーションと正しく連携しないため、デフォルトの設定では完全に CPU 経由で実行され(処理が遅くなります)。
出典:Installation-on-Apple-Silicon
Stable Diffusionの利用にはCPUの性能よりもGPUの性能が大きく影響するため、PCを選ぶ際は特にGPUに注目するようにしましょう。
なお、Webサービスやクラウドサービスを通じてStable Diffusionを利用する場合は、クラウド上のGPUを使用するため、PCのスペックを気にする必要はありません。
Stable Diffusionの利用にかかる費用
Stable Diffusionはローカル環境で利用する場合は料金がかかりません。ただし、導入するためにPCを購入する場合は初期費用が高くなるほか、画像生成中の電気代などのランニングコストはかかります。
一方で、クラウドサービスやWebサービスで利用する場合は毎月の費用がかかります。
長期かつ定期的に利用する場合はローカル、ときどき利用する場合やハイエンドモデルをお試しで使いたい場合はクラウドサービスやWebサービスを利用するとより費用を抑えられるでしょう。
最初は無料のサービスを使って機能を試し、本格利用する場合は予算に合った導入方法を選びましょう。
Stable Diffusion Web UI(AUTOMATIC1111/FORGE)インストール手順

ここでは、Stable Diffusion Web UIのインストール及びセットアップ手順を、Windowsのローカル環境・Docker・Google Colab別にご紹介します。
代表的なStable Diffusion Web UIとして、AUTOMATIC1111とForgeがあります。
AUTOMATIC1111は歴史が長く、ドキュメントが充実しており使いやすいでしょう。ForgeはVRAMを節約でき、生成速度も向上しているため、PCスペックに不安がある方はForgeの方がおすすめです。
この記事では、AUTOMATIC1111のインストール手順を解説していきます。
Windowsでのセットアップ手順
まずはWindowsのローカル環境でのセットアップ手順をご紹介します。
Stable Diffusionをローカルで利用するには、Pythonが必要となります。
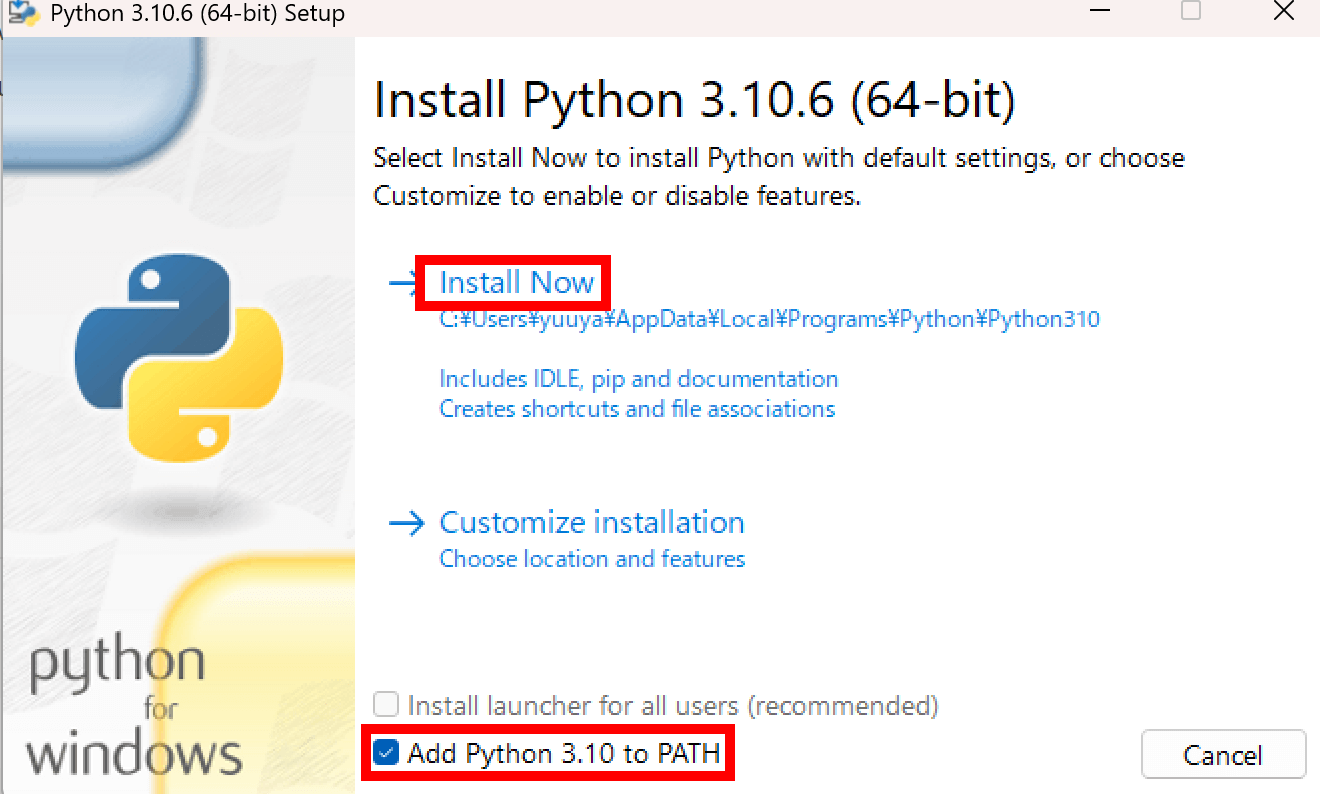
Pythonの公式サイトから、インストーラをダウンロードしましょう。
ダウンロードしたインストーラを開き、「Add python 3.10 to PATH」にチェックを入れて「Install Now」をクリックすると、Pythonがインストールできます。
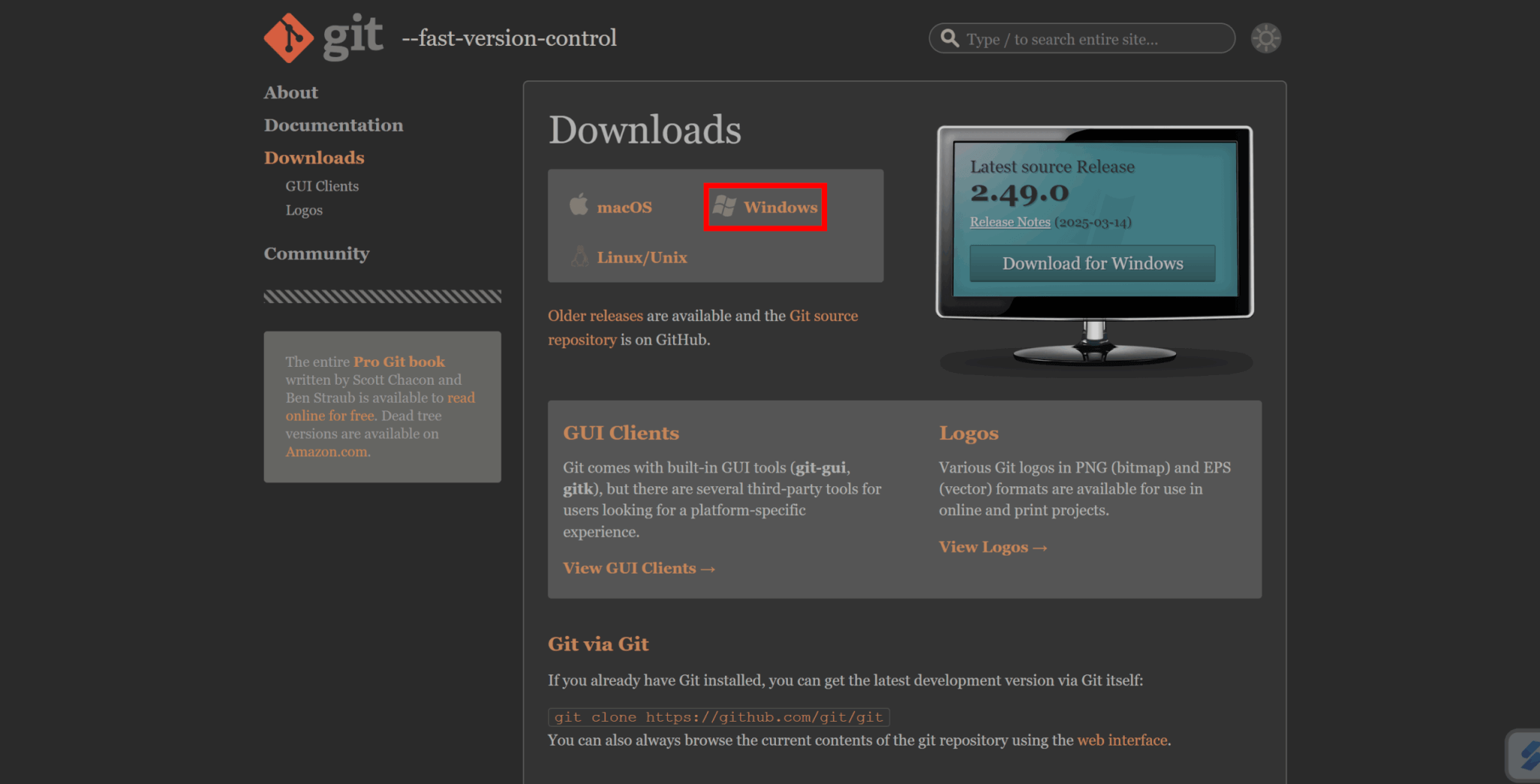
Stable Diffusionの利用にはGitも必要となります。
Gitの公式サイトから、環境に合ったインストーラをダウンロードしましょう。
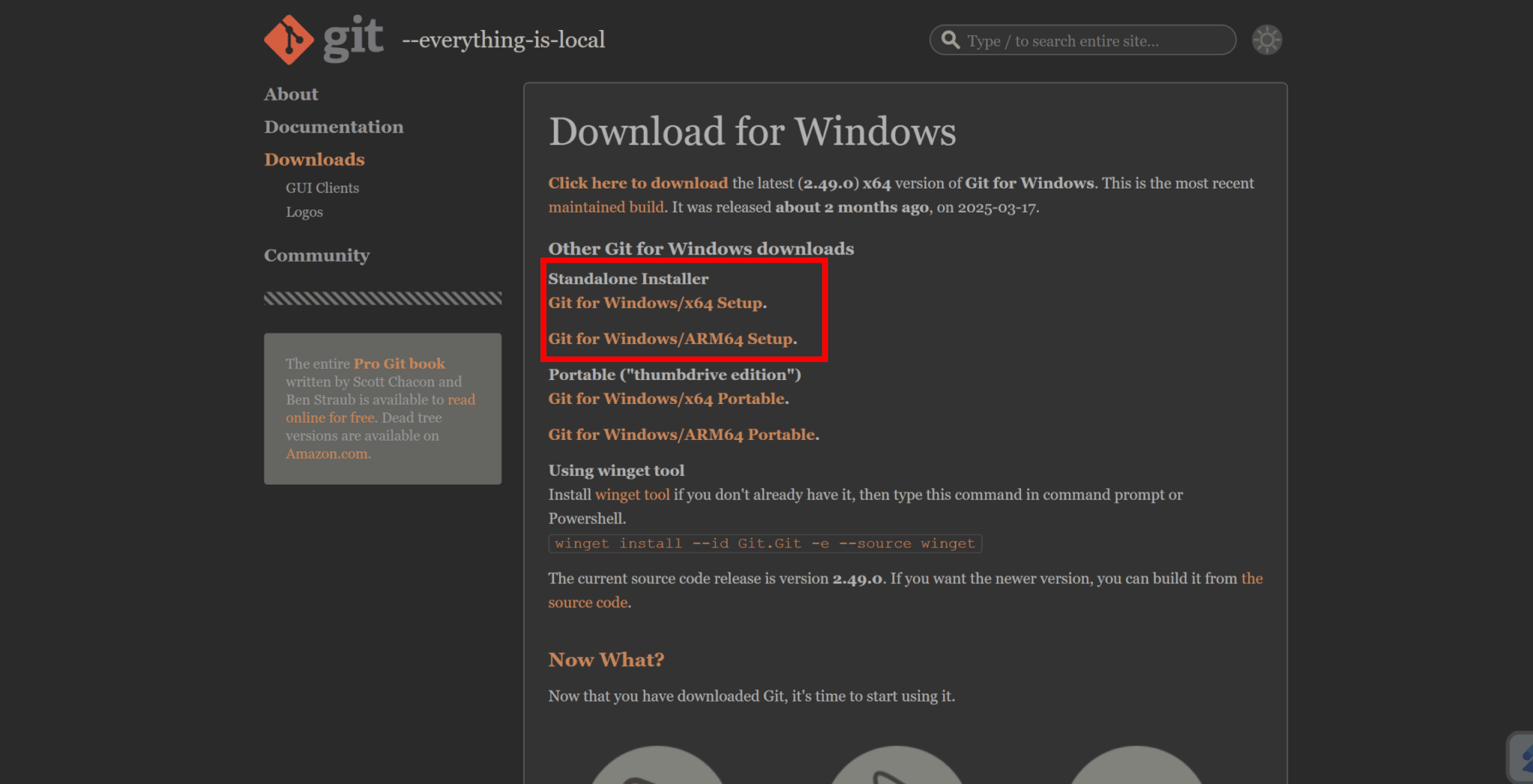
インストーラを起動し、指示に従って進めていくと、Gitをインストールできます。
Stable Diffusion WebUI関連のファイルを格納するフォルダを作成し、そのフォルダ内で右クリックをして「Open Git Bash here」をクリックします。
