

米Googleは日本時間5月21日深夜2時から、毎年恒例の開発者向けイベント「Google I/O」を米カリフォルニア州のショアライン・アンフィシアターにて開催しました。
今年のイベントは、特にAI技術「Gemini」を中心に、Googleの幅広い製品や新機能、最新の研究成果が次々と紹介されました。
Geminiシリーズの進化と普及状況
オープニングで登壇したCEOのスンダー・ピチャイ氏は、「私たちはGeminiの時代において、最も先進的なAIモデルをより速く皆さんに提供しています」と述べ、この1年で20以上の主要なAI製品や機能をリリースし、開発者向けに700万人以上がGemini APIを利用していることを明らかにしました。
また、Geminiが扱う処理トークン数は前年の9.7兆件から480兆件へと急増しており、AI技術の急速な普及を強調しました。Geminiシリーズの進化に伴い、コーディング能力や推論能力が大幅に向上したことも示され、技術的なブレークスルーが相次いでいることが示されました。
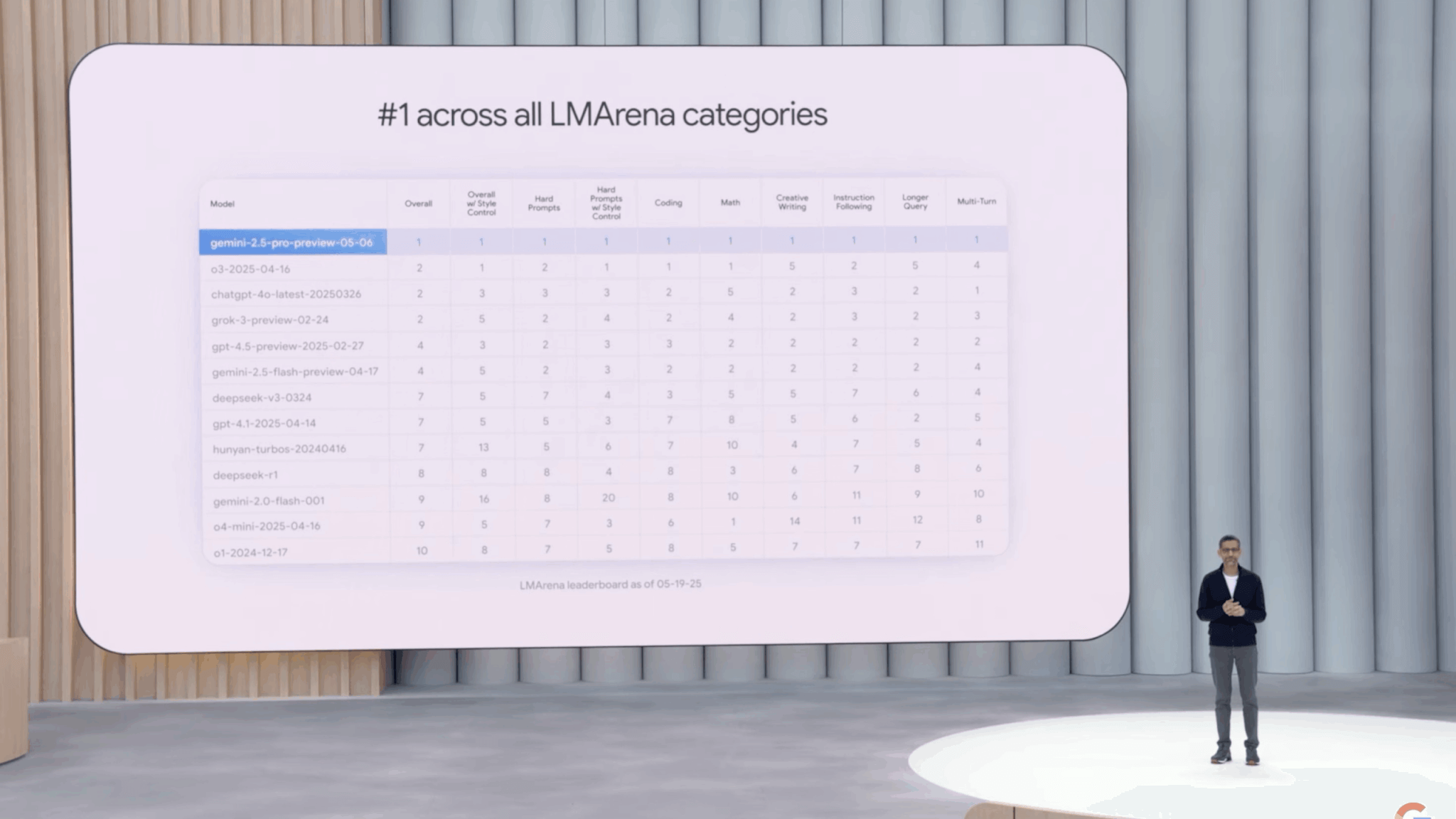
各種ベンチマークで最高性能を記録した「Gemini 2.5 Pro」
「Gemini 2.5 Pro」は、AIモデル性能評価の主要ベンチマーク「Chatbot Arena」の全カテゴリで最高の性能を記録しました。
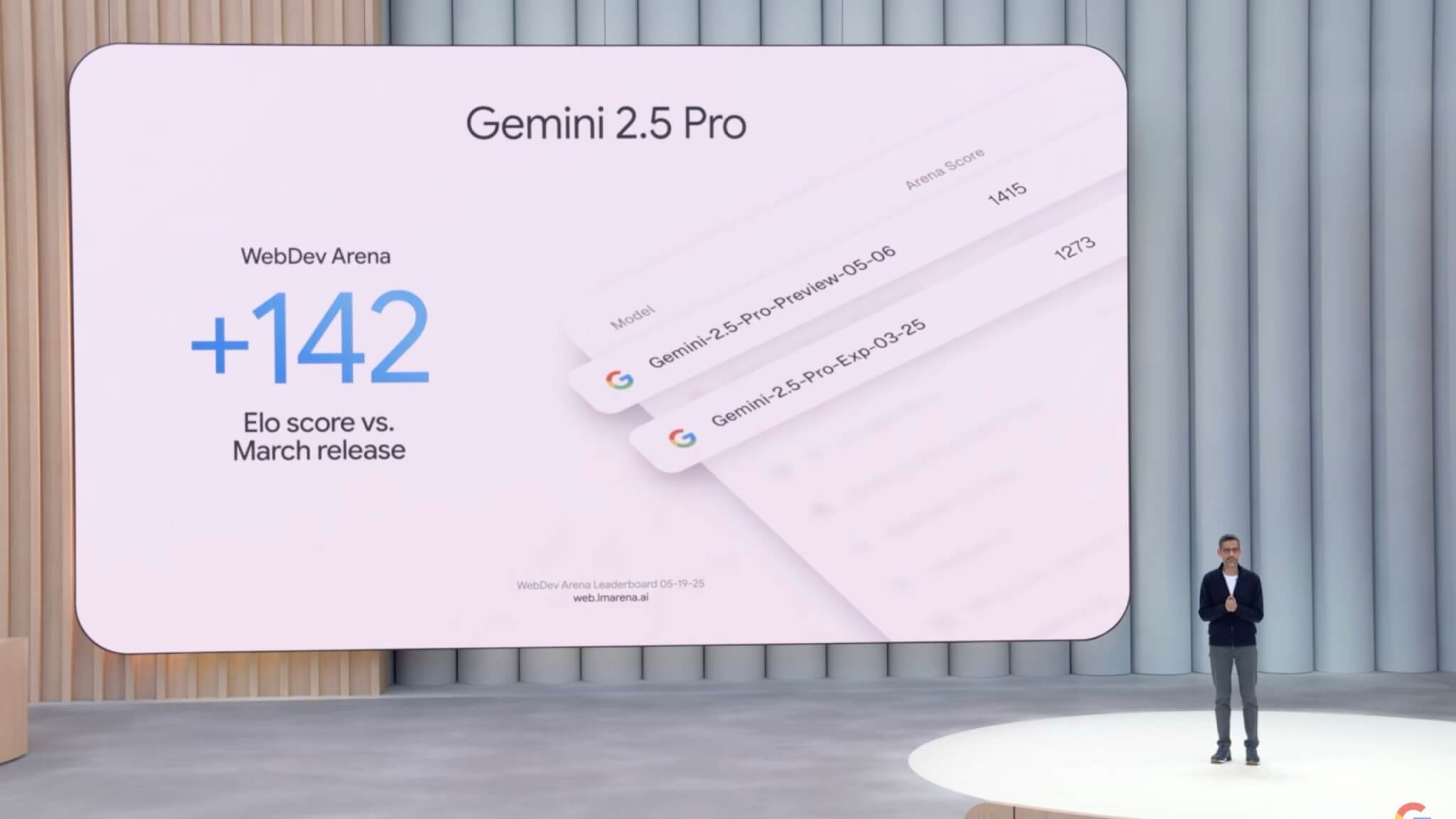
ウェブ開発ベンチマーク「WebDev Arena」でも従来モデルを142 Eloポイント上回り、圧倒的な性能を示しています。
さらにAIコードエディターの「Cursor」では、2025年に最も急成長したモデルとして評価されており、毎分数十万行のコード生成を実現しています。
開発者のGemini API利用・Vertex AIの利用者・Geminiアプリのユーザー数が大幅増
Gemini APIを利用している開発者は現在700万人を超え、昨年のGoogle I/Oから5倍以上に拡大しました。また、機械学習プラットフォームVertex AI上でのGemini利用は前年比40倍以上増加しています。
さらに、Geminiアプリの月間アクティブユーザー数は4億人を突破しており、特に最新のGemini 2.5モデルでの利用は45%の伸びを記録しています。