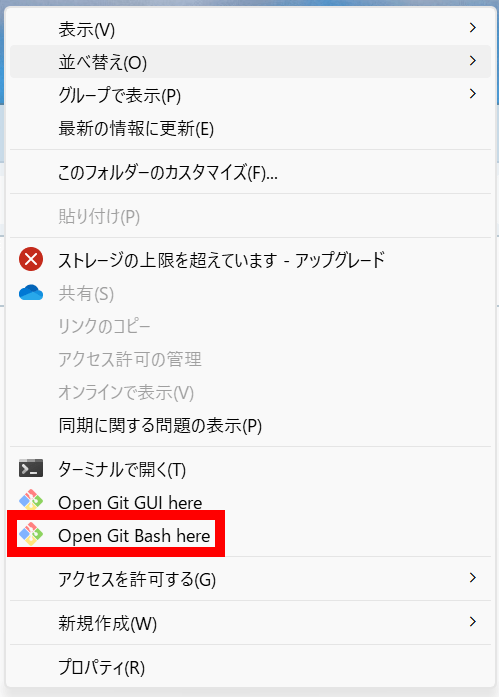
ターミナルを開いた後、次のコマンドを入力してStable Diffusion Web UIをローカル環境にダウンロードします。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitフォルダにWeb UIのフォルダが格納されており、そのフォルダ内にあるwebui-user.batファイルを実行すると、Stable Diffusion Web UIが起動できます。
なお、初回起動は時間がかかるので、気長に待ちましょう。
Dockerでのセットアップ手順
次に、Dockerでのセットアップ手順を解説します。
Dockerの公式サイトから、利用環境に合ったDocker Desktopのインストーラをダウンロードします。
インストーラを起動してDocker Desktopをインストールします。
インストール完了後、「Close and restart」をクリックすると、PCが再起動されます。
NVIDIA GPUを利用している場合は、利用しているGPUに合ったNVIDIA CUDA Toolkitをインストールしましょう。
OSがWindowsの場合は、WSL2をインストールします。
WSL2とは、Windows上でLinuxを仮想的に動かすためのツールです。
まずはWindows PowerShellを右クリックして管理者として実行します。
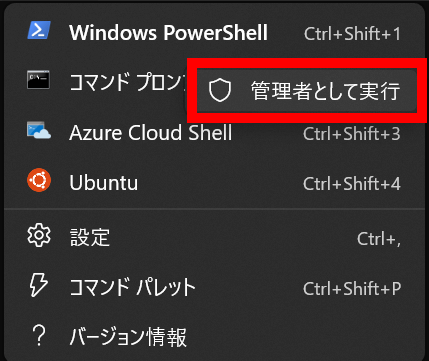
以下のコマンドを入力してWSL2をインストールします。
wsl --installインストール完了後は再起動し、ユーザー名とパスワードを設定することでWSL2を利用できるようになります。
Stable Diffusionはメモリを大量に使用するため、メモリの割り当てを増やしておきましょう。
C:/Users/[ユーザー名]/.wslconfigファイルを作成し、以下の内容を記載します。
[wsl2]
memory=13GB
swap=128GBファイル変更後、PCを再起動しましょう。
次のコマンドを入力することで、Docker版Stable Diffusion Web UIのリポジトリをクローンできます。
git clone https://github.com/AbdBarho/stable-diffusion-webui-docker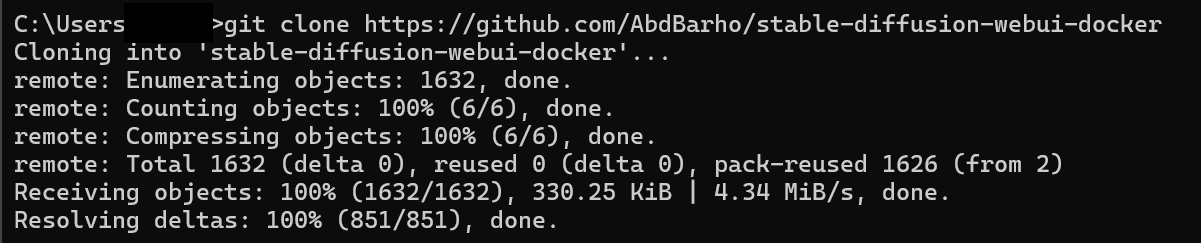
以下のコマンドを実行してディレクトリを移動します。
cd stable-diffusion-webui-dockerそして、次のコマンドを実行してStable Diffusionのコンテナを定義します。
docker compose --profile download up --build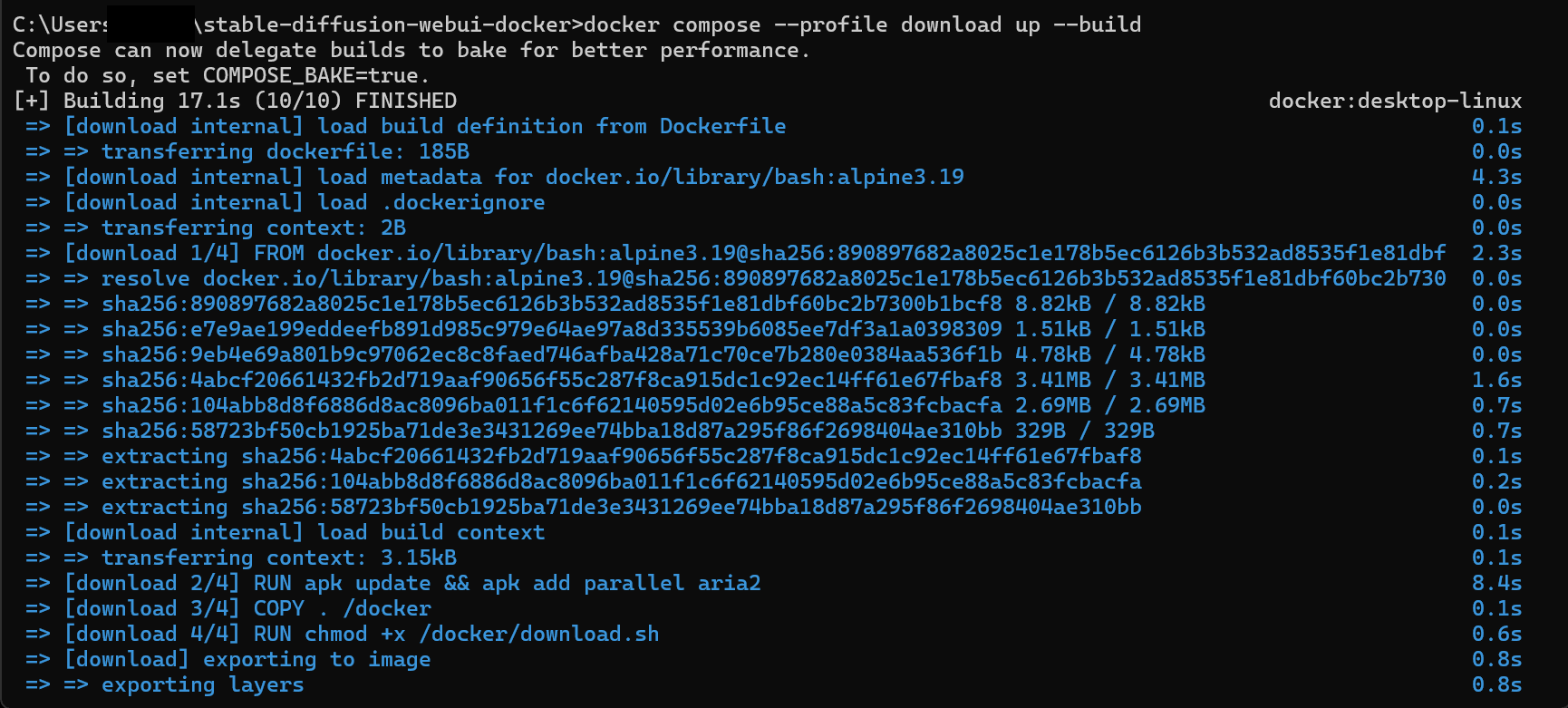
なお、コマンドの実行前にDocker Desktopを起動しておきましょう。
以下のコマンドを入力すると、Stable Diffusionを実行できます。
docker compose --profile auto up --build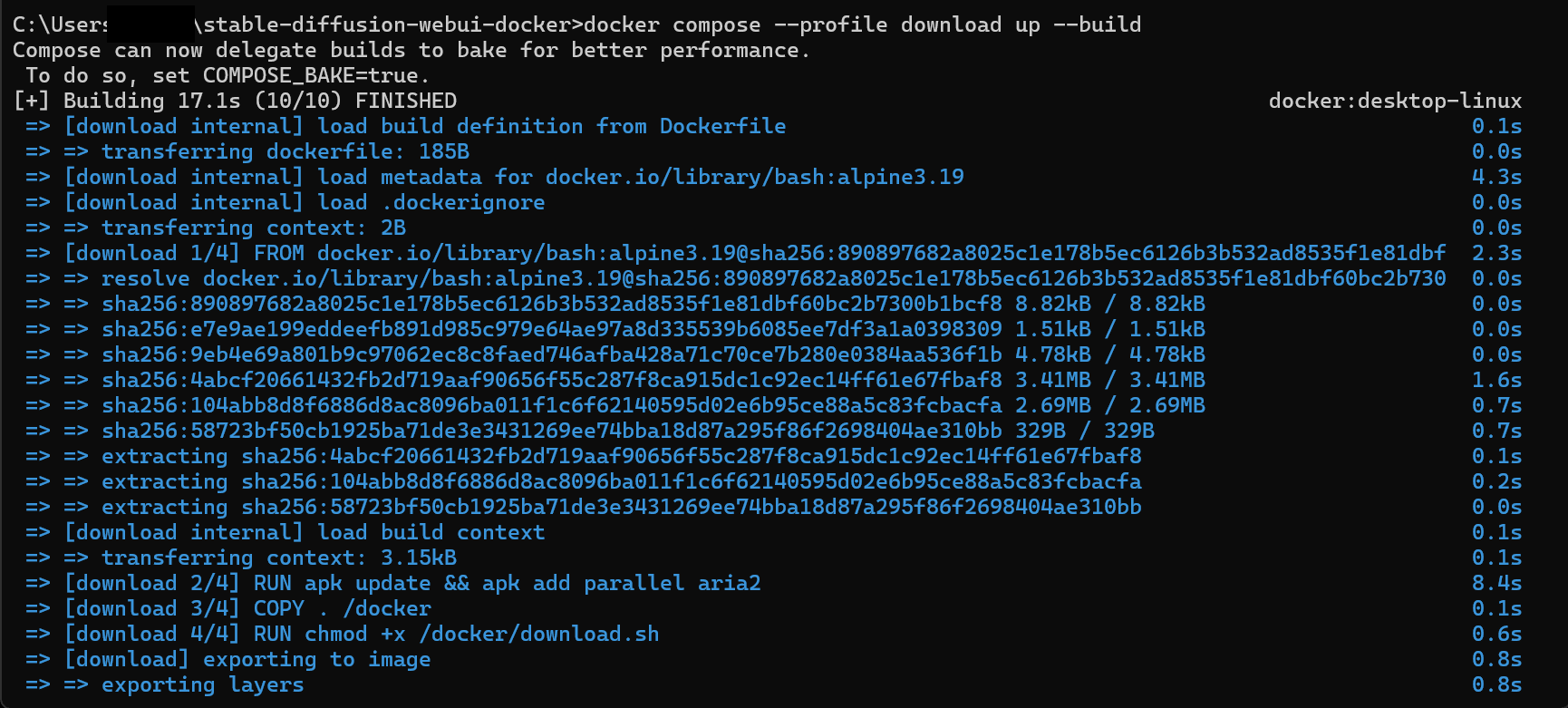
実行後、Docker DesktopでStable Diffusionが動いていることが確認できます。
ブラウザでhttp://localhost:7860にアクセスすると、Stable Diffusion Web UIが起動できます。
Google Colabでのセットアップ手順
最後に、Google Colabでのセットアップ手順を解説します。
Google ColabでStable Diffusionを利用する場合、無料プランでも利用できますが、Web UI 用途は無料枠では制限・切断されやすいため、有料版(Pro)の利用が実用的です。
安定した利用を希望する場合は、有料版(Pro)の契約を検討してください。
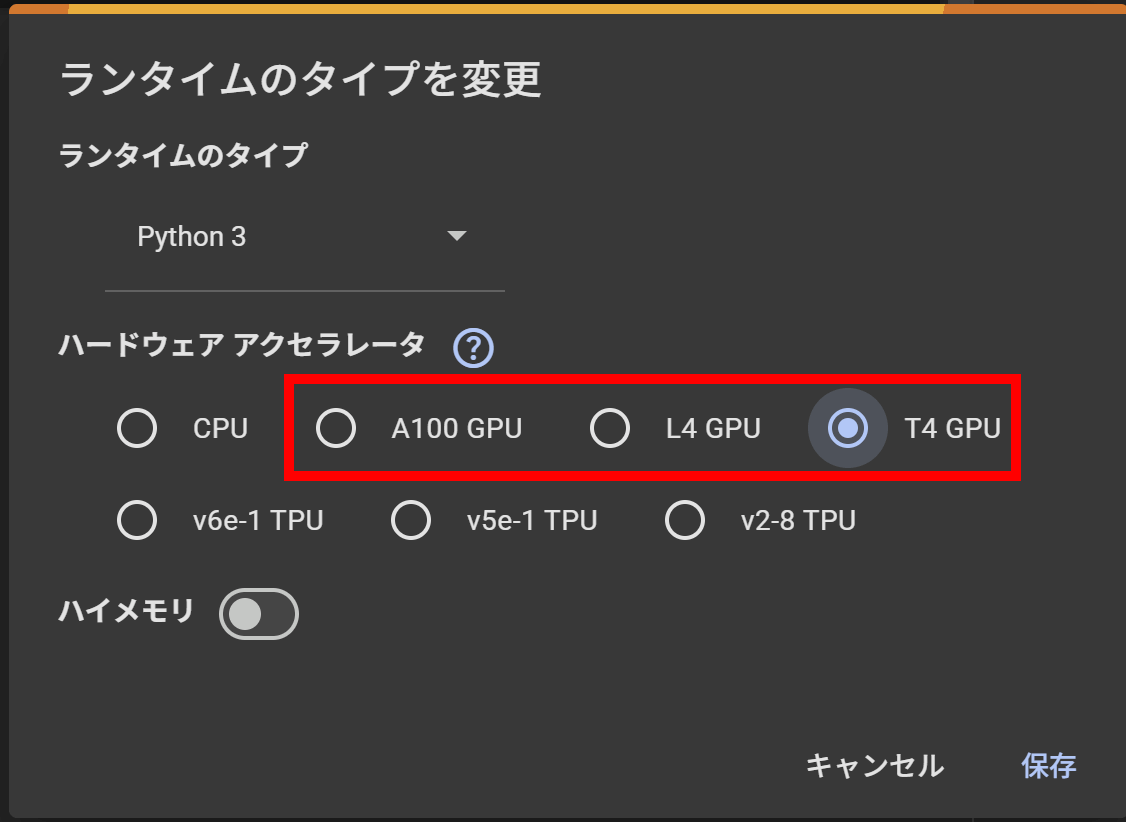
Stable Diffusionの利用にはGPU環境が必要であるため、ランタイムをGPUに設定します。
最も性能の高くクレジット消費量も多いGPUがA100、最も性能が低くクレジット消費量が少ないGPUがT4となっています。
Colabノートブック上で以下のコマンドを入力してリポジトリを複製します。
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui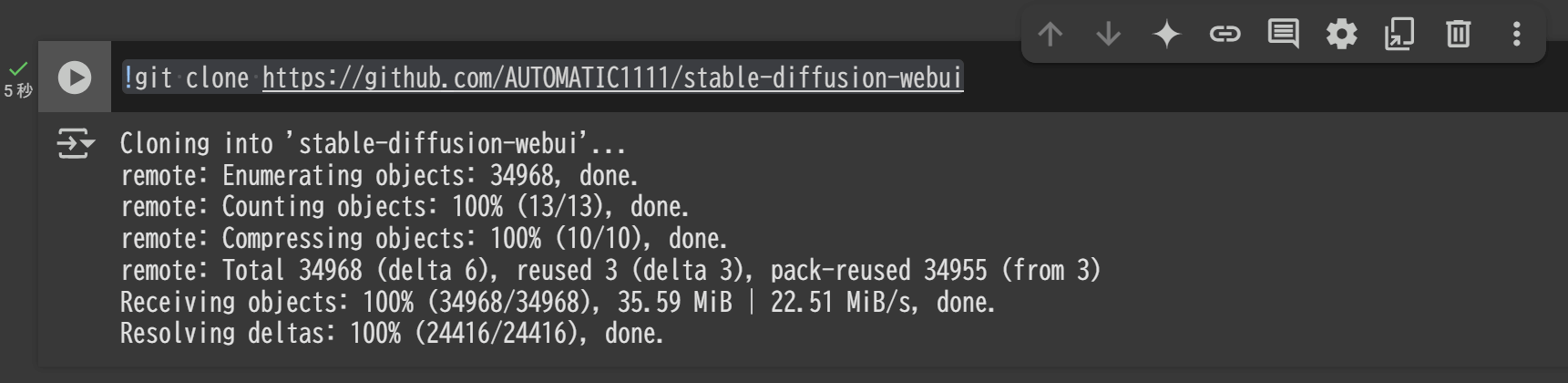
続いて、以下のコマンドを入力することでStable Diffusion Web UIがダウンロードできます。
%cd /content/stable-diffusion-webui
!python launch.py --share --enable-insecure-extension-access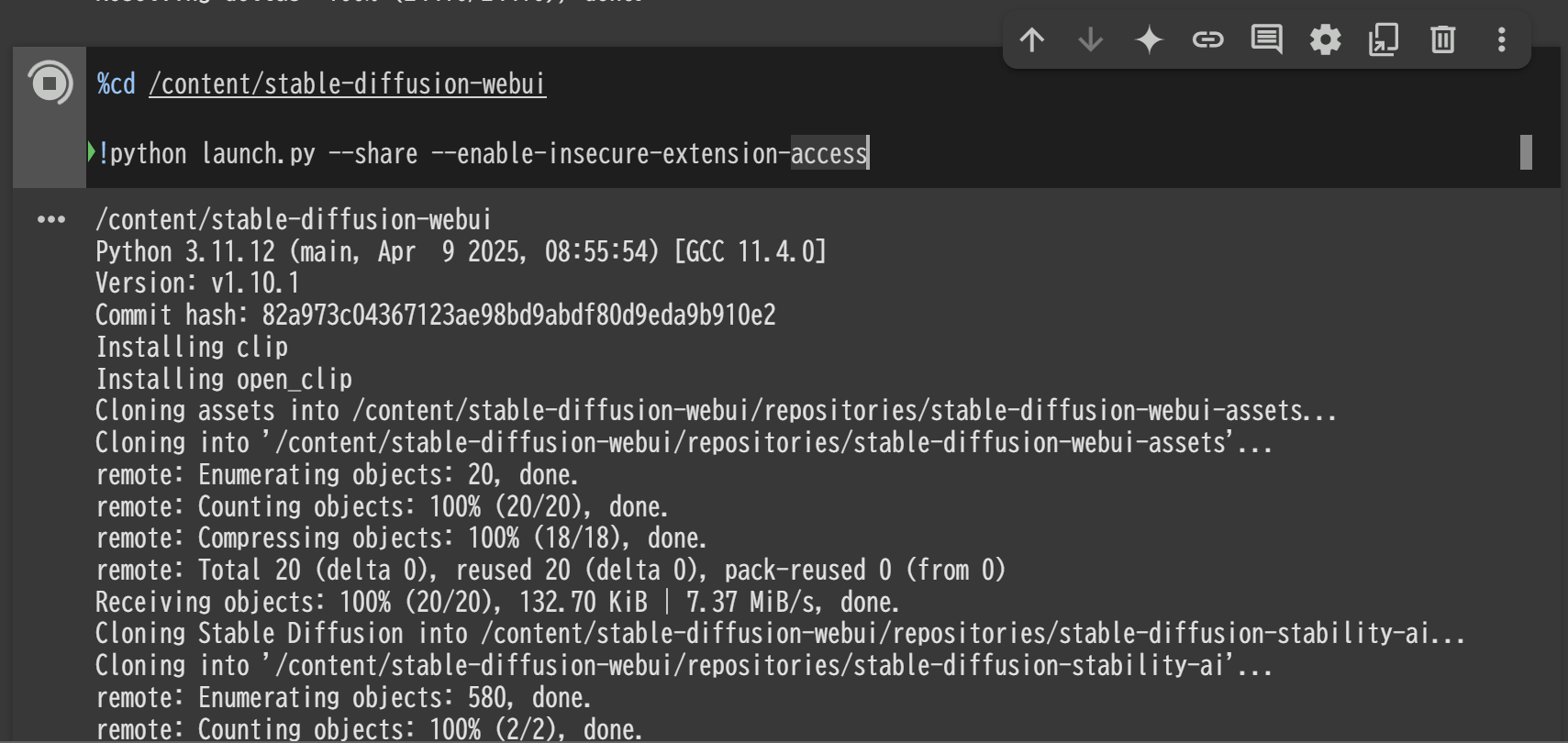
コマンド実行後に表示されるURLをクリックすると、Stable Diffusion Web UIを起動できます。
初回起動と日本語化の手順
Stable Diffusion Web UIは、ブラウザ上でローカルホストにアクセスすることで起動できます。
デフォルトは英語となっていますが、日本語化して使いたいという方もいるでしょう。Stable Diffusionは拡張機能を使うことで、日本語化することが可能です。
日本語化の手順は以下の通りです。
まずは「Extensions」タブを開きます。
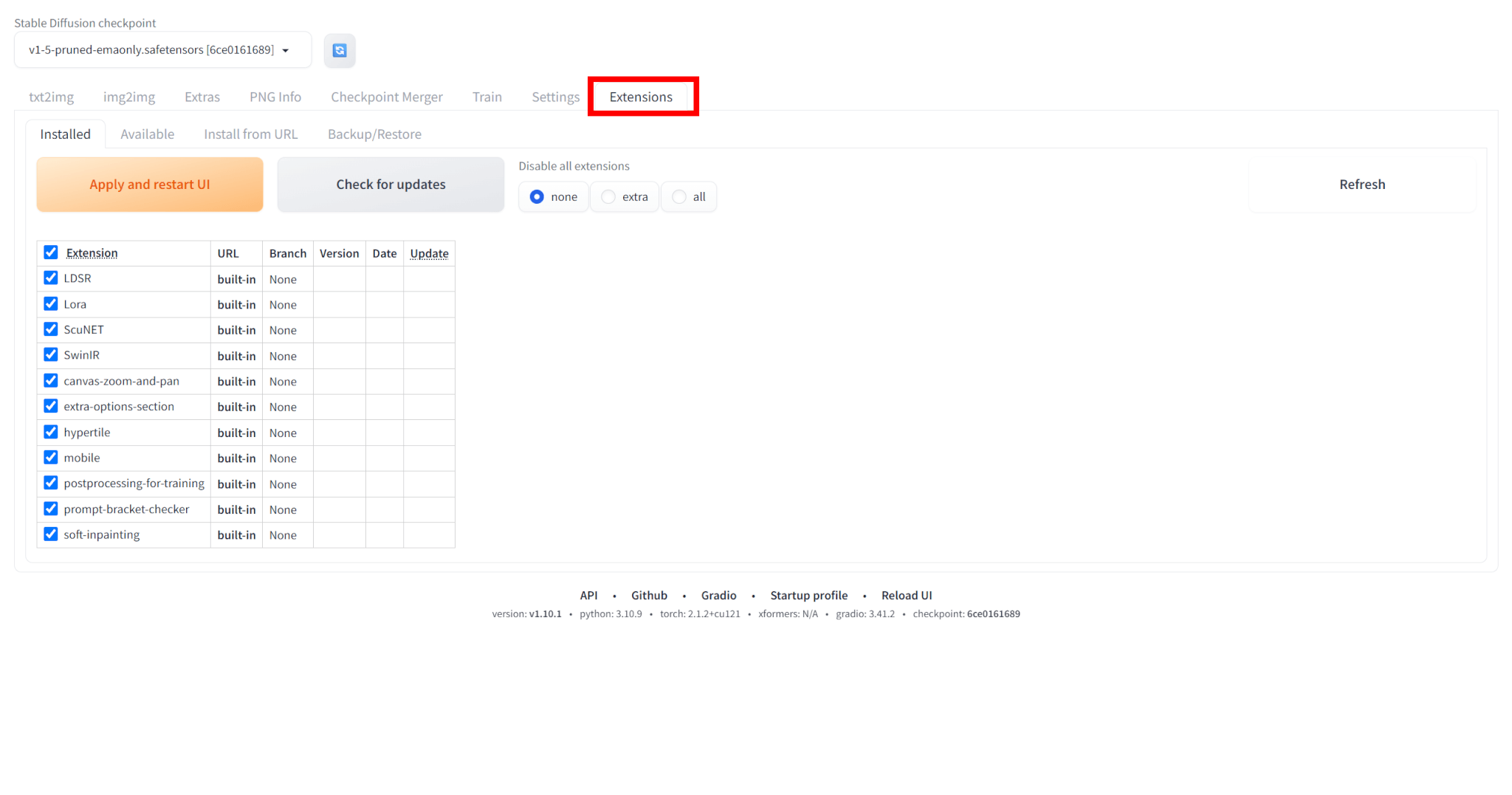
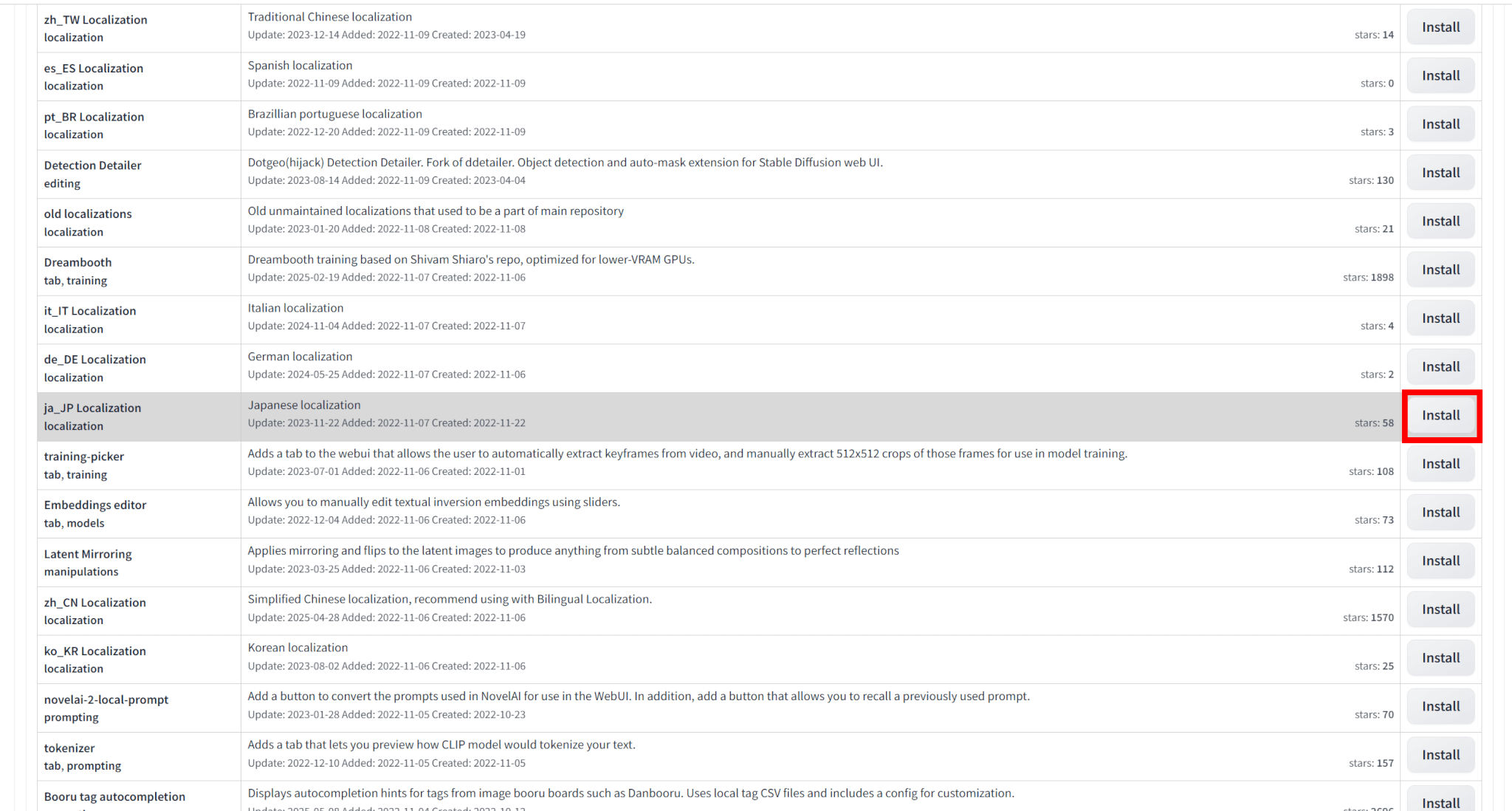
「Available」タブを選び、タグは「localization」のチェックを外し、Showing typeは「hide」にした状態で「Load from:」をクリックします。
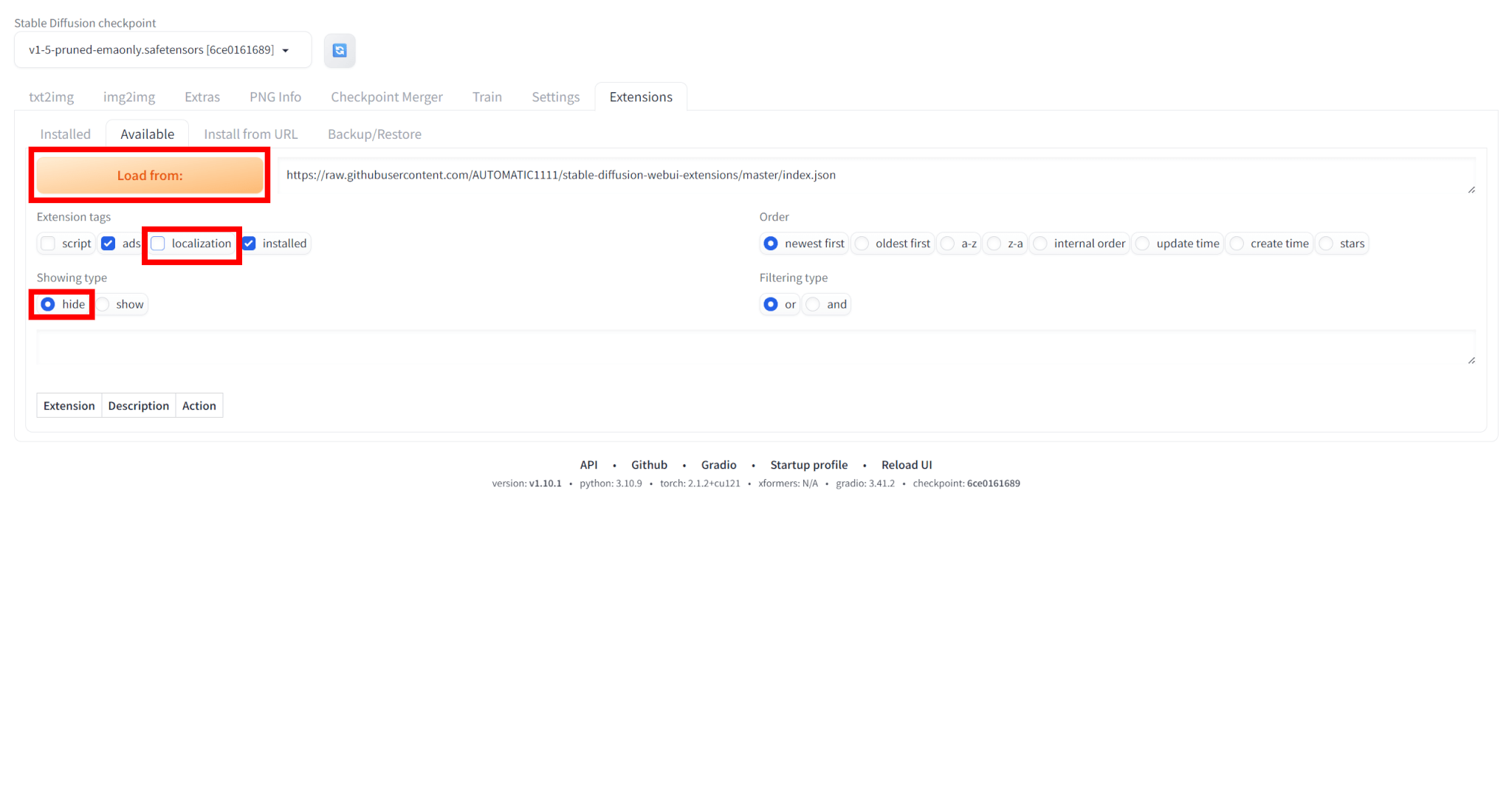
一覧の中から、「ja_JP Localization」という拡張機能を選び、「Install」をクリックしてインストールします。
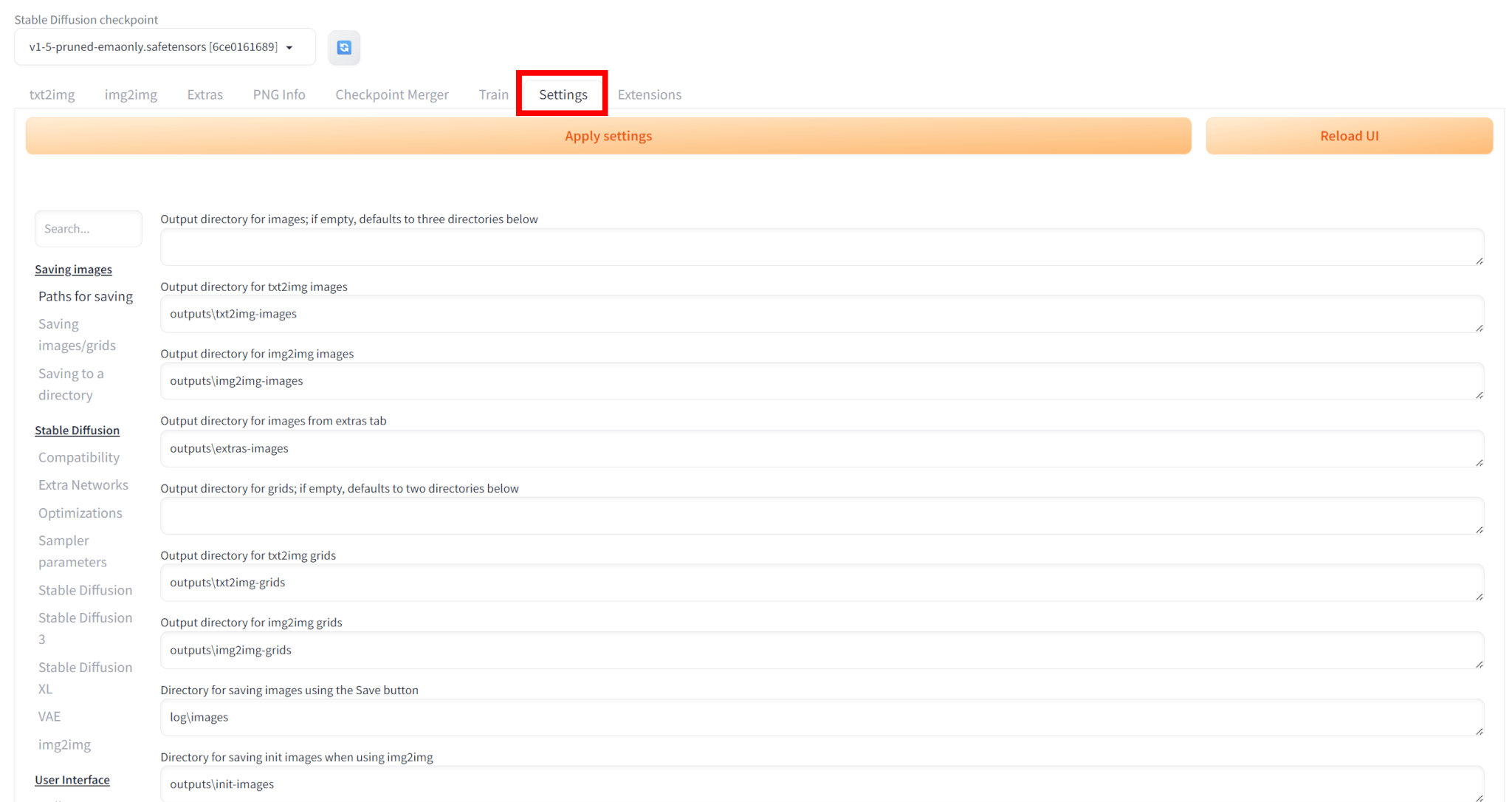
「Settings」タブを開き、「User Interface」を選びます。
一番上の「Localization」で「ja_JP」を選びます。
なお、「ja_JP」が表示されない場合は、右の更新ボタンを押してください。
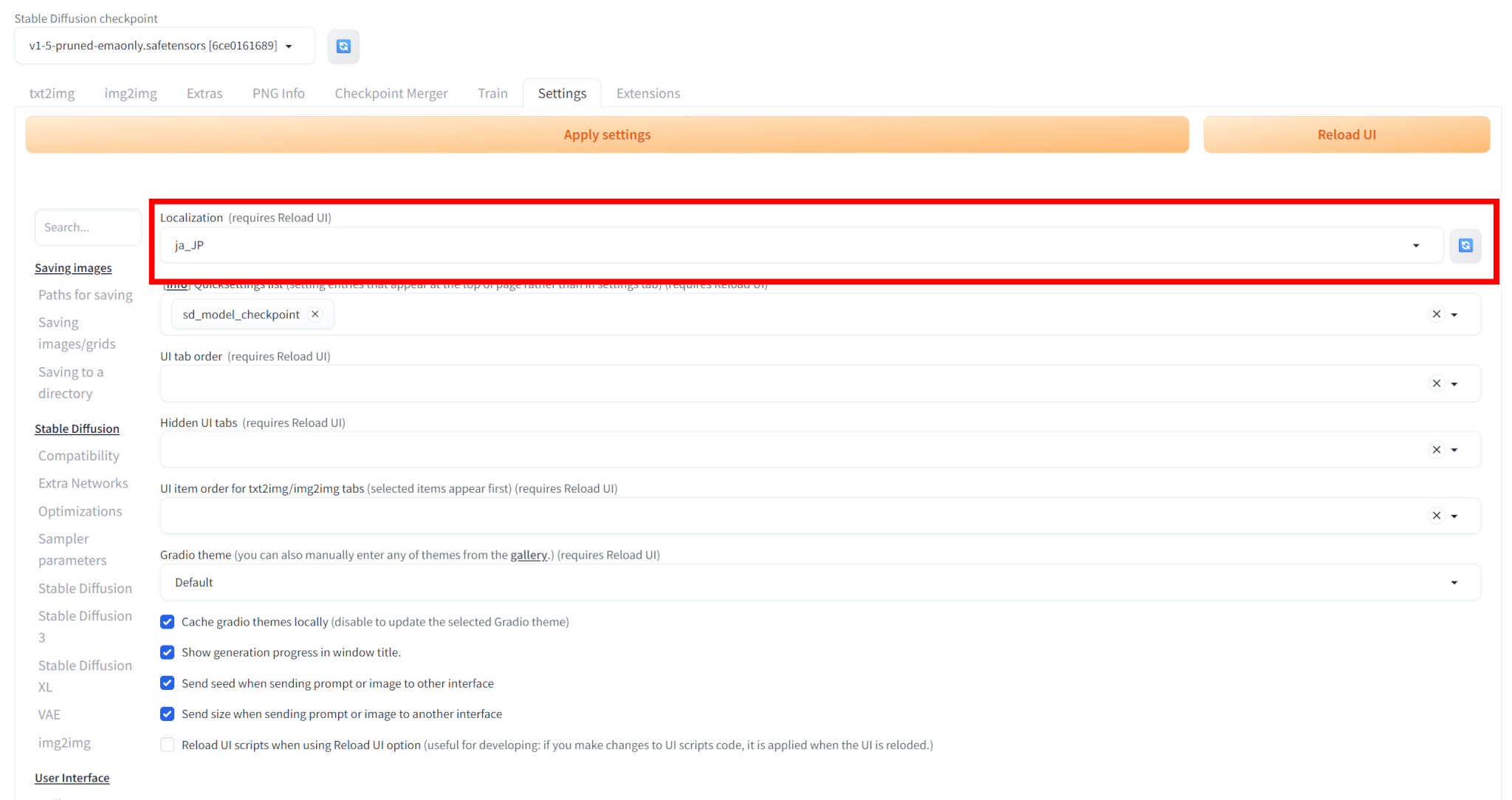