Google Beamを発表!リアルな3D映像通話を実現

Googleは、新しいAIベースのビデオコミュニケーションプラットフォーム「Google Beam」を発表しました。これは数年前のGoogle I/Oで紹介された「Project Starline」の進化版で、リアルタイムでリアルな3D映像通話を可能にする技術です。
AIで実現するリアルタイム3D映像コミュニケーション
「Google Beam」は、AI技術を活用して複数のカメラから撮影した2D映像をリアルタイムで処理し、自然で立体感のある3D映像を生成します。専用の3Dディスプレイ上で相手が目の前にいるかのような、没入感のある対話が可能になります。
また、頭の位置をミリ単位で追跡し、毎秒60フレームという非常に滑らかな映像を実現しており、これまでにない臨場感のあるコミュニケーションを提供します。
HPと協力、2025年内に製品化予定
Googleは、この新技術を搭載した「Google Beam」のデバイスをHPと共同開発しています。製品は2025年内に早期利用顧客向けに提供が開始される予定で、具体的な製品の詳細や提供方法についてはHPから今後数週間以内に発表される見通しです。
Google Meetにリアルタイム音声翻訳機能を導入
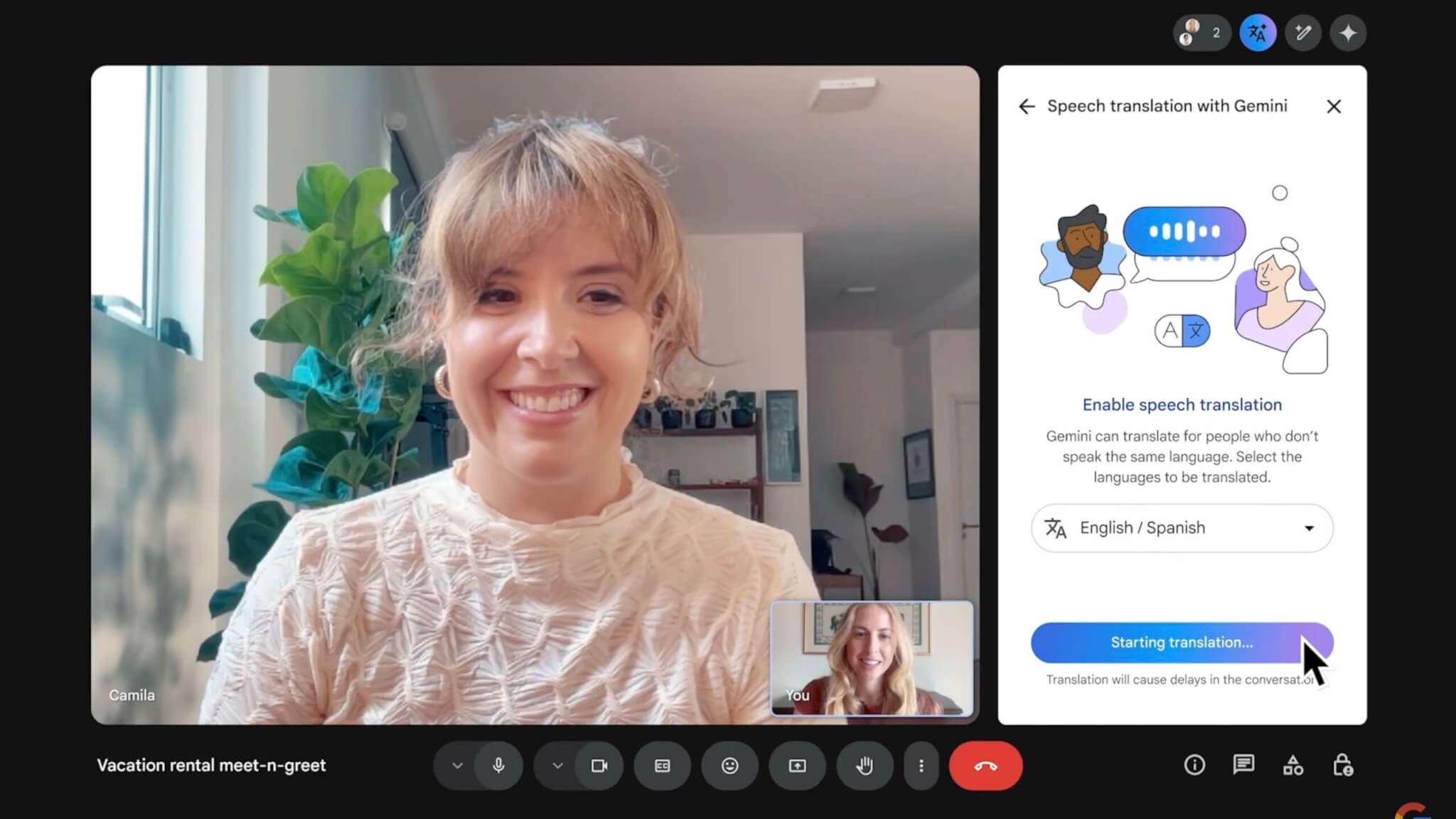
Googleは、ビデオ会議アプリ「Google Meet」にAIを活用したリアルタイム音声翻訳機能を新たに導入すると発表しました。これにより、言語の壁を越えて、参加者同士が互いの言語でスムーズに会話できる環境が整います。
英語とスペイン語間の翻訳機能を先行リリース
イベント中には、英語とスペイン語間でのリアルタイム音声翻訳機能のデモが行われました。デモでは、英語を話す利用者がスペイン語を話す相手との会話を自然な流れで進める様子が披露され、翻訳の正確さと、遅延を感じさせないスピーディな処理性能を印象付けました。
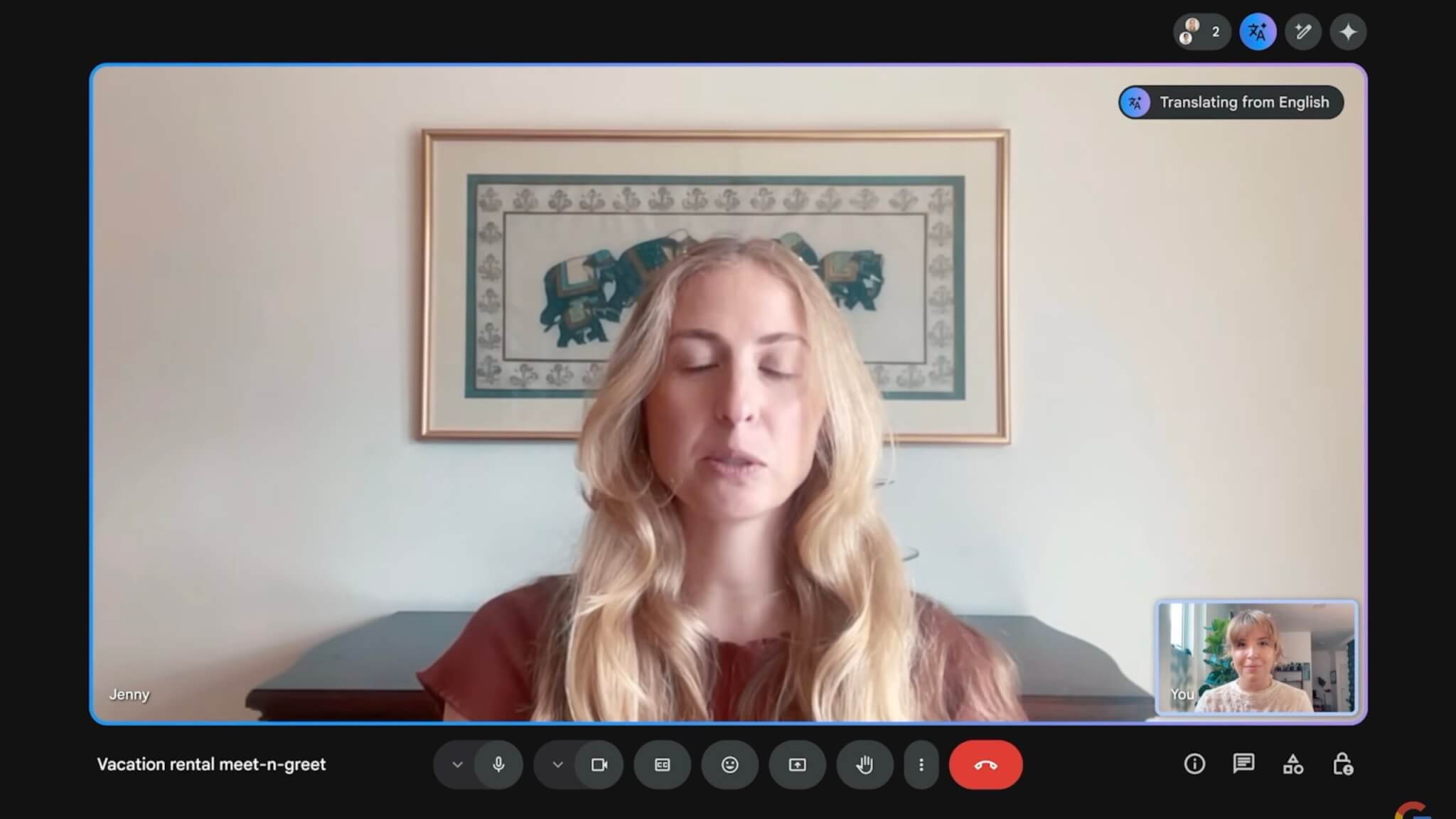
また、単に言葉を翻訳するだけではなく、話し手の声のトーンや話し方のニュアンスまでをも捉えて、聞き手に自然なコミュニケーション体験を提供できる点も強調されました。
企業向けの展開を2025年内に開始
Googleはさらに、現在サブスク契約者向けに提供しているこのリアルタイム音声翻訳機能を、2025年内に企業ユーザー向けにも提供する計画を発表しました。企業での導入により、グローバルな業務連携をスムーズに進められるようになります。
加えて、対応言語も順次拡充される予定で、まず英語とスペイン語の他に複数の主要言語への対応を目指しています。これにより、多様な国籍のメンバーが参加するグローバルチームや、多国籍企業でのオンラインミーティングにおいても、言語を意識せず自然にコミュニケーションを取れる環境が整う見通しです。
Project AstraのGemini Liveへの統合を発表