「Apply Settings」をクリックして変更を適用します。
その後、「Reload UI」をクリックするとStable Diffusionの日本語化が完了します。
とりあえずWeb UIを試してみたい方やGPUのスペックが足りないという方はGoogle Colab、ローカルで環境構築したい方はWindowsでの構築、Dockerも活用したい方はDockerを使った方法で導入しましょう。
基本操作ガイド

この記事では、Stable Diffusionの基本操作として、txt2img、img2img、inpaintの使い方と、seed値の決め方やprompt作成のコツを解説します。
txt2img画像生成方法
txt2imgでは、入力したテキストから画像を生成できます。
txt2imgで画像を生成する手順は以下の通りです。
txt2imgタブを選択し、生成したい画像の特徴をPromptに入力します。
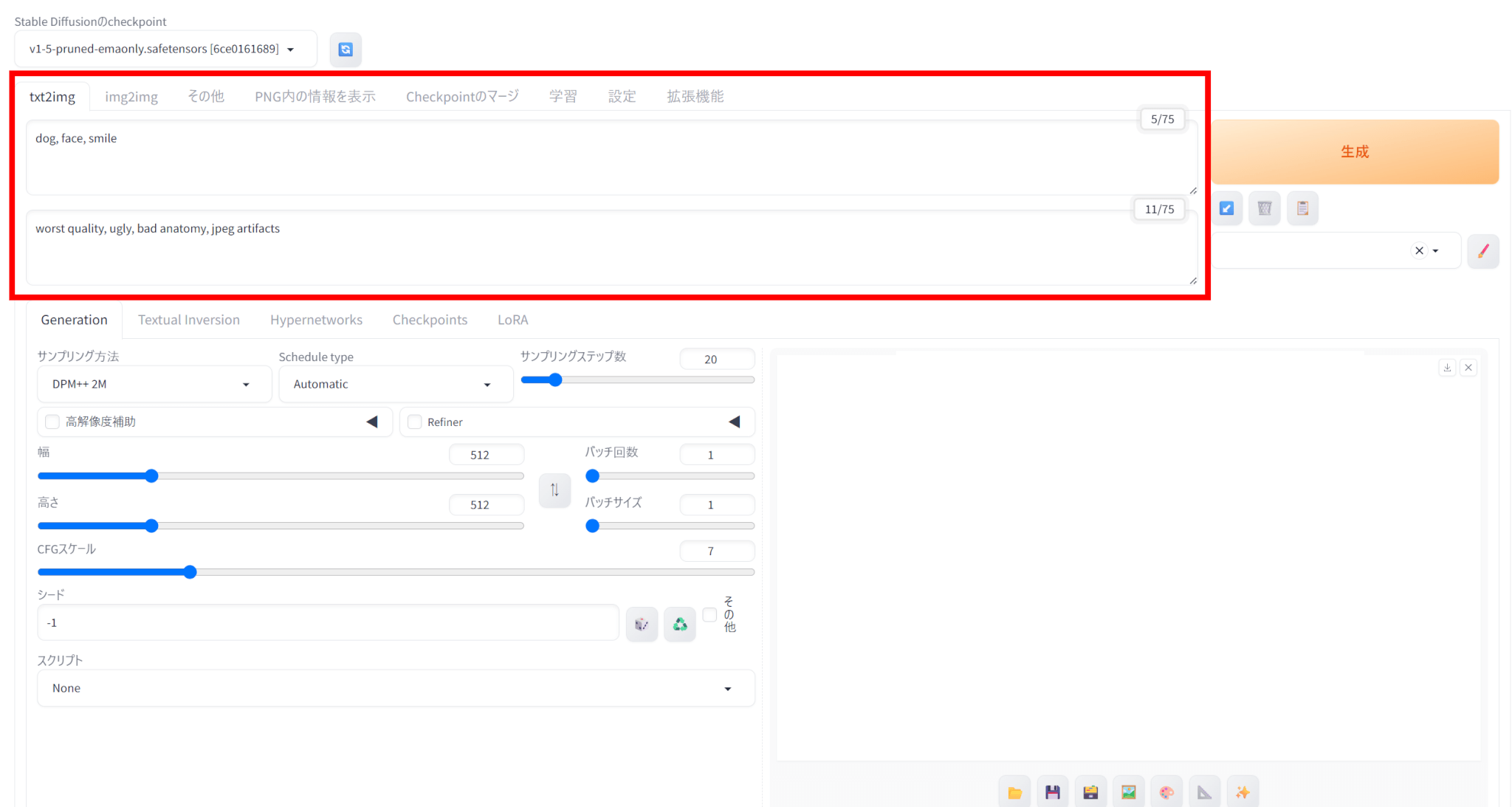
下のNegative promptには生成画像に含めてほしくない要素を入力します。
今回は、Promptに「dog, face, smile」を、Negative promptに「worst quality, ugly, bad anatomy, jpeg artifacts」と入力しました。
画像のサイズや生成枚数などを選択します。
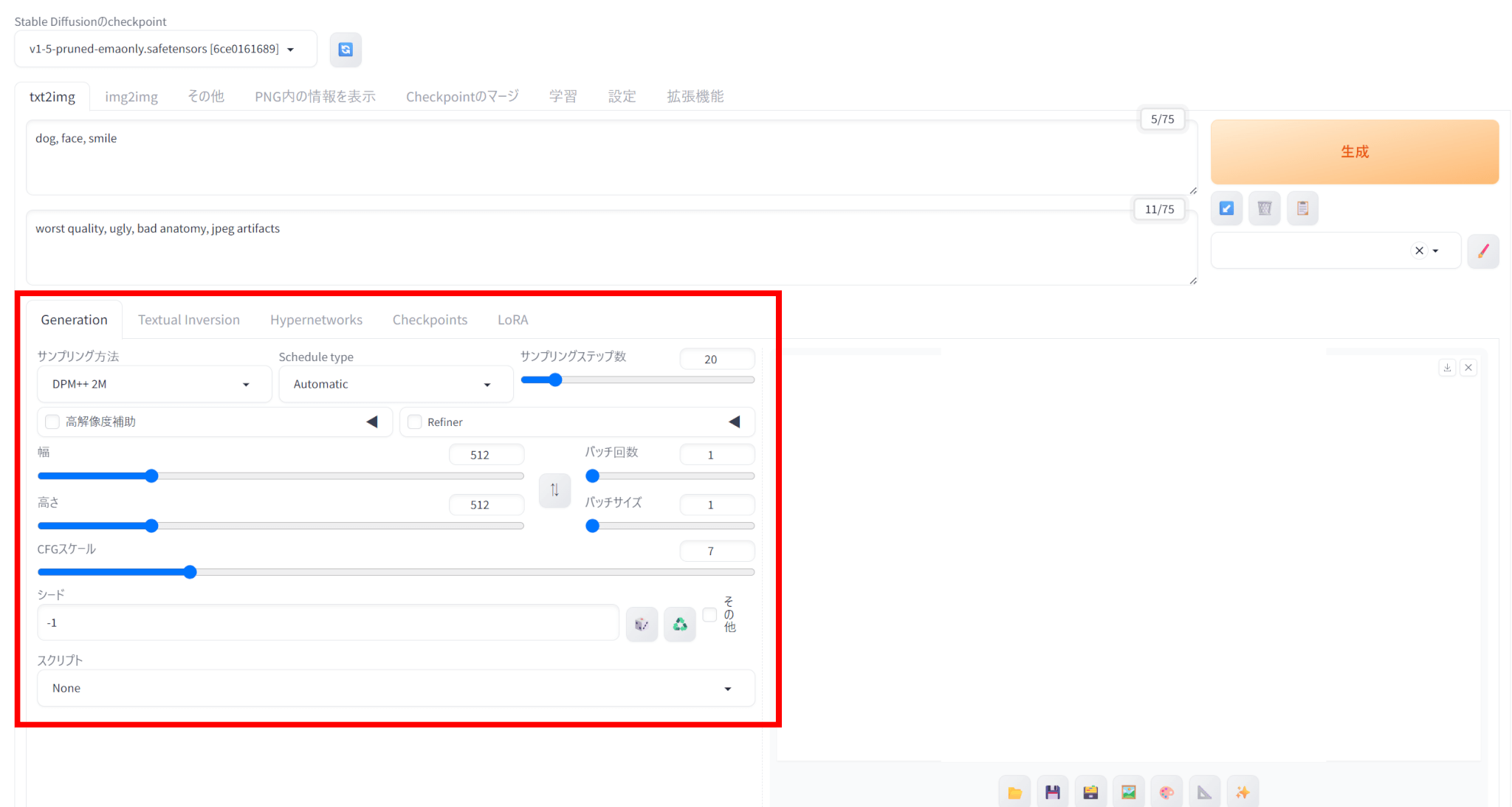
各パラメータの意味はこのようになっています。
| パラメータ | 意味 |
|---|---|
| サンプリング方法 | サンプリング手法を選択でき、生成速度や画像の品質が変わる |
| Schedule type | ノイズを減らす手法を選択でき、生成される画像の特徴や品質が変わる |
| サンプリングステップ数 | 値が大きいほど画像の品質が良くなるが、生成速度が落ちる |
| 幅・高さ | 画像サイズであり、大きいほど生成速度が遅くなる |
| バッチ回数 | 画像を生成する回数 |
| バッチサイズ | 一度に生成する画像の枚数 |
| CFG Scale | promptの影響の強さであり、値が大きいほど指示に忠実になる |
| シード | 画像生成のもととなる数値であり、固定すれば同じ画像を生成できる |
バッチ回数は画像を生成する回数、バッチサイズは一度に生成する画像の枚数を表します。
たとえば、バッチサイズを2にしてバッチ回数を3にすると、画像が2枚ずつ3回、合計6枚の画像が生成されます。
プロンプトとパラメータが設定できたら、右の「生成」をクリックします。
今回実際に生成された画像がこちらです。

img2img画像変換方法
img2imgでは、画像を入力として新たな画像を生成できます。
img2imgの使い方は以下の通りです。
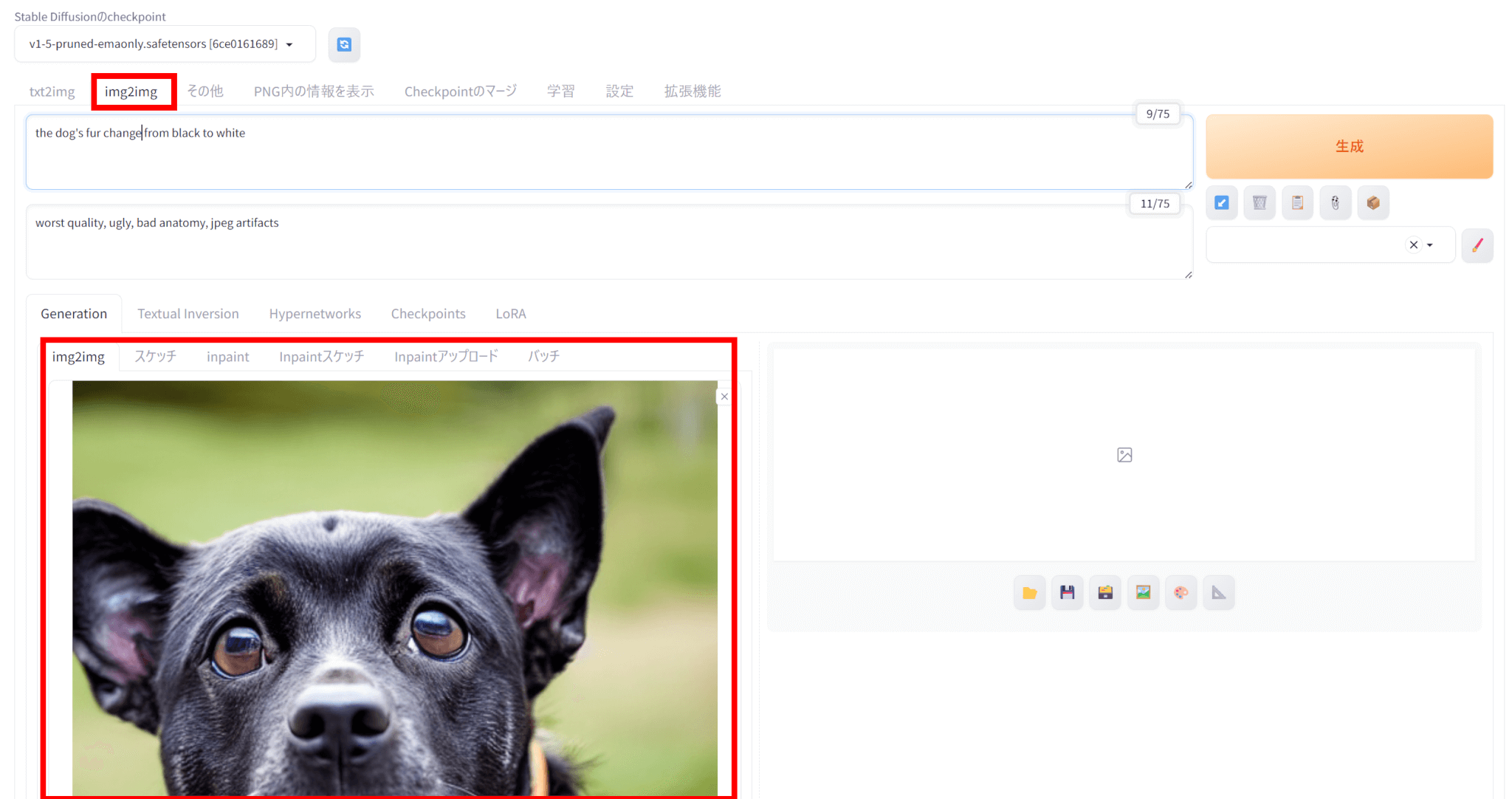
「img2img」タブを選択し、入力にしたい画像をアップロードします。
今回は、先ほどtxt2imgで生成した画像をアップロードしました。
生成したい画像に関する情報をPromptとして入力します。
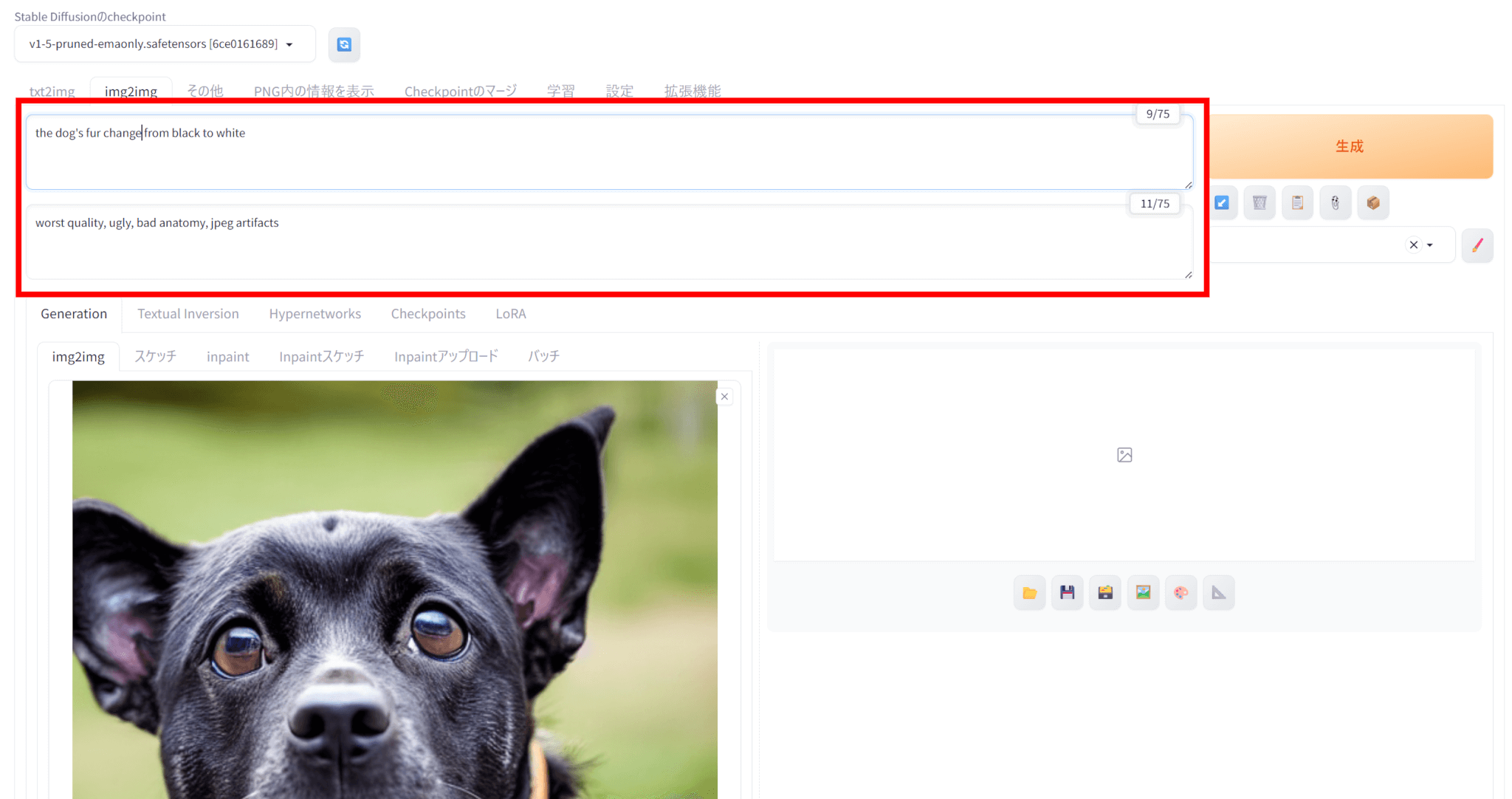