Googleは新たなAIエージェント技術「Project Astra」がGemini Liveへ統合されると発表しました。この技術はスマートフォンのカメラや画面共有を活用し、ユーザーが見ている内容についてリアルタイムでAIと対話を行うことができます。利用者の日常生活や仕事でのさまざまなシーンに役立つ機能が提供されます。
Project Astraでカメラを通じたAIとの自然なコミュニケーションを実現
イベントでは、ユーザーがカメラを通じてAIエージェントに質問を投げかけ、AIがリアルタイムで画像を解析して回答する様子がデモとして披露されました。例えば、ユーザーがゴミ収集車をオープンカーと勘違いした際にも、AIが即座にその誤認識を指摘するなど、対話の正確さと即時性を印象づけました。
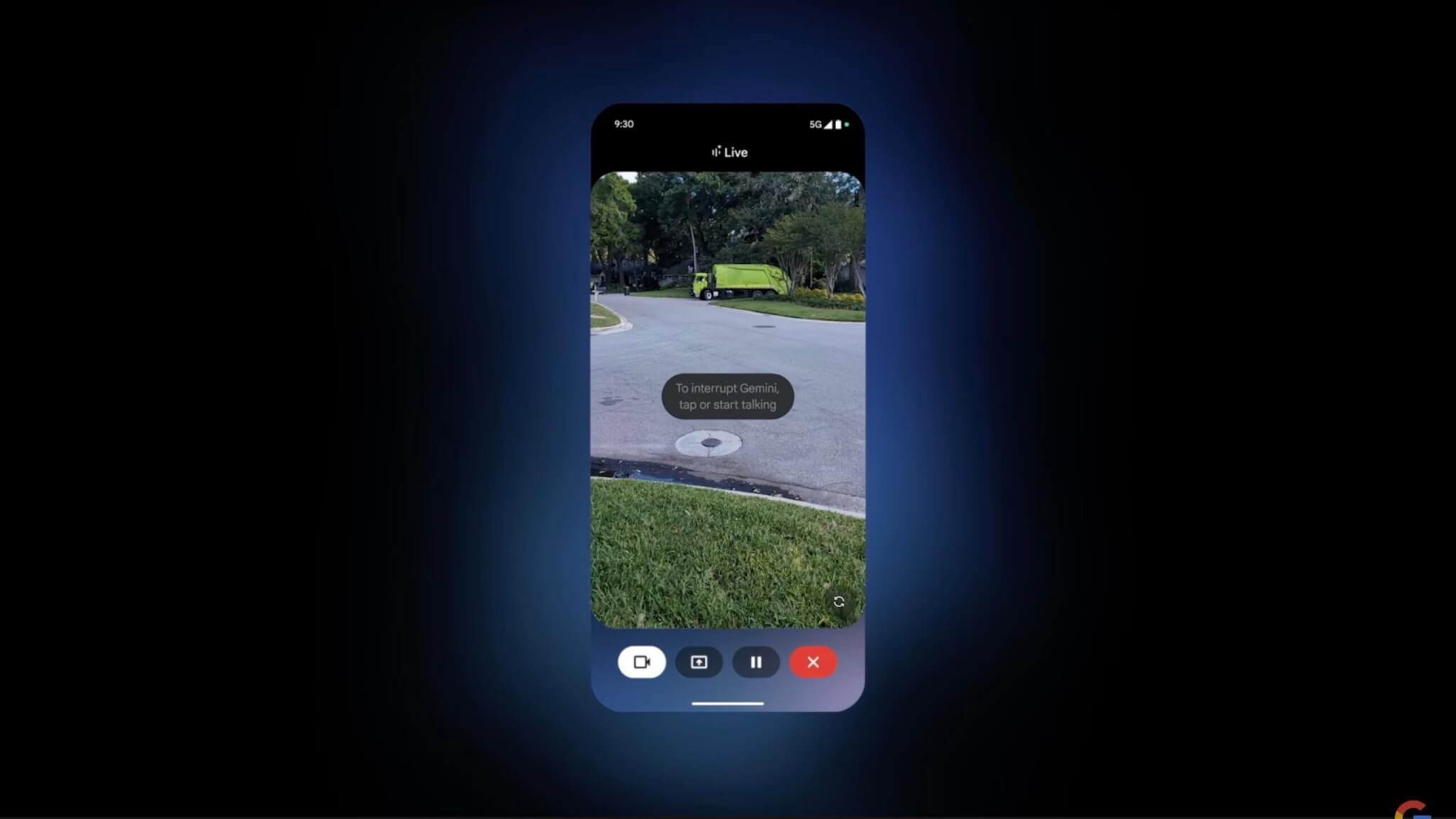
このリアルタイム対話型の技術により、利用者は日常の様々な疑問をその場で解決できるだけでなく、AIとの自然なコミュニケーションを通じて作業の効率化や新たな気づきを得ることが可能になります。
AndroidとiOS向けに即日提供開始、一般ユーザーもすぐに利用可能に
このAIエージェント技術は、「Gemini Live」としてGoogleのスマートフォンアプリに統合され、イベント当日から即座にAndroidおよびiOSユーザーに提供開始されました。これにより、一般の利用者もすぐに最先端のAIコミュニケーション機能を利用可能となりました。
Gemini Liveは45以上の言語に対応し、150カ国以上で即日(2025年5月21日)から無料で提供開始されています。
さらに、今後はGoogleの各種アプリとの連携を強化する予定で、Googleカレンダー、Googleマップ、Google Keep、Tasksなどの日常的に利用するサービスとの連携も近日中に実現する見込みです。これにより、ユーザーの日常生活や仕事のタスク管理においても、AIエージェントが強力な支援を提供できるようになります。
Project Marinerが進化し「Agent Mode」としてGeminiアプリに統合

Googleは、AIが複雑なタスクを自律的に処理できる技術として2024年12月に発表していた「Project Mariner」をさらに進化させ、「Agent Mode」としてGeminiアプリに統合すると発表しました。この機能により、AIが複数のタスクを同時並行的に処理し、ユーザーの日常的な作業負担を大幅に軽減します。
複数タスクの同時処理と自動学習機能を搭載
新たに導入された「Agent Mode」では、最大10個のタスクを同時に並行処理できる能力を備えました。さらに、ユーザーが行った作業をAIが学習し、以降の似たタスクを自動的に実行できる「Teach and Repeat」という自動学習機能も追加されています。
たとえば、ユーザーが物件探しをする際、AIが不動産情報サイトを自動で検索し、希望に合った条件の物件を抽出、さらに見学予約まで自動で行うことができます。
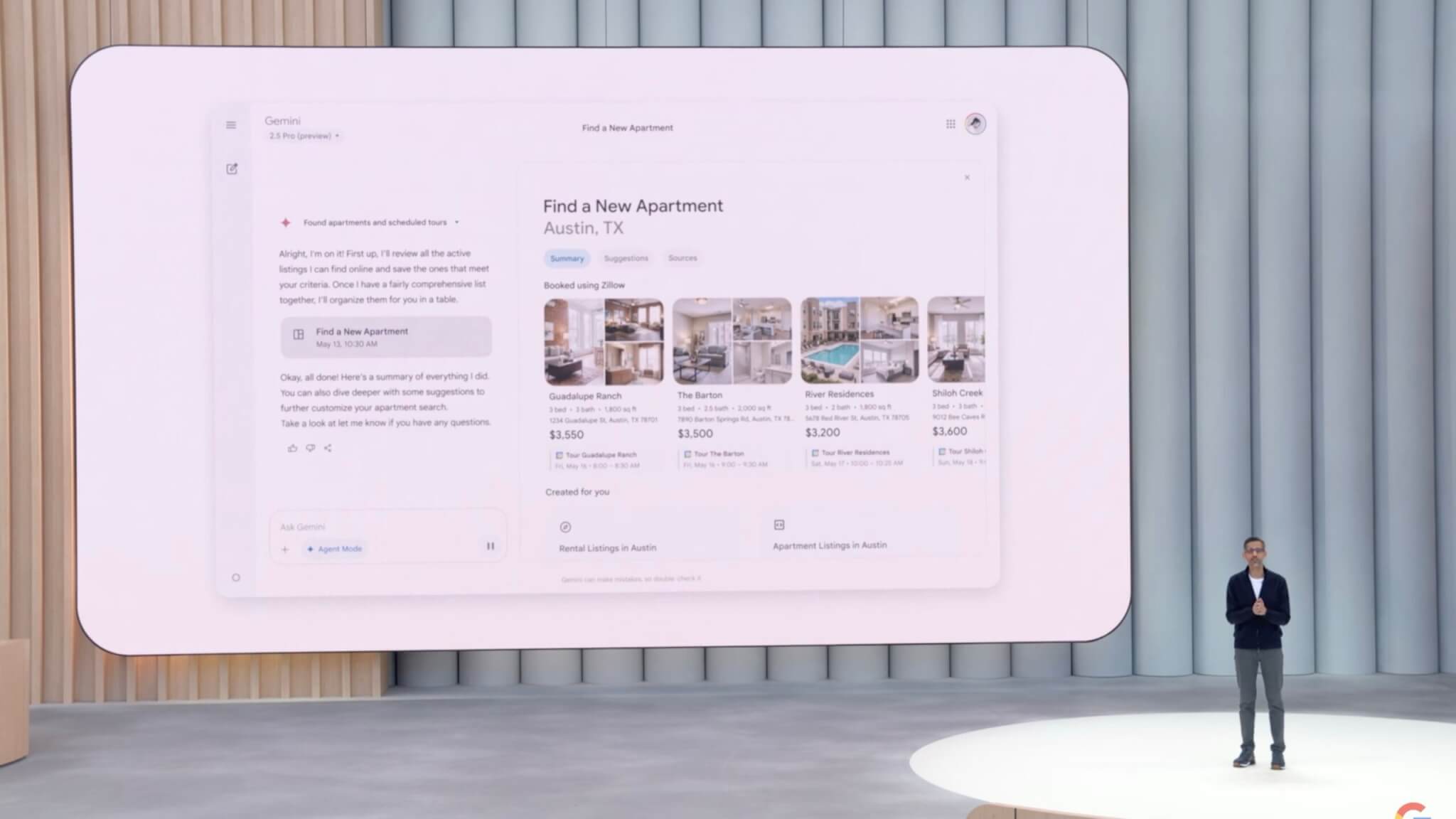
これにより、ユーザーは細かな検索や面倒なフォーム入力作業を行わずに、より簡単に目的を達成できるようになります。
他のAIエージェントとの連携を可能にするGemini SDKのMCP対応を発表
さらにGoogleは、Agent Modeを搭載したGeminiが他のAIエージェントや外部サービスと連携できるよう、Gemini SDKがモデルコンテキストプロトコル(MCP)に対応することも発表しました。