今回は、Promptに「the dog’s fur change from black to white」として、犬の毛を黒から白に変更することを試みました。
なお、Negative promptはtxt2imgと同じにしています。
画像のアップロード、promptの入力が完了したら、「生成」をクリックして画像を生成します。
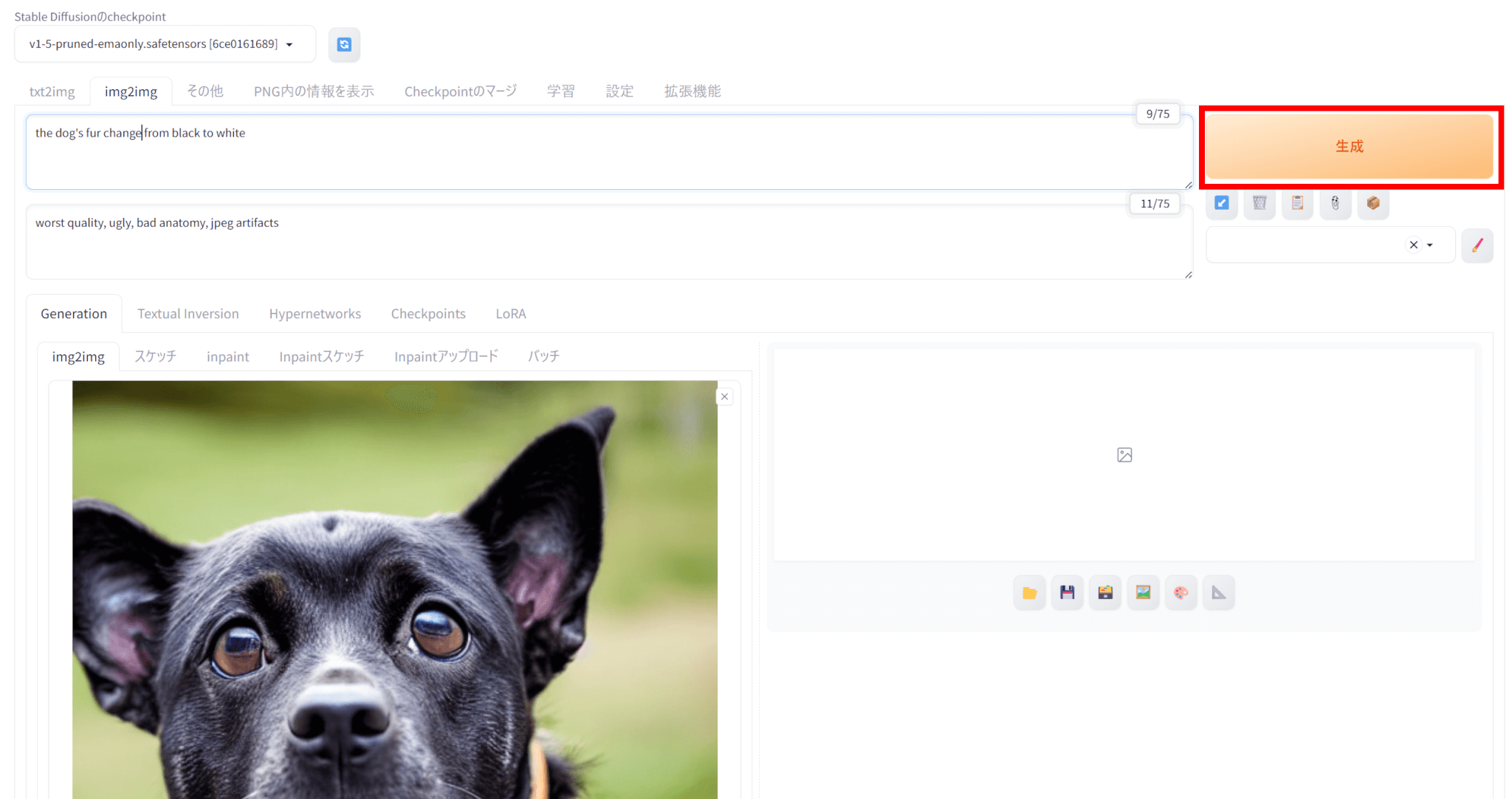
今回生成された画像がこちらです。

犬の毛を完全に白くすることはできませんでしたが、白色の毛を要素として入れることには成功していました。
inpaint部分修正のやり方
img2imgの中には、inpaintという生成画像の部分修正ができる機能があります。
inpaintの使い方は以下の通りです。
img2imgタブの中のinpaintタブを選択し、生成した画像をアップロードします。
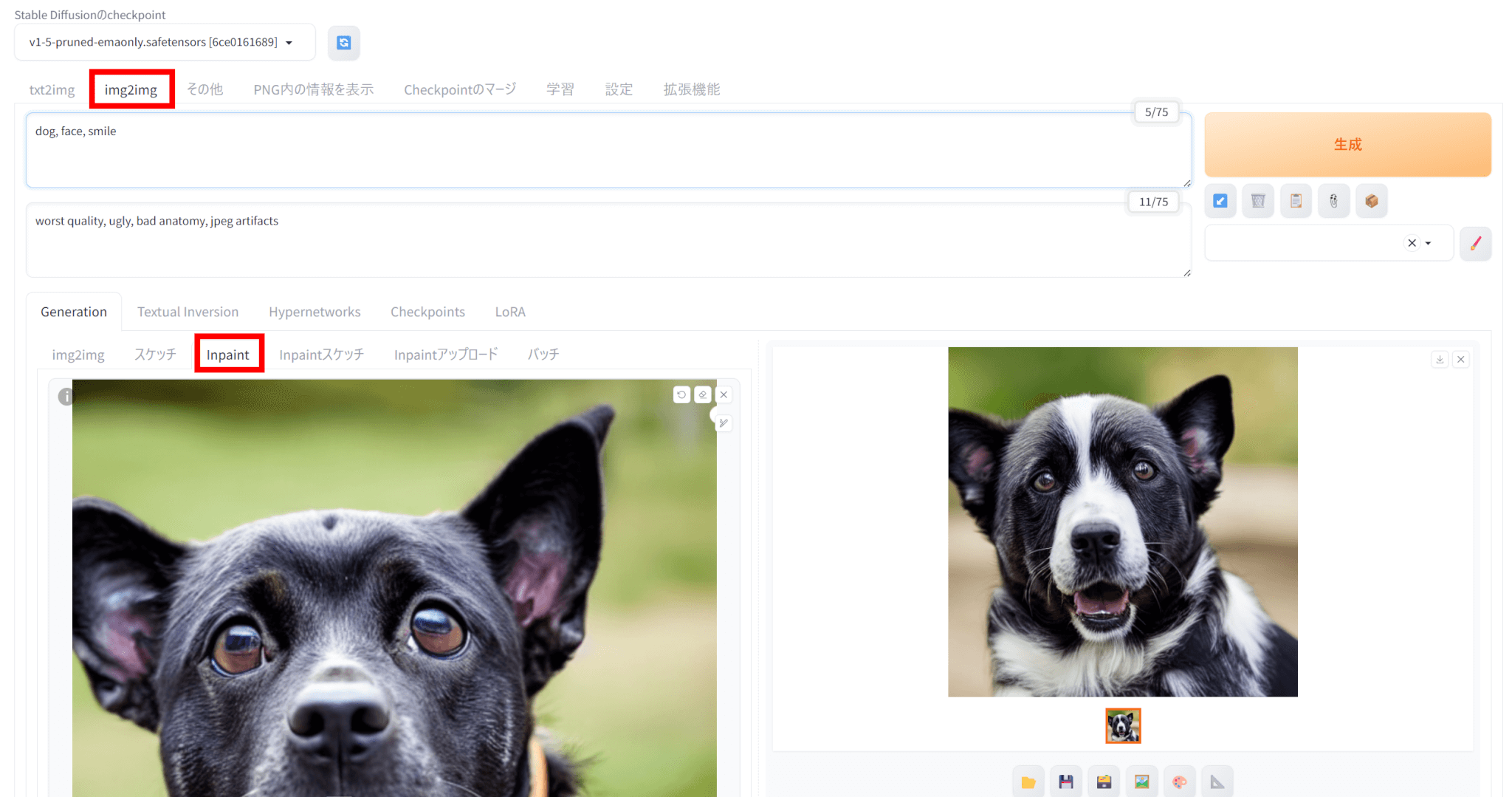
画像のうち、変更したい部分をマスクで選びます。
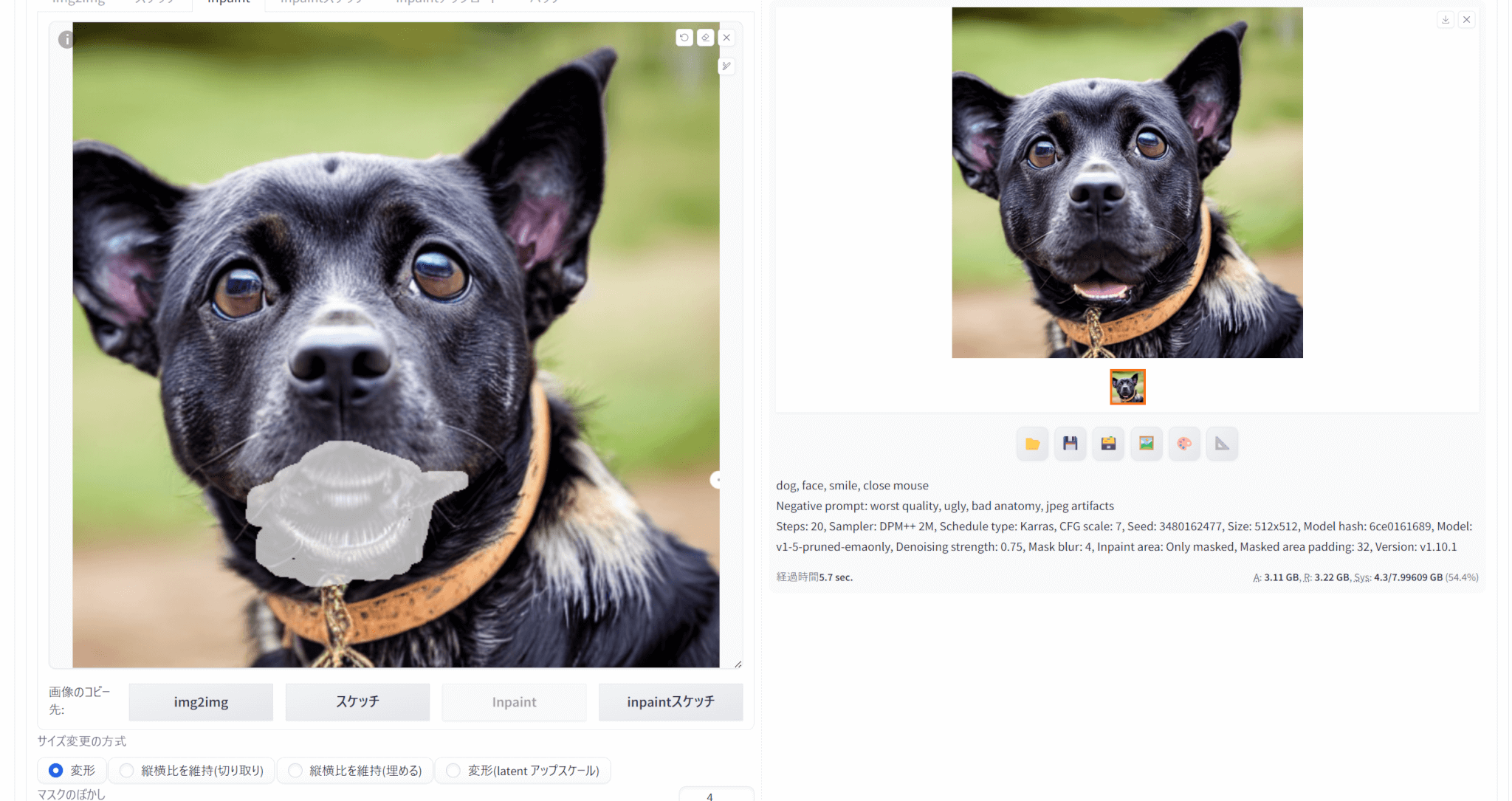
なお、マスクした部分以外を変更することも可能です。
変更したい要素をプロンプトとして入力します。
なお、プロンプトは基本生成時と同じものにしておく必要があります。
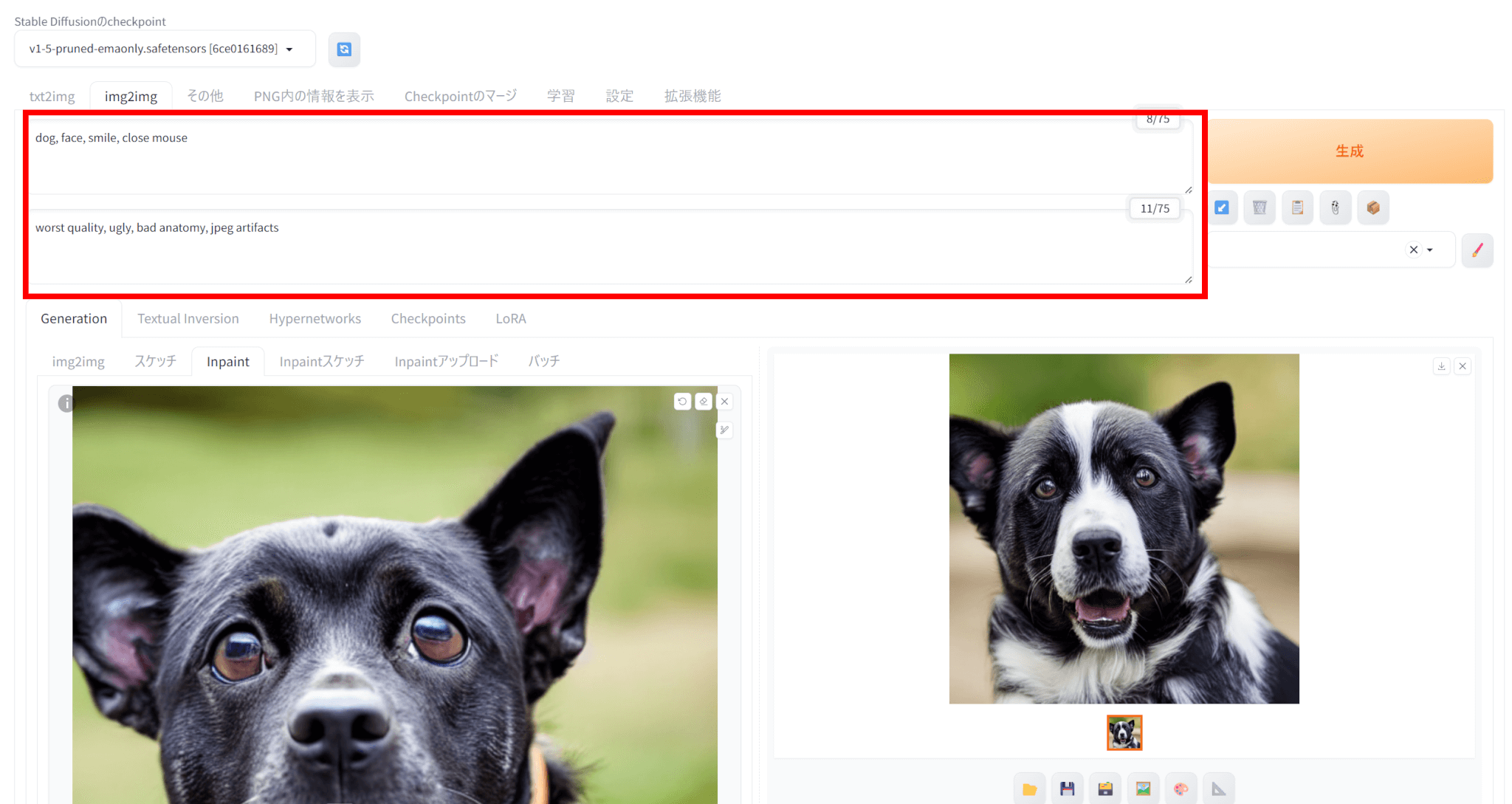
今回は、「close mouth」を加えて口を閉じた画像を生成させることを試みました。
パラメータを調整することで望み通りの画像を生成しやすくなります。
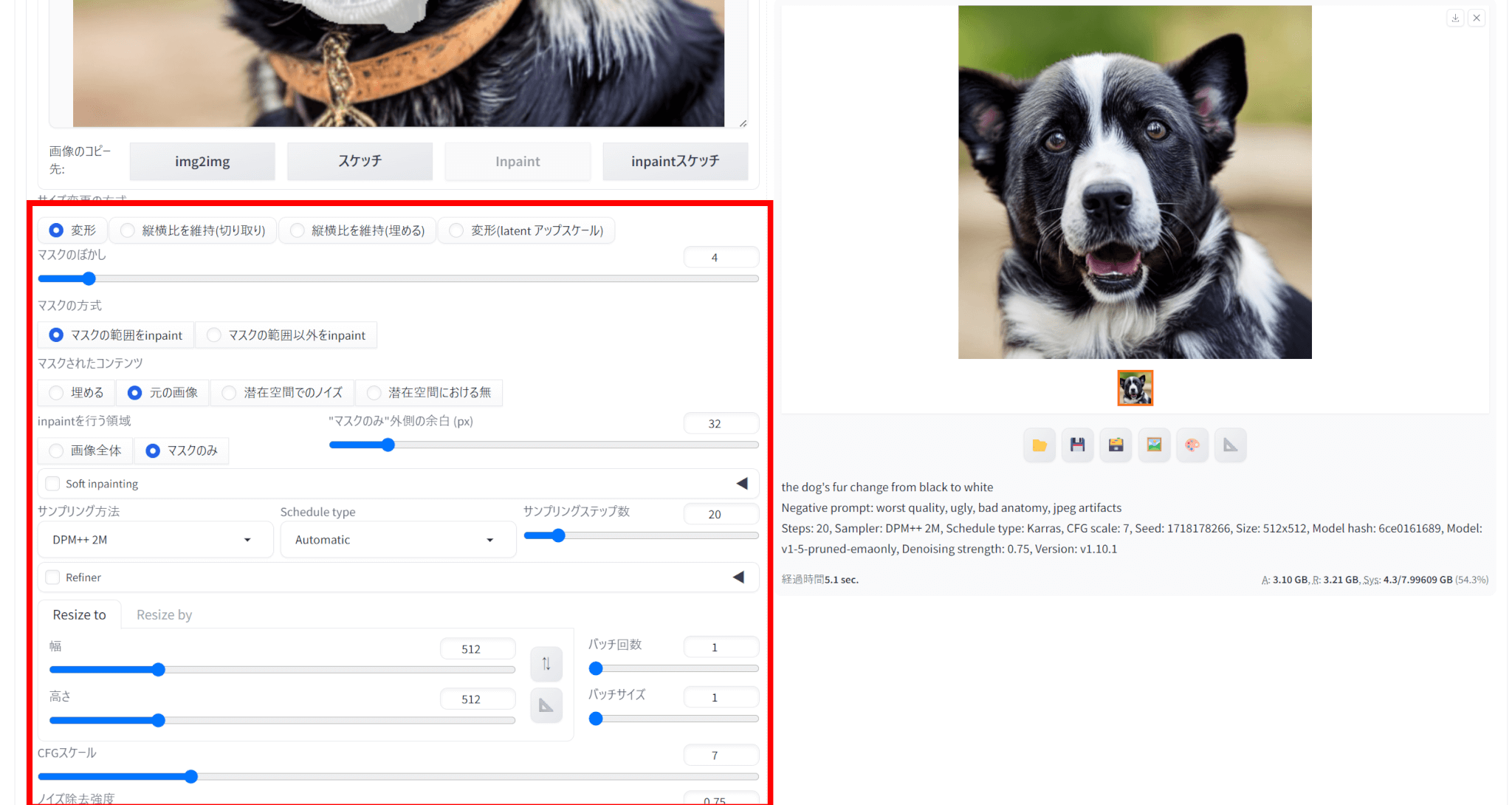
設定が完了したら、「生成」をクリックして画像を生成します。
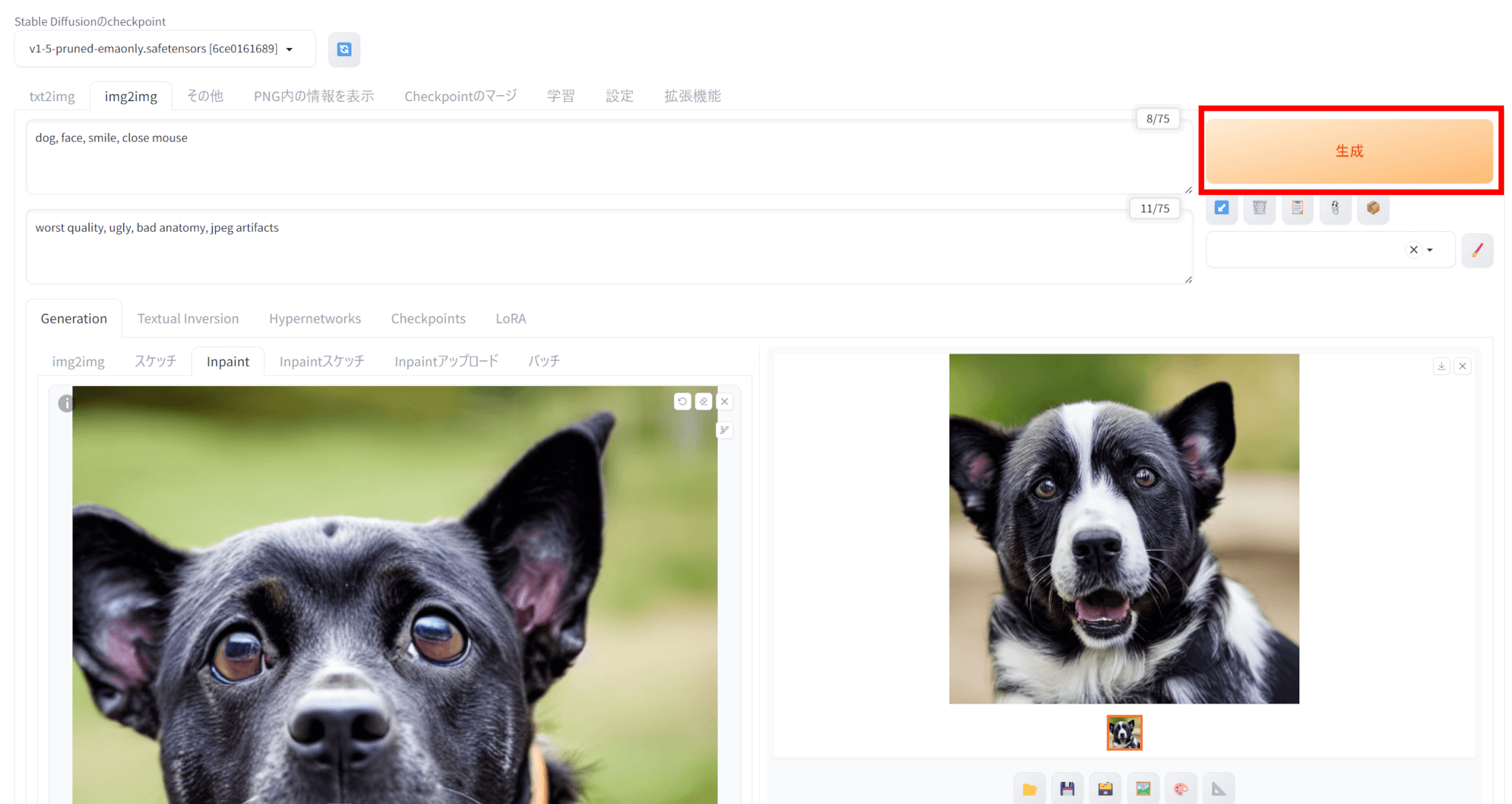
今回生成された画像がこちらです。

なお、元の画像がこちらです。
口を完全に閉じることはできていませんでしたが、口の部分のみを修正できていることが分かります。
seed値の決め方とprompt作成のコツ
Stable Diffusionで画像生成をする際、seed値の決め方とpromptは重要です。
seed値は画像生成の乱数の初期値であり、同じモデル・プロンプト・設定なら同じseedを指定することで完全に再現可能です。
新しい発想を得たい場合はseedを-1にするか、好みの数字の1桁を変えて小刻みに試行すると、傾向を比べながら効率的に探索できます。逆に構図や雰囲気を詰めたいときは、まずランダム生成で当たり画像のseedを控え、そのseedを固定したままプロンプトやパラメータを微調整すると細部を詰めやすくなります。
promptは先に入力したものほど強く影響するため、重要なキーワードほど先に入力するようにしましょう。さらに(単語:1.2) のように書くとその単語の重要度が1.2倍になり、重み付けできます。Negative promptを活用すると、ノイズや画像の品質低下を抑えられます。
まずはtxt2imgで画像生成とはどういうものであるかを掴み、img2imgやinpaintでの画像変更も試してみましょう。慣れてきたらseed値やpromptも変えて望み通りの画像を生成することを目指してみてください。
モデル・LoRA・VAE・Checkpoint の導入と管理
Stable Diffusionを使う上で、モデルやLoRA、VAE、Checkpointという言葉を聞くことがあります。