これにより、AIエージェント間での連携や外部サービスとの相互接続が容易となり、さまざまなサービスが統合的に利用できる環境が実現されます。
すでに自動化ソフトウェア企業のAutomation AnywhereやUiPathなどがこの新機能を使い始めており、今後さらなるサービスの拡充が見込まれています。
Gmailに「パーソナライズドSmart Reply」追加!個人に合わせた返信をAIが支援
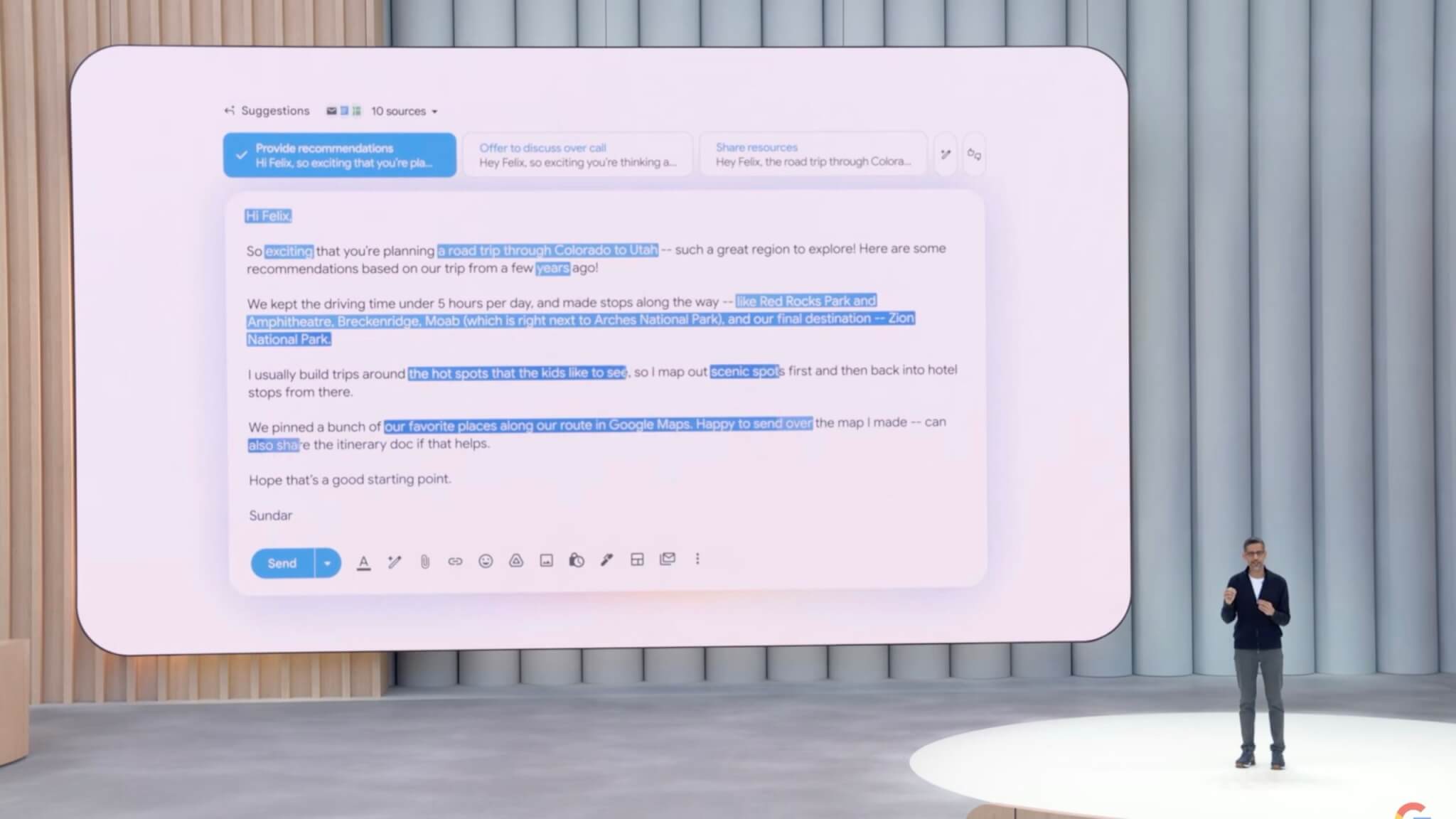
Googleは、Gmailに搭載されているAIによる返信支援機能を大幅に進化させ、「パーソナライズドSmart Reply」として提供を開始することを発表しました。
この新機能により、ユーザーの個人情報や文体に基づいた、自然かつ個人的な返信生成が可能になります。
AIがユーザーの文体や過去のメール履歴を学習し、自動的に返信を生成
新機能「パーソナライズドSmart Reply」では、ユーザーが日頃使用している言葉遣いや表現、メールでの挨拶などをAIが学習します。これにより、自動的に生成される返信文が、本人のスタイルを忠実に再現した自然な仕上がりになります。
たとえば、友人から旅行先についての相談を受け取った場合、Gmailはユーザーが以前訪れたことのある場所に関する過去のメールのやり取りやGoogleドライブ内の旅行記録、予約情報などを参照します。それらを元に、個人の経験や文体に基づく詳細な返信をAIが自動的に提案します。
ユーザーが情報利用の範囲を自由に管理可能、透明性とプライバシーに配慮
Googleは「パーソナライズドSmart Reply」の導入にあたり、個人情報の取り扱いを透明化しています。ユーザーは、この機能を利用するかどうか自由に設定できるほか、GoogleドライブやGmail内のどの情報を利用するか、具体的な範囲を明確に管理することが可能です。AIがどの情報を利用したのかを確認し、設定を随時調整することもできます。
Googleはこの新しいパーソナライズ機能を2025年夏頃にGmailユーザーに対して順次提供開始する予定です。
Geminiシリーズに新モデルや新機能を追加

Googleは、AIプラットフォーム「Gemini」シリーズの新たなモデルや機能の追加を発表しました。高性能で効率的な新モデルや、ユーザーがAIの挙動を細かく制御できる機能を拡充することで、開発者や利用者がより多様な用途でAIを活用できるようになります。
Gemini 2.5 Flashを発表
Googleは、Geminiシリーズの新たなモデル「Gemini 2.5 Flash」を発表しました。このモデルは、従来の「Gemini Flash」の後継となるもので、性能と効率が全面的に改善されています。
具体的には、Gemini 2.5 Flashは、従来モデルと比較して推論性能が大きく向上し、LMArenaベンチマークでGemini 2.5 Proに次ぐ第2位の性能を記録しました。

さらに、効率性も大幅に改善されており、従来と同じ性能を発揮するために必要なトークン数が22%削減されました。これにより、同等以上の品質を維持しながら、低コストでの運用が可能となります。
Gemini 2.5 Flashは、2025年6月初旬に一般提供を開始する予定で、Google AI Studio、Vertex AI、Geminiアプリなどで利用できるようになります。
ユーザーがAIの推論コストと精度を調整できる「Thinking Budgets」機能を導入
GoogleはGeminiシリーズに新たな「Thinking Budgets」機能を追加すると発表しました。この機能は、AIが回答を導き出すまでの思考(処理)に使うトークン量をユーザー自身が調整できるようにするもので、コストや応答速度とAI推論の精度とのバランスを柔軟にコントロールできます。
具体的には、「Thinking Budgets」を使用することで、ユーザーはGeminiが回答を生成する前に、どの程度の量の「考える(推論)ためのトークン」を使わせるかを指定できます。これにより、予算や目的に合わせて、AIの推論精度を高めたり、逆に迅速な応答を重視してトークン使用量を抑えることが可能になります。
この新機能は既に提供中のGemini 2.5 Flashに続いて、今後数週間以内にGemini 2.5 Proにも導入される予定です。
非同期型AIコーディング支援ツール「Jules」が公開ベータを開始
Googleは、開発者のコーディング作業を自動化して効率化する新たな非同期AI支援ツール「Jules」の公開ベータ版の提供開始を発表しました。

「Jules」は、開発者が行うコードのバグ修正やアップデート作業をAIが代行するもので、開発者がタスクを指示すると、AIが自動で処理を進めます。特に、Node.jsのバージョンアップなどの複雑な作業を自動化することが可能で、作業に要する時間を大幅に短縮できます。
このツールはGitHubとも統合されており、AIがコードの修正や変更を直接GitHubのリポジトリに反映することも可能です。そのため、開発者は複雑なコード管理作業を簡単かつ迅速に進められます。
イベント時点で「Jules」の公開ベータ版は既に提供開始されており、開発者であれば誰でも無料で利用を開始することができます。Googleは今後のフィードバックをもとに、このツールのさらなる改良や機能拡張を進めていく方針です。
テキスト生成を高速化する新モデル「Gemini Diffusion」を発表
Googleは、新しいテキスト生成モデルである「Gemini Diffusion」を発表しました。このモデルは、従来のような逐次(左から右へ順番に)テキストを生成する方式とは異なり、並列に文章を生成する拡散(Diffusion)方式を採用しています。

この新しい方式により、従来モデル(Gemini 2.0 Flashlight)と比較して約5倍という非常に高いテキスト生成速度を実現しました。特に数学的な問題やプログラミングコードの生成など、精度が求められる複雑な内容の生成においても、高速かつ正確な生成が可能になります。
発表イベントでは、実際のデモとして複雑な数式を解く問題を瞬時に回答する様子が紹介され、その並行処理能力と正確性をアピールしました。Gemini Diffusionモデルは現在、一部の限定的なテスターに提供されていますが、将来的には一般ユーザーにも提供される予定です。
また、この並列拡散方式を今後さらに改善し、Geminiシリーズの他モデルにも応用することで、AIの推論全般の速度や精度をさらに高める計画も発表されています。
高度な推論を実現する「Gemini 2.5 Pro DeepThink」モードを公開
Googleは、Gemini 2.5 Proに高度な推論能力を備えた新機能「DeepThink」モードを導入すると発表しました。この「DeepThink」モードは、特に複雑で高難易度な問題を解決する際にAIモデルの能力を極限まで引き出し、従来モデルを大きく上回る高度な推論を可能にします。

具体的な性能としては、難関数学ベンチマークであるUSAMO 2025(米国数学オリンピック)で非常に高いスコアを獲得したほか、競技レベルのコーディングを評価するベンチマーク「Live Code Bench」でも首位を記録しました。また、多様なマルチモーダル能力を評価するベンチマーク「MMMU」でも業界トップの性能を達成しています。
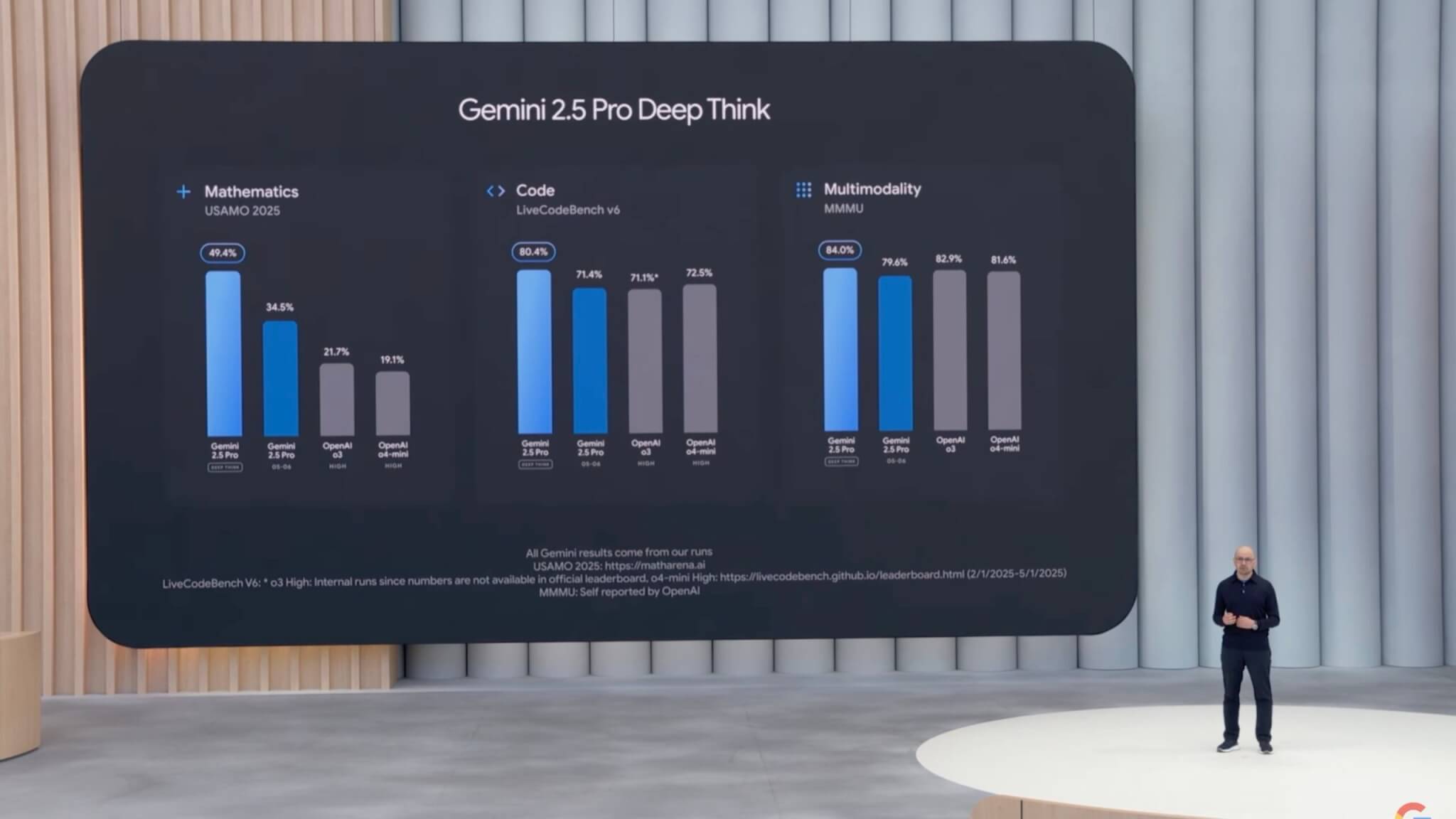
ただし、このDeepThinkモードは非常に高い推論能力を持つことから、Googleは安全性や倫理的な側面の評価を追加で実施するとしています。そのため、まず限定された信頼できるテスターにのみ提供し、安全性評価を完了した後、一般ユーザーへの公開を予定しています。
なお、このDeepThinkモードは、新料金プラン「Google AI Ultra」の加入者向けにも優先的に提供される見込みです。
Google検索の「AIモード」が進化!個人向け機能や高度な検索能力を大幅強化
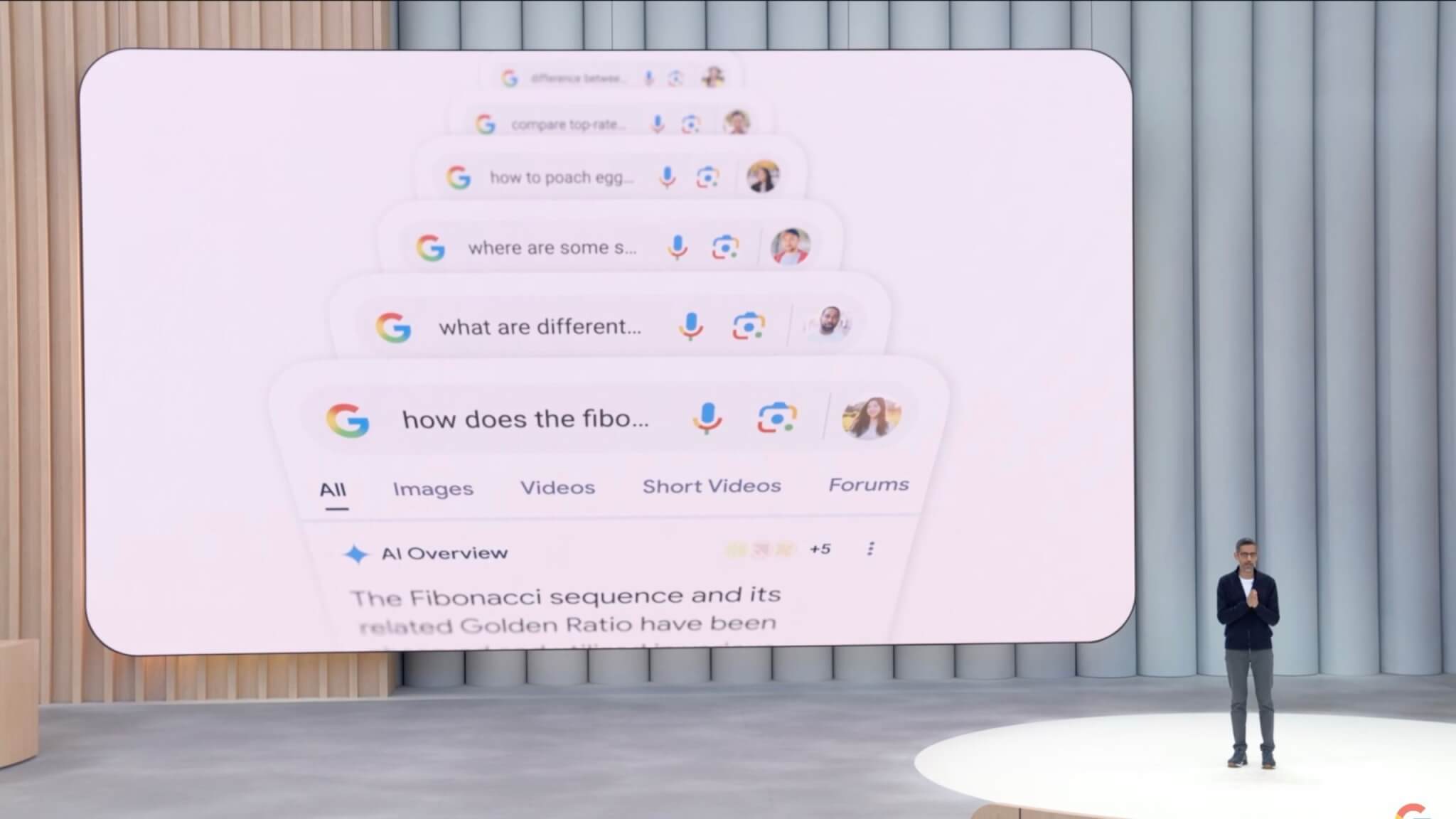
Googleは、検索エンジンに導入されているAIベースの検索体験「AIモード」を大幅に進化させ、一般ユーザー向けの提供開始と新機能の追加を発表しました。特にAIを活用した検索結果表示や、個人向けのパーソナライズ機能が強化されています。
「AIモード」が米国のすべてのユーザーに一般提供開始、Gemini 2.5の最先端AIを活用
Googleは、AIをフル活用した新しい検索体験である「AIモード」を米国内のすべてのユーザーに対して、2025年5月21日より正式に提供開始しました。

このモードでは、Geminiシリーズ最新モデルである「Gemini 2.5」が搭載されており、複雑で長い質問や深い推論が必要な検索に対しても迅速かつ精度の高い回答を提示できるようになっています。
また、「AIモード」は単純な情報提示にとどまらず、テキスト、画像、リンク、地図などの多彩な情報を最適な形式で動的に組み合わせて表示します。ユーザーが自然な会話形式でフォローアップの質問をすることも可能で、従来の検索よりも遥かに柔軟で直感的な検索体験を提供します。
15億人以上が利用する「AI Overviews」にもGemini 2.5を導入、検索精度と速度が向上
Googleは2024年に導入した検索結果の要約機能である「AI Overviews」にもGemini 2.5を導入し、品質と応答速度を大幅に向上させました。現在、AI Overviewsは世界200カ国以上、月間15億人以上のユーザーに利用されています。