ここでは、これらについてご紹介します。
モデルとは?管理方法も解説
Stable Diffusionではモデルを設定し、プロンプトを入力することで画像を生成します。設定するモデルによって、実写風や、アニメ調、油絵など、生成される画像の雰囲気やスタイル、画風が変わります。
さまざまなモデルを利用することで、想定したイメージに近い画像を生成しやすくなります。
モデルはCheckpointというモデルファイルとして設定できます。
Checkpointの導入方法
モデルファイルであるCheckpointは、Hugging FaceやCivitaiで配布されています。


モデルをダウンロードした後は、stable-diffusion-webui/models/Stable-diffusionフォルダにモデルファイルを格納することで、Stable Diffusionで利用できます。ダウンロードしたモデルファイルは、基本的にこのフォルダで管理することになります。
Stable Diffusionで設定する際は、左上のプルダウンから選択します。
LoRA の作り方
LoRAとは追加学習モデルのことであり、Checkpointに対して追加学習を行った差分ファイルとなります。
LoRAもCheckpointと同様にHugging FaceやCivitaiから入手可能です。ダウンロードしたLoRAは、stable-diffusion-webui/models/LoRAに格納することで利用できるようになります。
また、LoRAファイルをダウンロードして使うだけではなく、自分で画像データを学習させてLoRAファイルを作成することも可能です。
通常のモデルファイルと比べて計算量が少なく済むため、解像度を1024x1024px、または512×512 pxに統一した画像を20〜100枚用意し、5〜10エポック学習させることでLoRAが作成できます。ただし、VRAMは16GB以上が推奨されています。

VAE の導入方法
VAEは、まず膨大なピクセル情報をコンパクトな潜在ベクトルへ射影し、後にそのベクトルから元の解像度の画像を復元する仕組みです。
画像生成AIは計算負荷が大きいため、高解像度のまま演算すると時間がかかります。そこで処理の初段階で画像を低次元の潜在空間に圧縮し、データ量を減らして計算を高速化します。最後に、その潜在ベクトルをデコーダで展開し、高次元の画像に戻して出力します。
VAEファイルもHugging FaceやCivitaiからダウンロードでき、ファイルをstable-diffusion-webui/models/VAEに格納することでVAEを利用できるようになります。
まずはデフォルトのモデルを使用して画像を生成し、その後望み通りの画像を生成するためにさまざまなモデルをダウンロードして試してみましょう。自分好みの雰囲気や背景などを取り入れたい場合はLoRAの自作にも挑戦してみてください。
拡張機能 ControlNet/Web UI Extensions 活用術
Stable Diffusion Web UIには、拡張機能となるWeb UI Extensionsがあります。
ここでは、Web UI Extensionsの概要と、代表的な拡張機能であるControlNetの使い方についてご説明します。
Web UI Extensionsとは?