Gemini 2.5導入により、従来よりも複雑なクエリに対応できるようになっただけでなく、生成速度も業界最速レベルに達しています。さらにAI Overviewsの導入により、米国やインドなどの主要市場で検索クエリ数が10%以上増加しており、この傾向は継続的に伸びています。
個人の状況に応じて最適化する「パーソナルコンテキスト」を夏に導入
新機能「パーソナルコンテキスト」が2025年夏に導入されます。この機能により、ユーザーの過去の検索履歴、Gmailにある旅行予約やイベント情報などを基に、検索結果が個別に最適化されます。
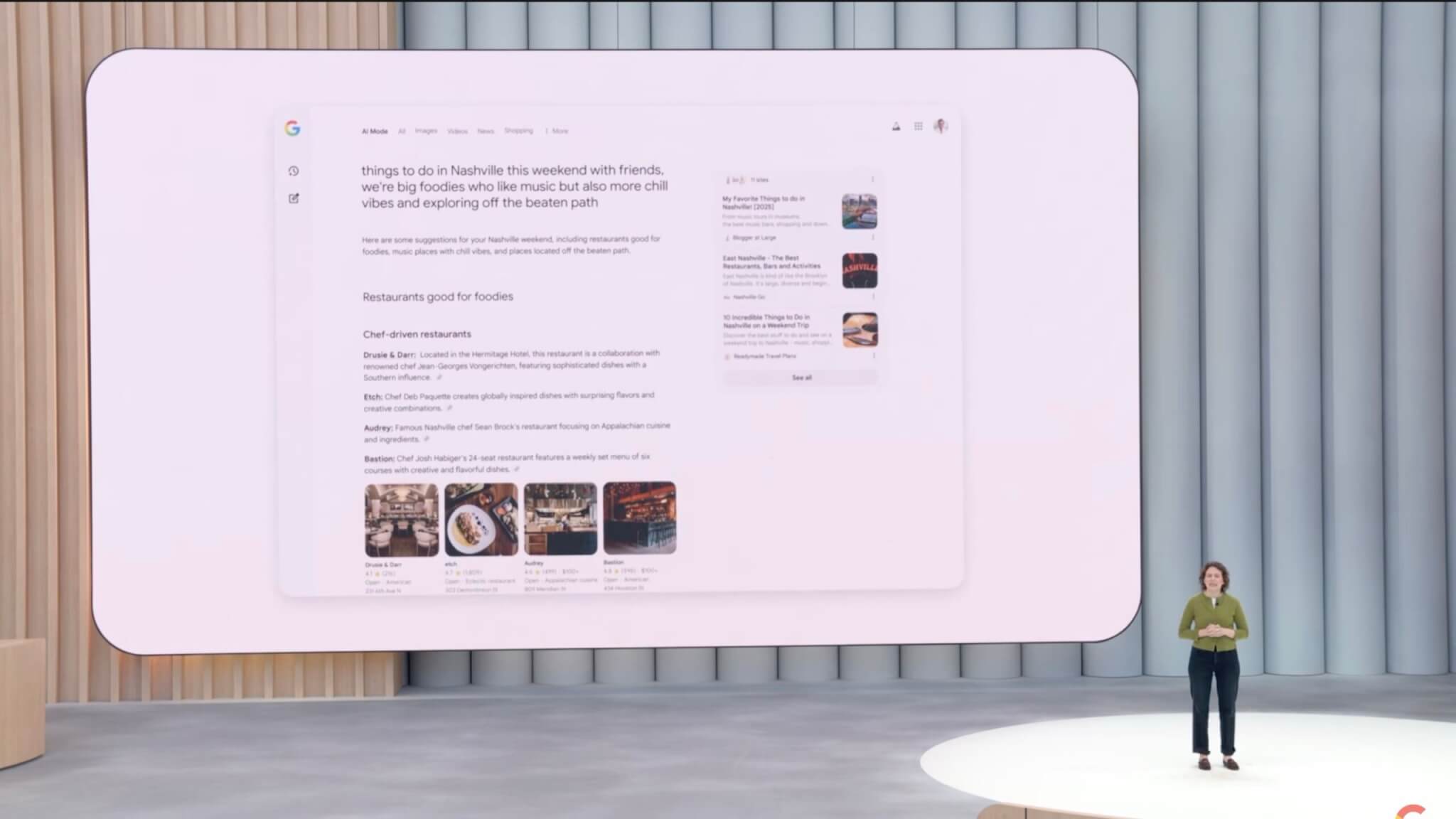
例えば、過去の検索からユーザーが屋外での食事を好むことを認識し、検索結果にユーザーの趣向に合ったレストランを表示します。また、旅行先や宿泊先の予約情報がGmailにあれば、その期間や地域に合ったイベントやレストラン情報を提案します。この機能はユーザーが任意でオンオフを切り替え可能で、情報共有の範囲も自由に管理できます。
複雑なテーマの徹底調査をAIが自動で行う「Deep Search」を発表
Googleは、複雑な調査や専門的な内容を深掘りできる新機能「Deep Search」を発表しました。この機能は、ユーザーが入力した複雑な質問をAIが複数の小さな質問に分割し、それぞれを同時に多数の検索クエリとして実行します。その結果を総合的に分析し、信頼できる情報源を引用した詳細なレポートを数分で自動的に作成します。
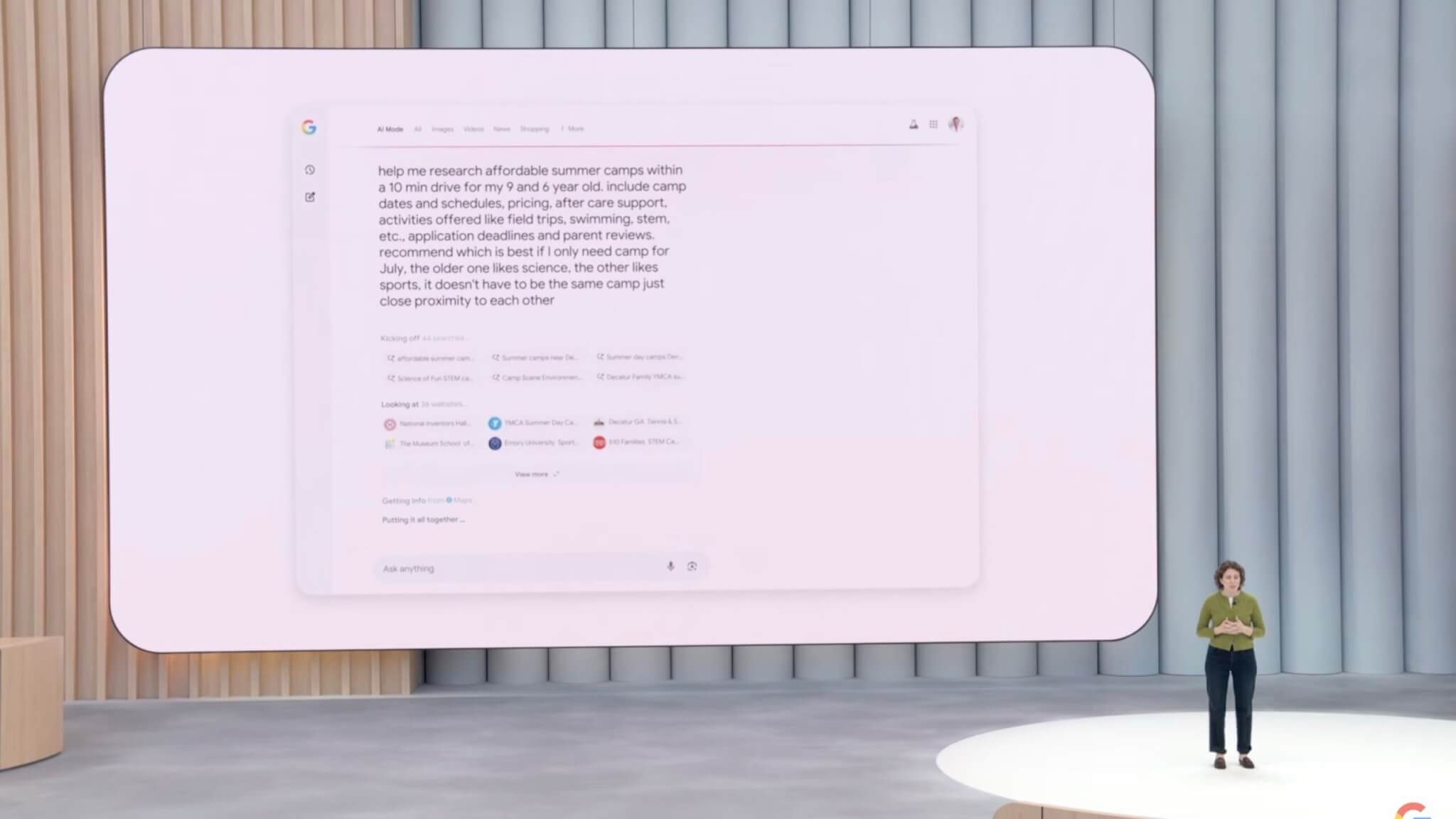
この新しい検索機能は、特に専門的なトピックや学術的な調査、ビジネス分析などの場面で強力な支援となり、2025年内にGoogle検索のAIモードで提供開始予定です。
「Search Live」でカメラを使ったリアルタイムなマルチモーダル検索を導入
GoogleはProject Astraの技術を応用し、カメラを通じてリアルタイムでAIと会話しながら情報を得ることができる新機能「Search Live」を発表しました。ユーザーはスマートフォンのカメラを使い、自宅でのDIY作業や学校の課題、身近な物に関する質問などを直接AIに尋ねることができます。
デモ映像では、子供たちが家庭で科学実験を行い、AIがリアルタイムで的確な指示やアドバイスを提供する様子が紹介されました。
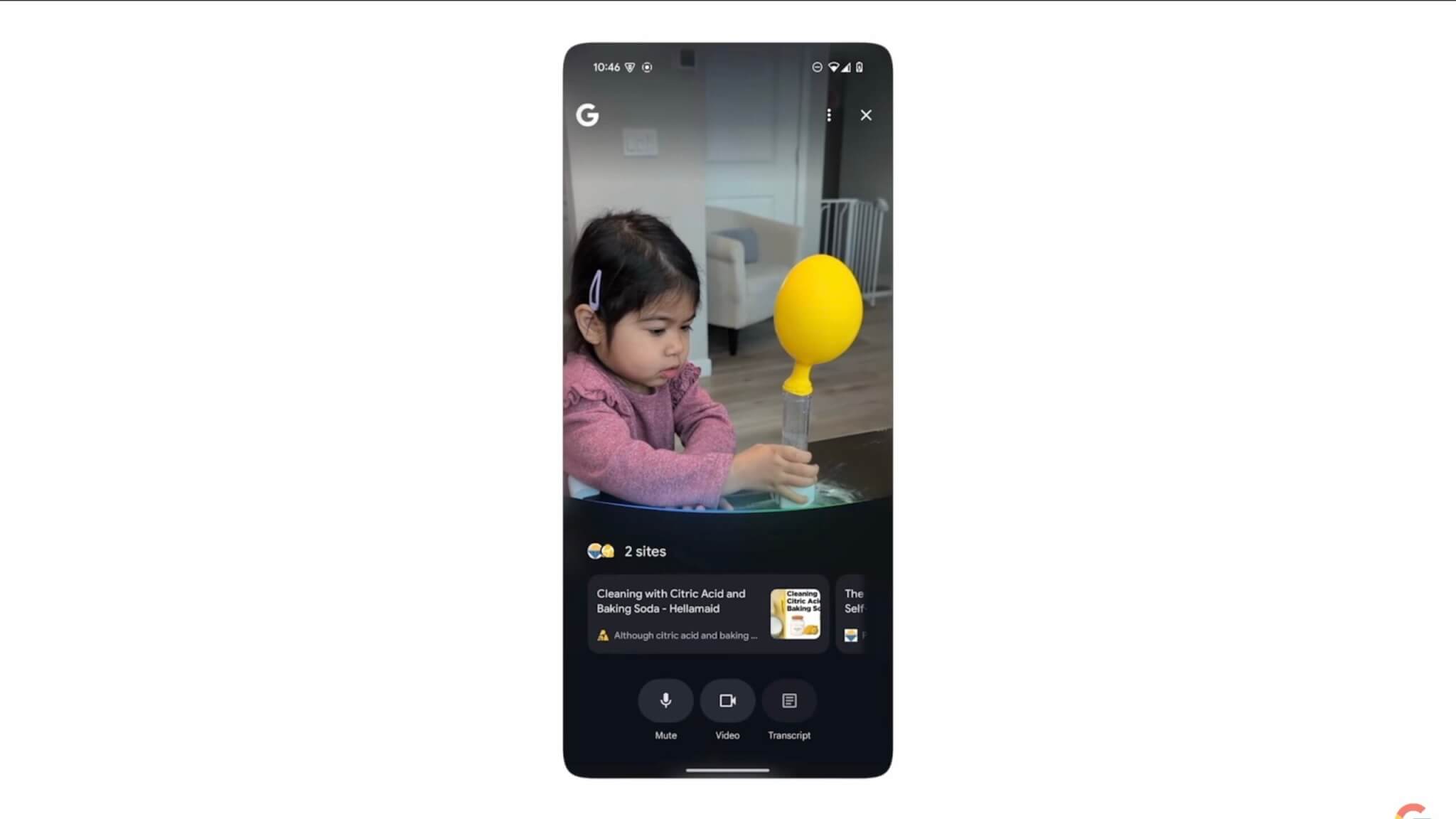
Search Liveは2025年内に提供開始される予定です。
「ビジュアルショッピング」と「バーチャル試着」を提供開始
Googleは検索エンジン内でのショッピング機能を大幅に強化し、特に視覚的な検索とバーチャル試着機能を導入しました。AIモードにおいて、ユーザーが特定の商品を検索すると、その商品の画像や関連商品が個々のユーザーの好みに合わせて表示される「ビジュアルショッピング」が提供されます。