Web UI Extensionsは、画像生成AIであるStable Diffusion Web UIに、さらなる機能を追加するためのプラグインです。
これらの拡張機能を利用することで、画像の品質を向上させたり、特定のスタイルや構図を簡単に適用したり、あるいは動画生成のような新しい機能を追加したりと、基本的なWeb UIだけでは実現できない多様な操作が可能になります。
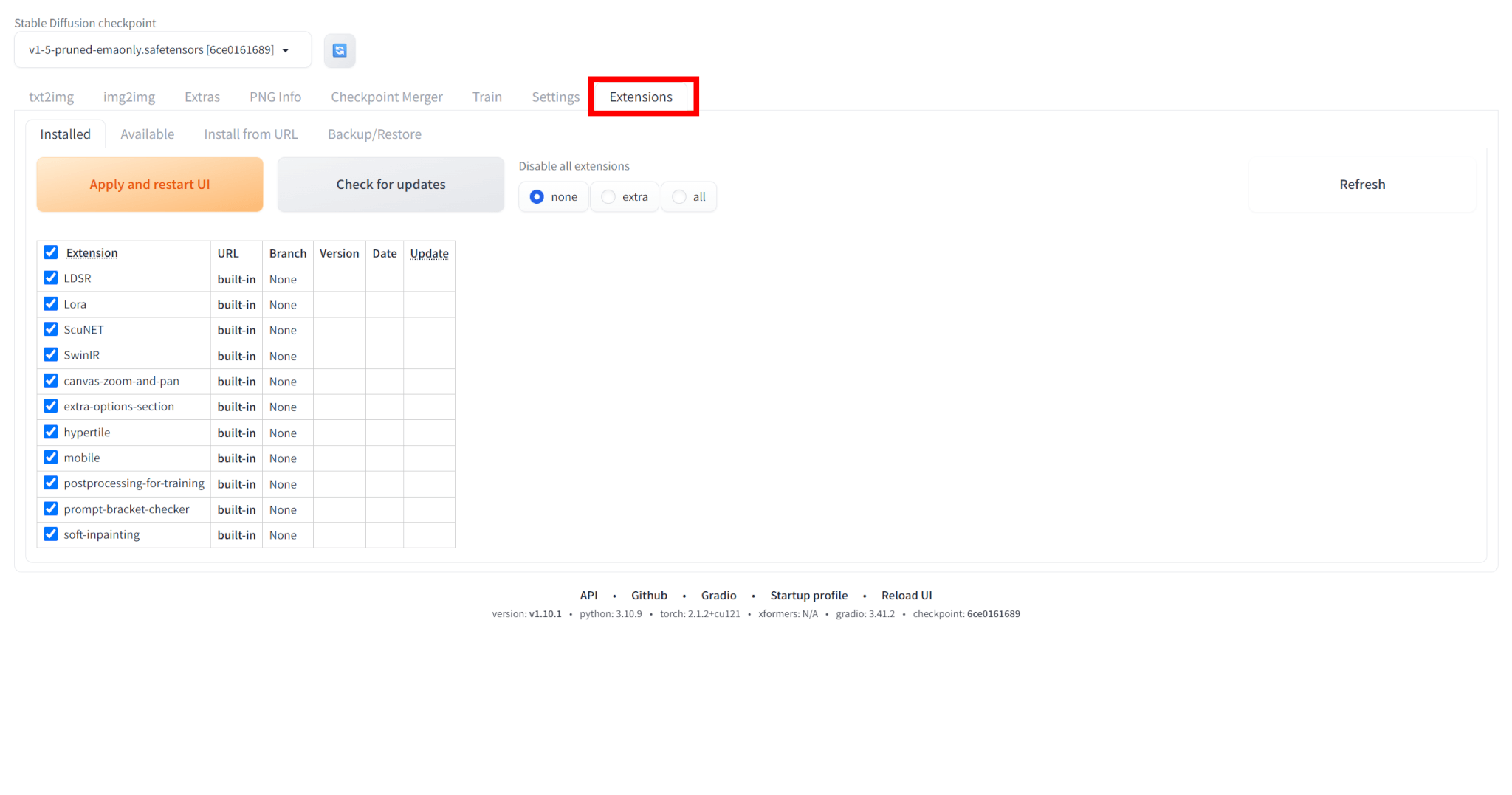
多くの場合、Web UIの「Extensions」タブから簡単にインストールや管理ができ、ユーザーは自身の目的に合わせて機能をカスタマイズできます。
これにより、Stable Diffusionの表現力や利便性が大幅に向上し、より高度で効率的な画像生成体験が実現します。
ControlNetの使い方
ControlNetは、Stable Diffusionにおいて生成される画像の構図やポーズなどをより精密に制御するための拡張機能です。参照となる画像を入力として与えることで、その画像と同じポーズや線画などを生成画像に反映させることができます。
ControlNet の使い方は以下の通りです。
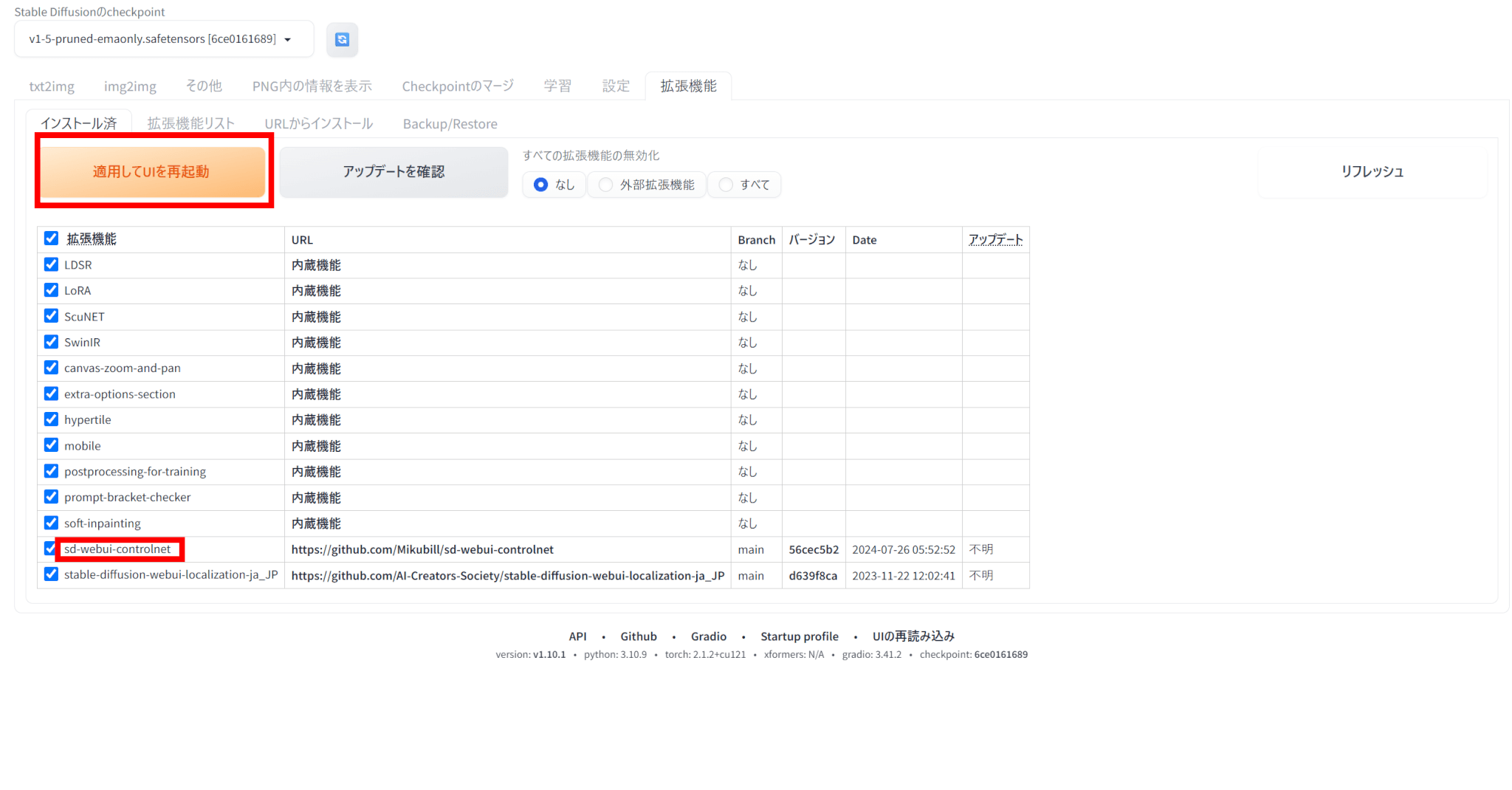
Stable Diffusionの「拡張機能」タブの「URLからインストール」を選びます。
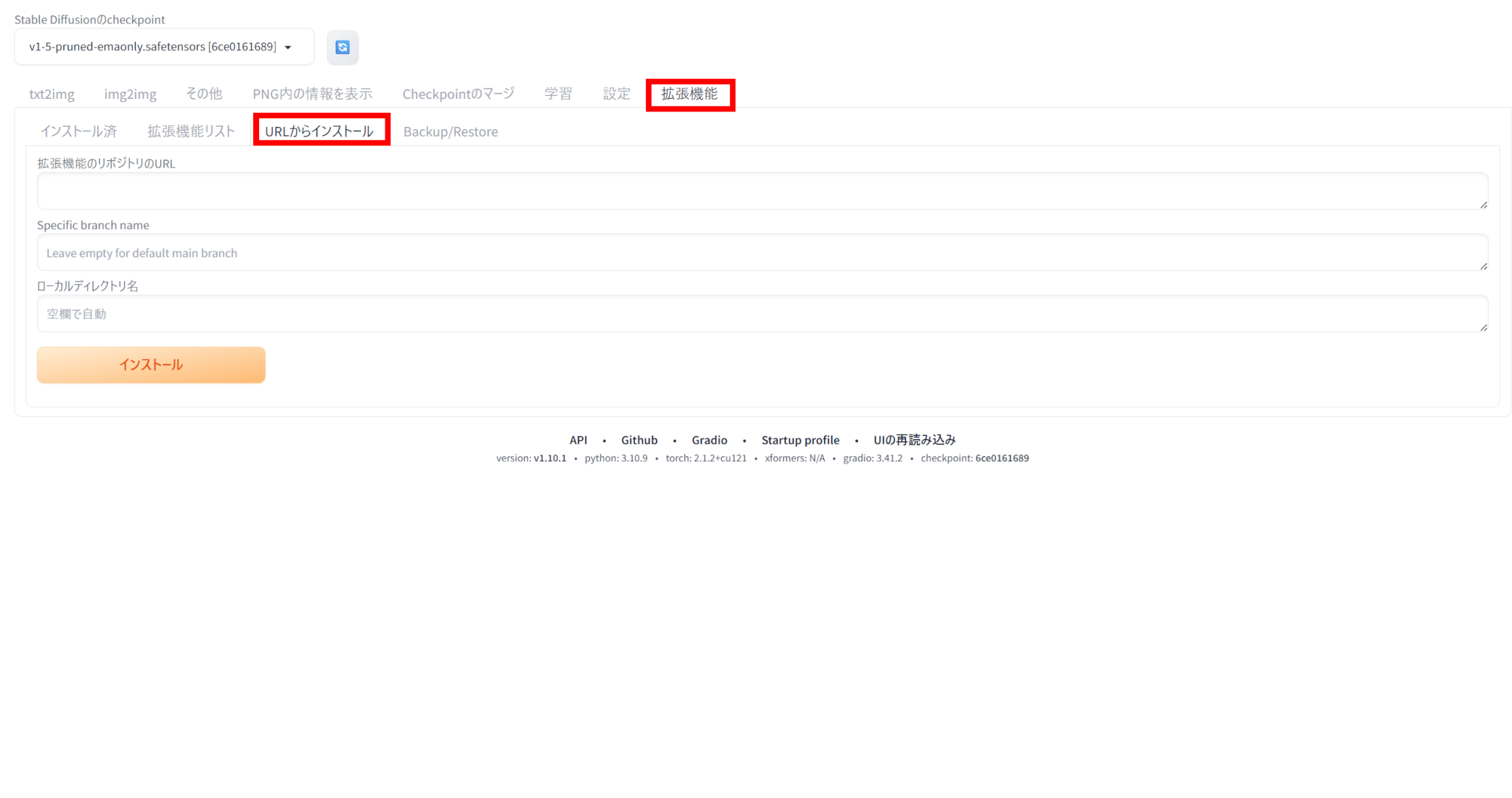
リポジトリのURLとして、ControlNetのリポジトリURL(https://github.com/Mikubill/sd-webui-controlnet)を入力します。
「インストール」をクリックすると、ControlNetがインストールされます。
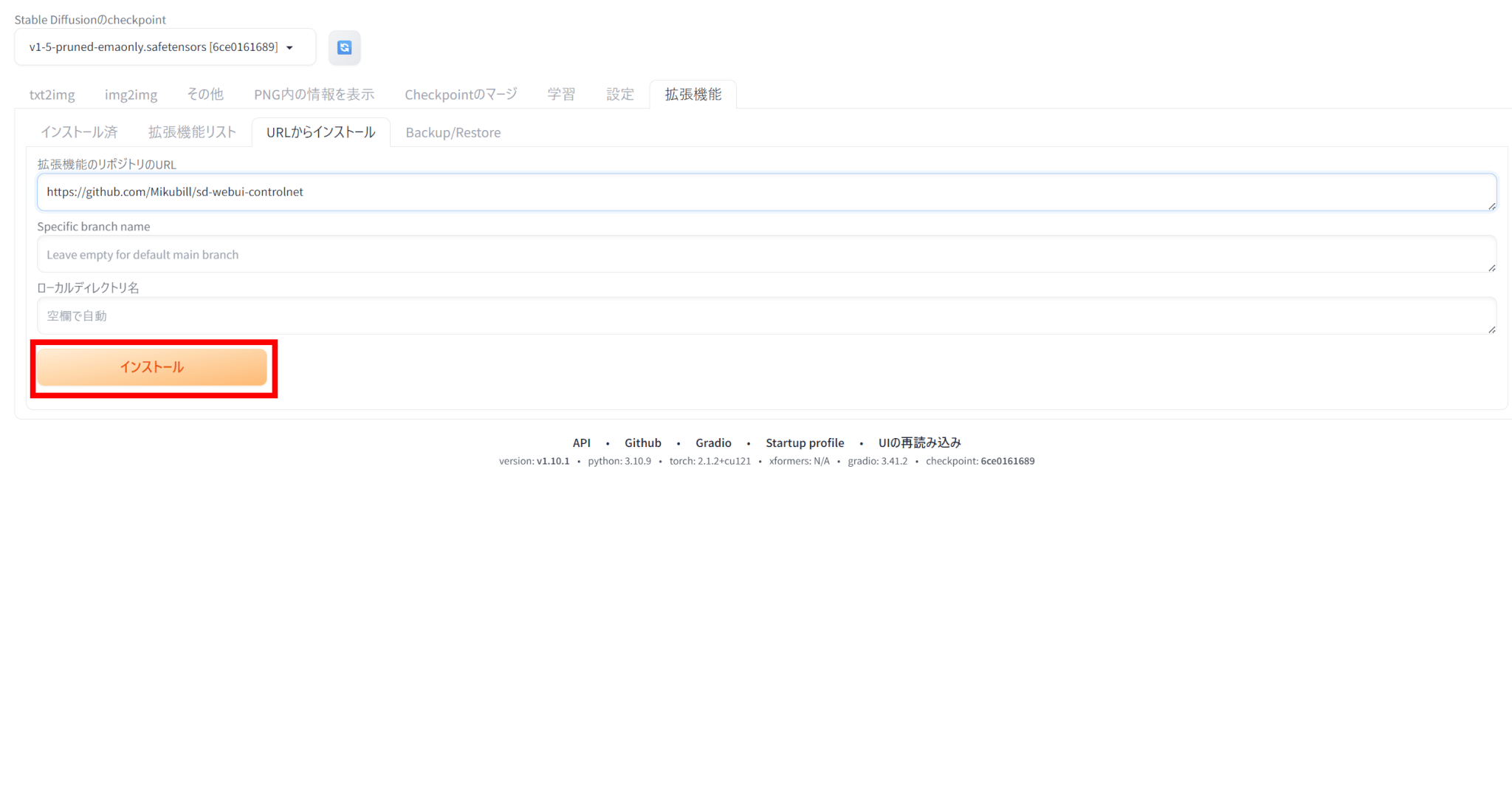
インストール後、「インストール済」の欄にControlNetがあることを確認し、「適用してUIを再起動」をクリックします。
再起動後、txt2imgにControlNetが追加されていれば、ControlNetが利用できる状態になっています。
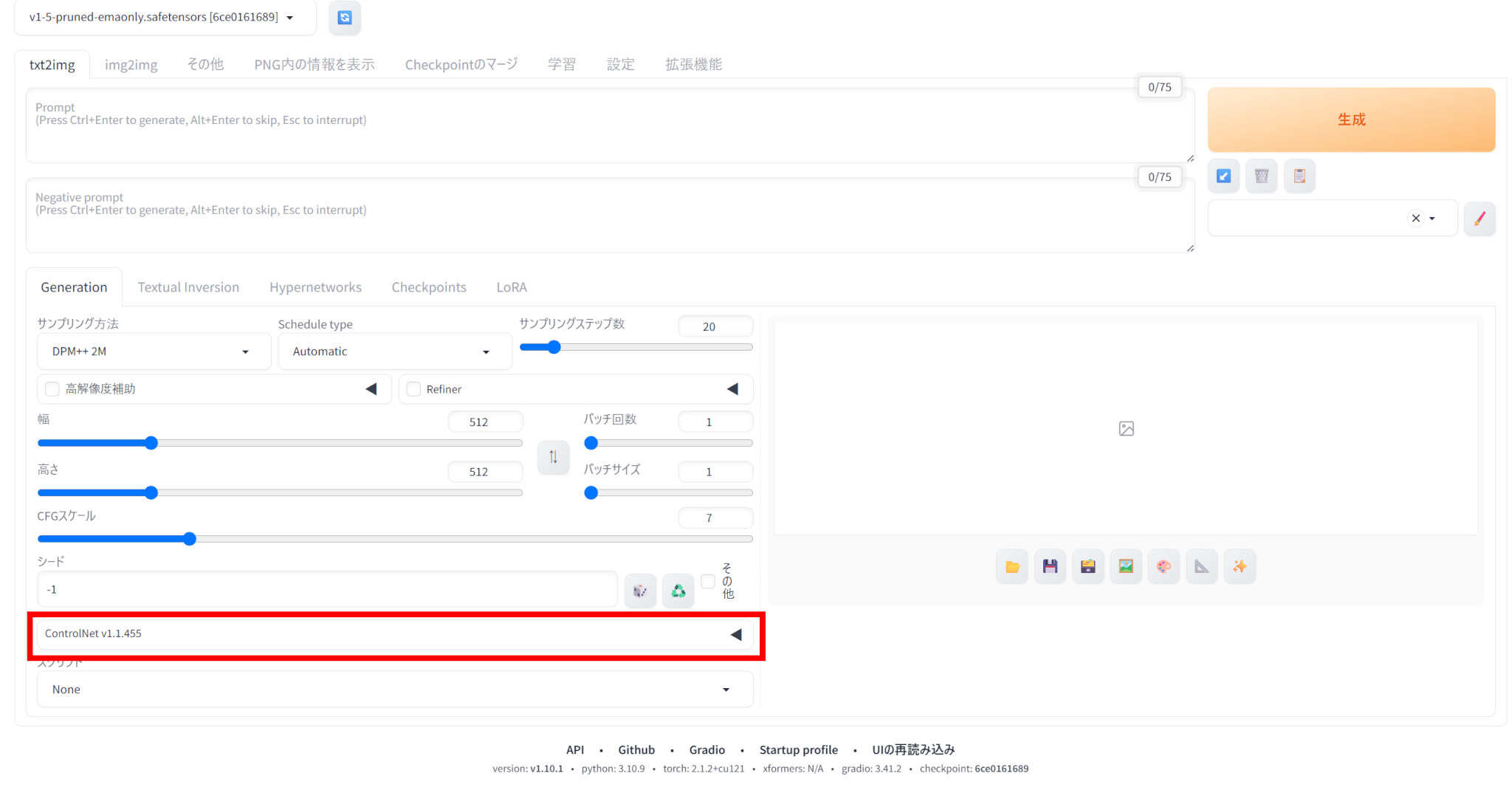
ControlNetを使うには、ControlNet用のモデルが必要です。
Hugging FaceやCivitaiを通じて、必要なモデルをダウンロードしましょう。
拡張機能の中でもControlNetは有名なので、まずはControlNetから試してみましょう。その後、ほしい機能があればWeb UI Extensionsを探してみてください。
スマホで使うStable Diffusion(iOS/Android)

ここまでPCを使ってStable Diffusionを利用する方法を解説してきましたが、実はスマホでも利用できます。
PCのようにローカルに環境構築して利用するのは無理ですが、Webサービスやスマホアプリを使うことで、Stable Diffusionを利用できます。
Stable Diffusionのスマホアプリはある?
Stable Diffusionを利用できるスマホアプリとしては、『Dream by WoMBO』があります。Dream by WoMBOはiOS、Androidの両方で利用でき、無料でも基本機能が使えます。
『Dream by WoMBO』ではプロンプトとスタイルを入力するだけで簡単にイラストを生成できます。
スマホで手軽にStable Diffusionを使った画像生成を試したい方は、スマホアプリを使うことをおすすめします。
Stable Diffusionをスマホで使う方法
Stable Diffusionをスマホで使うには、アプリをダウンロードして使う方法や、Webサービスに登録してブラウザ上で使う方法、LINEで使う方法があります。
Webサービスの例としては、Stable Diffusionオンラインがあります。無料で利用でき、プロンプトや画像の入力のみで細かな設定なしに画像生成が可能です。AIイラストくんというサービスでは、LINE友達に追加することでLINEのトーク画面から画像生成ができます。
このように、さまざまなサービスを活用することでスマホでも生成AIを使って画像生成を行うことが可能です。スマホを使って画像生成したい方は、まずはサービスに登録してみましょう。
商用利用・著作権・NSFW設定の注意点

Stable Diffusionを利用する際には、商用利用や著作権、NSFW設定において注意点があります。
ここでは、それらの注意点を解説します。
Stable Diffusionは商用利用できる?
Stable Diffusionは無料で利用可能ですが、使用する際にはライセンス条件を確認することが重要です。
2026年3月時点では、年間売上高が100万ドル未満の研究者、開発者、中小企業、クリエイターであれば無償で利用可能なCommunityライセンスが存在します。
一方で、エンタープライズ、APIプロバイダー、および年間売上高が100万ドルを超える企業の商用利用は有償のEnterpriseライセンスを利用する必要があるので注意しましょう。
Enterprise
For enterprise, API providers, and businesses with annual revenue exceeding $1M.License includes:
- Commercial Use
- Implementation Support
Available upgrades include:
- Custom Model Training
- Consulting Services
Custom Pricing和訳:エンタープライズ
年間売上高が100万ドルを超える企業、APIプロバイダー、および事業者向け。
ライセンスに含まれるもの:
商用利用
導入サポート
利用可能なアップグレード:
カスタムモデルのトレーニング
コンサルティングサービス
カスタム価格設定
出典:Stability AI
商用利用を考えている場合は、最新のライセンス情報を確認し、必要な手続きを行うようにしてください。
著作権の注意点
Stable Diffusionは、インターネット上の画像データを学習して画像を生成しているため、意図せず実在の人物や既存の著作物に酷似した画像を生成してしまう可能性があります。
利用の際、生成画像の権利は利用者に帰属する一方、第三者の著作権や商標を侵害しない責任はユーザーに課されています。元作品の実質的複製と見なされれば侵害に問われる恐れがあり、実際にアーティスト団体がStability AIを提訴した事例もあります。
A lawsuit that several artists filed against Stability AI, Midjourney, and other AI-related companies can proceed with some claims dismissed, a judge ruled yesterday.
和訳:複数のアーティストがStability AI、Midjourney、およびその他のAI関連企業を相手取って提起した訴訟について、一部の請求は却下されるものの、訴訟手続きは継続できるとの判決が昨日下された。
出典:The Verge
プロンプトに注意を払うことはもちろん、生成した画像が著作権を侵害していないかを確認することが必須です。
NSFWフィルタの設定
NSFWとは「Not Safe For Work」の略で、職場や公共の場で見ると不適切と判断され得る性的・暴力的・ショッキングな内容を含む可能性を示す警告ラベルです。
Stable DiffusionではCLIP埋め込みを用いたSafety Checkerが実装されており、NSFWと推定される画像は自動的に黒画像へ置き換えたり生成を停止したりします。AUTOMATIC1111ではNSFWフィルタは標準では組み込まれておらず、拡張機能として提供されています。拡張機能の設定からオン・オフを切り替えることができます。
ただし、フィルタを解除してローカル生成しても、ライセンスや各国法が禁じる児童ポルノ・過度な暴力表現などを公開・配信すれば規約違反や違法行為にあたる可能性があります。
NSFWフィルタの解除は自己責任であり、常に利用規約やコミュニティガイドラインを遵守し、責任ある利用を心がけてください。注意点を把握しつつ、生成物には責任を持つようにしましょう。
よくあるエラーとトラブルシューティング

Stable Diffusionを利用していると、さまざまなエラーが発生する可能性があります。
ここでは、よくあるエラーとその解決策をご紹介します。
Stable DiffusionのWeb UI(AUTOMATIC1111)が起動しないとき
Stable DiffusionのWeb UIが起動しない要因としては、Pythonが認識されていないことや、Pythonのバージョンが対応していないことが挙げられます。
以下のエラーが出た場合はPythonが正しく認識されていない可能性があります。
Couldn't launch pythonこのエラーが起きた場合、Pythonの位置情報を認識させるために、保存先をwebui-user.batに変更します。その後、webui-user.bat内を以下のように編集します。
set PYTHON=<Pythonのパス>また、AUTOMATIC1111で推奨されているPythonのバージョンは3.10.6であり、Pythonバージョンが対応していない場合は以下のエラーが発生します。
ERROR: Could not find a version that satisfies the requirement torch==1.13.1+cu117 (from versions: none)
ERROR: No matching distribution found for torch==1.13.1+cu117この場合は、PythonとAUTOMATIC1111を両方ともアンインストールし、再インストールしましょう。
画像生成がうまくいかないとき
Stable Diffusionを使っていて画像生成がうまくいかない原因としては、サーバー接続やGPUのスペック不足が考えられます。
Something went wrong Connecttion errored out.上記のようなエラーが出た場合、サーバーとの接続が切れていることが原因です。この場合はStable Diffusionを再起動することで対処可能です。
また、以下のようなエラーは、VRAMが不足していることが原因です。
Not enough memory,use lower resolution(max approx, ...).
Need:...,Have:...最も確実な対処法は、GPUの買い替えです。推奨VRAMは12GB以上なので、それに合ったGPUを選びましょう。
もし買い替えが難しいという場合は、webui-user.batのset COMMANDLINE_ARGS=行に以下のどちらかを設定することで解決できるかもしれません。
set COMMANDLINE_ARGS=--medvram
set COMMANDLINE_ARGS=--lowvramlowvramはVRAMへの負荷が大きく軽減できますが、処理にかかる時間がかなり長くなります。medvramの方が望ましく、可能であればGPUの買い替えをおすすめします。
トラブルがあった場合はこれらの方法を試してみてください。
まとめ:最速で上達する学習ロードマップ
Stable Diffusionは、無料で利用できる画像生成AIであり、オープンソースの利点を活かして、ローカル環境やクラウドサービス、Webサービスで導入できます。
まずは導入して基本操作を覚え、そこからさまざまなモデルやLoRA、拡張機能を使いこなせるようになっていけると理想的です。
商用利用も可能で、クリエイティブな作業の幅を広げるツールとなっています。
AIによる画像生成の魅力をぜひお試しください。