また、新たにバーチャル試着機能も追加されました。ユーザーが自分の写真をアップロードすると、AIが商品の着用イメージをリアルにシミュレーションします。この技術は、人間の体型と服の素材の質感、ドレープ、伸縮性などを非常に高い精度で再現することが可能であり、特にファッション商品のオンライン購入時の参考になります。
このバーチャル試着機能は、イベント当日(2025年5月21日)よりGoogle検索のLabsにて試験的に提供が開始されています。
「エージェント型チェックアウト」機能を導入し価格監視から購入手続きまでAIが代行
さらにGoogleは、オンラインショッピングでの購入プロセスをAIが代行する「エージェント型チェックアウト」機能を発表しました。この機能では、欲しい商品の価格がユーザーの設定した希望価格に達した場合、自動的に通知が届き、AIが購入手続きを進めます。購入時の支払いはGoogle Payを使って安全に行われます。
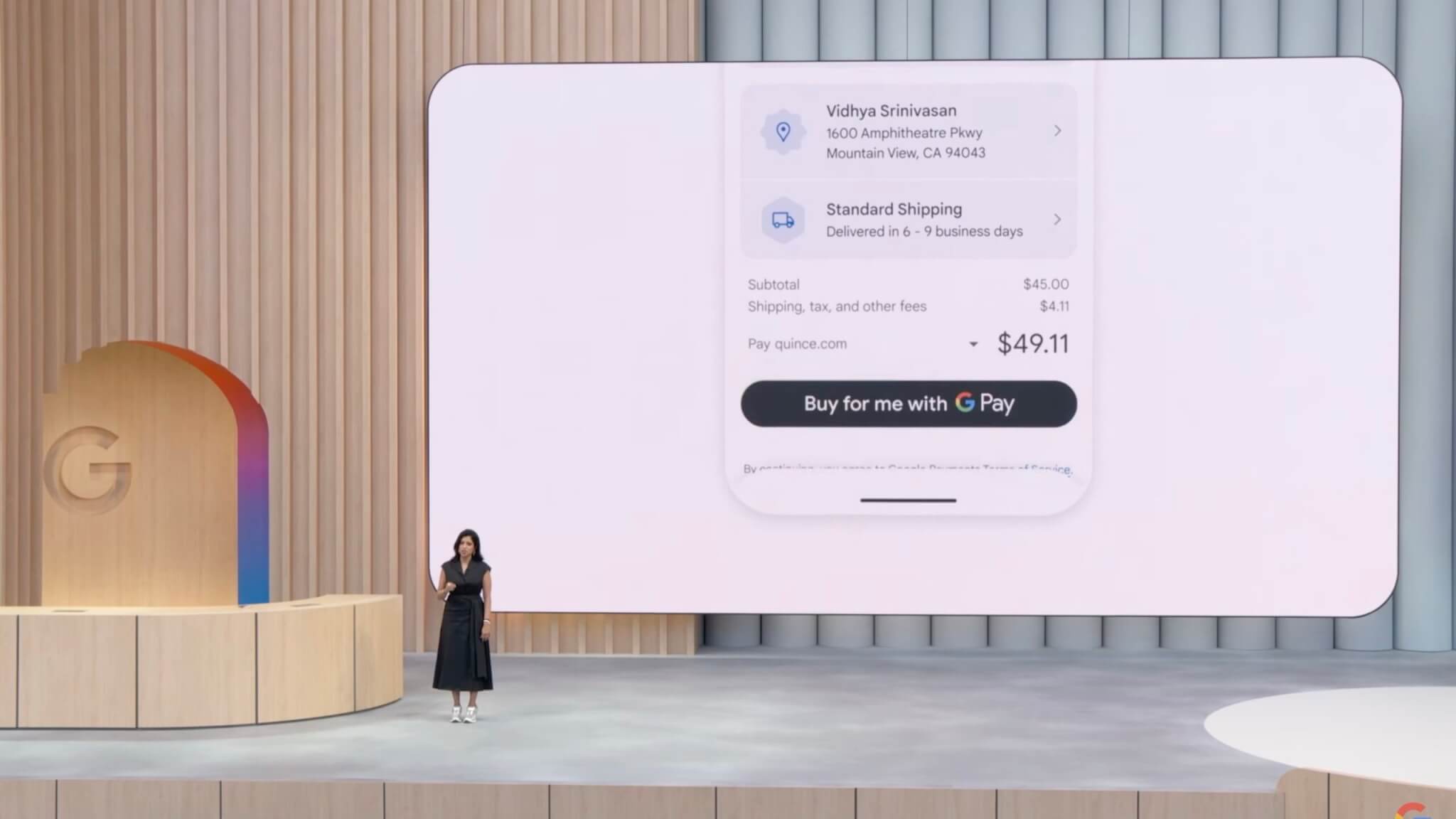
この機能は数ヶ月以内に提供が開始される予定です。
Geminiアプリが大幅進化!個人向けの新機能を多数導入

Googleは、AIアシスタントアプリ「Gemini」を大幅にアップデートし、新たなパーソナライズ機能やリアルタイムのコミュニケーション機能を導入しました。これにより、ユーザーが日常生活や仕事において、より高度で便利なAIサポートを受けることが可能になります。
「Deep Research」機能を強化、個人ファイルやGoogleドライブ・Gmailとの連携が可能に
Geminiアプリ内で利用できる調査支援機能「Deep Research」が強化されました。今回のアップデートにより、ユーザー自身がアップロードした個人ファイルをGeminiが参照し、より正確かつ詳細な調査が可能になります。
さらに今後は、GoogleドライブやGmail内のデータとも連携し、各種ドキュメントやメールの内容も調査に活用できるようになる予定です。
共同作業ツール「Canvas」が大幅に進化、ファイルの自動変換やインタラクティブコンテンツ生成機能を追加
Geminiアプリ内の共同作業スペース「Canvas」も大きく進化しました。新たに、ユーザーがアップロードした文書を一瞬でインタラクティブなウェブページやクイズ、インフォグラフィック、ポッドキャストなど多彩なコンテンツに自動変換する機能が追加されています。
また、Canvas内で「Vibe Code」を活用し、自然言語で指定するだけでコード生成や編集を簡単に行えるようになりました。
GeminiをChromeブラウザに統合、ウェブ閲覧をサポートする新機能を提供
GeminiがChromeブラウザと統合され、閲覧中のウェブページに関する質問に自動的に回答する機能が導入されます。
この機能は特に長いページや比較検討が必要な情報において、迅速に情報を整理・提示します。この機能は米国のGemini有料プランユーザー向けに2025年5月21日より提供を開始しています。
生成AIのクリエイティブ応用技術が進化!画像・映像・音楽の生成能力が向上
Googleは、クリエイターや一般ユーザー向けの生成AI技術の大幅な進化を発表しました。新たな画像生成モデルや映像生成モデルを導入し、特に動画生成については音声生成機能も統合して大きく強化しています。また音楽生成技術にも改良を加え、プロフェッショナルレベルの音楽制作をAIで支援できるようになっています。
画像生成モデル「Imagine 4」を発表
Googleは最新の画像生成モデル「Imagine 4」を発表しました。この新モデルは、画像生成における細部の再現性、色の鮮やかさ、全体的なリアルさが従来モデルと比較して大幅に改善されています。

具体的な改善として、影の描写、水滴の細かさなど、よりリアルな質感表現が可能になりました。また、テキストやタイポグラフィの生成能力も著しく向上しており、ポスターや招待状などのデザイン制作にも精度の高い画像生成が可能となっています。
さらに、「Imagine 4」には従来モデルの10倍以上という高速バージョンも提供されるため、ユーザーは迅速に多数の画像アイデアを試し、よりクリエイティブな制作が行えるようになります。
この新モデルはイベント当日(2025年5月21日)よりGeminiアプリ内で利用可能となっています。
映像生成モデルが「Veo 3」に進化、動画と音声の統合生成が可能に
Googleは、映像生成モデル「Veo」シリーズの最新バージョンとなる「Veo 3」を発表しました。「Veo 3」は映像生成技術としての品質をさらに高めただけでなく、新たに音声生成機能も搭載しています。
「Veo 3」では、従来モデルと比較して映像のリアルさ、特に物理的な挙動(例えば、水や光の自然な表現、物体のリアルな動きなど)の表現能力が著しく向上しています。生成された映像は、従来モデルに比べてより自然でリアリティがあり、映像制作のプロフェッショナルが求める高いクオリティを実現しました。

さらに「Veo 3」は、動画生成に加えて音声も同時に生成可能になりました。これにより、映像内のキャラクターが実際に会話をしたり、映像に自然な効果音や背景音を加えたりすることができます。
イベントでは、実際に生成された映像サンプルが公開され、森の中でのフクロウとアナグマの会話シーンが紹介されました。

自然な映像表現とキャラクターのリアルな音声が一体化した高品質なコンテンツが示され、映像クリエイターにとって新たな表現力をもたらすモデルとして注目されました。
「Veo 3」はイベント当日の2025年5月21日より、AI映像制作ツール「Flow」の中で利用可能となっています。
音楽生成モデルが進化、「Lyria 2」でプロ品質の音楽制作が可能に
Googleは、新しい音楽生成モデル「Lyria 2」を発表しました。このモデルは、AIによって作曲や編曲を行い、プロフェッショナルレベルの音楽制作を支援することを目的としています。

「Lyria 2」は高品質な楽曲を生成するだけでなく、歌声(ソロやコーラス)を含むメロディアスで表現力豊かな音楽を生成可能です。音楽生成の質が大幅に向上しており、AIが生成する楽曲の多様性と音楽的な表現の深みが増しています。
イベントでは、グラミー賞受賞歴を持つ著名な音楽家、シャンカル・マハデヴァン氏が実際に「Lyria 2」を利用して音楽を制作するデモ映像が紹介されました。シャンカル氏は、このモデルを「創造力を刺激する素晴らしいツール」と称し、AIが生成した音楽を土台として、自身の創造的なインスピレーションを得ることができると評価しました。
Googleは、この新モデル「Lyria 2」を企業、YouTubeクリエイター、音楽制作プロフェッショナル向けにイベント当日(2025年5月21日)より提供開始しました。
新AIツール「Flow」を発表、AIによる動画制作をプロレベルで支援
Googleは、AIを活用した映像制作ツール「Flow」を新たに発表しました。このツールは、映像生成モデル「Veo 3」と画像生成モデル「Imagine 4」、およびGeminiの推論技術を統合したもので、特にクリエイターや映像制作者のために開発されました。
「Flow」は、AIの支援を受けながら映像クリップを制作・編集する機能を備えており、ユーザーは自然言語で動画の内容を指示するだけで、望んだシーンを生成することが可能です。具体的には、キャラクターやシーンを指定すると、「Flow」が自動的に一貫性のあるストーリー映像を生成します。また、生成した映像のカメラアングルや映像の流れを自由に編集・調整することも容易に行えます。
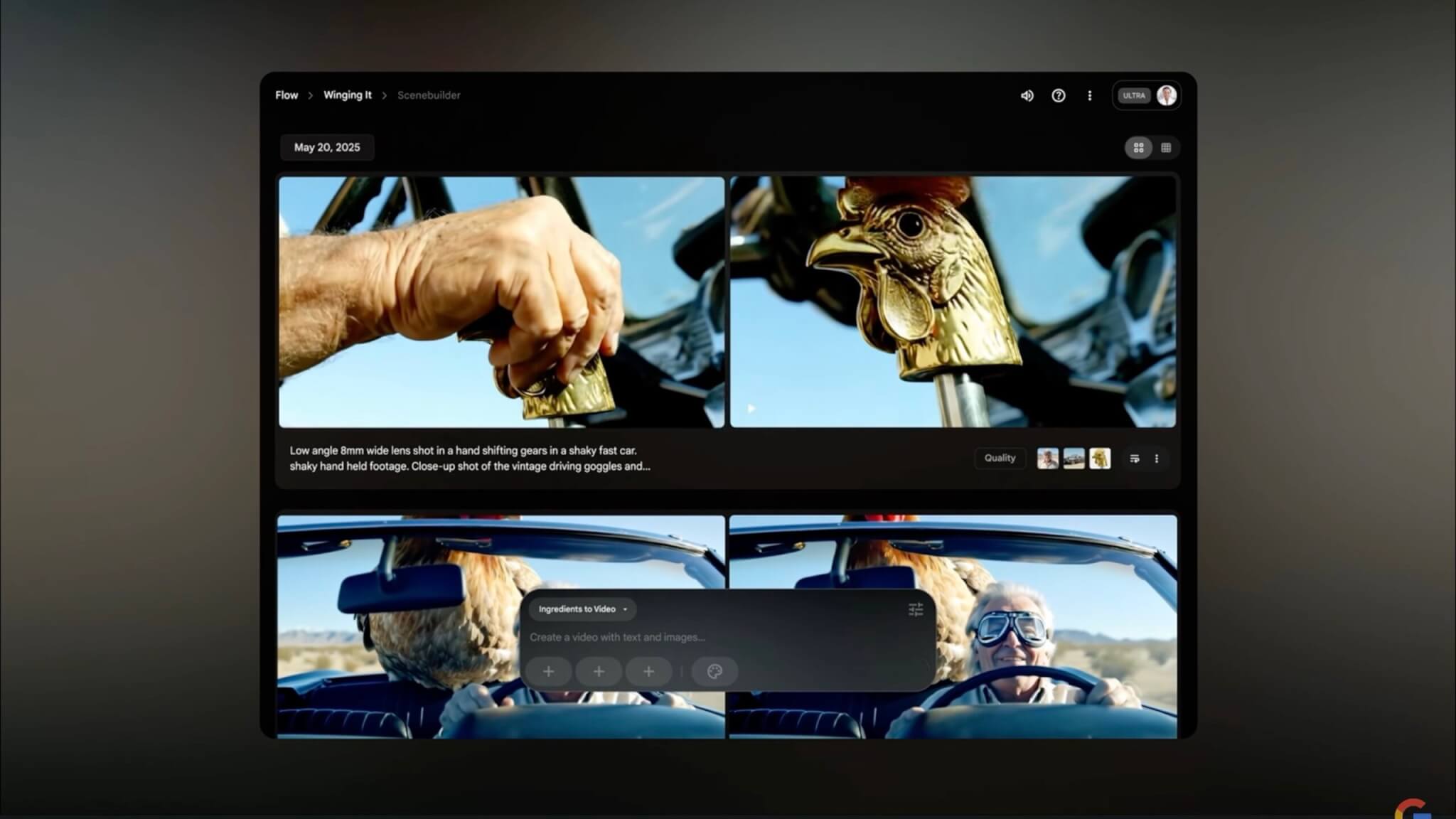
イベント内では実際に「Flow」を使って制作された映像が紹介されました。AIが生成したキャラクターやアイテムを利用してシーンを構築し、次のシーンを自然言語の指示で生成・追加するデモが行われました。完成した映像はプロのクリエイターが手掛けたような仕上がりで、AIによる動画生成の高い表現力と実用性を示しました。
この新ツール「Flow」はイベント当日(2025年5月21日)より、Googleが新たに発表したAI利用の上位プラン「Google AI Ultra」のユーザー向けに提供開始されました。
新料金プラン「Google AI Pro」「Google AI Ultra」を発表

Googleは、AIサービスを利用するための新たなサブスクリプション料金プラン「Google AI Pro」と「Google AI Ultra」を発表しました。これらのプランにより、ユーザーはGoogleの各種AIプロダクトへのアクセスが広がり、利用可能な機能も拡充されます。
「Google AI Pro」を提供開始!従来よりも高い使用制限と特別機能を追加
「Google AI Pro」は、従来の「Gemini Advanced」プランをリニューアルしたもので、全世界のユーザーに対して提供されます。この新プランでは、AIサービスの無料版と比較してより高い使用制限(レートリミット)が設定されており、特別な機能へのアクセスも可能になります。

具体的には、月額19.99ドルでGeminiアプリのProバージョンやGoogleのAI関連プロダクトを自由に利用でき、より多くのリクエストを処理することができます。
「Google AI Ultra」を提供開始!YouTube Premiumや大容量ストレージも付属
「Google AI Ultra」は、最新かつ高度なAI機能をいち早く利用したいユーザー向けに提供される最上位の料金プランで、月額249.99ドルです。このプランに加入すると、Googleの最先端AIプロダクトや新機能への優先的な早期アクセスが可能になります。

具体的には、映像制作AIツール「Flow」、最先端AI推論モード「Gemini 2.5 Pro DeepThinkモード」など、Googleが提供する最新のAI技術を一般ユーザーよりも早く利用できます。
さらに特典として、YouTube Premiumの利用権および大容量のクラウドストレージも含まれており、AIサービスの利用に加えて動画視聴やデータ保管にも大きなメリットがあります。
この「Google AI Ultra」プランは米国で2025年5月21日より提供開始され、順次他の地域にも展開される予定です。
AI生成コンテンツの透明性向上に向けた取り組みを強化
Googleは、AIによって生成されたコンテンツの透明性を確保し、ユーザーがAI生成コンテンツを正確に識別できるようにするための新たな取り組みを発表しました。特に、AI生成画像や動画、音声などのコンテンツが急速に増加する中で、生成コンテンツの信頼性を高めるために重要な施策を展開しています。
AI生成コンテンツを識別する「SynthID」を拡充、検出精度も向上
Googleは、生成されたコンテンツに埋め込むことでAI生成物であることを示す透かし技術「SynthID」の拡充を発表しました。この技術は2023年に導入され、すでに100億件を超えるコンテンツに利用されています。
今回の発表では、このSynthIDをさらに多くのAI生成コンテンツに適用できるようにするほか、埋め込まれた透かしの検出精度を大幅に向上させる新しいSynthID検出器を公開しました。この検出器は、画像だけでなく音声やテキスト、動画など多様な種類のAI生成コンテンツに対応し、部分的なコンテンツでも透かしを検出できるようになりました。
SynthID検出器の新バージョンは、一部の限定的なテスター向けに2025年5月21日より提供開始されています。
パートナーシップを拡大し、AI生成物の透明性向上を業界全体で推進
Googleはまた、この透明性向上の取り組みを業界全体に広げるため、新たな企業や組織とのパートナーシップを拡大しています。生成AIのコンテンツ制作に携わるさまざまな企業と協力し、AI生成コンテンツが広く識別可能になるよう環境整備を進めます。
こうした取り組みにより、ユーザーがAI生成コンテンツを正確に認識できるようになり、誤解や混乱の防止に大きく寄与すると期待されています。
Android XRを発表、XRデバイス向けにGemini搭載で新たな体験を提供

Googleは、GeminiのAI技術を統合した次世代プラットフォーム「Android XR」を正式に発表しました。このプラットフォームは、ヘッドセットや軽量メガネ型デバイスなど、XR(拡張現実、仮想現実)デバイスのためのAndroidベースの新しいOSです。
Samsungのヘッドセット「Project Moohan」が初のAndroid XR対応デバイスとして登場
Android XRプラットフォームを最初に採用するデバイスとして、Samsungが開発したXRヘッドセット「Project Moohan」が公開されました。

このヘッドセットでは、GeminiのAIアシスタントを利用しながら、仮想的に大画面でアプリを操作したり、Googleマップを使って世界のあらゆる場所へ瞬時に仮想旅行したりすることが可能になります。
さらにMLBアプリと連携したスポーツ観戦など、リアルタイムで詳細な情報をAIに質問しながら視聴する体験が可能です。「Project Muhan」は2025年内に一般販売が開始される予定です。
Android XR対応のメガネ型デバイスも開発中
Googleは、ヘッドセット以外に日常的に利用できる軽量メガネ型のAndroid XR対応デバイスも発表しました。このメガネ型デバイスは、Geminiがユーザーの周囲の環境をカメラやマイクを通じてリアルタイムで把握し、音声や視覚情報でユーザーをサポートします。

具体的な使用例としては、街中の看板や物体にカメラを向けてGeminiに質問したり、歩行中にリアルタイムで道順を案内してもらったり、予定のスケジュール管理をハンズフリーで行ったりすることが可能です。
Gentle MonsterとWarby Parkerと提携
Googleは、メガネ型デバイスの開発・提供を加速させるため、アイウェアブランドのGENTLE MONSTERおよびWarby Parkerとの提携を発表しました。

両社と協力し、デザイン性に優れ、普段使いしやすいスタイリッシュなXR対応メガネを展開する計画です。
メガネ型デバイスのプロトタイプは既に一部の限定テスターに提供されており、開発者向けには2025年内に公開予定となっています。
火災監視衛星「FireSat」やドローン配送などを展開

Googleは、AIを活用して社会的課題の解決を目指す取り組みを拡充すると発表しました。特に、防災や災害支援といった緊急時における迅速な対応を可能にするため、AI技術を駆使した新たなプロジェクトを導入しています。
火災の迅速な検知を可能にする衛星プロジェクト「FireSat」を始動
Googleは新たに、AI技術を用いて山火事や森林火災を高精度かつ迅速に検知する衛星プロジェクト「FireSat(ファイアサット)」を開始しました。このプロジェクトでは、多波長の衛星画像とAIを組み合わせ、火災を迅速に検知・分析します。
FireSat衛星はすでに初号機が軌道上に打ち上げられており、火災発生後の映像取得頻度を現状の約12時間ごとから約20分ごとに短縮する計画です。特に約25平方メートル(1台分のガレージ相当)の小さな規模の火災でも即座に検出可能であり、今後の火災対応の迅速化に大きく貢献すると期待されています。
AI支援ドローンを活用した災害支援活動を実施、ウォルマートや赤十字と協力
Google傘下のドローン配送企業であるWingは、ウォルマートおよび米国赤十字と協力し、AI技術を活用した災害支援を実施しました。具体的には、ハリケーン「Helene」の被災地(ノースカロライナ州)において、AIがリアルタイムで被災者が必要とする食料や医薬品などを分析し、ドローンを通じて迅速にYMCAシェルターへの物資配送を行いました。
このようなAIを用いた迅速な物資支援は、今後さらに拡大していく計画です。
Waymoの自動運転タクシーが進展、技術的成熟度と安全性が向上

Googleの自動運転技術開発子会社であるWaymoは、自動運転タクシーの開発状況について最新の進展を発表しました。自動運転技術の成熟度と安全性が一層高まり、一般利用の拡大に向けて着実に進展しています。
Waymoの自動運転車は米国サンフランシスコなどですでに商用運行を開始していますが、GoogleのCEOであるスンダー・ピチャイ氏は、自身の両親がWaymoに初めて乗車した際のエピソードを紹介しました。ピチャイ氏は80代の父親が助手席で自動運転の技術に驚き感銘を受ける姿を見て、自動運転技術の社会実装が進んでいることを改めて実感したと述べました。
また、Waymoは今後も技術の安全性向上と運用範囲の拡大を継続的に進める方針であり、数年以内にはさらに広範な地域で自動運転タクシーを利用できるようになると期待されています。
まとめ
Google I/O 2025では、AI「Gemini」の自律性とパーソナライゼーションの深化が示されました。
「Google Beam」や「AI Mode」、さらに「Android XR」など新しい技術との融合により、AIが日常生活や創造活動を能動的にサポートする未来が現実味を帯びています。
GoogleのAIが私たちの生活を一段と豊かに変える一年となりそうです。